

Recuperação de desastres com CVO e AVS (armazenamento conectado ao convidado)
 Sugerir alterações
Sugerir alterações
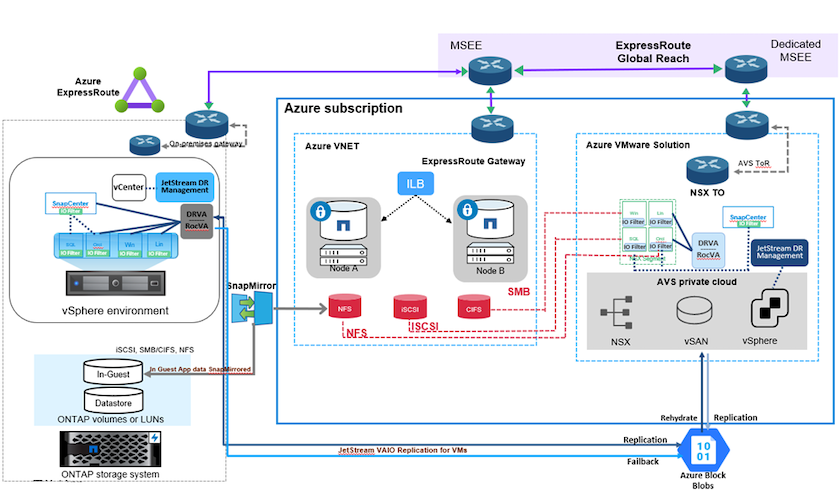
A recuperação de desastres na nuvem é uma maneira resiliente e econômica de proteger cargas de trabalho contra interrupções do site e eventos de corrupção de dados, como ransomware. Com o NetApp SnapMirror, as cargas de trabalho locais do VMware que usam armazenamento conectado ao convidado podem ser replicadas para o NetApp Cloud Volumes ONTAP em execução no Azure.
Visão geral
This covers application data; however, what about the actual VMs themselves. Disaster recovery should cover all dependent components, including virtual machines, VMDKs, application data, and more. To accomplish this, SnapMirror along with Jetstream can be used to seamlessly recover workloads replicated from on-premises to Cloud Volumes ONTAP while using vSAN storage for VM VMDKs. Este documento fornece uma abordagem passo a passo para configurar e executar a recuperação de desastres que usa o NetApp SnapMirror, o JetStream e o Azure VMware Solution (AVS).
Suposições
Este documento se concentra no armazenamento no convidado para dados de aplicativos (também conhecido como convidado conectado), e presumimos que o ambiente local esteja usando o SnapCenter para backups consistentes com aplicativos.

|
Este documento se aplica a qualquer solução de backup ou recuperação de terceiros. Dependendo da solução usada no ambiente, siga as práticas recomendadas para criar políticas de backup que atendam aos SLAs organizacionais. |
Para conectividade entre o ambiente local e a rede virtual do Azure, use o Express Route Global Reach ou uma WAN virtual com um gateway VPN. Os segmentos devem ser criados com base no design da vLAN local.
|
|
Há várias opções para conectar datacenters locais ao Azure, o que nos impede de descrever um fluxo de trabalho específico neste documento. Consulte a documentação do Azure para obter o método apropriado de conectividade local com o Azure. |
Implementando a solução de DR
Visão geral da implantação da solução
-
Certifique-se de que os dados do aplicativo sejam copiados usando o SnapCenter com os requisitos de RPO necessários.
-
Provisione o Cloud Volumes ONTAP com o tamanho de instância correto usando o Cloud Manager dentro da assinatura e rede virtual apropriadas.
-
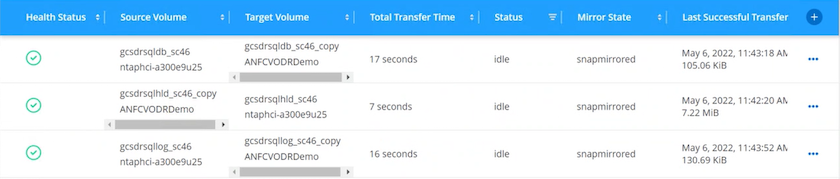
Configure o SnapMirror para os volumes de aplicativos relevantes.
-
Atualize as políticas de backup no SnapCenter para acionar atualizações do SnapMirror após os trabalhos agendados.
-
-
Instale o software JetStream DR no data center local e inicie a proteção para máquinas virtuais.
-
Instale o software JetStream DR na nuvem privada do Azure VMware Solution.
-
Durante um evento de desastre, interrompa o relacionamento do SnapMirror usando o Cloud Manager e acione o failover de máquinas virtuais para o Azure NetApp Files ou para armazenamentos de dados vSAN no site de DR do AVS designado.
-
Reconecte os LUNs ISCSI e as montagens NFS para as VMs do aplicativo.
-
-
Invoque o failback para o site protegido por meio da ressincronização reversa do SnapMirror após a recuperação do site primário.
Detalhes da implantação
Configurar o CVO no Azure e replicar volumes para o CVO
O primeiro passo é configurar o Cloud Volumes ONTAP no Azure ("Link" ) e replicar os volumes desejados para o Cloud Volumes ONTAP com as frequências e retenções de snapshots desejadas.
Configurar hosts AVS e acesso a dados CVO
Dois fatores importantes a serem considerados ao implantar o SDDC são o tamanho do cluster SDDC na solução Azure VMware e por quanto tempo manter o SDDC em serviço. Essas duas considerações importantes para uma solução de recuperação de desastres ajudam a reduzir os custos operacionais gerais. O SDDC pode ter apenas três hosts ou até mesmo um cluster de vários hosts em uma implantação em grande escala.
A decisão de implantar um cluster AVS é baseada principalmente nos requisitos de RPO/RTO. Com a solução Azure VMware, o SDDC pode ser provisionado na hora certa em preparação para testes ou para um evento de desastre real. Um SDDC implantado just in time economiza em custos de host ESXi quando você não está lidando com um desastre. No entanto, essa forma de implantação afeta o RTO por algumas horas enquanto o SDDC está sendo provisionado.
A opção mais comumente implantada é ter o SDDC em execução em um modo de operação piloto sempre ativo. Essa opção fornece uma pequena área de cobertura de três hosts que estão sempre disponíveis e também acelera as operações de recuperação ao fornecer uma linha de base em execução para atividades de simulação e verificações de conformidade, evitando assim o risco de desvio operacional entre os sites de produção e DR. O cluster de luz piloto pode ser ampliado rapidamente para o nível desejado quando necessário para lidar com um evento de DR real.
Para configurar o AVS SDDC (seja sob demanda ou no modo piloto), consulte"Implantar e configurar o ambiente de virtualização no Azure" . Como pré-requisito, verifique se as VMs convidadas que residem nos hosts AVS conseguem consumir dados do Cloud Volumes ONTAP depois que a conectividade for estabelecida.
Depois que o Cloud Volumes ONTAP e o AVS forem configurados corretamente, comece a configurar o Jetstream para automatizar a recuperação de cargas de trabalho locais para o AVS (VMs com VMDKs de aplicativo e VMs com armazenamento no convidado) usando o mecanismo VAIO e aproveitando o SnapMirror para cópias de volumes de aplicativo para o Cloud Volumes ONTAP.
Instalar o JetStream DR no datacenter local
O software JetStream DR consiste em três componentes principais: o JetStream DR Management Server Virtual Appliance (MSA), o DR Virtual Appliance (DRVA) e componentes de host (pacotes de filtros de E/S). O MSA é usado para instalar e configurar componentes do host no cluster de computação e, em seguida, para administrar o software JetStream DR. O processo de instalação é o seguinte:
-
Verifique os pré-requisitos.
-
Execute a Ferramenta de Planejamento de Capacidade para obter recomendações de recursos e configuração.
-
Implante o JetStream DR MSA em cada host vSphere no cluster designado.
-
Inicie o MSA usando seu nome DNS em um navegador.
-
Registre o servidor vCenter com o MSA.
-
Depois que o JetStream DR MSA for implantado e o vCenter Server for registrado, navegue até o plug-in JetStream DR com o vSphere Web Client. Isso pode ser feito navegando até Datacenter > Configurar > JetStream DR.
-
Na interface do JetStream DR, conclua as seguintes tarefas:
-
Configure o cluster com o pacote de filtro de E/S.
-
Adicione o armazenamento de Blobs do Azure localizado no site de recuperação.
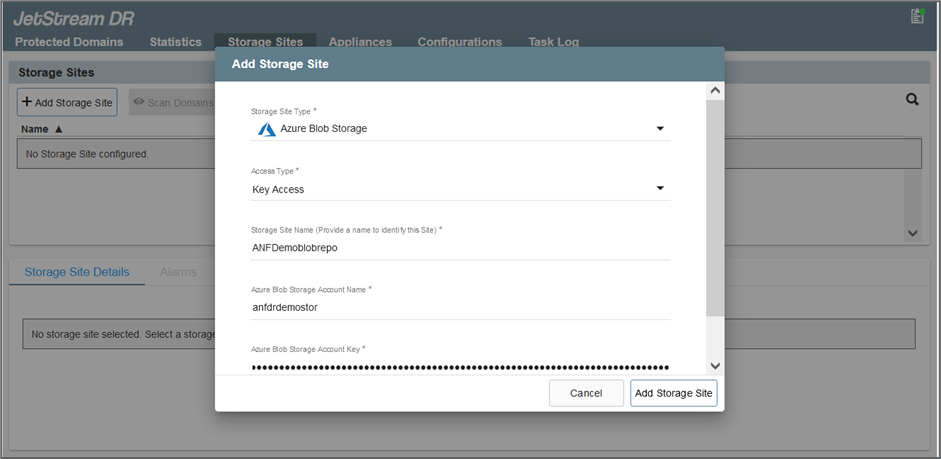
-
-
Implante o número necessário de DR Virtual Appliances (DRVAs) na guia Appliances.
Use a ferramenta de planejamento de capacidade para estimar o número de DRVAs necessários. 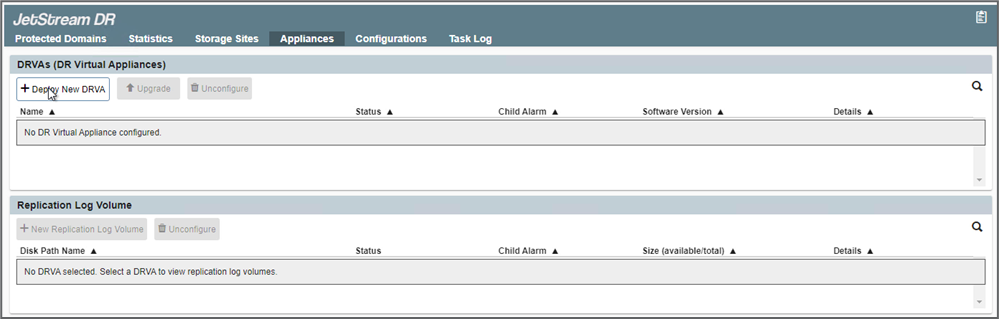
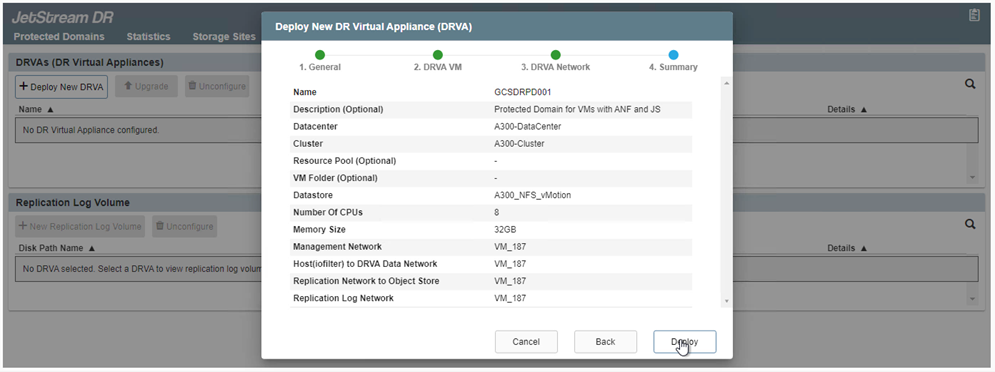
-
Crie volumes de log de replicação para cada DRVA usando o VMDK dos armazenamentos de dados disponíveis ou do pool de armazenamento iSCSI compartilhado independente.
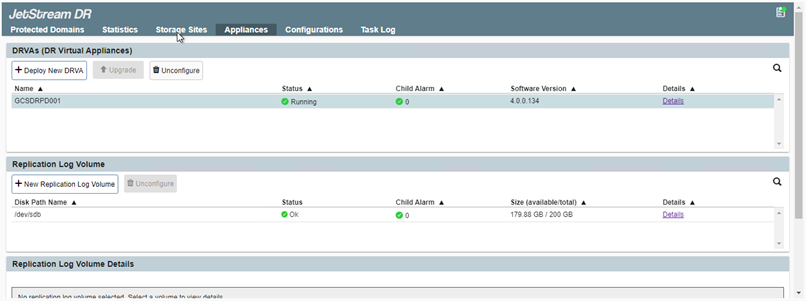
-
Na guia Domínios Protegidos, crie o número necessário de domínios protegidos usando informações sobre o site do Armazenamento de Blobs do Azure, a instância do DRVA e o log de replicação. Um domínio protegido define uma VM específica ou um conjunto de VMs de aplicativos dentro do cluster que são protegidas em conjunto e recebem uma ordem de prioridade para operações de failover/failback.
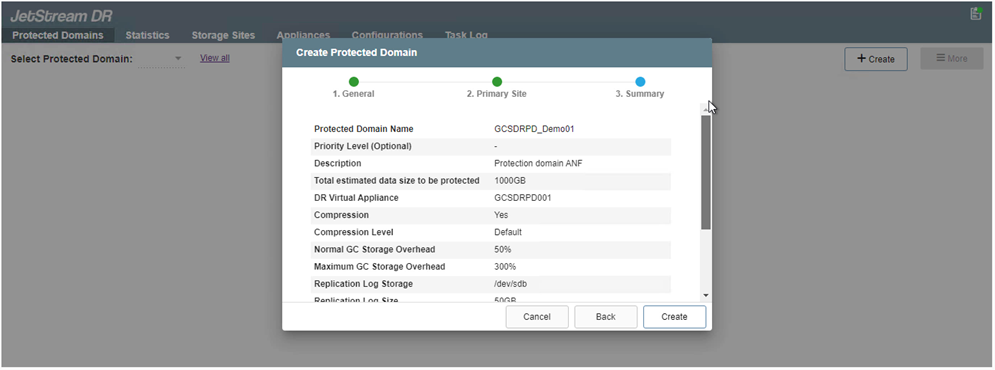
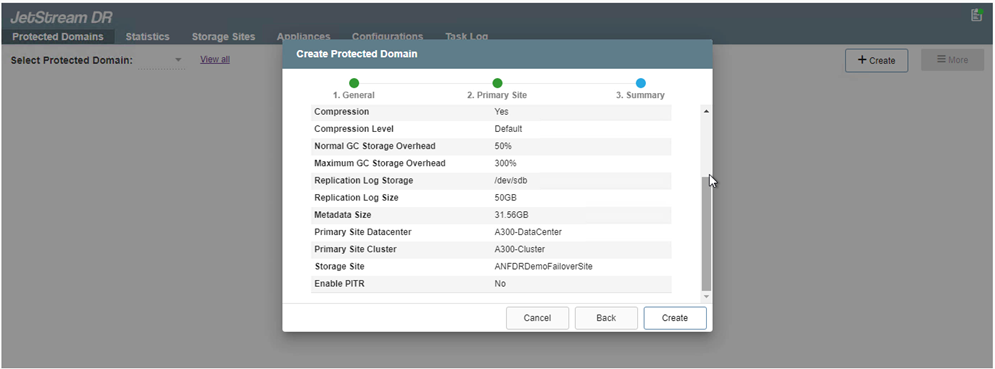
-
Selecione as VMs a serem protegidas e agrupe-as em grupos de aplicativos com base na dependência. As definições de aplicativo permitem agrupar conjuntos de VMs em grupos lógicos que contêm suas ordens de inicialização, atrasos de inicialização e validações de aplicativo opcionais que podem ser executadas na recuperação.
Certifique-se de que o mesmo modo de proteção seja usado para todas as VMs em um domínio protegido.
O modo Write-Back (VMDK) oferece maior desempenho. 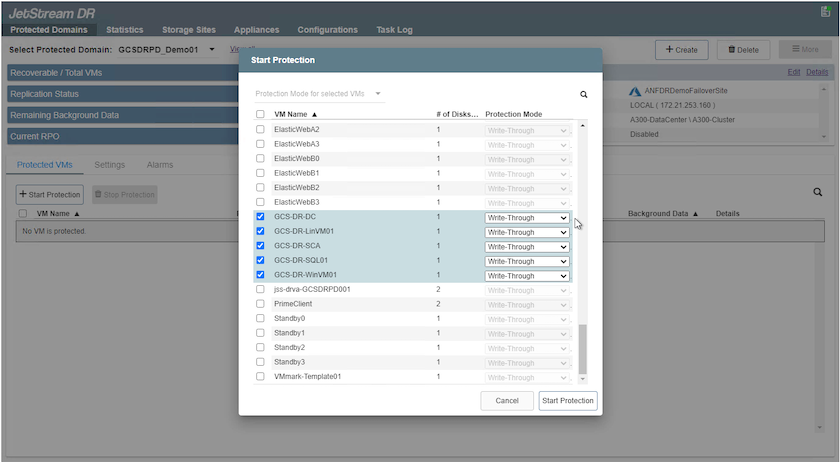
-
Certifique-se de que os volumes de log de replicação sejam colocados em armazenamento de alto desempenho.
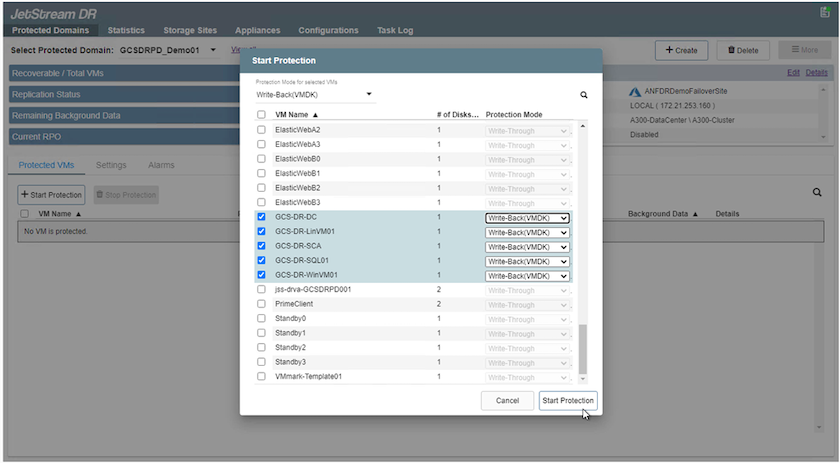
-
Após terminar, clique em Iniciar proteção para o domínio protegido. Isso inicia a replicação de dados das VMs selecionadas para o repositório de Blobs designado.
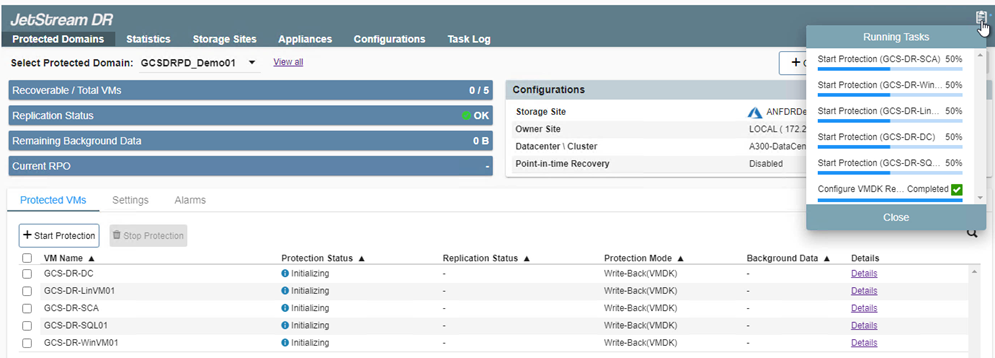
-
Após a conclusão da replicação, o status de proteção da VM é marcado como Recuperável.
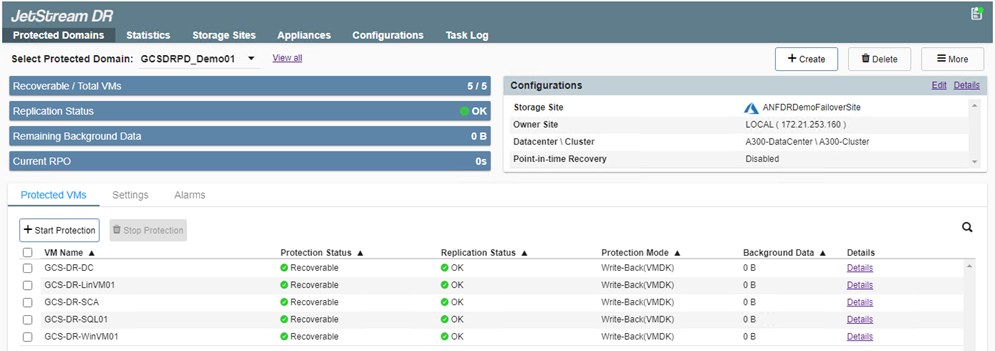
Os runbooks de failover podem ser configurados para agrupar as VMs (chamado de grupo de recuperação), definir a sequência da ordem de inicialização e modificar as configurações de CPU/memória, juntamente com as configurações de IP. -
Clique em Configurações e depois no link Configurar runbook para configurar o grupo de runbooks.
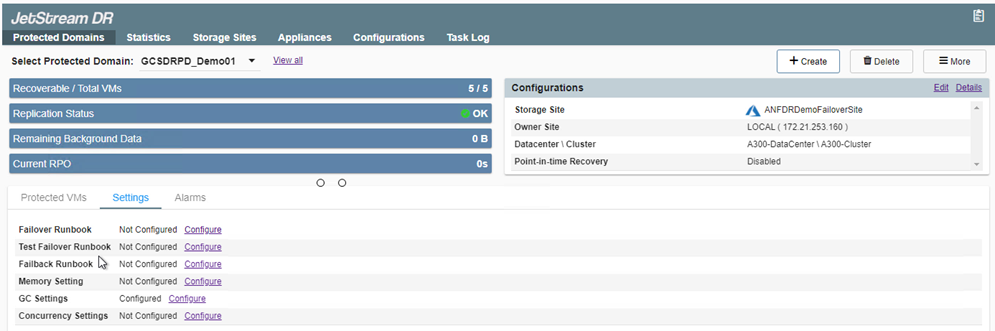
-
Clique no botão Criar grupo para começar a criar um novo grupo de runbook.
Se necessário, na parte inferior da tela, aplique pré-scripts e pós-scripts personalizados para serem executados automaticamente antes e depois da operação do grupo de runbooks. Certifique-se de que os scripts do Runbook estejam residindo no servidor de gerenciamento. 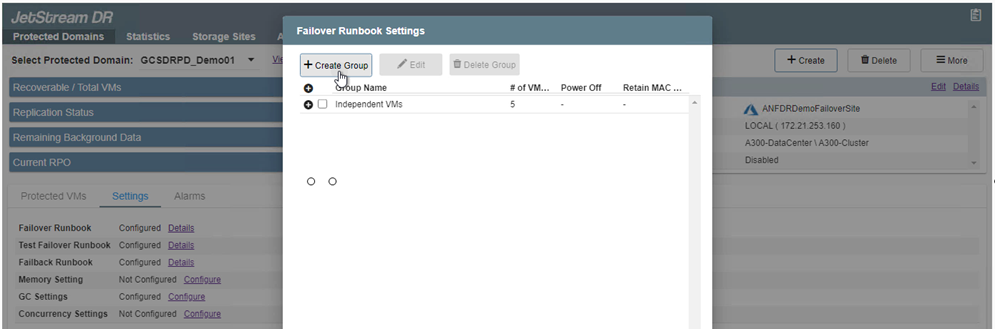
-
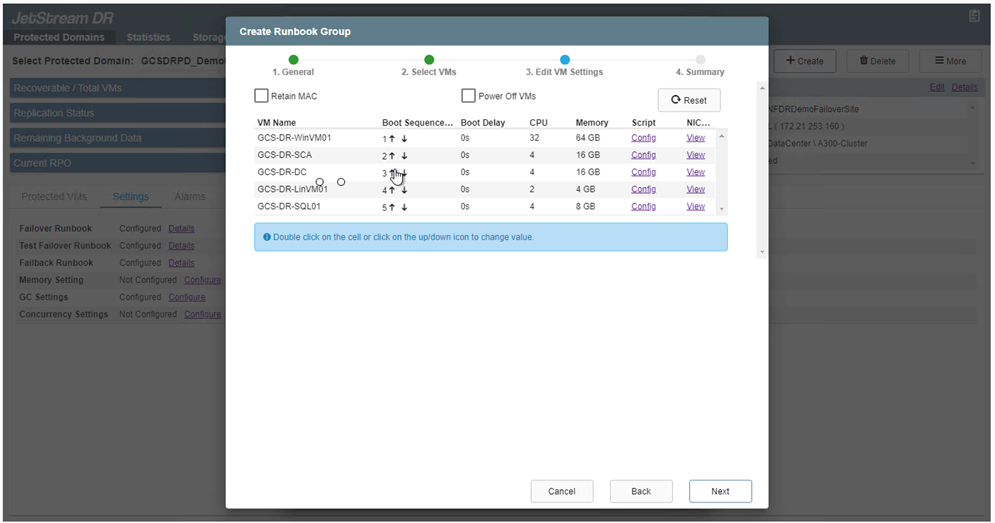
Edite as configurações da VM conforme necessário. Especifique os parâmetros para recuperar as VMs, incluindo a sequência de inicialização, o atraso de inicialização (especificado em segundos), o número de CPUs e a quantidade de memória a ser alocada. Altere a sequência de inicialização das VMs clicando nas setas para cima ou para baixo. Também são fornecidas opções para manter o MAC.
-
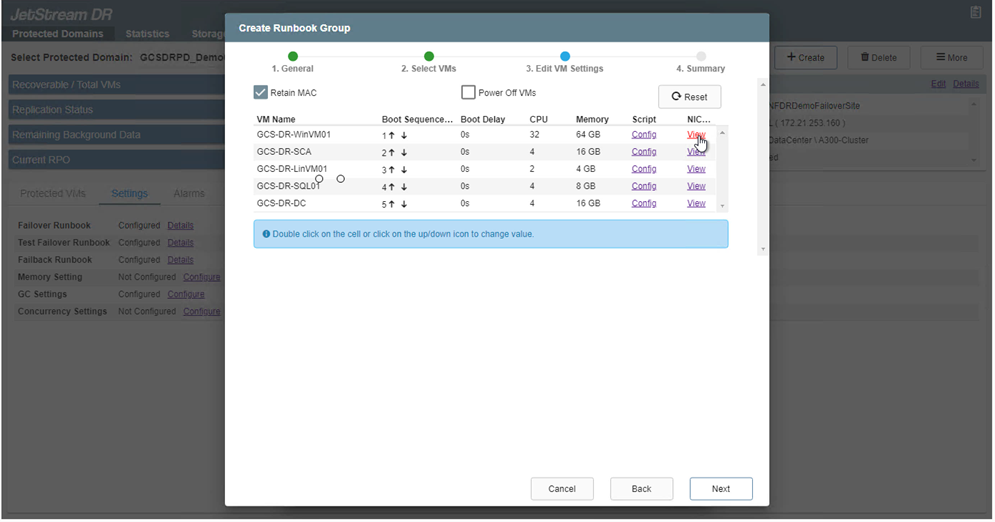
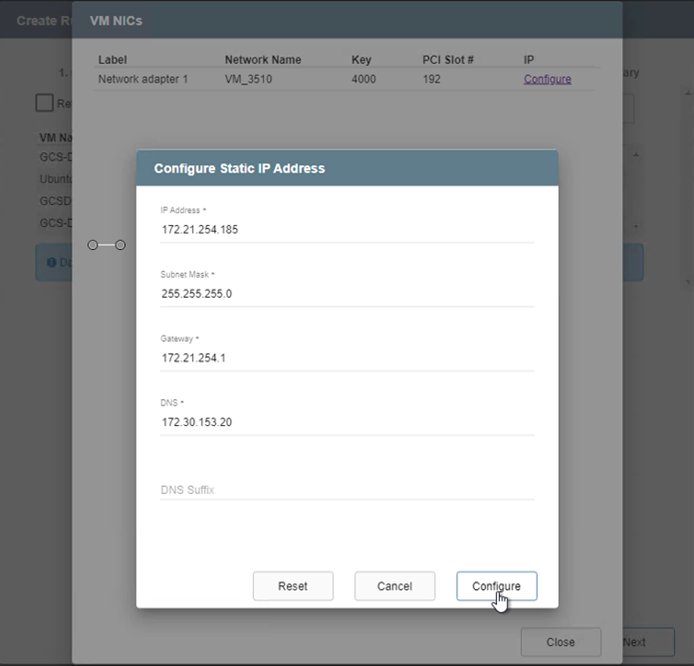
Endereços IP estáticos podem ser configurados manualmente para as VMs individuais do grupo. Clique no link Visualização da NIC de uma VM para configurar manualmente suas configurações de endereço IP.
-
Clique no botão Configurar para salvar as configurações de NIC para as respectivas VMs.
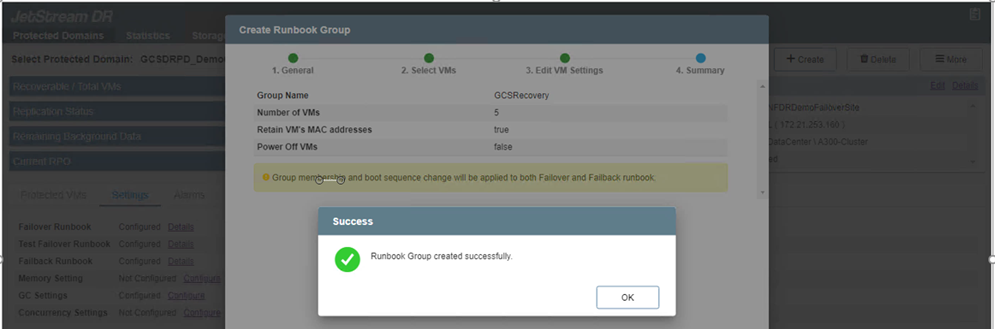
O status dos runbooks de failover e failback agora está listado como Configurado. Os grupos de runbooks de failover e failback são criados em pares usando o mesmo grupo inicial de VMs e configurações. Se necessário, as configurações de qualquer grupo de runbooks podem ser personalizadas individualmente clicando no respectivo link Detalhes e fazendo alterações.
Instalar JetStream DR para AVS em nuvem privada
Uma prática recomendada para um site de recuperação (AVS) é criar um cluster de luz piloto de três nós com antecedência. Isso permite que a infraestrutura do site de recuperação seja pré-configurada, incluindo o seguinte:
-
Segmentos de rede de destino, firewalls, serviços como DHCP e DNS e assim por diante
-
Instalação do JetStream DR para AVS
-
Configuração de volumes ANF como datastores e muito mais
O JetStream DR suporta um modo RTO próximo de zero para domínios de missão crítica. Para esses domínios, o armazenamento de destino deve ser pré-instalado. ANF é um tipo de armazenamento recomendado neste caso.
|
|
A configuração de rede, incluindo a criação de segmentos, deve ser configurada no cluster AVS para atender aos requisitos locais. |
|
|
Dependendo dos requisitos de SLA e RTO, você pode usar o failover contínuo ou o modo de failover regular (padrão). Para um RTO próximo de zero, você deve iniciar a reidratação contínua no local de recuperação. |
-
Para instalar o JetStream DR para AVS em uma nuvem privada do Azure VMware Solution, use o comando Executar. No portal do Azure, acesse a solução Azure VMware, selecione a nuvem privada e selecione Executar comando > Pacotes > JSDR.Configuration.
O usuário padrão do CloudAdmin do Azure VMware Solution não tem privilégios suficientes para instalar o JetStream DR para AVS. A Solução VMware do Azure permite a instalação simplificada e automatizada do JetStream DR invocando o comando Executar Solução VMware do Azure para o JetStream DR. A captura de tela a seguir mostra a instalação usando um endereço IP baseado em DHCP.
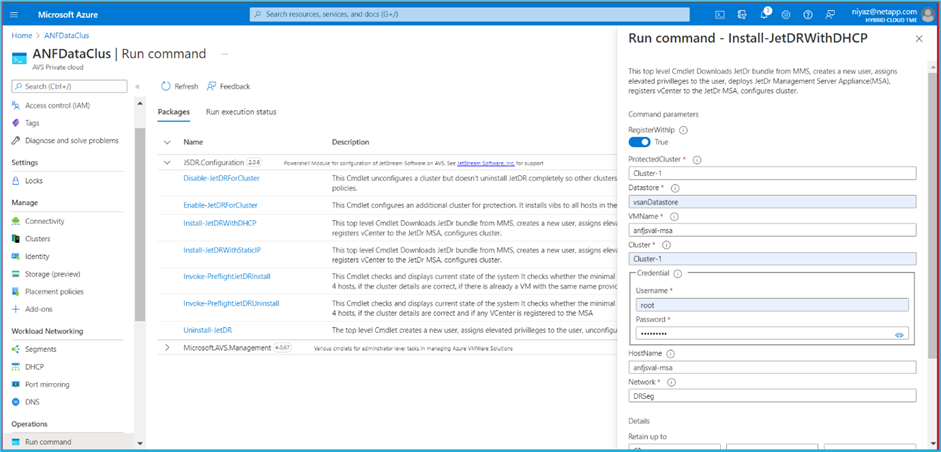
-
Após a conclusão da instalação do JetStream DR para AVS, atualize o navegador. Para acessar a interface do usuário do JetStream DR, vá para SDDC Datacenter > Configurar > JetStream DR.
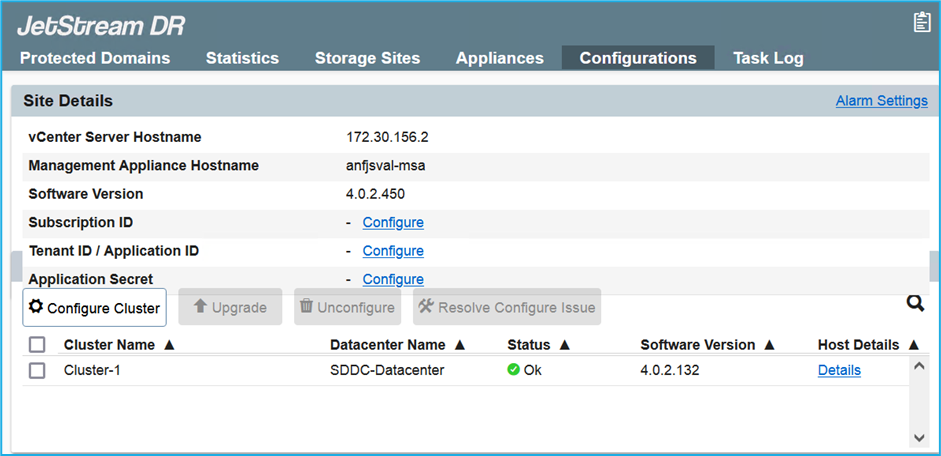
-
Na interface do JetStream DR, conclua as seguintes tarefas:
-
Adicione a conta do Armazenamento de Blobs do Azure que foi usada para proteger o cluster local como um site de armazenamento e execute a opção Verificar Domínios.
-
Na janela de diálogo pop-up que aparece, selecione o domínio protegido a ser importado e clique no link Importar.

-
-
O domínio é importado para recuperação. Vá para a aba Domínios Protegidos e verifique se o domínio pretendido foi selecionado ou escolha o desejado no menu Selecionar Domínio Protegido. Uma lista de VMs recuperáveis no domínio protegido é exibida.
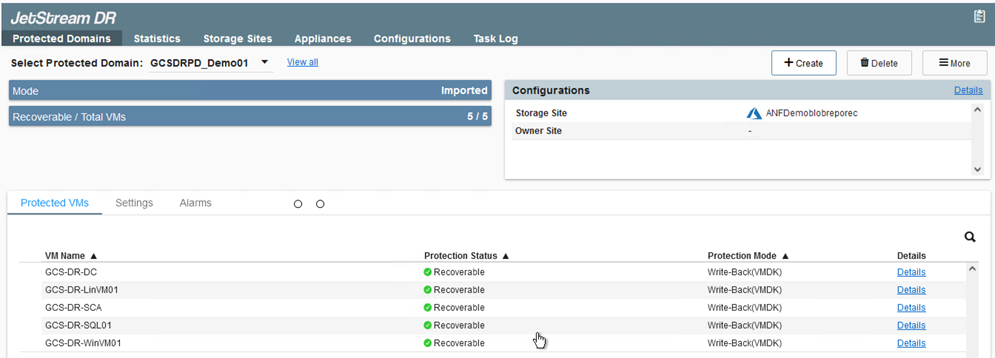
-
Depois que os domínios protegidos forem importados, implante os dispositivos DRVA.
Essas etapas também podem ser automatizadas usando planos criados pela CPT. -
Crie volumes de log de replicação usando armazenamentos de dados vSAN ou ANF disponíveis.
-
Importe os domínios protegidos e configure a VA de recuperação para usar um armazenamento de dados ANF para posicionamentos de VM.
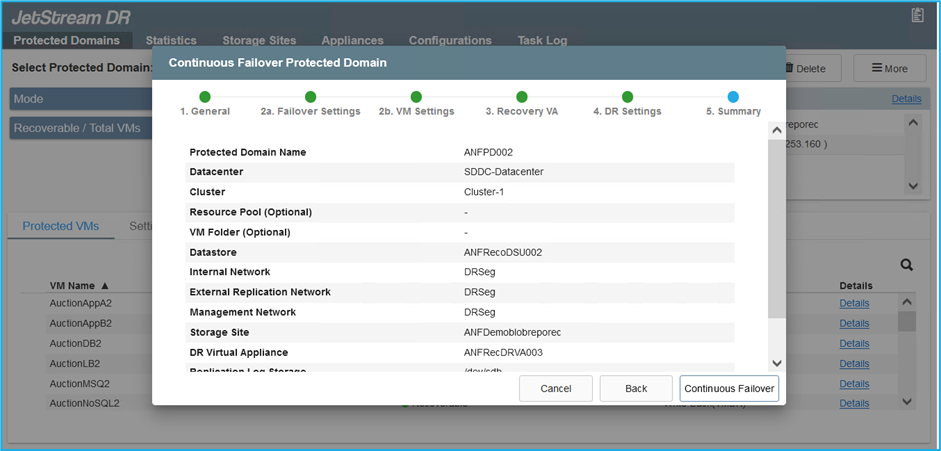
Certifique-se de que o DHCP esteja habilitado no segmento selecionado e que haja IPs suficientes disponíveis. IPs dinâmicos são usados temporariamente enquanto os domínios estão se recuperando. Cada VM em recuperação (incluindo reidratação contínua) requer um IP dinâmico individual. Após a recuperação ser concluída, o IP é liberado e pode ser reutilizado. -
Selecione a opção de failover apropriada (failover contínuo ou failover). Neste exemplo, a reidratação contínua (failover contínuo) é selecionada.
Embora os modos Failover Contínuo e Failover sejam diferentes em quando a configuração é realizada, ambos os modos de failover são configurados usando as mesmas etapas. As etapas de failover são configuradas e executadas juntas em resposta a um evento de desastre. O failover contínuo pode ser configurado a qualquer momento e então executado em segundo plano durante a operação normal do sistema. Após a ocorrência de um evento de desastre, o failover contínuo é concluído para transferir imediatamente a propriedade das VMs protegidas para o site de recuperação (RTO próximo de zero). 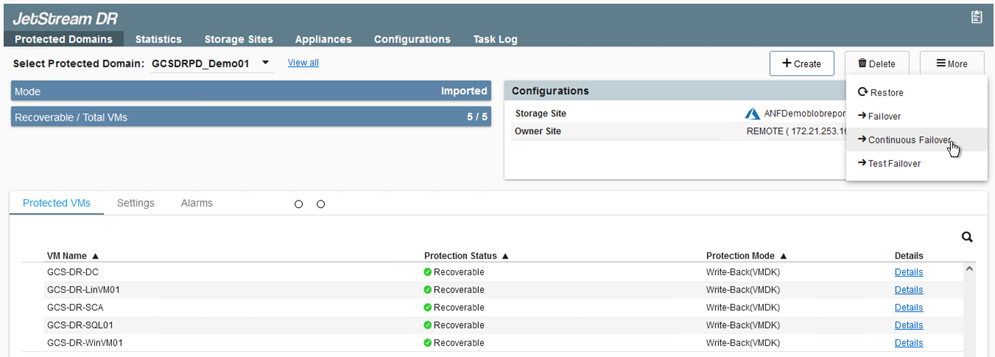
O processo de failover contínuo é iniciado e seu progresso pode ser monitorado pela interface do usuário. Clicar no ícone azul na seção Etapa atual expõe uma janela pop-up mostrando detalhes da etapa atual do processo de failover.
Failover e Failback
-
Após ocorrer um desastre no cluster protegido do ambiente local (falha parcial ou completa), você pode acionar o failover para VMs usando o Jetstream após interromper o relacionamento do SnapMirror para os respectivos volumes de aplicativo.
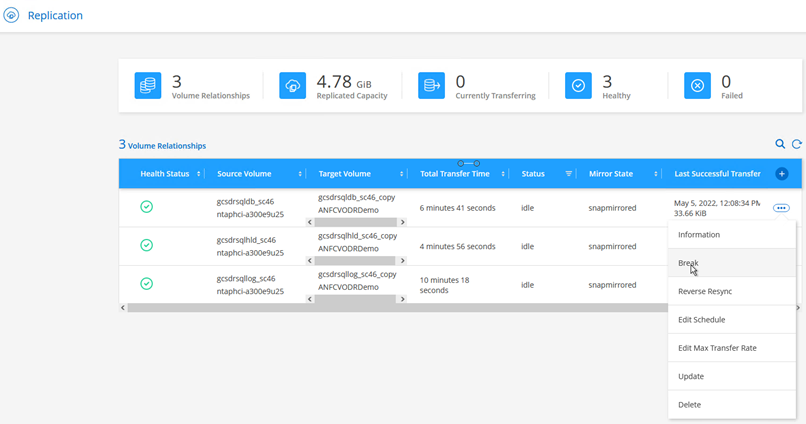
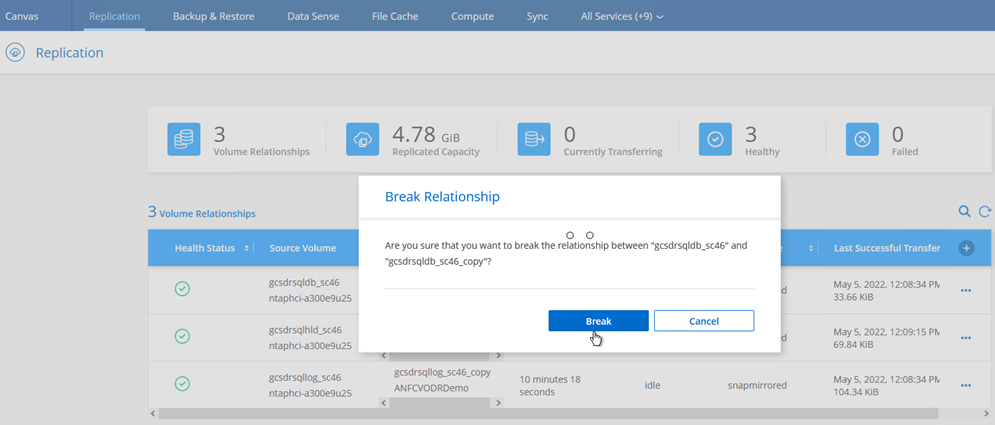
Esta etapa pode ser facilmente automatizada para facilitar o processo de recuperação. -
Acesse a interface do usuário do Jetstream no AVS SDDC (lado de destino) e acione a opção de failover para concluir o failover. A barra de tarefas mostra o progresso das atividades de failover.
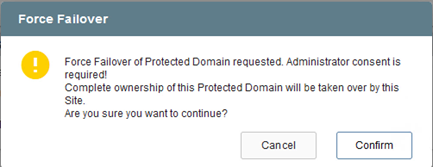
Na janela de diálogo que aparece ao concluir o failover, a tarefa de failover pode ser especificada como planejada ou assumida como forçada.
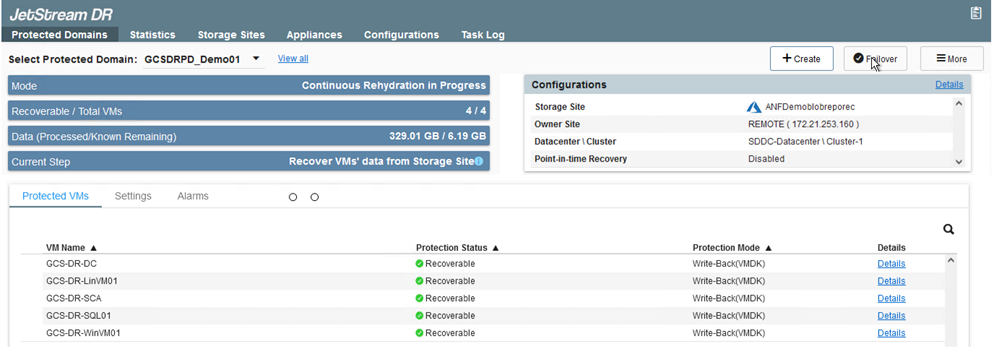
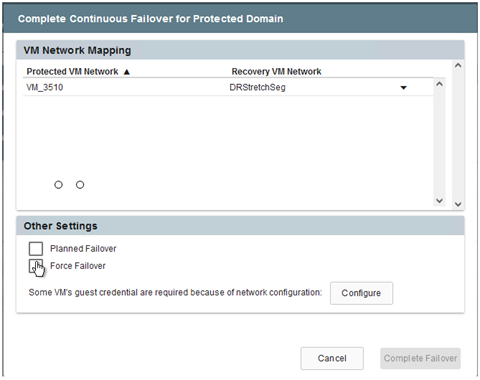
O failover forçado pressupõe que o site principal não está mais acessível e a propriedade do domínio protegido deve ser assumida diretamente pelo site de recuperação.
-
Após a conclusão do failover contínuo, uma mensagem será exibida confirmando a conclusão da tarefa. Quando a tarefa estiver concluída, acesse as VMs recuperadas para configurar sessões ISCSI ou NFS.
O modo de failover muda para Em execução no failover e o status da VM é Recuperável. Todas as VMs do domínio protegido agora estão em execução no site de recuperação no estado especificado pelas configurações do runbook de failover.
Para verificar a configuração e a infraestrutura de failover, o JetStream DR pode ser operado no modo de teste (opção Test Failover) para observar a recuperação de máquinas virtuais e seus dados do armazenamento de objetos em um ambiente de recuperação de teste. Quando um procedimento de failover é executado no modo de teste, sua operação se assemelha a um processo de failover real. 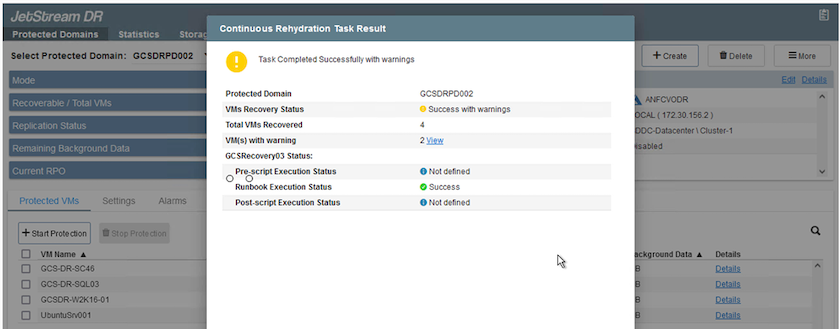
-
Depois que as máquinas virtuais forem recuperadas, use a recuperação de desastres de armazenamento para armazenamento no convidado. Para demonstrar esse processo, o servidor SQL é usado neste exemplo.
-
Efetue login na VM SnapCenter recuperada no AVS SDDC e ative o modo DR.
-
Acesse a interface do usuário do SnapCenter usando o navegadorN.
-
Na página Configurações, navegue até Configurações > Configurações globais > Recuperação de desastres.
-
Selecione Habilitar recuperação de desastres.
-
Clique em Aplicar.
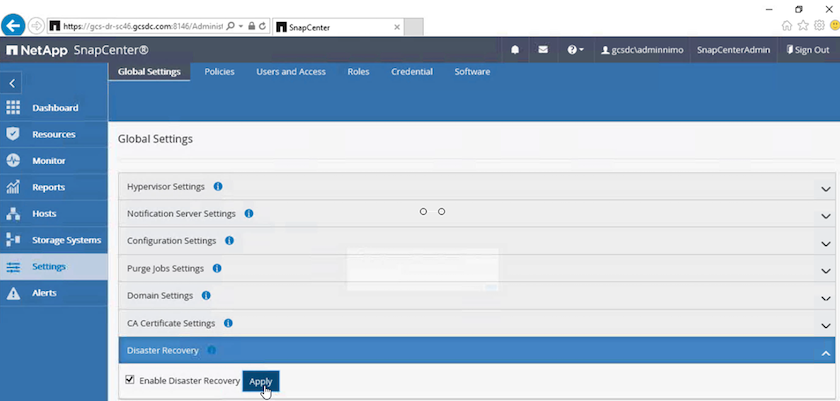
-
Verifique se o trabalho de DR está habilitado clicando em Monitor > Trabalhos.
O NetApp SnapCenter 4.6 ou posterior deve ser usado para recuperação de desastres de armazenamento. Para versões anteriores, snapshots consistentes com o aplicativo (replicados usando SnapMirror) devem ser usados e a recuperação manual deve ser executada caso backups anteriores precisem ser recuperados no site de recuperação de desastres.
-
-
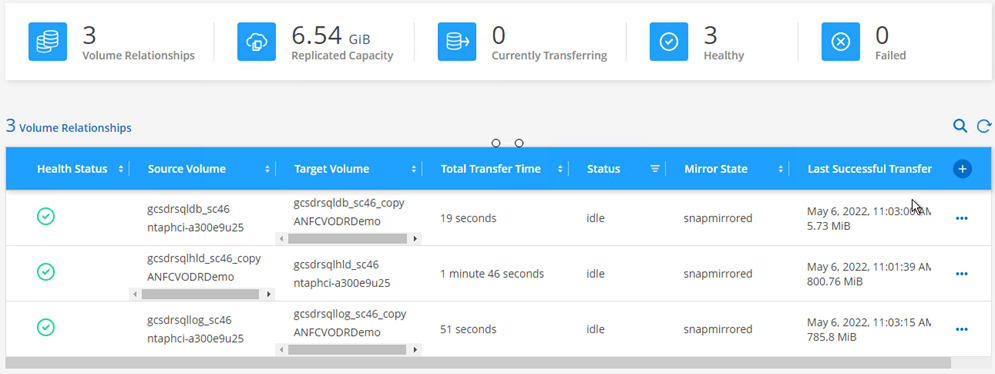
Certifique-se de que o relacionamento SnapMirror esteja quebrado.
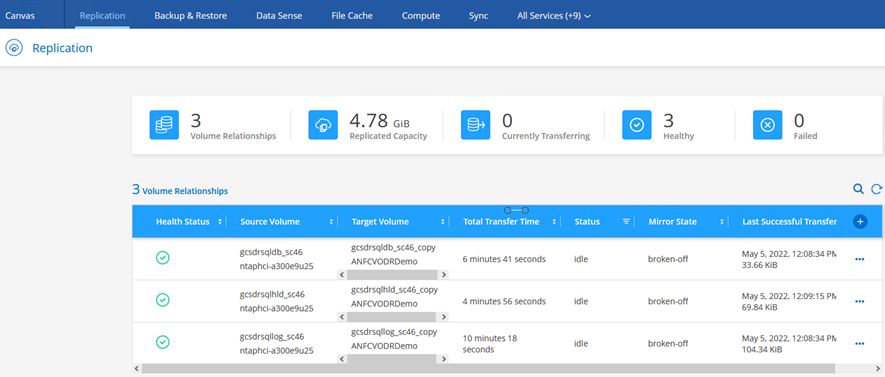
-
Anexe o LUN do Cloud Volumes ONTAP à VM convidada do SQL recuperada com as mesmas letras de unidade.
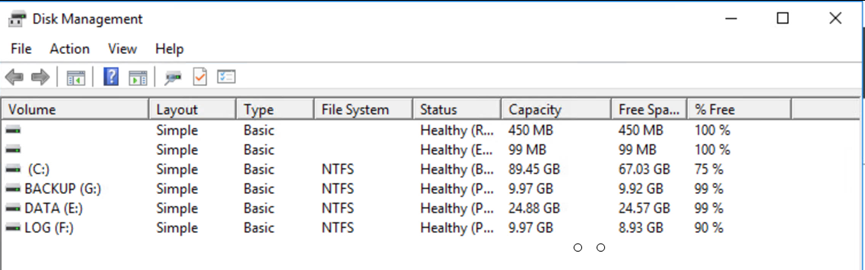
-
Abra o iSCSI Initiator, limpe a sessão desconectada anterior e adicione o novo destino junto com o multipath para os volumes Cloud Volumes ONTAP replicados.
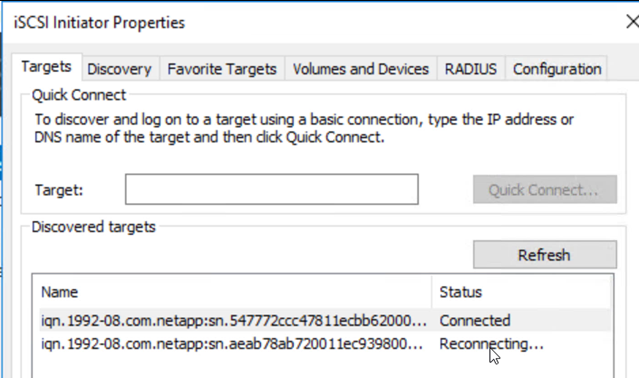
-
Certifique-se de que todos os discos estejam conectados usando as mesmas letras de unidade que eram usadas antes do DR.
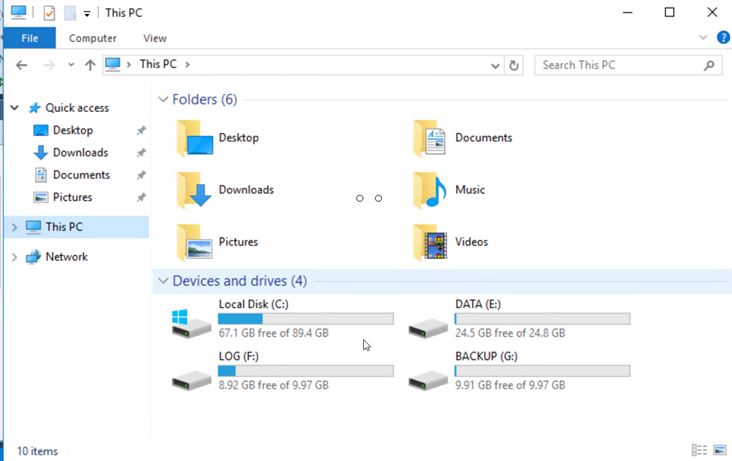
-
Reinicie o serviço do servidor MSSQL.
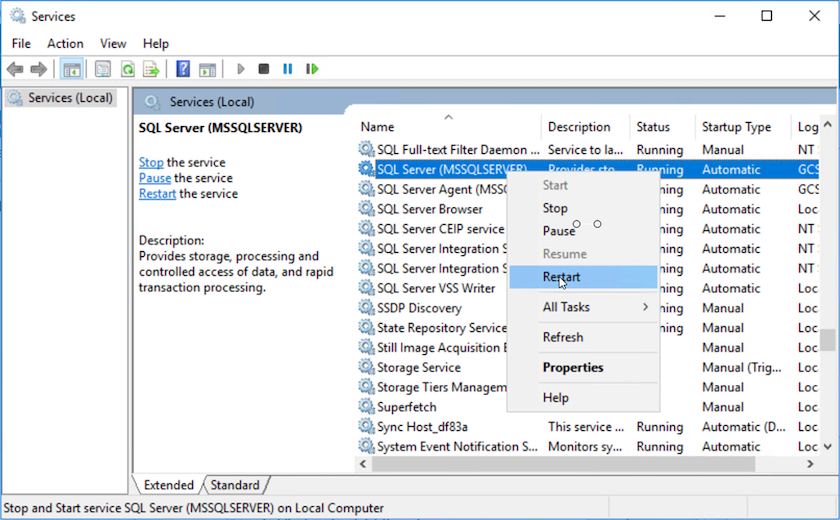
-
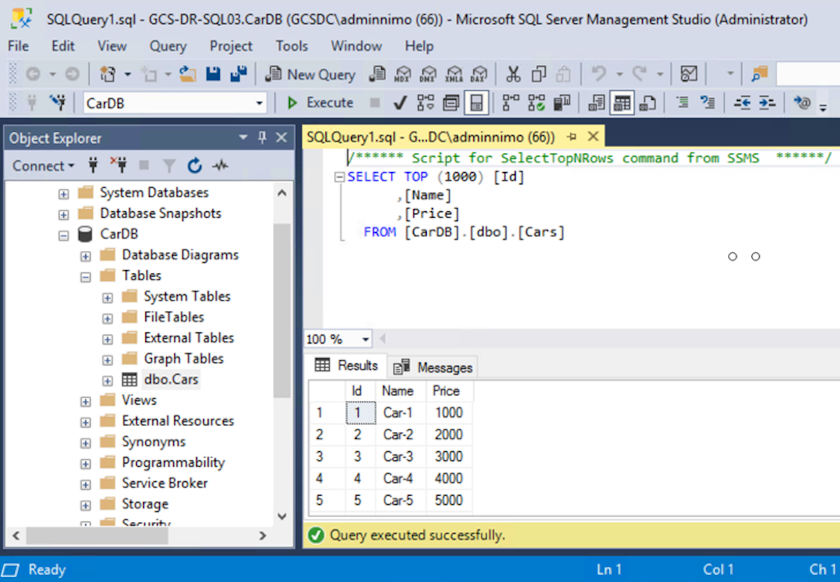
Certifique-se de que os recursos SQL estejam online novamente.
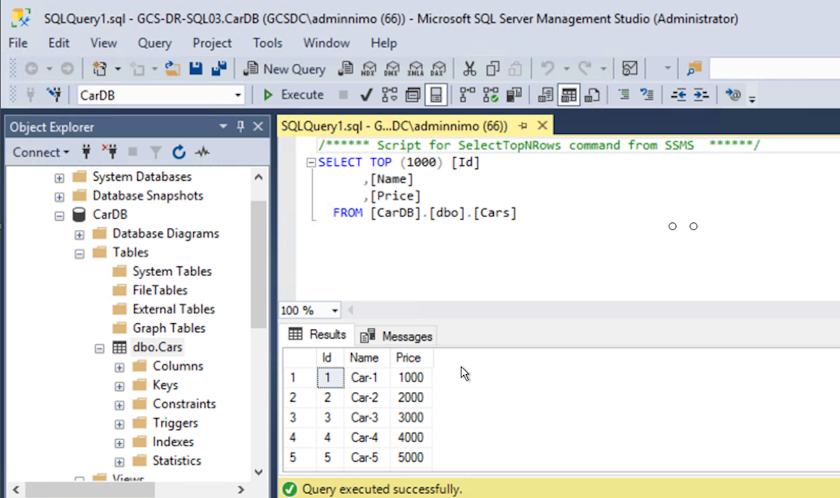
No caso do NFS, anexe os volumes usando o comando mount e atualize o /etc/fstabentradas.Neste ponto, as operações podem ser executadas e os negócios continuam normalmente.
No final do NSX-T, um gateway de nível 1 dedicado separado pode ser criado para simular cenários de failover. Isso garante que todas as cargas de trabalho possam se comunicar entre si, mas que nenhum tráfego possa entrar ou sair do ambiente, de modo que qualquer tarefa de triagem, contenção ou proteção possa ser executada sem risco de contaminação cruzada. Esta operação está fora do escopo deste documento, mas pode ser facilmente realizada para simular isolamento.
Depois que o site principal estiver funcionando novamente, você poderá executar o failback. A proteção da VM é retomada pelo Jetstream e o relacionamento do SnapMirror deve ser revertido.
-
Restaure o ambiente local. Dependendo do tipo de incidente de desastre, pode ser necessário restaurar e/ou verificar a configuração do cluster protegido. Se necessário, o software JetStream DR pode precisar ser reinstalado.
-
Acesse o ambiente local restaurado, vá para a interface do usuário do Jetstream DR e selecione o domínio protegido apropriado. Depois que o site protegido estiver pronto para failback, selecione a opção Failback na interface do usuário.
O plano de failback gerado pelo CPT também pode ser usado para iniciar o retorno das VMs e seus dados do armazenamento de objetos para o ambiente VMware original. 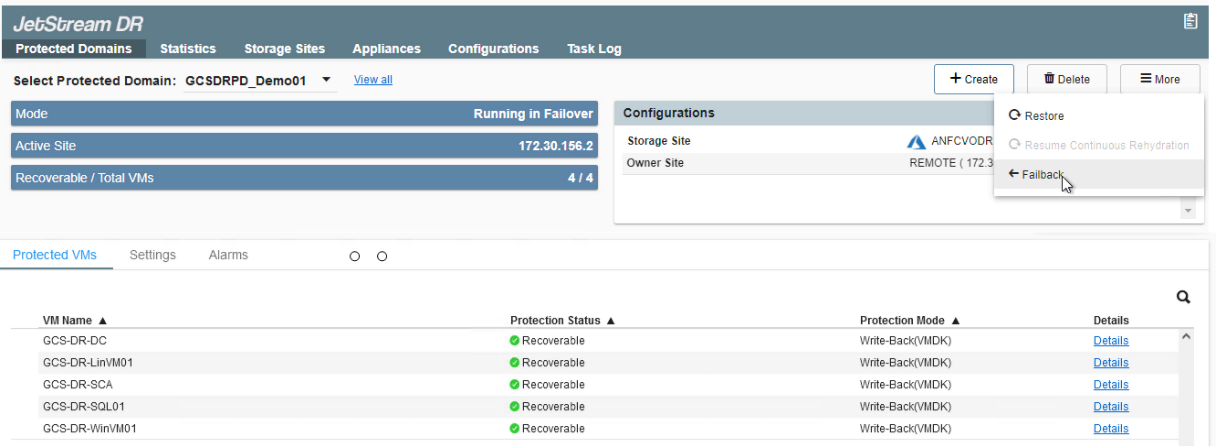
Especifique o atraso máximo após pausar as VMs no site de recuperação e reiniciá-las no site protegido. O tempo necessário para concluir esse processo inclui a conclusão da replicação após interromper as VMs de failover, o tempo necessário para limpar o site de recuperação e o tempo necessário para recriar as VMs no site protegido. A NetApp recomenda 10 minutos. 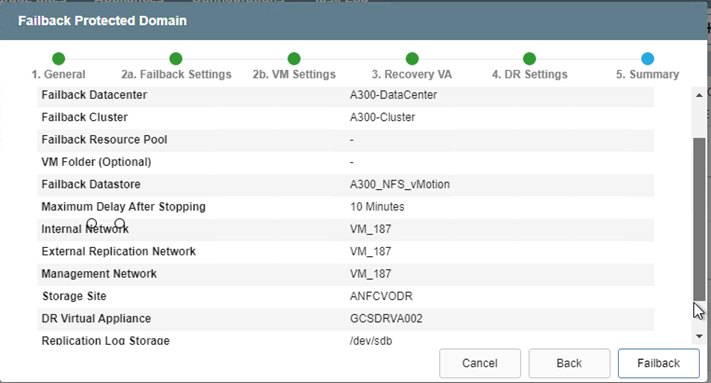
-
Conclua o processo de failback e confirme a retomada da proteção da VM e da consistência dos dados.
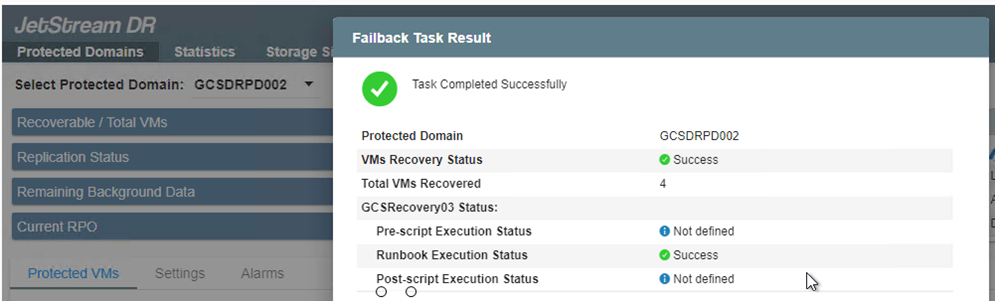
-
Depois que as VMs forem recuperadas, desconecte o armazenamento secundário do host e conecte-o ao armazenamento primário.
-
Reinicie o serviço do servidor MSSQL.
-
Verifique se os recursos SQL estão online novamente.
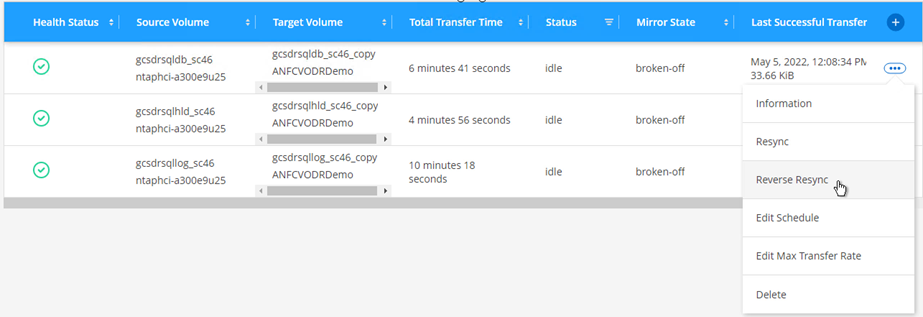
Para fazer failback para o armazenamento primário, certifique-se de que a direção do relacionamento permaneça a mesma de antes do failover, executando uma operação de ressincronização reversa.
Para manter as funções de armazenamento primário e secundário após a operação de ressincronização reversa, execute a operação de ressincronização reversa novamente.
Esse processo é aplicável a outros aplicativos como Oracle, bancos de dados semelhantes e quaisquer outros aplicativos que usem armazenamento conectado a convidados.
Como sempre, teste as etapas envolvidas para recuperar as cargas de trabalho críticas antes de portá-las para produção.
Benefícios desta solução
-
Utiliza a replicação eficiente e resiliente do SnapMirror.
-
Recupera para quaisquer pontos disponíveis no tempo com retenção de instantâneos ONTAP .
-
A automação completa está disponível para todas as etapas necessárias para recuperar centenas a milhares de VMs, desde as etapas de armazenamento, computação, rede e validação de aplicativos.
-
O SnapCenter usa mecanismos de clonagem que não alteram o volume replicado.
-
Isso evita o risco de corrupção de dados para volumes e instantâneos.
-
Evita interrupções de replicação durante fluxos de trabalho de teste de DR.
-
Aproveita os dados de DR para fluxos de trabalho além de DR, como desenvolvimento/teste, testes de segurança, testes de patch e atualização e testes de remediação.
-
-
A otimização da CPU e da RAM pode ajudar a reduzir os custos da nuvem ao permitir a recuperação para clusters de computação menores.