

Fluxo de trabalho de recuperação de desastres
 Sugerir alterações
Sugerir alterações
As empresas adotaram a nuvem pública como um recurso viável e destino para recuperação de desastres. O SnapCenter torna esse processo o mais simples possível. Este fluxo de trabalho de recuperação de desastres é muito semelhante ao fluxo de trabalho de clone, mas a recuperação do banco de dados é executada no último log disponível que foi replicado na nuvem para recuperar todas as transações comerciais possíveis. No entanto, há etapas adicionais de pré-configuração e pós-configuração específicas para recuperação de desastres.
Clonar um banco de dados de produção Oracle local para a nuvem para recuperação de desastres
-
Para validar se a recuperação do clone é executada pelo último log disponível, criamos uma pequena tabela de teste e inserimos uma linha. Os dados de teste seriam recuperados após uma recuperação completa do último log disponível.
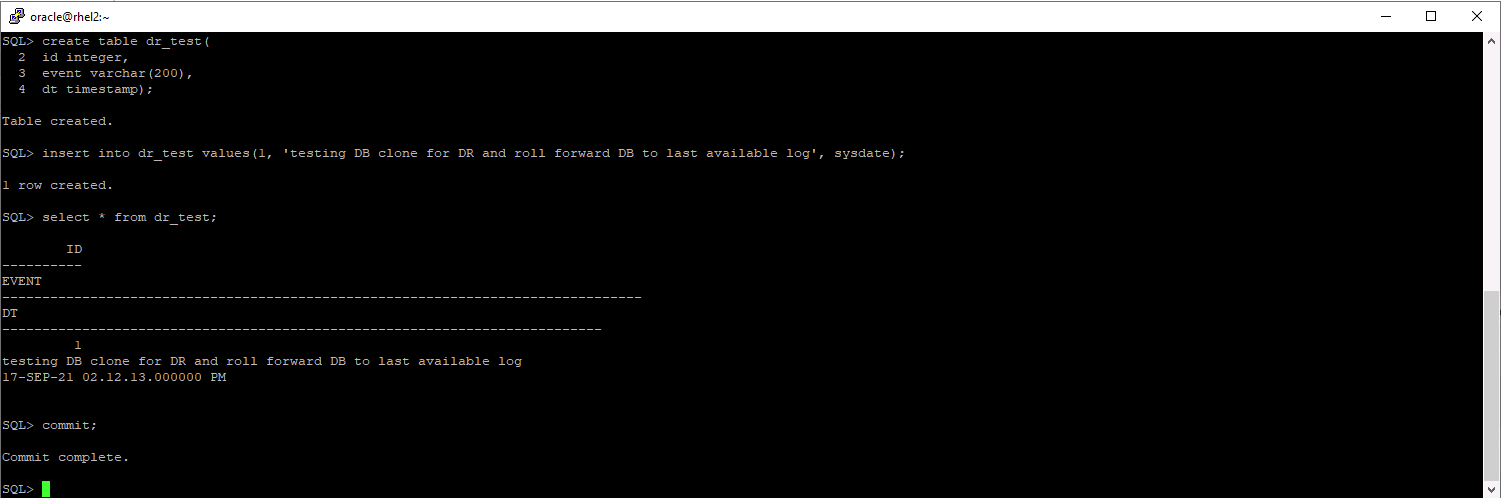
-
Efetue login no SnapCenter como um ID de usuário de gerenciamento de banco de dados do Oracle. Navegue até a guia Recursos, que mostra os bancos de dados Oracle sendo protegidos pelo SnapCenter.
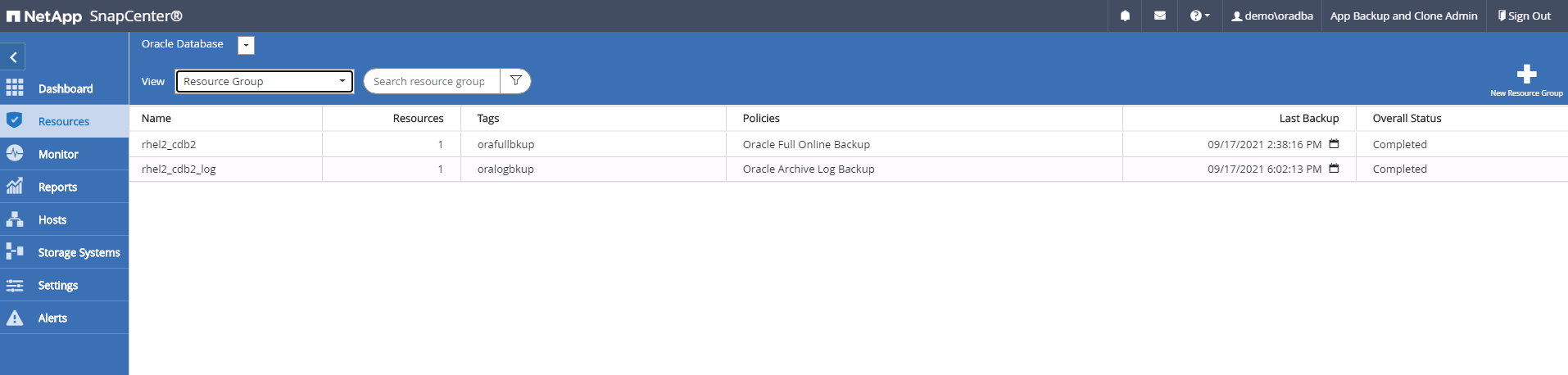
-
Selecione o grupo de recursos de log do Oracle e clique em Fazer backup agora para executar manualmente um backup de log do Oracle para liberar a transação mais recente para o destino na nuvem. Em um cenário de DR real, a última transação recuperável depende da frequência de replicação do volume de log do banco de dados para a nuvem, que por sua vez depende da política de RTO ou RPO da empresa.
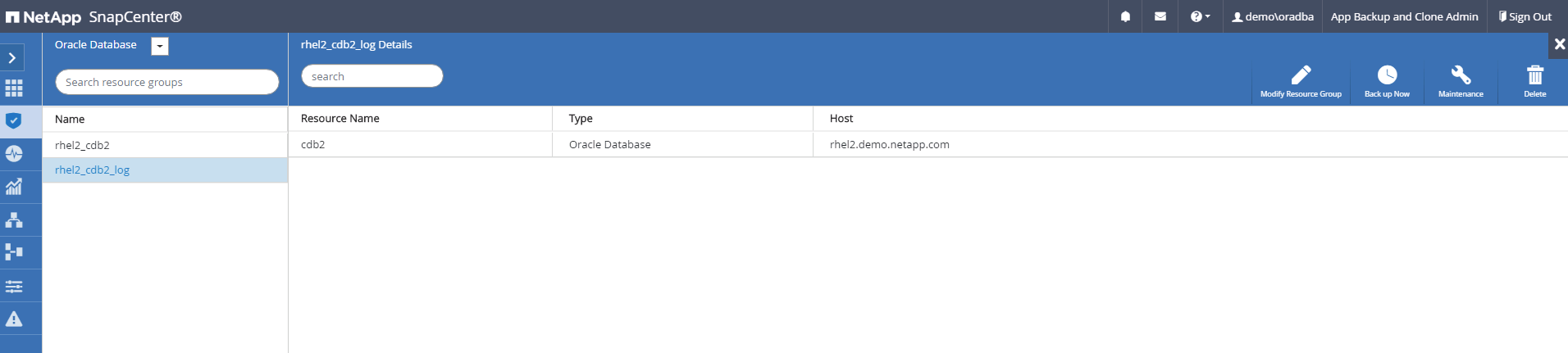
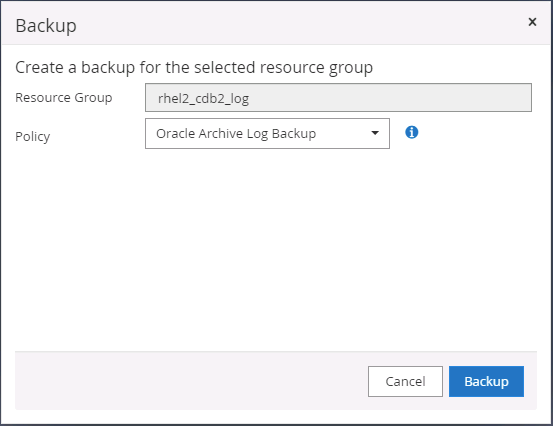

O SnapMirror assíncrono perde dados que não chegaram ao destino na nuvem no intervalo de backup do log do banco de dados em um cenário de recuperação de desastre. Para minimizar a perda de dados, é possível agendar backups de log mais frequentes. No entanto, há um limite para a frequência de backup de log que é tecnicamente possível. -
Selecione o último backup de log no(s) Backup(s) de Espelho Secundário e monte o backup de log.
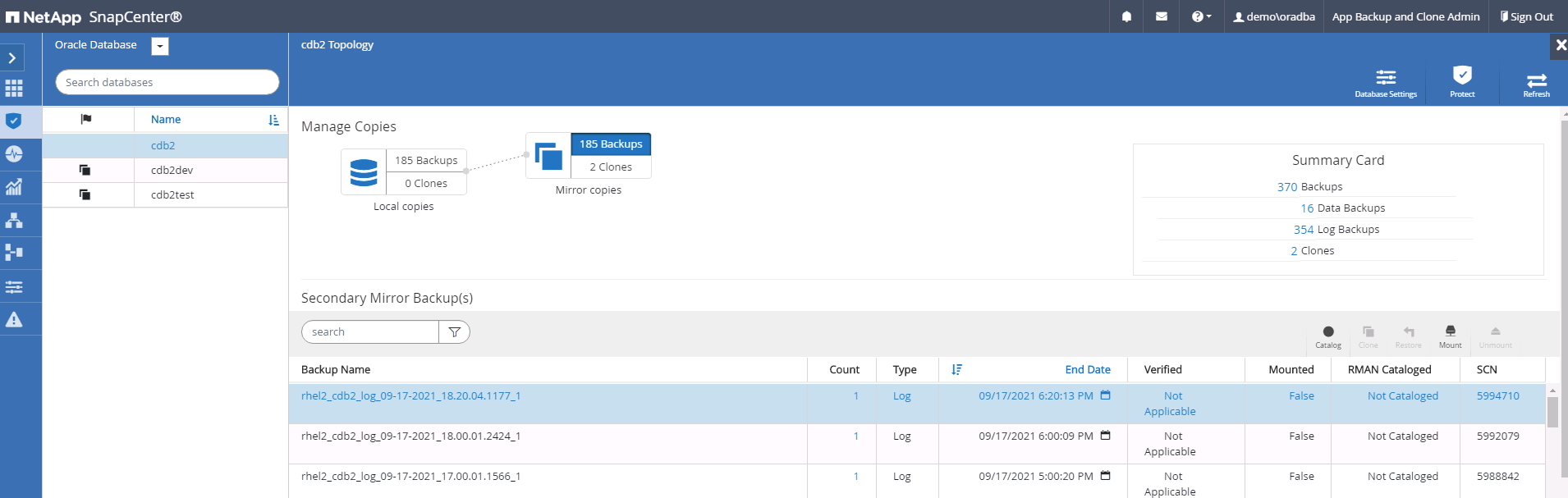
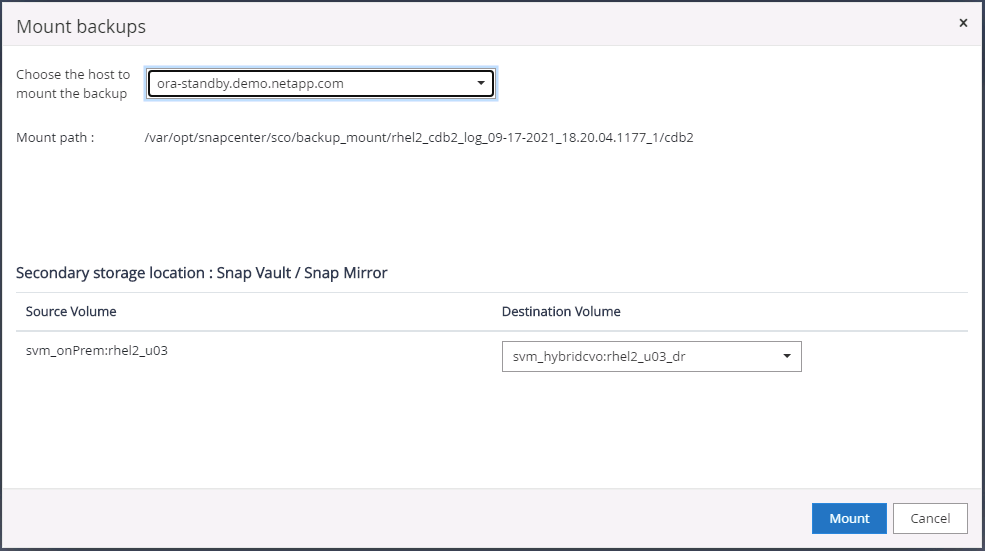
-
Selecione o último backup completo do banco de dados e clique em Clonar para iniciar o fluxo de trabalho de clonagem.
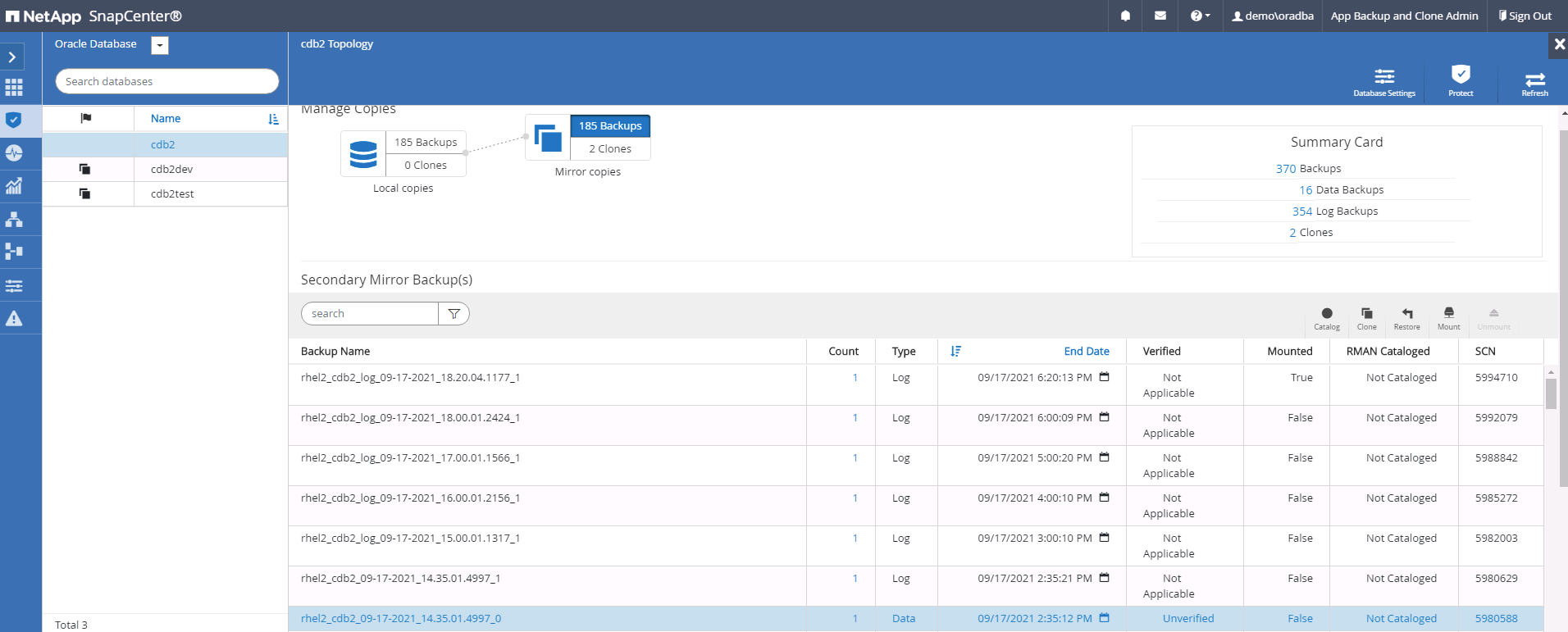
-
Selecione um ID de banco de dados clone exclusivo no host.
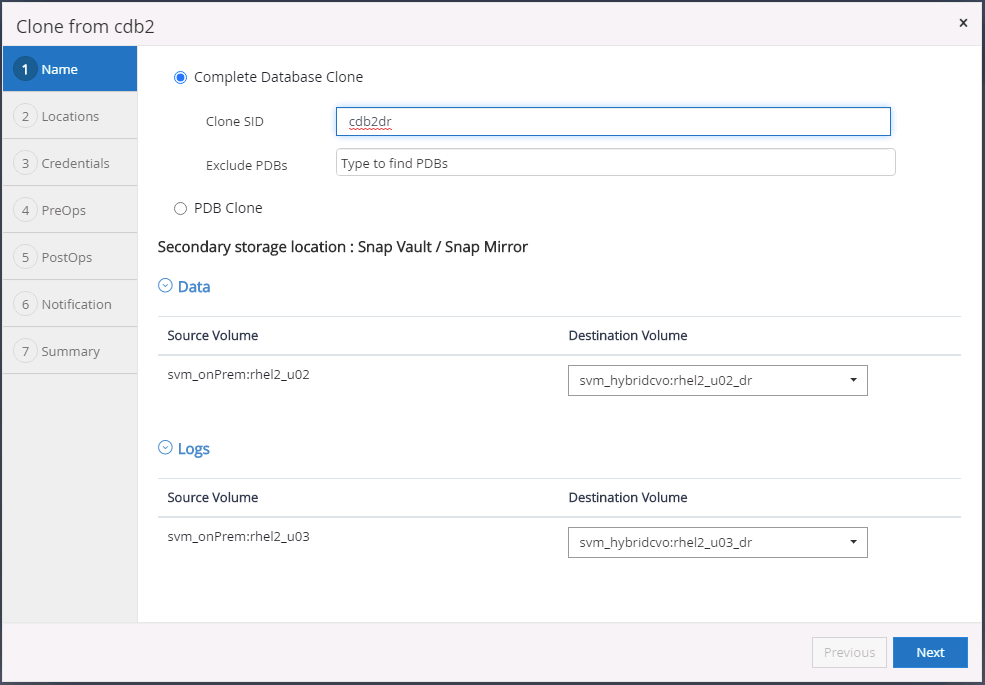
-
Provisione um volume de log e monte-o no servidor DR de destino para a área de recuperação flash do Oracle e logs on-line.
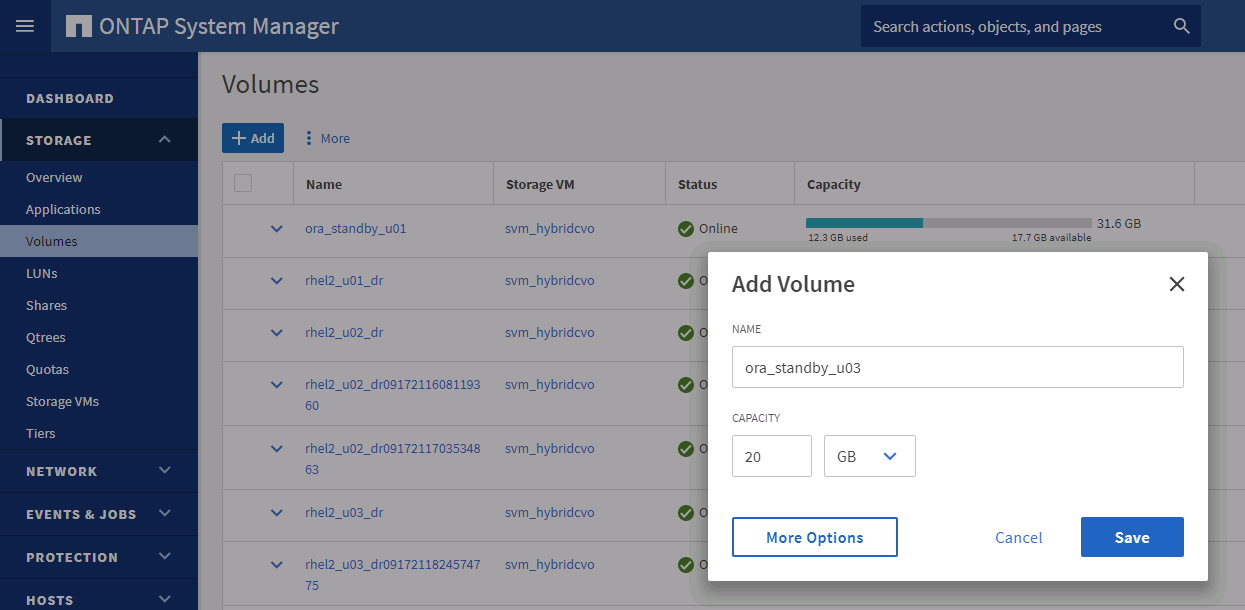
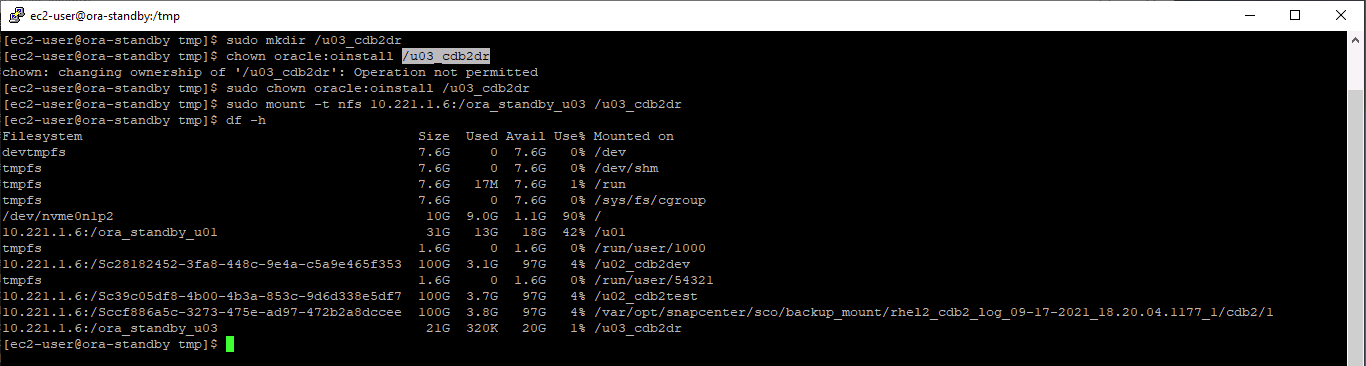
O procedimento de clonagem do Oracle não cria um volume de log, que precisa ser provisionado no servidor DR antes da clonagem. -
Selecione o host do clone de destino e o local para colocar os arquivos de dados, arquivos de controle e logs de refazer.
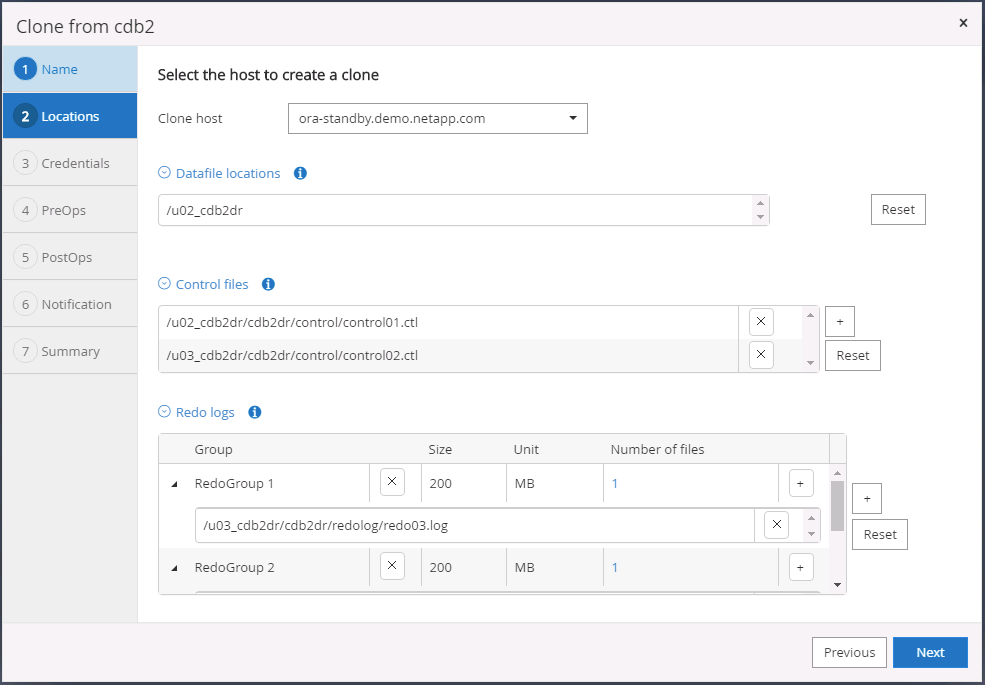
-
Selecione as credenciais para o clone. Preencha os detalhes da configuração inicial do Oracle no servidor de destino.
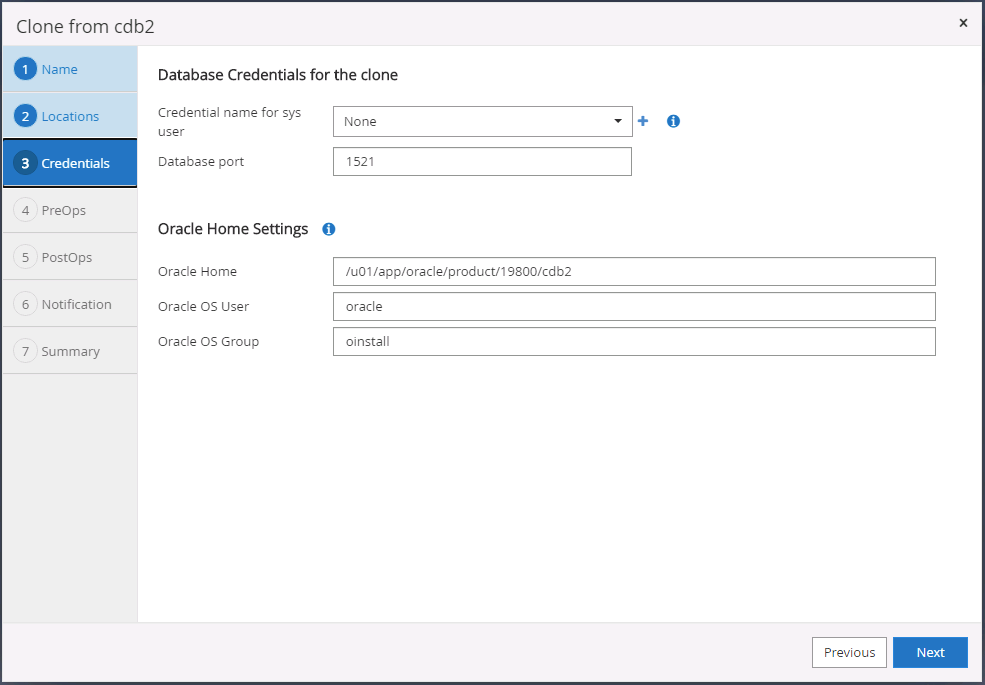
-
Especifique os scripts a serem executados antes da clonagem. Os parâmetros do banco de dados podem ser ajustados, se necessário.
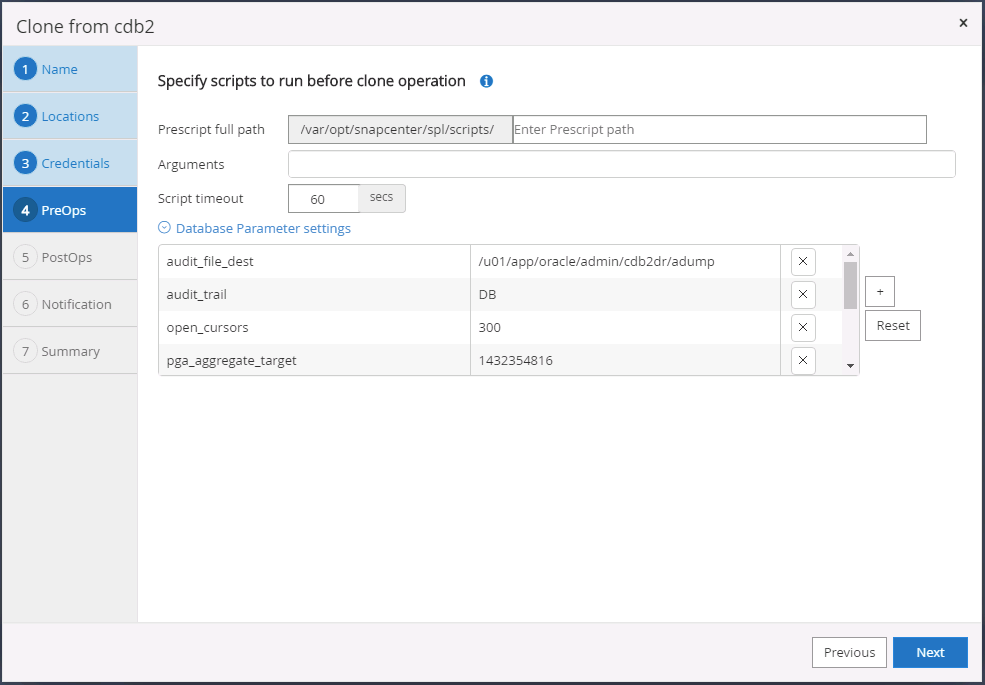
-
Selecione Até Cancelar como a opção de recuperação para que a recuperação seja executada em todos os logs de arquivamento disponíveis para recuperar a última transação replicada no local da nuvem secundária.
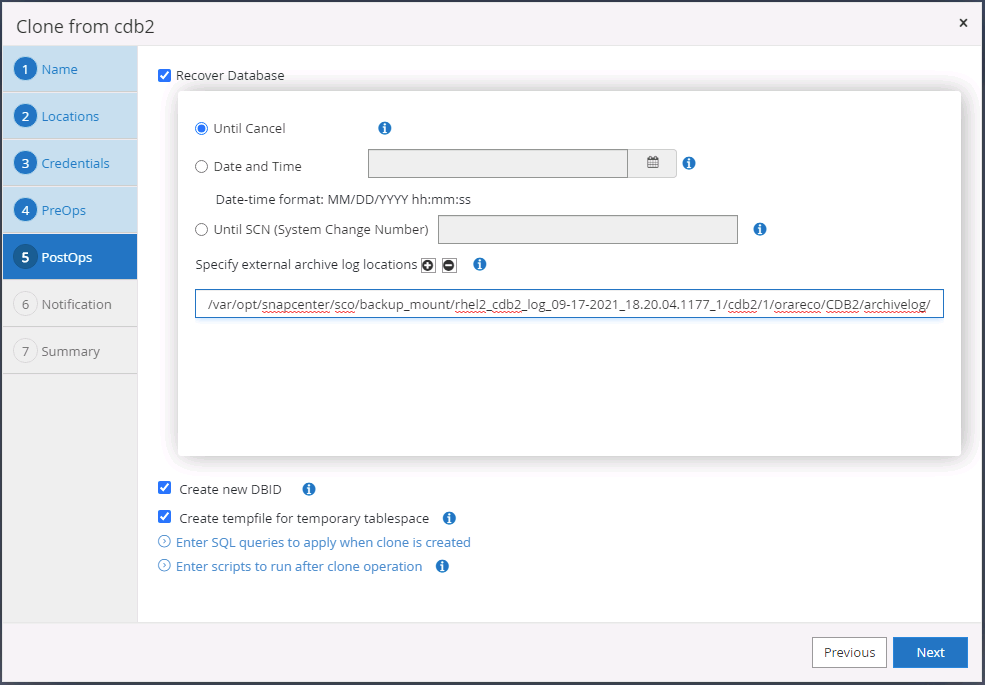
-
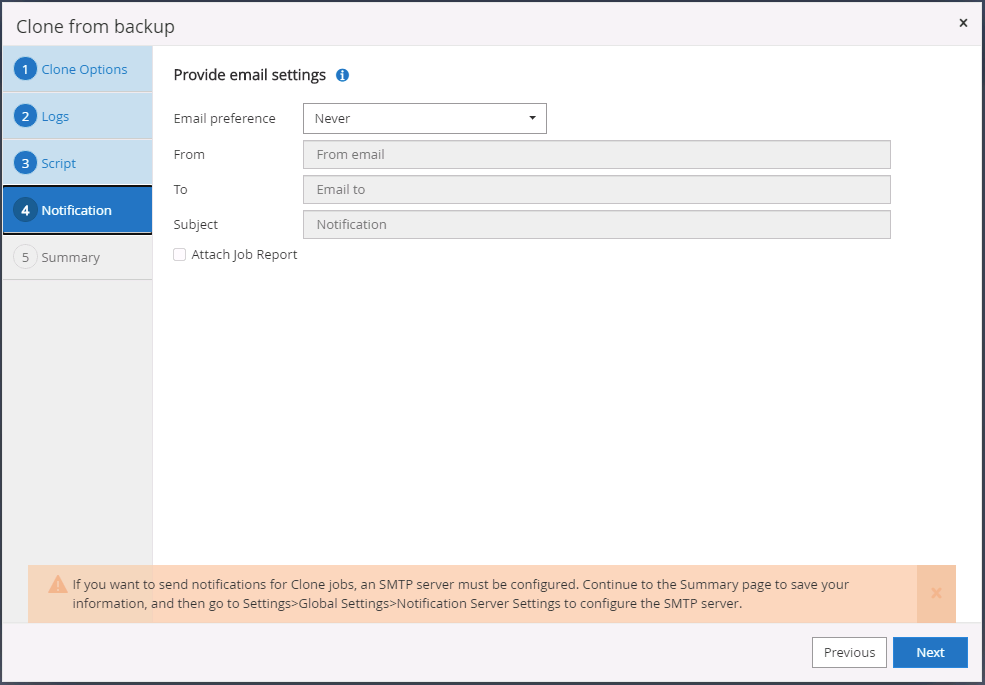
Configure o servidor SMTP para notificação por email, se necessário.
-
Resumo do clone DR.
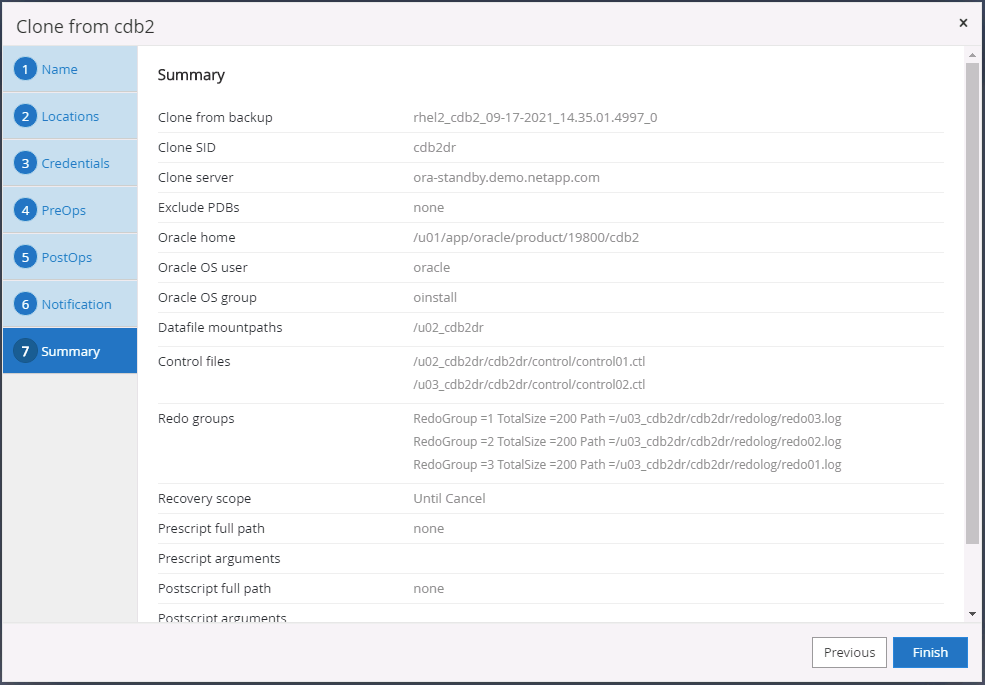
-
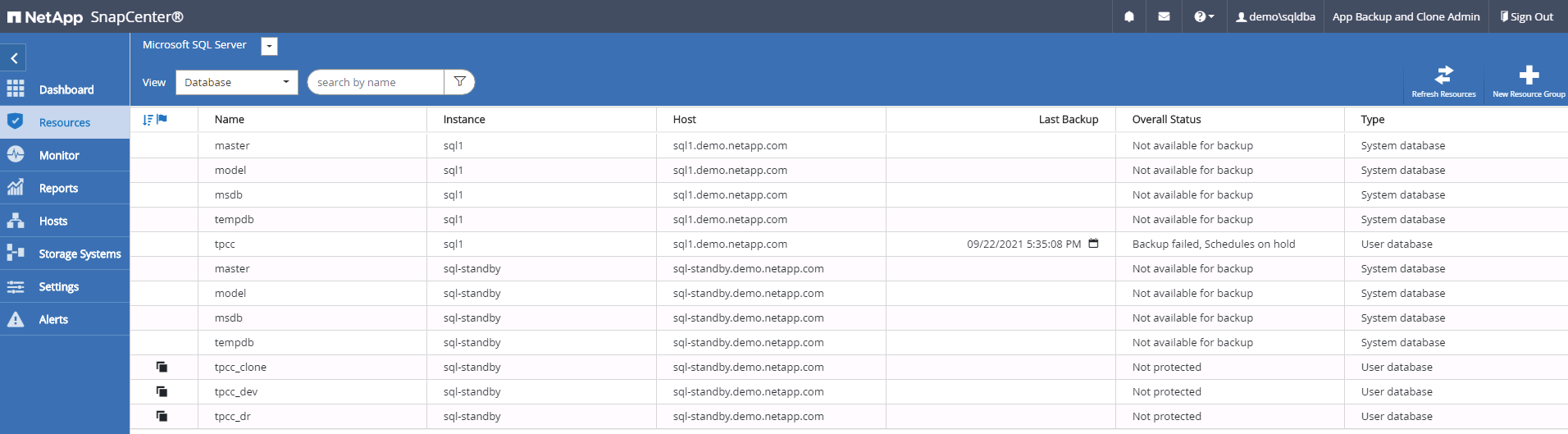
Os bancos de dados clonados são registrados no SnapCenter imediatamente após a conclusão da clonagem e ficam então disponíveis para proteção de backup.
Validação e configuração de clone pós-DR para Oracle
-
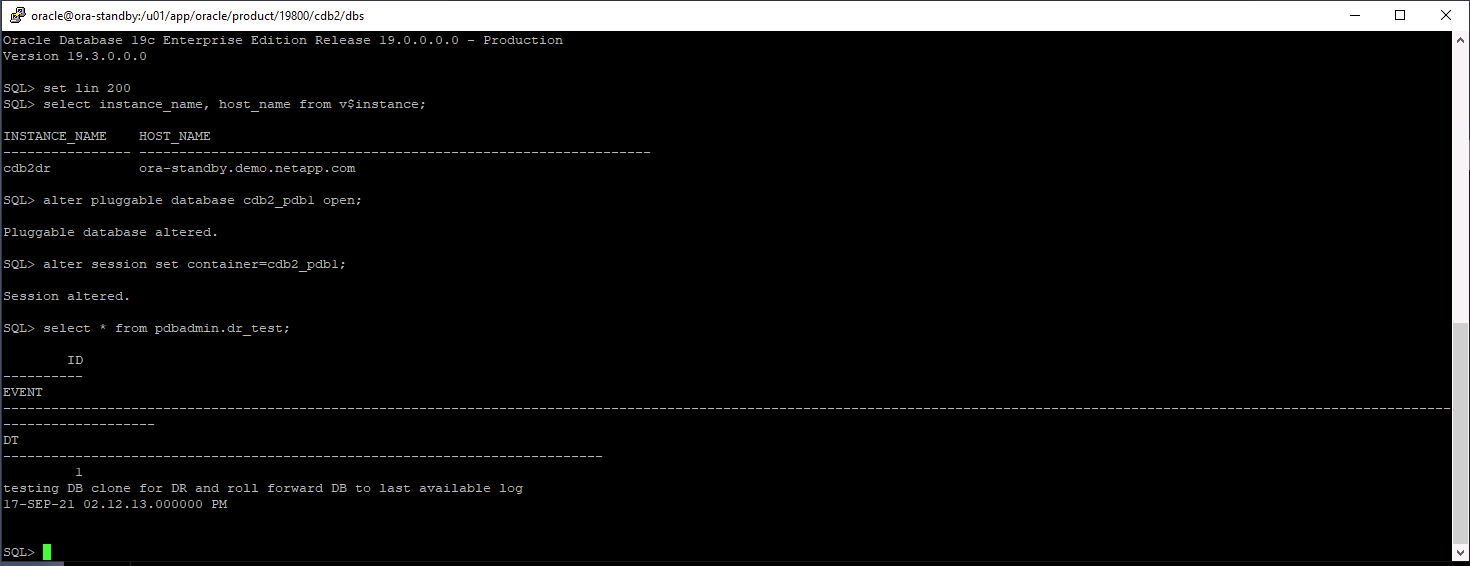
Valide a última transação de teste que foi liberada, replicada e recuperada no local de DR na nuvem.
-
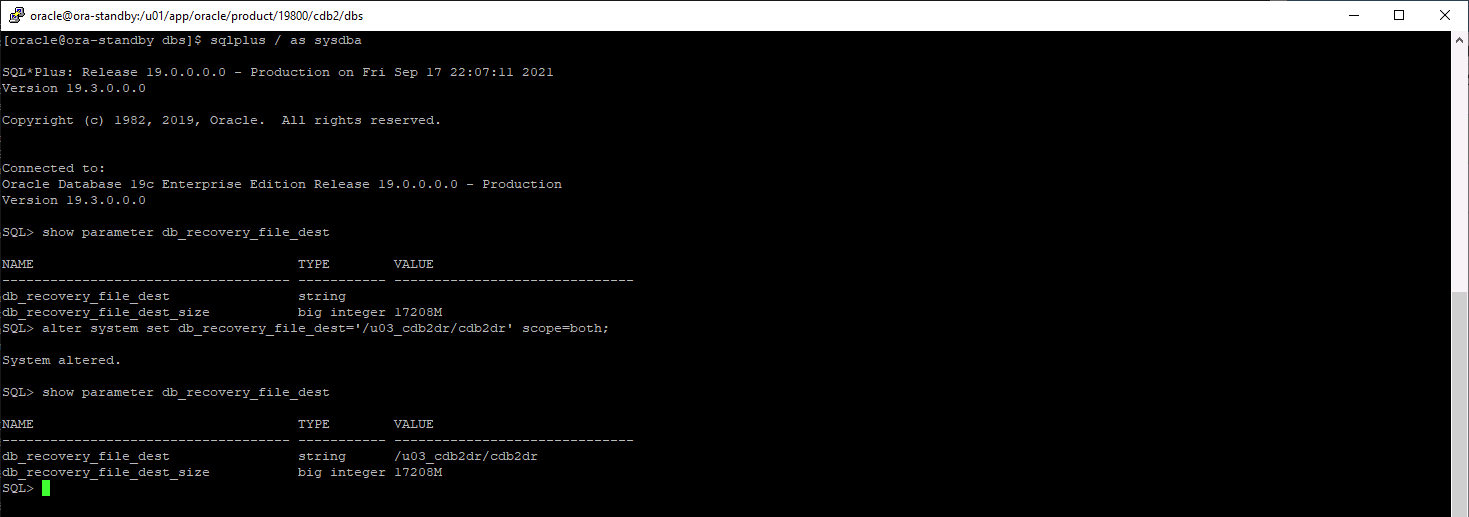
Configure a área de recuperação do flash.
-
Configure o ouvinte Oracle para acesso do usuário.
-
Divida o volume clonado do volume de origem replicado.
-
Reverta a replicação da nuvem para o local e reconstrua o servidor de banco de dados local com falha.
|
|
A divisão de clones pode incorrer em utilização temporária de espaço de armazenamento muito maior que a operação normal. No entanto, depois que o servidor de banco de dados local for reconstruído, espaço extra poderá ser liberado. |
Clonar um banco de dados de produção SQL local para a nuvem para recuperação de desastres
-
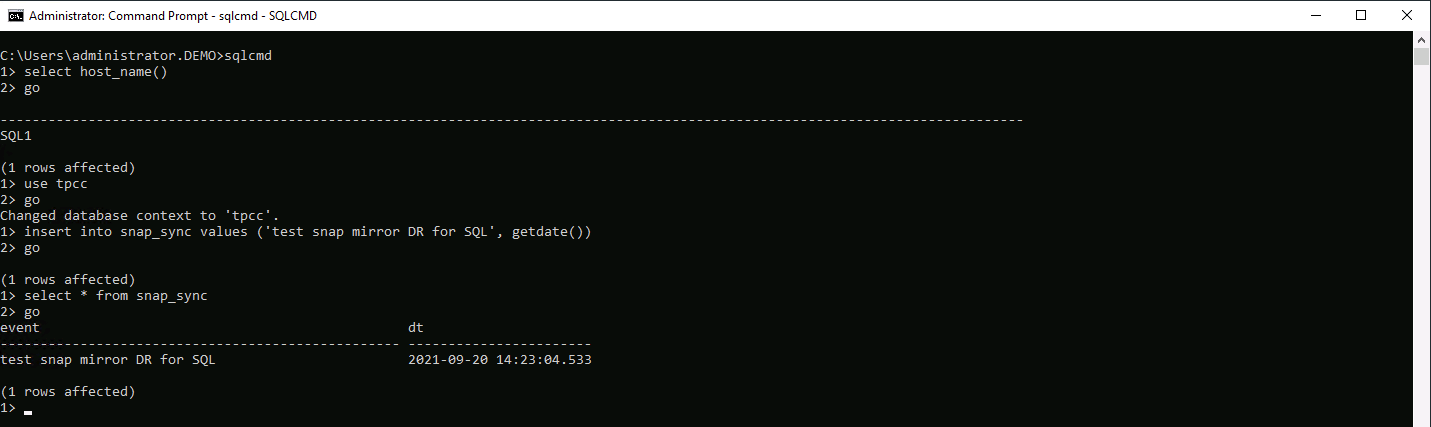
Da mesma forma, para validar se a recuperação do clone SQL foi executada no último log disponível, criamos uma pequena tabela de teste e inserimos uma linha. Os dados de teste seriam recuperados após uma recuperação completa do último log disponível.
-
Efetue login no SnapCenter com uma ID de usuário de gerenciamento de banco de dados do SQL Server. Navegue até a guia Recursos, que mostra o grupo de recursos de proteção do SQL Server.

-
Execute manualmente um backup de log para liberar a última transação a ser replicada no armazenamento secundário na nuvem pública.
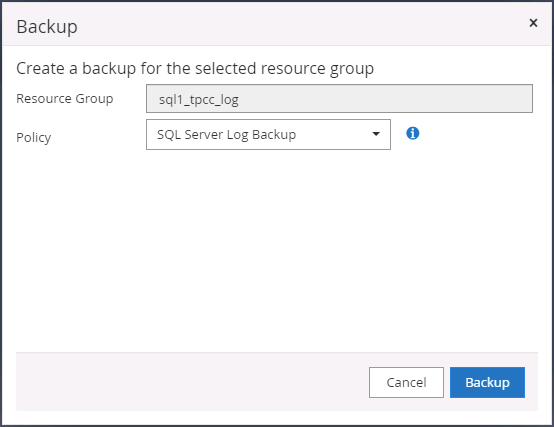
-
Selecione o último backup completo do SQL Server para o clone.
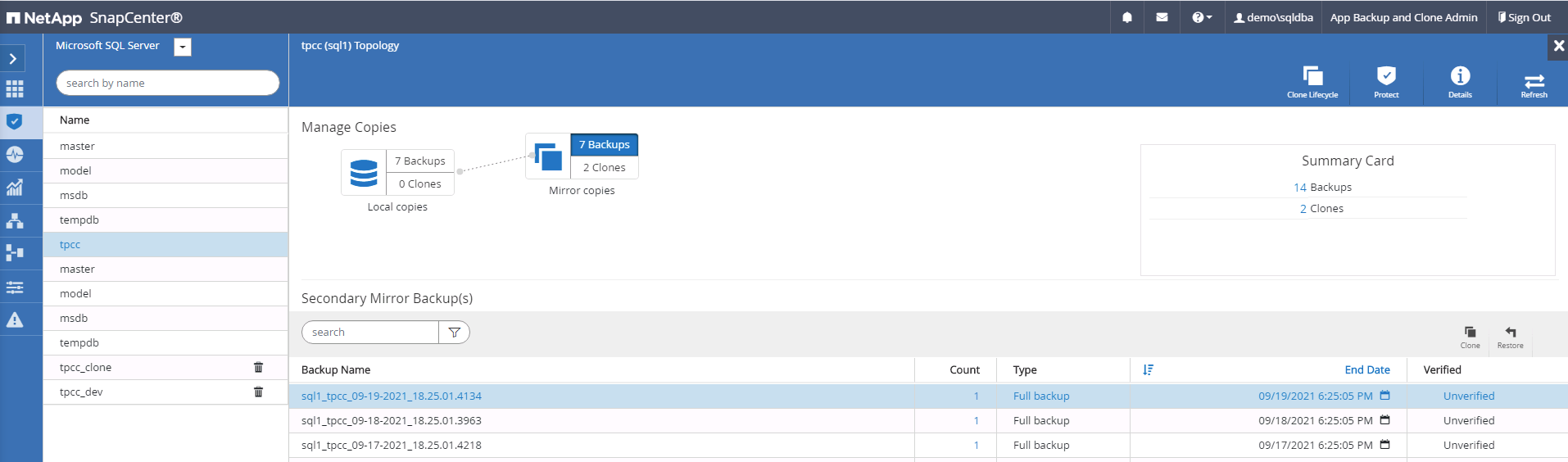
-
Defina as configurações de clone, como Servidor clone, Instância clone, Nome clone e opção de montagem. O local de armazenamento secundário onde a clonagem é realizada é preenchido automaticamente.
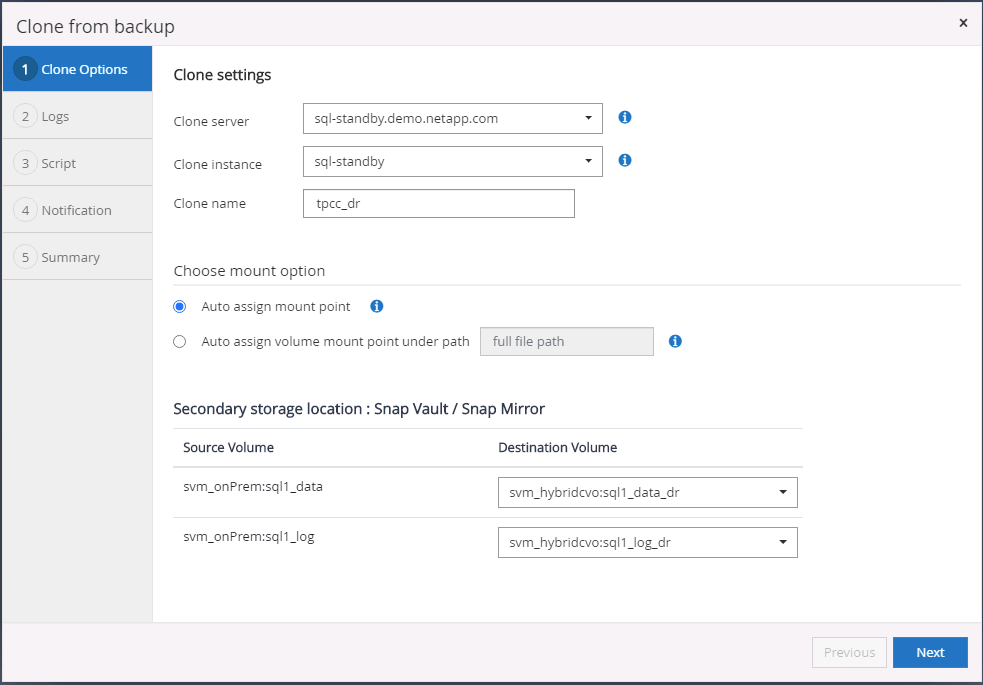
-
Selecione todos os backups de log a serem aplicados.
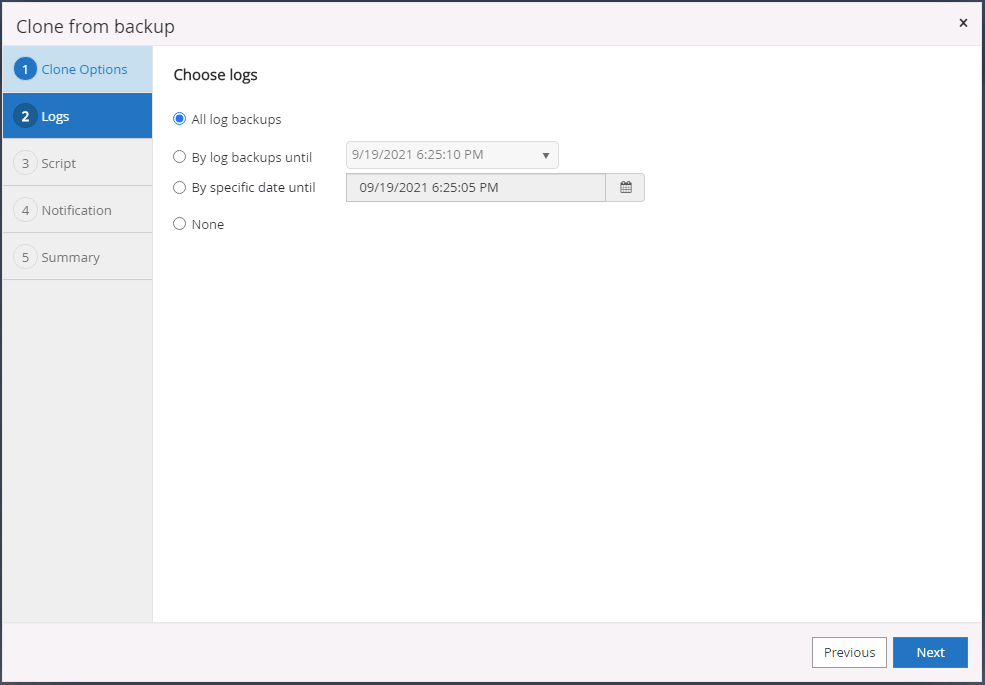
-
Especifique quaisquer scripts opcionais a serem executados antes ou depois da clonagem.
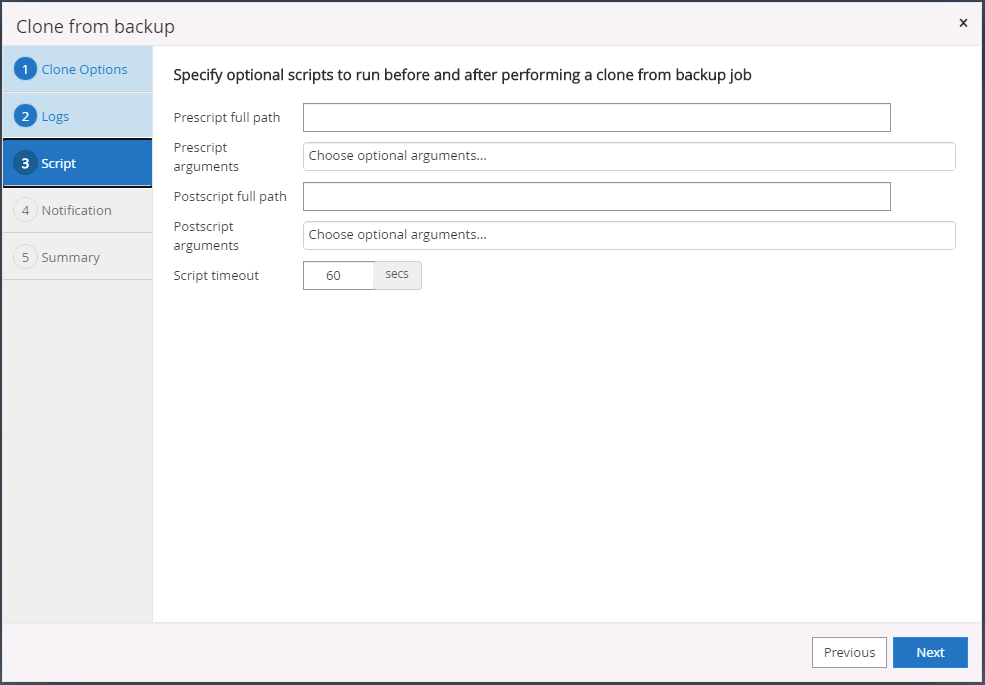
-
Especifique um servidor SMTP se desejar receber notificação por e-mail.
-
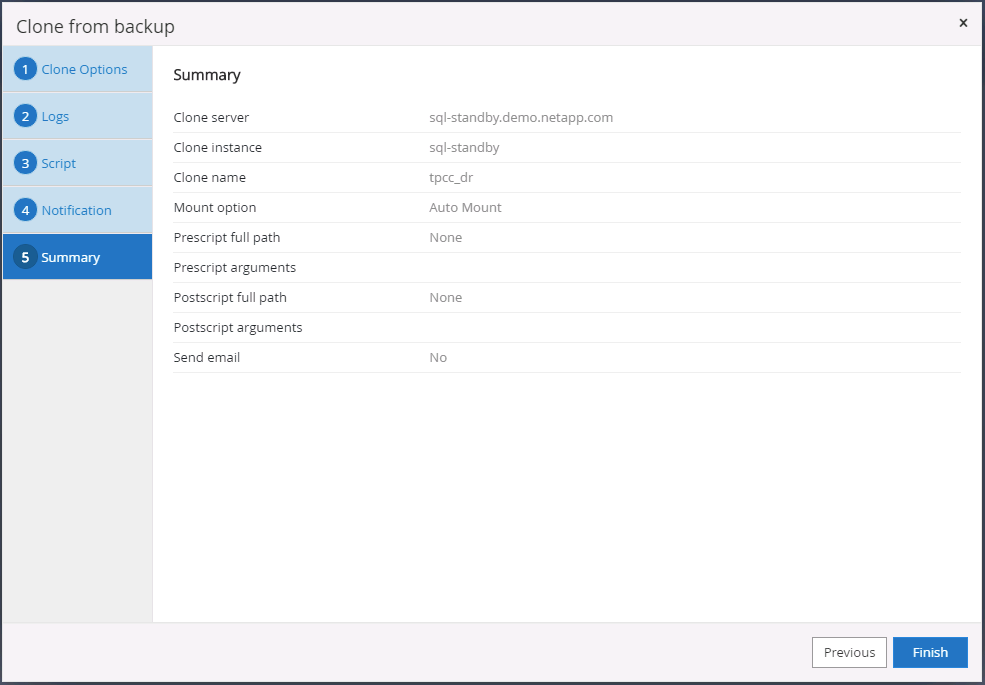
Resumo do clone DR. Bancos de dados clonados são imediatamente registrados no SnapCenter e ficam disponíveis para proteção de backup.
Validação e configuração do clone pós-DR para SQL
-
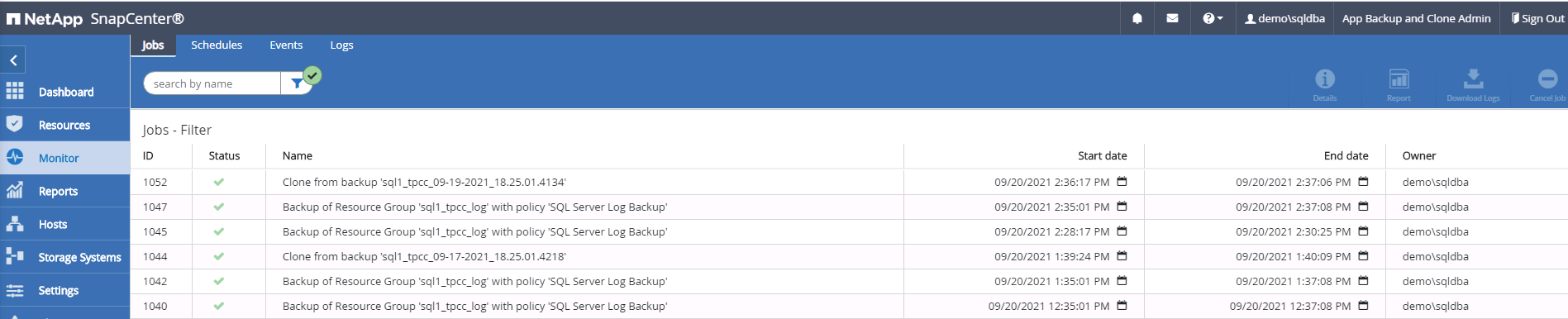
Monitore o status do trabalho de clonagem.
-
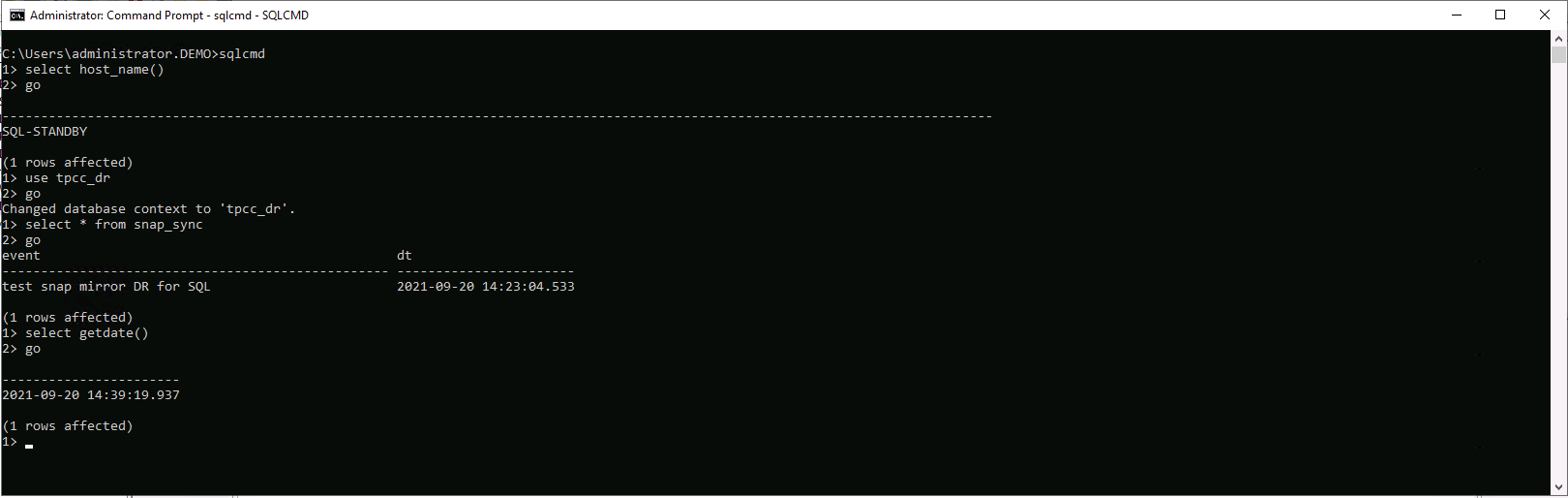
Valide se a última transação foi replicada e recuperada com todos os clones de arquivos de log e recuperação.
-
Configure um novo diretório de log do SnapCenter no servidor DR para backup de log do SQL Server.
-
Divida o volume clonado do volume de origem replicado.
-
Reverta a replicação da nuvem para o local e reconstrua o servidor de banco de dados local com falha.
Onde procurar ajuda?
Se precisar de ajuda com esta solução e casos de uso, junte-se a nós"Canal do Slack de suporte da comunidade de automação de soluções da NetApp" e procure o canal de automação de soluções para postar suas dúvidas ou perguntas.