

TR-4988: Backup, recuperação e clonagem do banco de dados Oracle no ANF com SnapCenter
 Sugerir alterações
Sugerir alterações
Allen Cao, Niyaz Mohamed, NetApp
Esta solução fornece uma visão geral e detalhes para implantação automatizada do Oracle no Microsoft Azure NetApp Files como armazenamento de banco de dados primário com protocolo NFS e o banco de dados Oracle é implantado como banco de dados de contêiner com dNFS habilitado. O banco de dados implantado no Azure é protegido usando a ferramenta SnapCenter UI para gerenciamento simplificado do banco de dados.
Propósito
O software NetApp SnapCenter software é uma plataforma empresarial fácil de usar para coordenar e gerenciar com segurança a proteção de dados em aplicativos, bancos de dados e sistemas de arquivos. Ele simplifica o gerenciamento do ciclo de vida de backup, restauração e clonagem, transferindo essas tarefas para os proprietários dos aplicativos sem sacrificar a capacidade de supervisionar e regular a atividade nos sistemas de armazenamento. Ao aproveitar o gerenciamento de dados baseado em armazenamento, ele permite maior desempenho e disponibilidade, bem como tempos reduzidos de teste e desenvolvimento.
Em TR-4987,"Implantação simplificada e automatizada do Oracle no Azure NetApp Files com NFS" , demonstramos a implantação automatizada do Oracle no Azure NetApp Files (ANF) na nuvem do Azure. Nesta documentação, mostramos a proteção e o gerenciamento do banco de dados Oracle no ANF na nuvem do Azure com uma ferramenta de interface de usuário SnapCenter muito fácil de usar.
Esta solução aborda os seguintes casos de uso:
-
Backup e recuperação de banco de dados Oracle implantado no ANF na nuvem Azure com SnapCenter.
-
Gerencie instantâneos de banco de dados e clone cópias para acelerar o desenvolvimento de aplicativos e melhorar o gerenciamento do ciclo de vida dos dados.
Público
Esta solução é destinada às seguintes pessoas:
-
Um DBA que gostaria de implantar bancos de dados Oracle no Azure NetApp Files.
-
Um arquiteto de soluções de banco de dados que gostaria de testar cargas de trabalho Oracle no Azure NetApp Files.
-
Um administrador de armazenamento que gostaria de implantar e gerenciar bancos de dados Oracle no Azure NetApp Files.
-
Um proprietário de aplicativo que gostaria de configurar um banco de dados Oracle no Azure NetApp Files.
Ambiente de teste e validação de soluções
Os testes e a validação desta solução foram realizados em um ambiente de laboratório que pode não corresponder ao ambiente de implantação final. Veja a seçãoFatores-chave para consideração de implantação para maiores informações.
Arquitetura
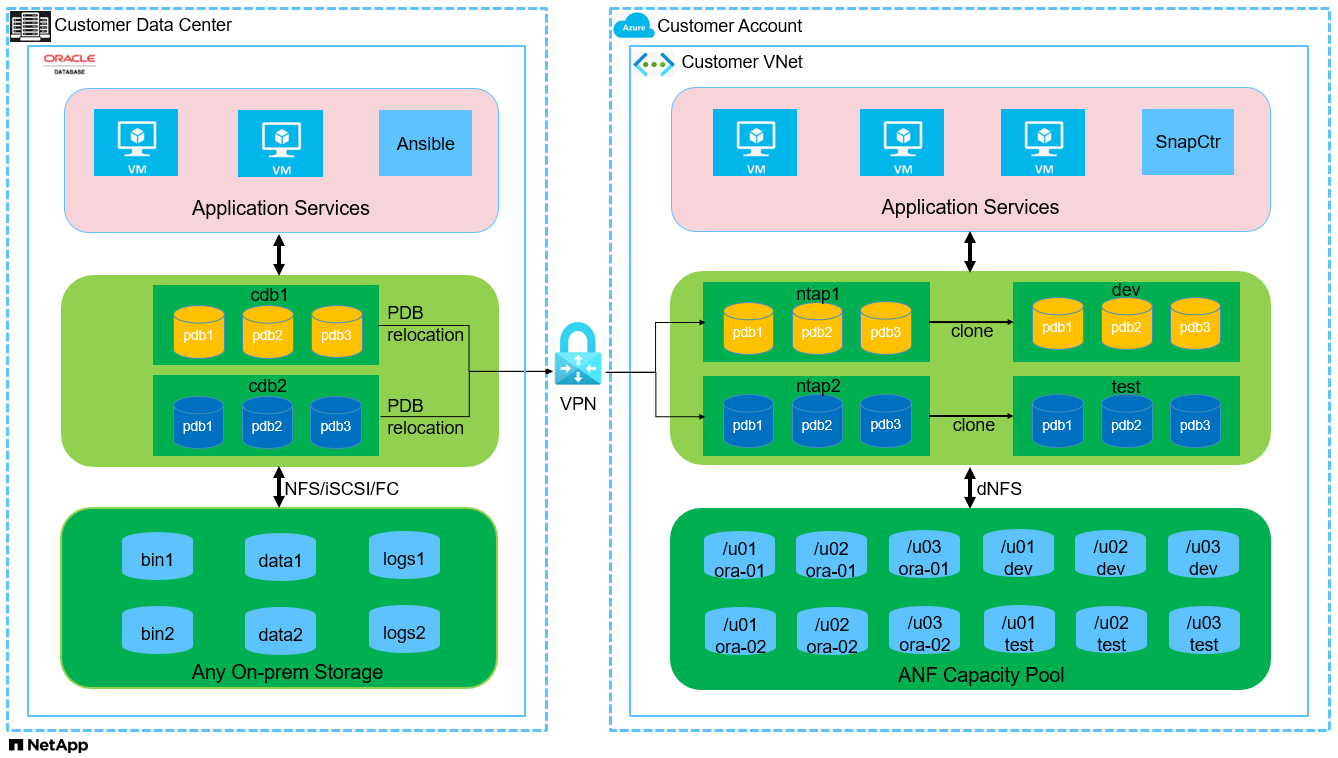
Componentes de hardware e software
Hardware |
||
Azure NetApp Files |
Oferta atual no Azure pela Microsoft |
Um pool de capacidade com nível de serviço Premium |
VM do Azure para servidor de banco de dados |
Standard_B4ms - 4 vCPUs, 16 GiB |
Duas instâncias de máquina virtual Linux |
VM do Azure para SnapCenter |
Standard_B4ms - 4 vCPUs, 16 GiB |
Uma instância de máquina virtual do Windows |
Software |
||
RedHat Linux |
RHEL Linux 8.6 (LVM) - x64 Gen2 |
Assinatura RedHat implantada para teste |
Servidor Windows |
DataCenter 2022; AE Hotpatch - x64 Gen2 |
Hospedagem do servidor SnapCenter |
Banco de Dados Oracle |
Versão 19.18 |
Patch p34765931_190000_Linux-x86-64.zip |
Oracle OPatch |
Versão 12.2.0.1.36 |
Patch p6880880_190000_Linux-x86-64.zip |
Servidor SnapCenter |
Versão 5.0 |
Implantação de grupo de trabalho |
Abra o JDK |
Versão java-11-openjdk |
Requisito do plugin SnapCenter em VMs de banco de dados |
NFS |
Versão 3.0 |
Oracle dNFS habilitado |
Ansible |
núcleo 2.16.2 |
Python 3.6.8 |
Configuração do banco de dados Oracle no ambiente de laboratório
Servidor |
Banco de dados |
Armazenamento de banco de dados |
ora-01 |
NTAP1(NTAP1_PDB1,NTAP1_PDB2,NTAP1_PDB3) |
/u01, /u02, /u03 NFS monta no pool de capacidade ANF |
ora-02 |
NTAP2(NTAP2_PDB1,NTAP2_PDB2,NTAP2_PDB3) |
/u01, /u02, /u03 NFS monta no pool de capacidade ANF |
Fatores-chave para consideração de implantação
-
* Implantação do SnapCenter .* O SnapCenter pode ser implantado em um domínio do Windows ou em um ambiente de grupo de trabalho. Para implantação baseada em domínio, a conta de usuário do domínio deve ser uma conta de administrador de domínio ou o usuário do domínio deve pertencer ao grupo de administradores locais no servidor de hospedagem do SnapCenter .
-
Resolução de nomes. O servidor SnapCenter precisa resolver o nome para o endereço IP de cada host do servidor de banco de dados de destino gerenciado. Cada host do servidor de banco de dados de destino deve resolver o nome do servidor SnapCenter para o endereço IP. Se um servidor DNS não estiver disponível, adicione nomes aos arquivos do host local para resolução.
-
Configuração do grupo de recursos. O grupo de recursos no SnapCenter é um agrupamento lógico de recursos semelhantes que podem ser copiados juntos. Dessa forma, simplifica e reduz o número de tarefas de backup em um ambiente de banco de dados grande.
-
Backup completo separado do banco de dados e do log de arquivo. O backup completo do banco de dados inclui volumes de dados e volumes de log com instantâneos de grupo consistentes. Um snapshot completo e frequente do banco de dados gera maior consumo de armazenamento, mas melhora o RTO. Uma alternativa é fazer snapshots completos do banco de dados com menos frequência e fazer backups de logs de arquivo com mais frequência, o que consome menos armazenamento e melhora o RPO, mas pode estender o RTO. Considere seus objetivos de RTO e RPO ao configurar o esquema de backup. Também há um limite (1023) do número de backups de instantâneos em um volume.
-
* Delegação de Privileges .* Aproveite o controle de acesso baseado em funções integrado à interface de usuário do SnapCenter para delegar privilégios às equipes de aplicativos e bancos de dados, se desejar.
Implantação da solução
As seções a seguir fornecem procedimentos passo a passo para implantação, configuração, backup, recuperação e clonagem do SnapCenter , além de banco de dados Oracle no Azure NetApp Files na nuvem do Azure.
Pré-requisitos para implantação
Details
A implantação requer bancos de dados Oracle existentes em execução no ANF no Azure. Caso contrário, siga as etapas abaixo para criar dois bancos de dados Oracle para validação da solução. Para obter detalhes sobre a implantação do banco de dados Oracle no ANF na nuvem Azure com automação, consulte TR-4987:"Implantação simplificada e automatizada do Oracle no Azure NetApp Files com NFS"
-
Uma conta do Azure foi configurada e os segmentos de VNet e rede necessários foram criados dentro da sua conta do Azure.
-
No portal de nuvem do Azure, implante VMs do Azure Linux como servidores Oracle DB. Crie um pool de capacidade do Azure NetApp Files e volumes de banco de dados para o banco de dados Oracle. Habilitar autenticação de chave pública/privada SSH da VM para o azureuser em servidores de banco de dados. Veja o diagrama de arquitetura na seção anterior para obter detalhes sobre a configuração do ambiente. Também referido como"Procedimentos passo a passo de implantação do Oracle no Azure VM e no Azure NetApp Files" para obter informações detalhadas.

Para VMs do Azure implantadas com redundância de disco local, certifique-se de ter alocado pelo menos 128 GB no disco raiz da VM para ter espaço suficiente para preparar os arquivos de instalação do Oracle e adicionar o arquivo de troca do sistema operacional. Expanda as partições do sistema operacional /tmplv e /rootlv adequadamente. Certifique-se de que a nomenclatura do volume do banco de dados siga a convenção VMname-u01, VMname-u02 e VMname-u03. sudo lvresize -r -L +20G /dev/mapper/rootvg-rootlvsudo lvresize -r -L +10G /dev/mapper/rootvg-tmplv -
No portal de nuvem do Azure, provisione um servidor Windows para executar a ferramenta NetApp SnapCenter UI com a versão mais recente. Consulte o link a seguir para obter detalhes:"Instalar o SnapCenter Server" .
-
Provisione uma VM Linux como o nó do controlador Ansible com a versão mais recente do Ansible e do Git instalada. Consulte o link a seguir para obter detalhes:"Introdução à automação de soluções da NetApp " na seção -
Setup the Ansible Control Node for CLI deployments on RHEL / CentOSou
Setup the Ansible Control Node for CLI deployments on Ubuntu / Debian.
O nó do controlador Ansible pode ser localizado no local ou na nuvem do Azure, desde que possa alcançar as VMs do Azure DB por meio da porta SSH. -
Clone uma cópia do kit de ferramentas de automação de implantação do NetApp Oracle para NFS. Siga as instruções em"TR-4887" para executar os manuais.
git clone https://bitbucket.ngage.netapp.com/scm/ns-bb/na_oracle_deploy_nfs.git -
Etapa seguinte: arquivos de instalação do Oracle 19c no diretório /tmp/archive da VM do Azure DB com permissão 777.
installer_archives: - "LINUX.X64_193000_db_home.zip" - "p34765931_190000_Linux-x86-64.zip" - "p6880880_190000_Linux-x86-64.zip"
-
Assista ao vídeo a seguir:
Backup, recuperação e clonagem de banco de dados Oracle em ANF com SnapCenter -
Revise o
Get Startedcardápio online.
Instalação e configuração do SnapCenter
Details
Recomendamos que você faça isso online"Documentação do software SnapCenter" antes de prosseguir com a instalação e configuração do SnapCenter : . A seguir, um resumo de alto nível das etapas para instalação e configuração do SnapCenter software para Oracle no Azure ANF.
-
No servidor SnapCenter Windows, baixe e instale o Java JDK mais recente em"Obtenha Java para aplicativos de desktop" .
-
No servidor SnapCenter Windows, baixe e instale a versão mais recente (atualmente 5.0) do executável de instalação do SnapCenter do site de suporte da NetApp :"NetApp | Suporte" .
-
Após a instalação do servidor SnapCenter , inicie o navegador para efetuar login no SnapCenter com o usuário administrador local do Windows ou com a credencial de usuário de domínio pela porta 8146.
-
Análise
Get Startedcardápio online.
-
Em
Settings-Global Settings, verificarHypervisor Settingse clique em Atualizar.
-
Se necessário, ajuste
Session Timeoutpara SnapCenter UI para o intervalo desejado.
-
Adicione usuários adicionais ao SnapCenter , se necessário.
-
O
Roleslista de guias as funções integradas que podem ser atribuídas a diferentes usuários do SnapCenter . Funções personalizadas também podem ser criadas pelo usuário administrador com os privilégios desejados.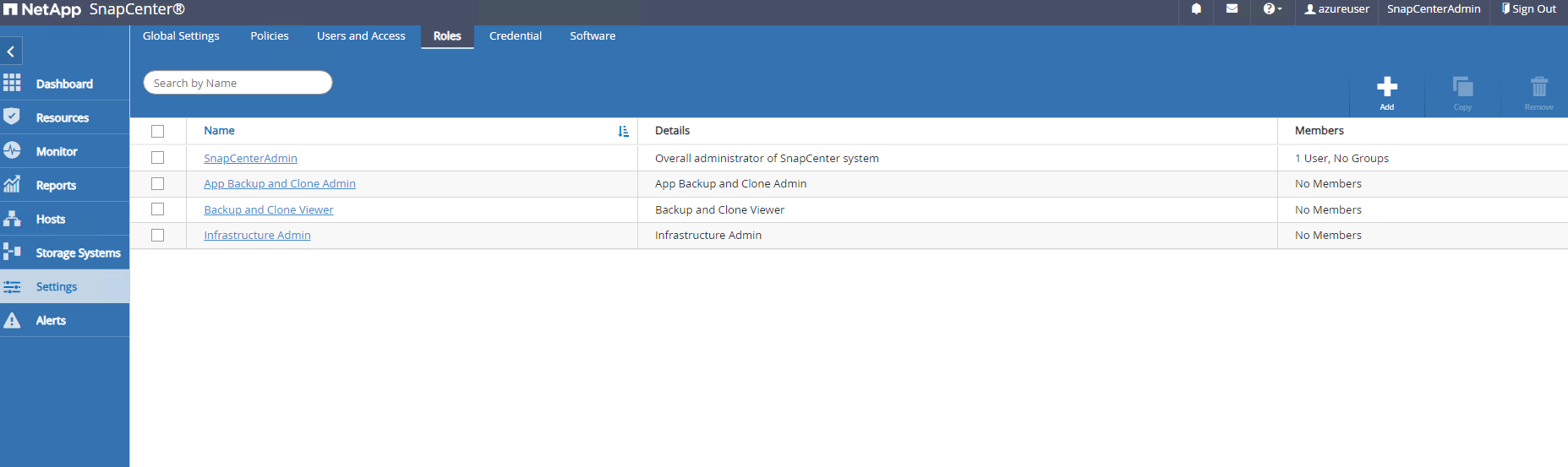
-
De
Settings-Credential, crie credenciais para destinos de gerenciamento do SnapCenter . Neste caso de uso de demonstração, eles são usuários Linux para login na VM do Azure e credenciais ANF para acesso ao pool de capacidade.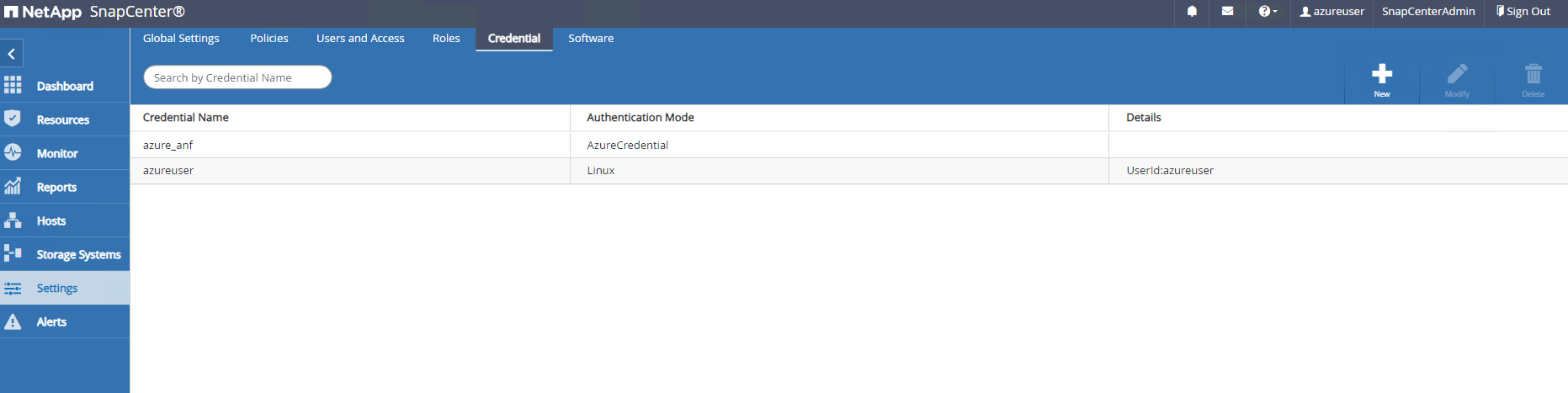
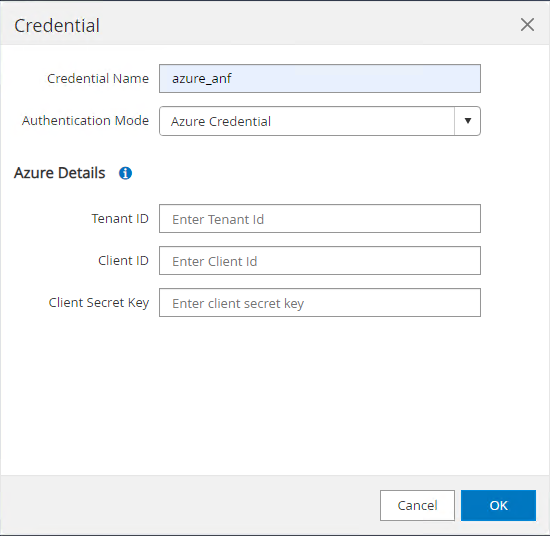
-
De
Storage Systemsaba, adicionarAzure NetApp Filescom credencial criada acima.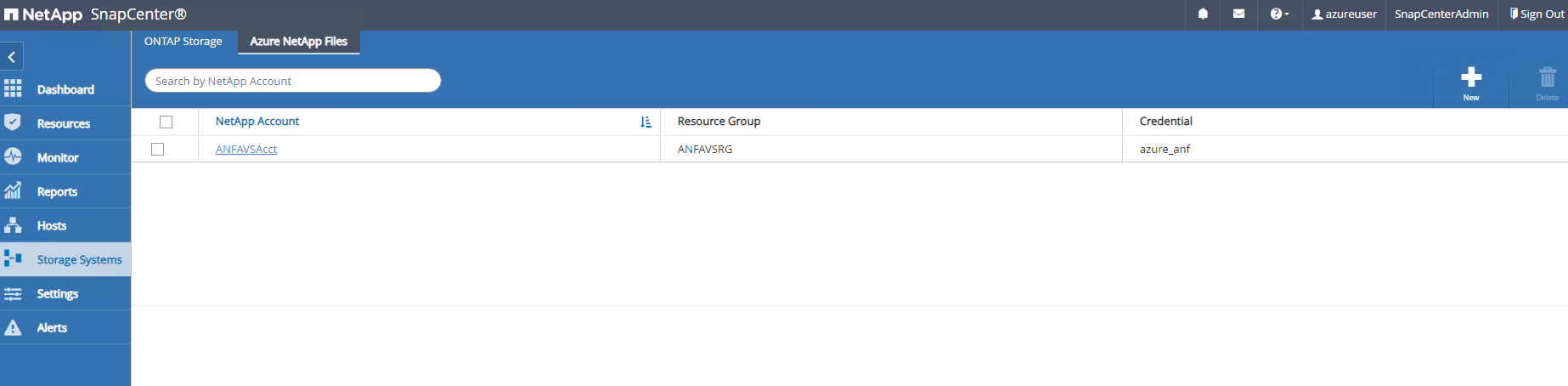

-
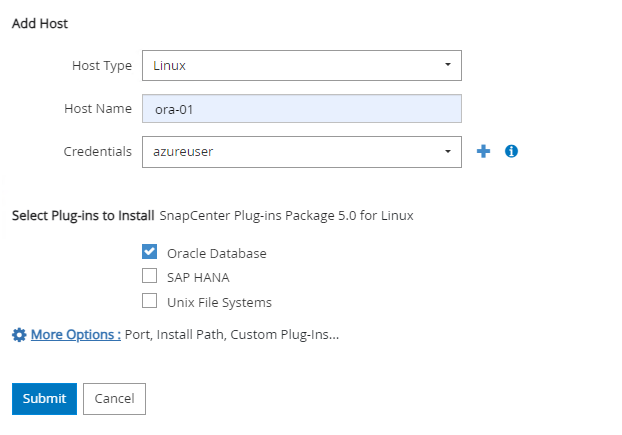
De
Hostsguia, adicione VMs do Azure DB, que instala o plug-in SnapCenter para Oracle no Linux.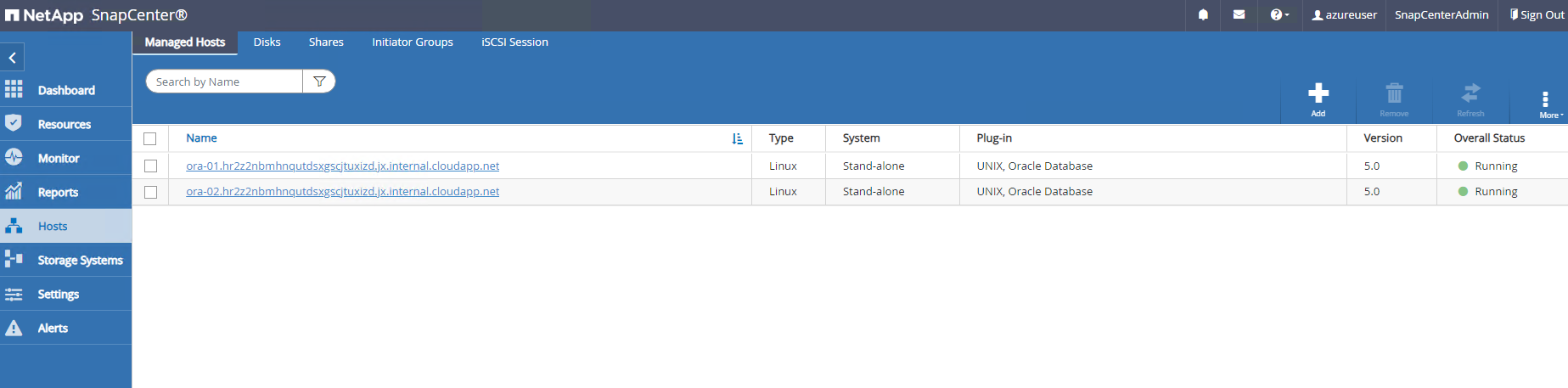
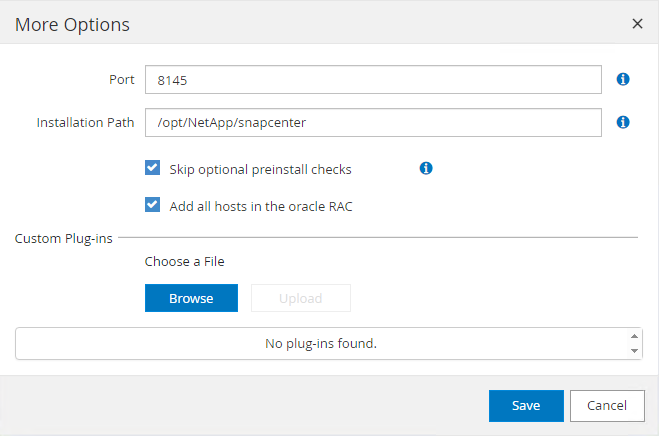
-
Depois que o plugin do host é instalado na VM do servidor DB, os bancos de dados no host são descobertos automaticamente e ficam visíveis em
Resourcesaba. Voltar paraSettings-Polices, crie políticas de backup para backup on-line completo do banco de dados Oracle e somente backup de logs de arquivamento. Consulte este documento"Crie políticas de backup para bancos de dados Oracle" para procedimentos detalhados passo a passo.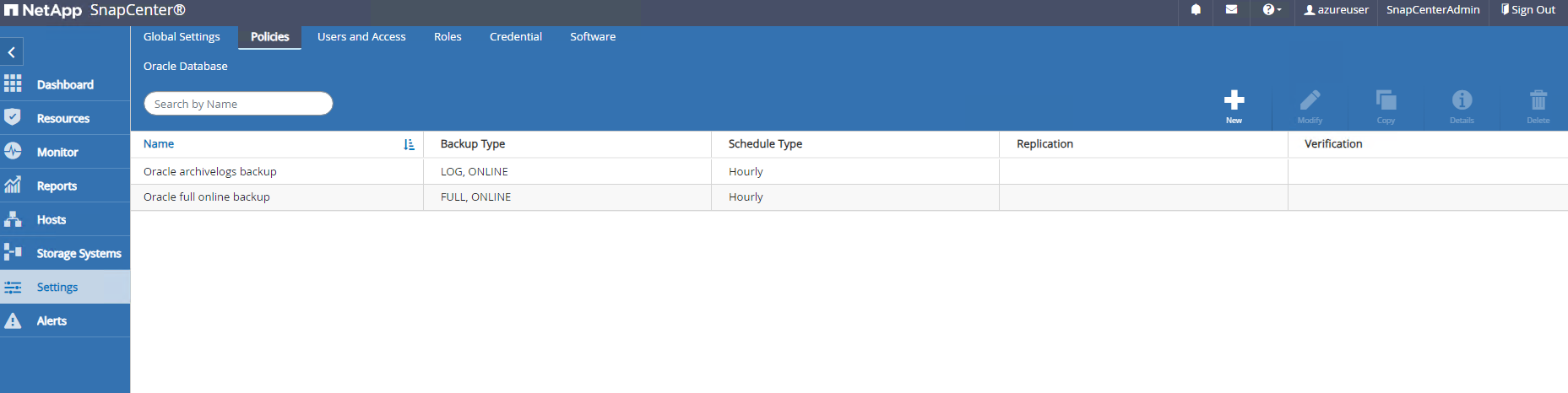
Backup de banco de dados
Details
Um backup de instantâneo do NetApp cria uma imagem pontual dos volumes do banco de dados que você pode usar para restaurar em caso de falha do sistema ou perda de dados. Os backups de instantâneos levam muito pouco tempo, geralmente menos de um minuto. A imagem de backup consome espaço de armazenamento mínimo e gera sobrecarga de desempenho insignificante porque registra apenas alterações nos arquivos desde a última cópia instantânea. A seção a seguir demonstra a implementação de snapshots para backup de banco de dados Oracle no SnapCenter.
-
Navegando para
Resourcesguia, que lista os bancos de dados descobertos quando o plugin SnapCenter é instalado na VM do banco de dados. Inicialmente, oOverall Statusdo banco de dados mostra comoNot protected.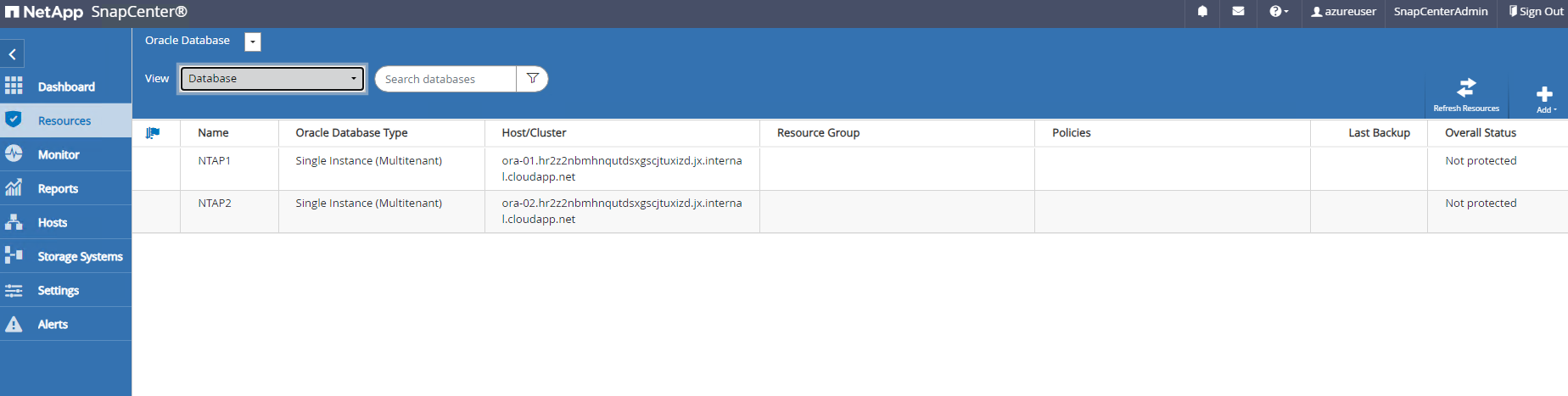
-
Clique em
Viewmenu suspenso para alterar paraResource Group. Clique emAddsinalize à direita para adicionar um Grupo de Recursos.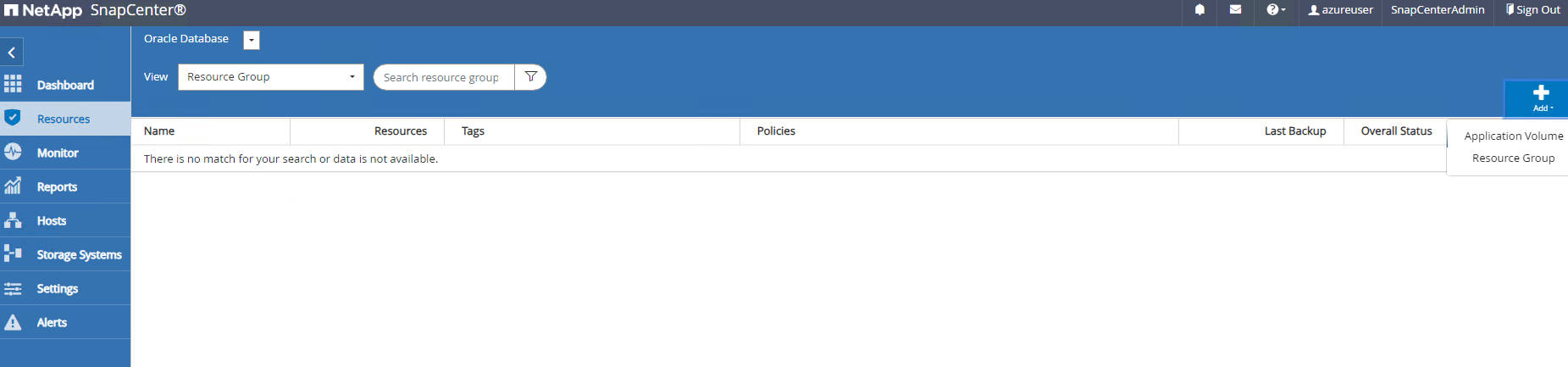
-
Dê um nome ao seu grupo de recursos, tags e qualquer nome personalizado.
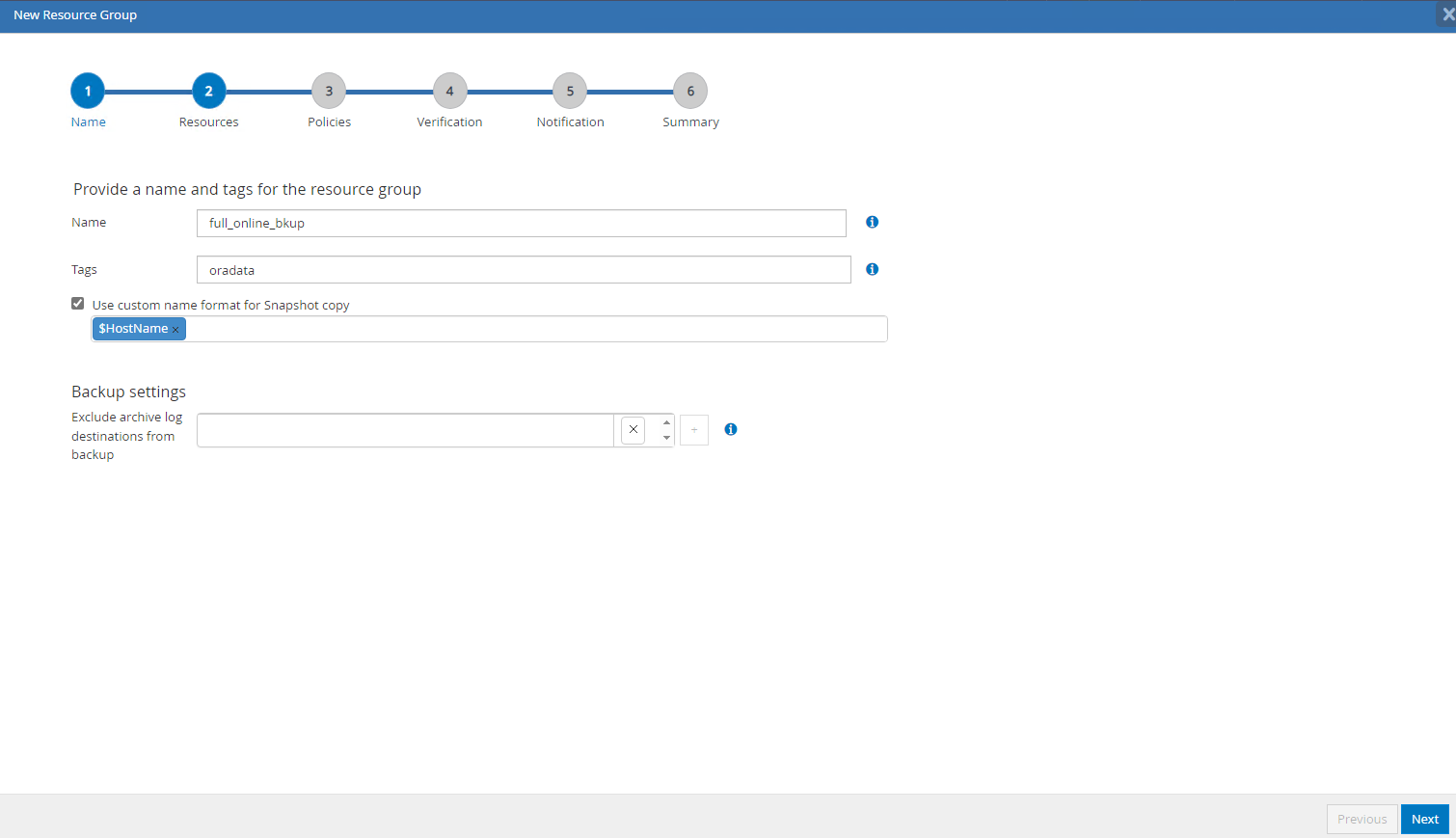
-
Adicione recursos ao seu
Resource Group. O agrupamento de recursos semelhantes pode simplificar o gerenciamento de banco de dados em um ambiente grande.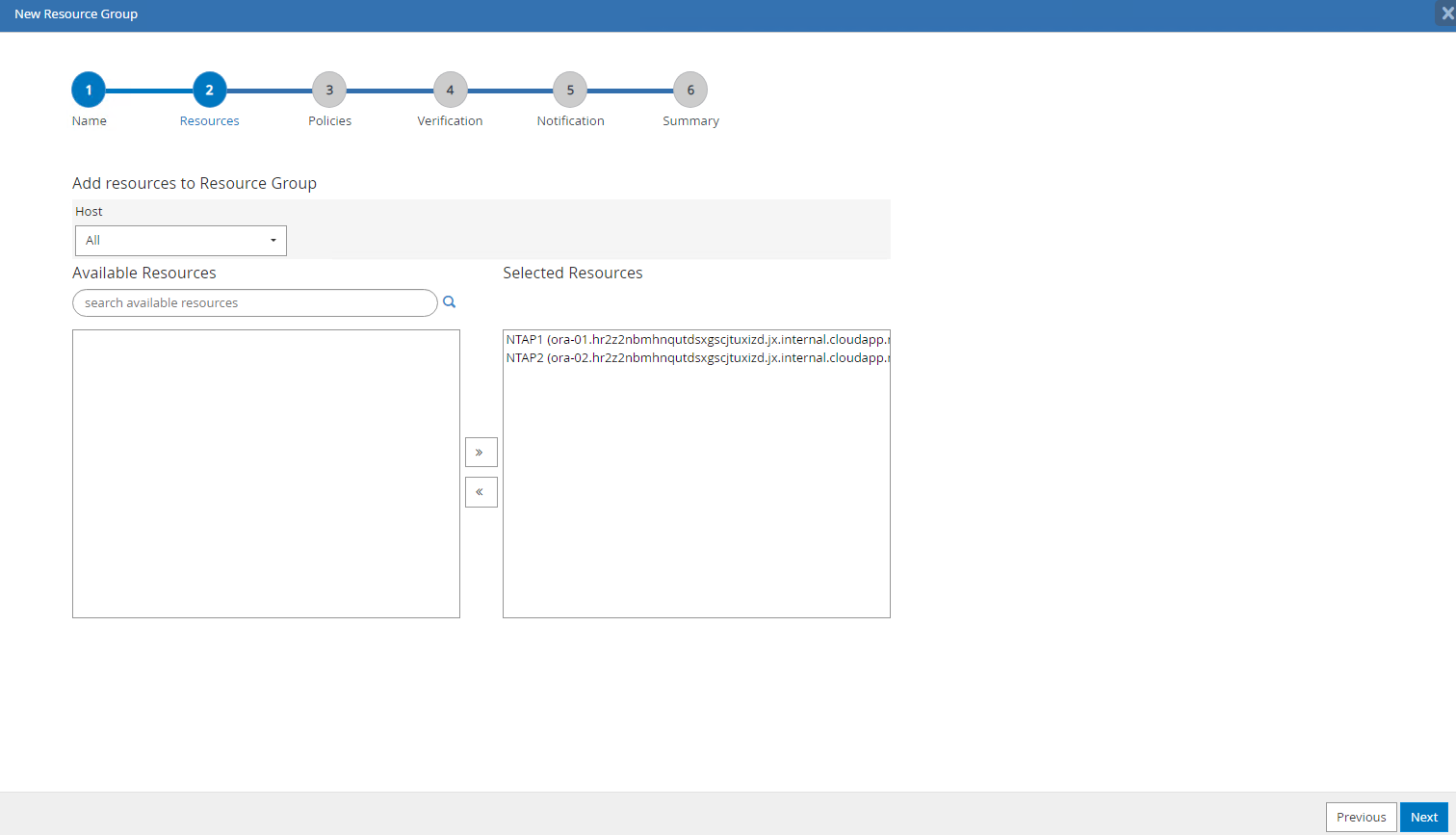
-
Selecione a política de backup e defina uma programação clicando no sinal '+' em
Configure Schedules.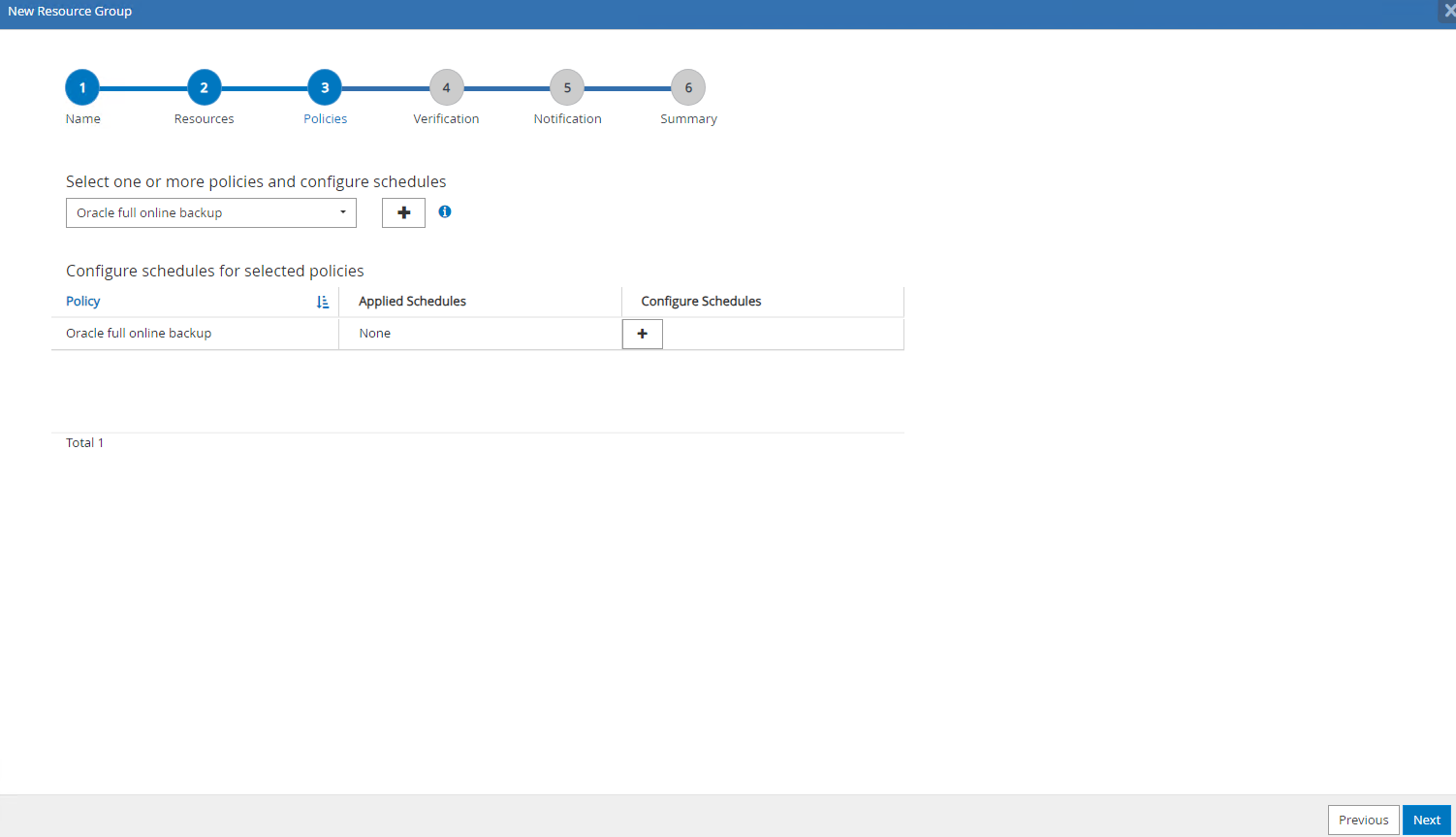
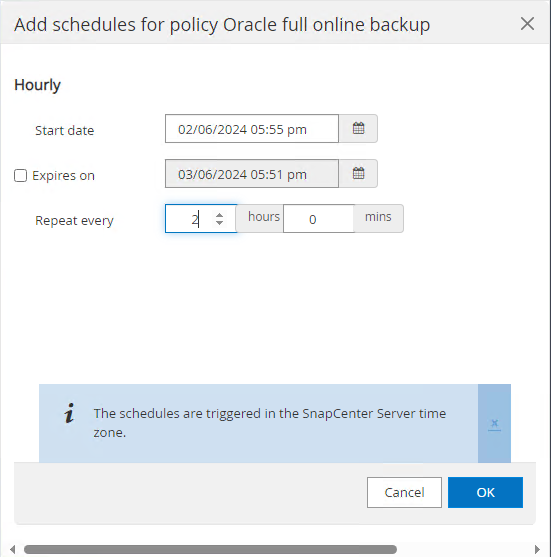
-
Se a verificação de backup não estiver configurada na política, deixe a página de verificação como está.
-
Para enviar um relatório de backup e uma notificação por e-mail, é necessário um servidor de e-mail SMTP no ambiente. Ou deixe-o preto se um servidor de e-mail não estiver configurado.
-
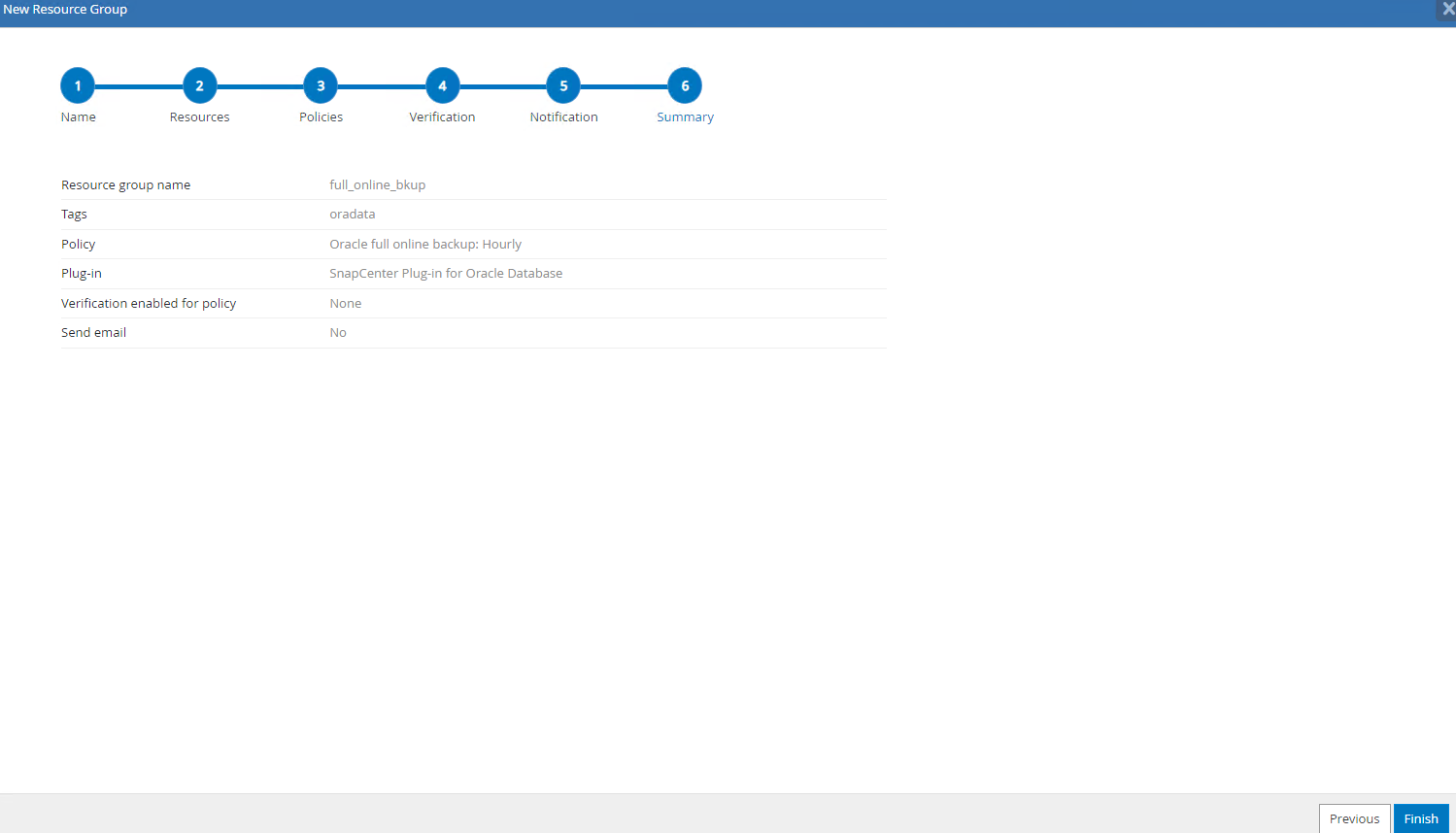
Resumo do novo grupo de recursos.
-
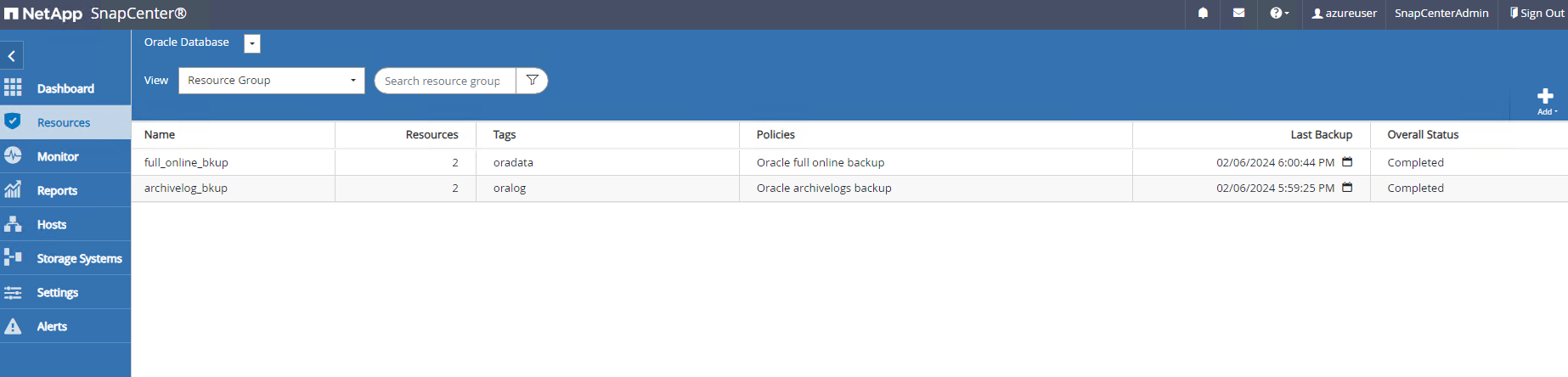
Repita os procedimentos acima para criar um backup somente do log de arquivamento do banco de dados com a política de backup correspondente.
-
Clique em um grupo de recursos para revelar os recursos que ele inclui. Além do trabalho de backup agendado, um backup único pode ser acionado clicando em
Backup Now.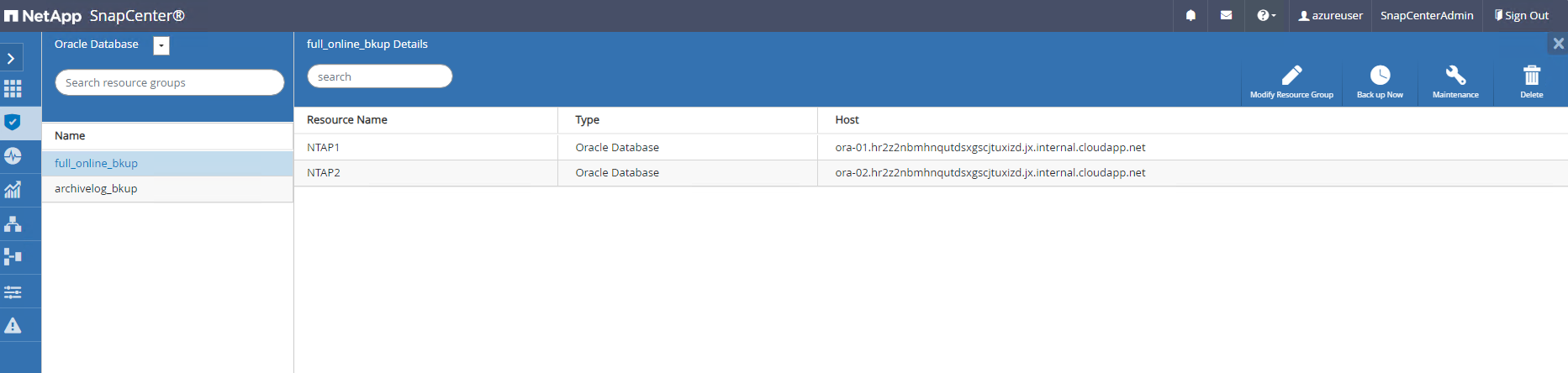
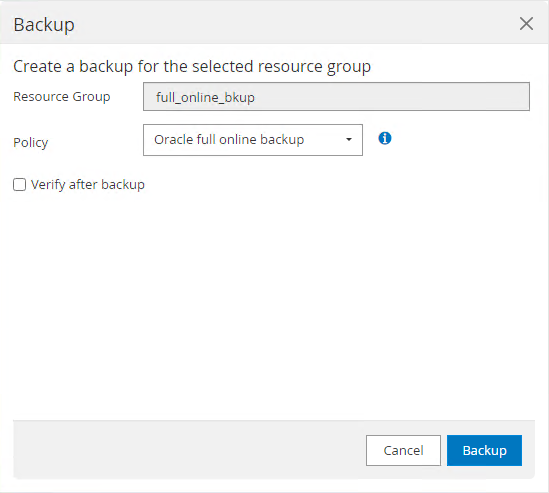
-
Clique no trabalho em execução para abrir uma janela de monitoramento, que permite ao operador acompanhar o andamento do trabalho em tempo real.
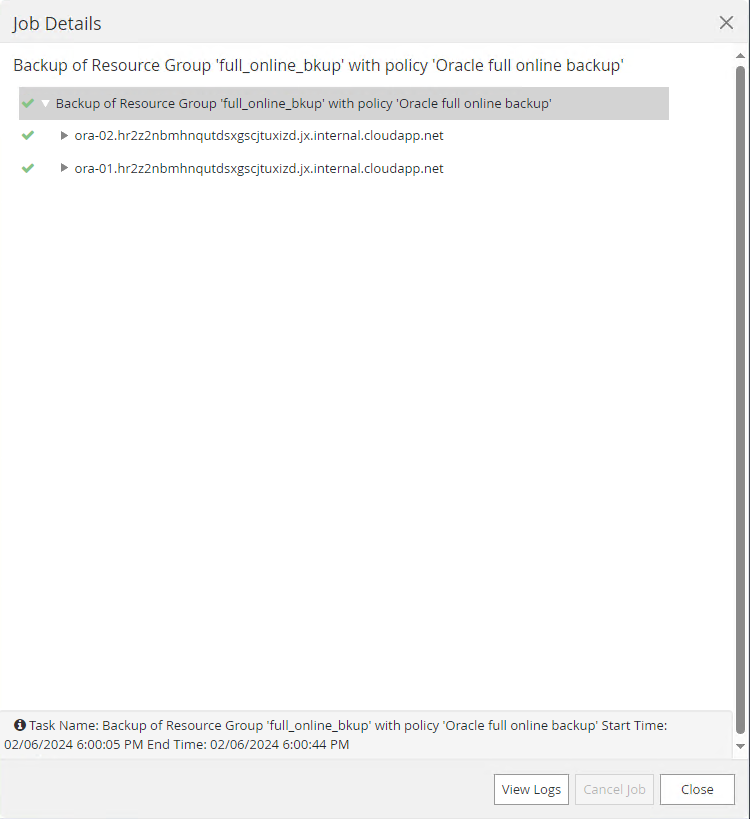
-
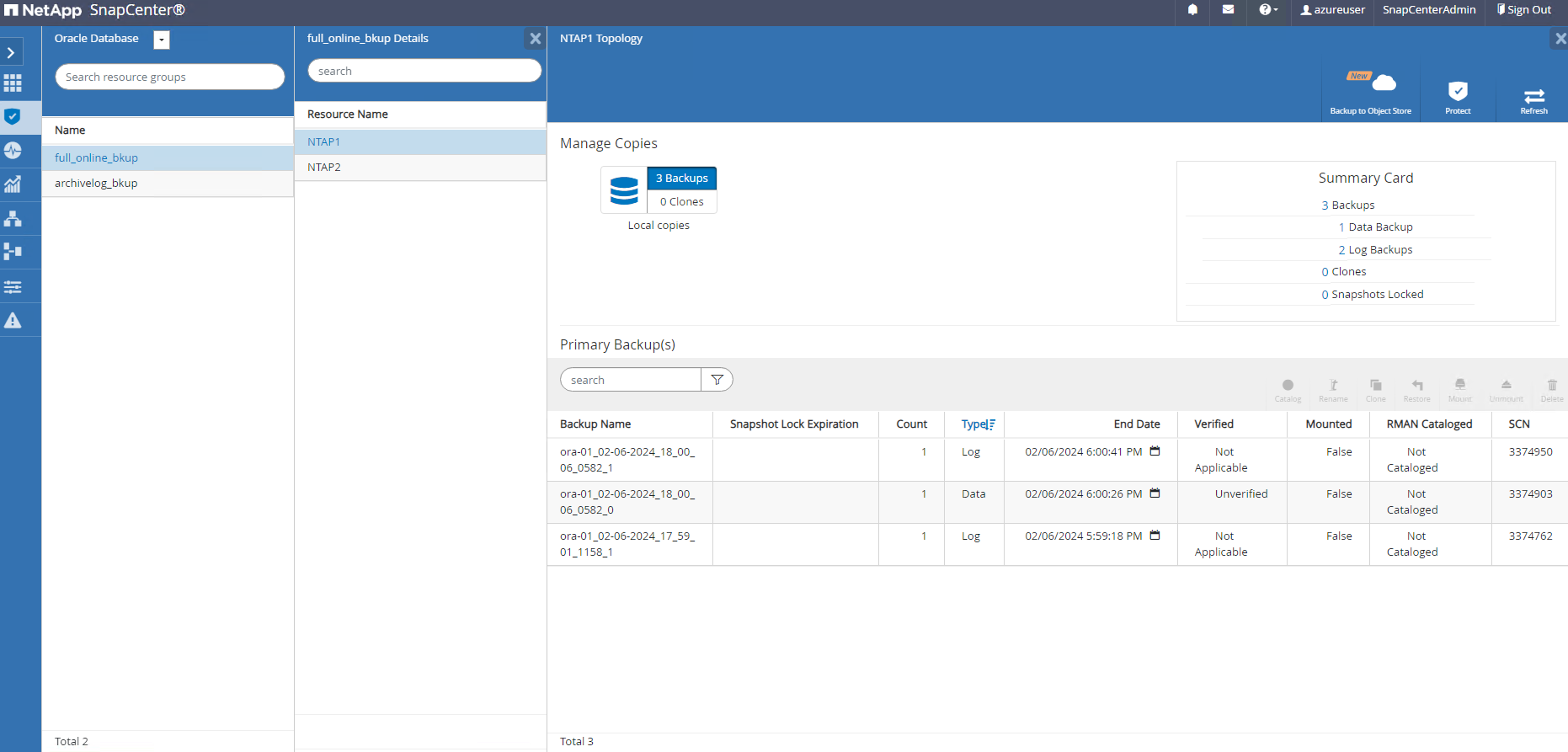
Um conjunto de backup de instantâneo aparece na topologia do banco de dados quando uma tarefa de backup bem-sucedida é concluída. Um conjunto completo de backup do banco de dados inclui um instantâneo dos volumes de dados do banco de dados e um instantâneo dos volumes de log do banco de dados. Um backup somente de log contém apenas um instantâneo dos volumes de log do banco de dados.
Recuperação de banco de dados
Details
A recuperação de banco de dados via SnapCenter restaura uma cópia instantânea da imagem do volume do banco de dados em um determinado momento. O banco de dados é então rolado para um ponto desejado por SCN/carimbo de data/hora ou um ponto permitido pelos logs de arquivamento disponíveis no conjunto de backup. A seção a seguir demonstra o fluxo de trabalho de recuperação de banco de dados com o SnapCenter UI.
-
De
Resourcesguia, abra o banco de dadosPrimary Backup(s)página. Selecione o instantâneo do volume de dados do banco de dados e clique emRestorebotão para iniciar o fluxo de trabalho de recuperação do banco de dados. Anote o número do SCN ou o registro de data e hora nos conjuntos de backup se desejar executar a recuperação pelo Oracle SCN ou registro de data e hora.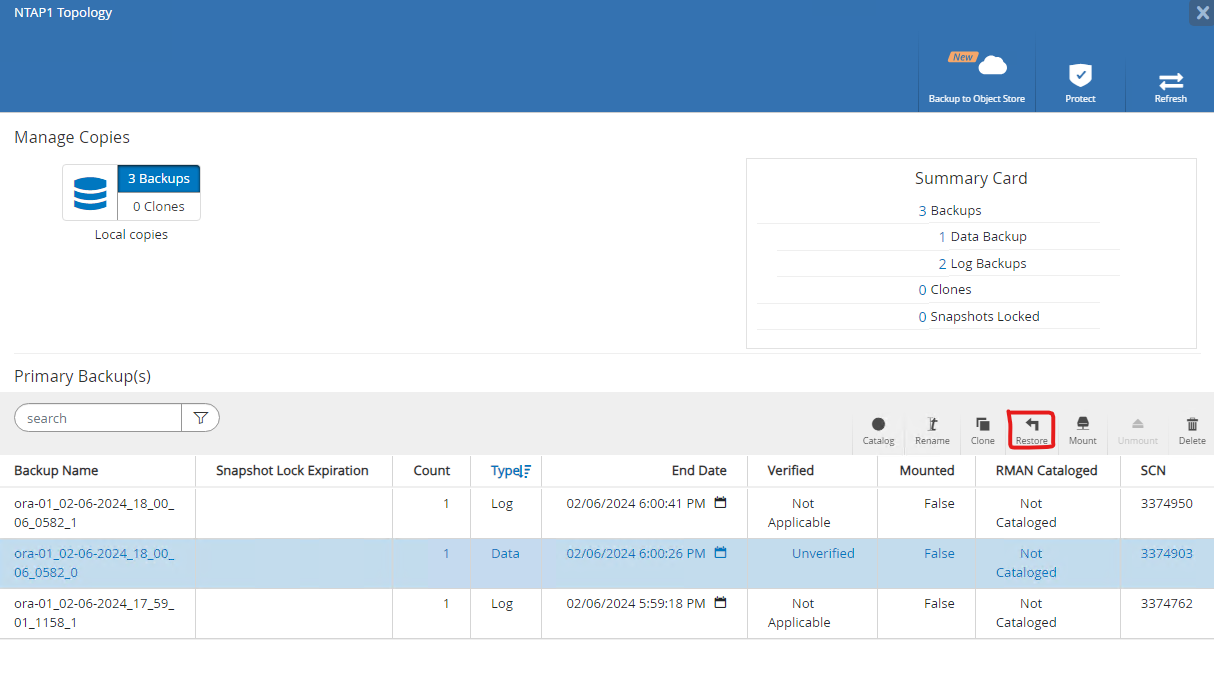
-
Selecione
Restore Scope. Para um banco de dados de contêiner, o SnapCenter é flexível para executar uma restauração de banco de dados de contêiner completo (todos os arquivos de dados), bancos de dados conectáveis ou nível de tablespaces.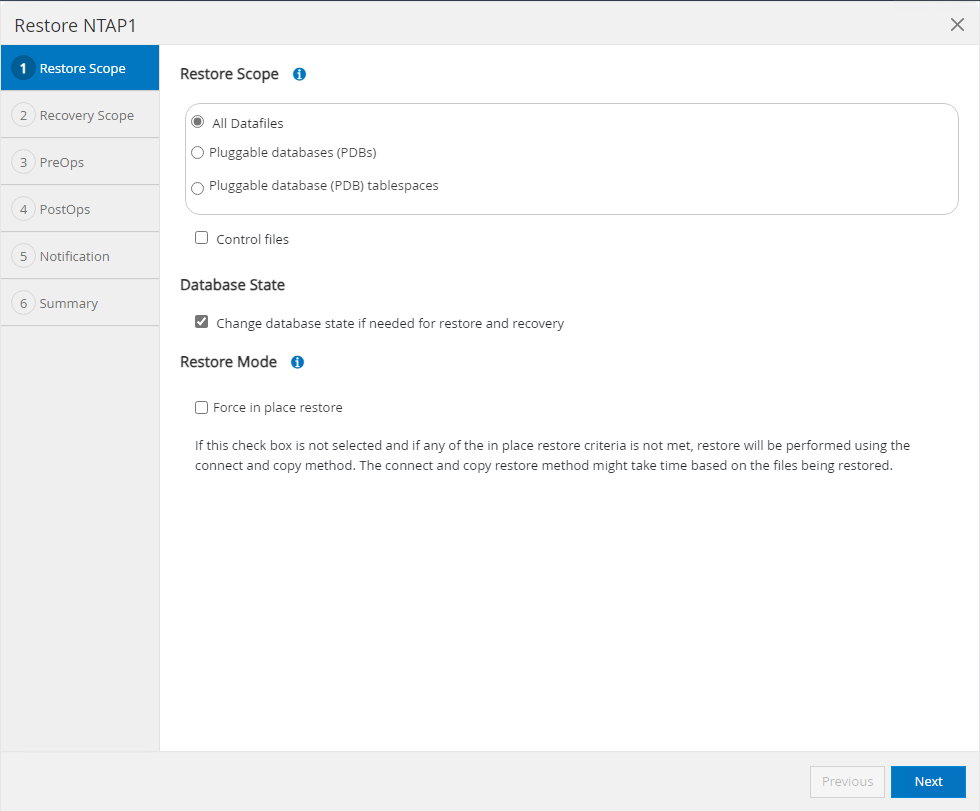
-
Selecione
Recovery Scope.All logssignifica aplicar todos os logs de arquivo disponíveis no conjunto de backup. Recuperação de ponto no tempo por SCN ou registro de data e hora também está disponível.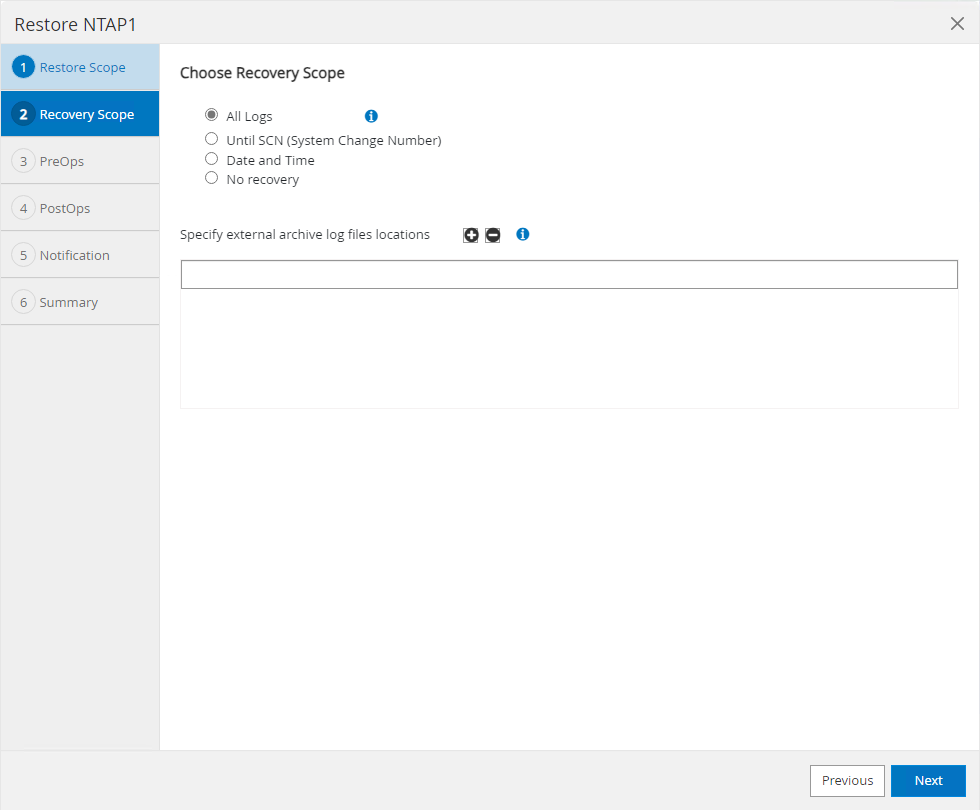
-
O
PreOpspermite a execução de scripts no banco de dados antes da operação de restauração/recuperação.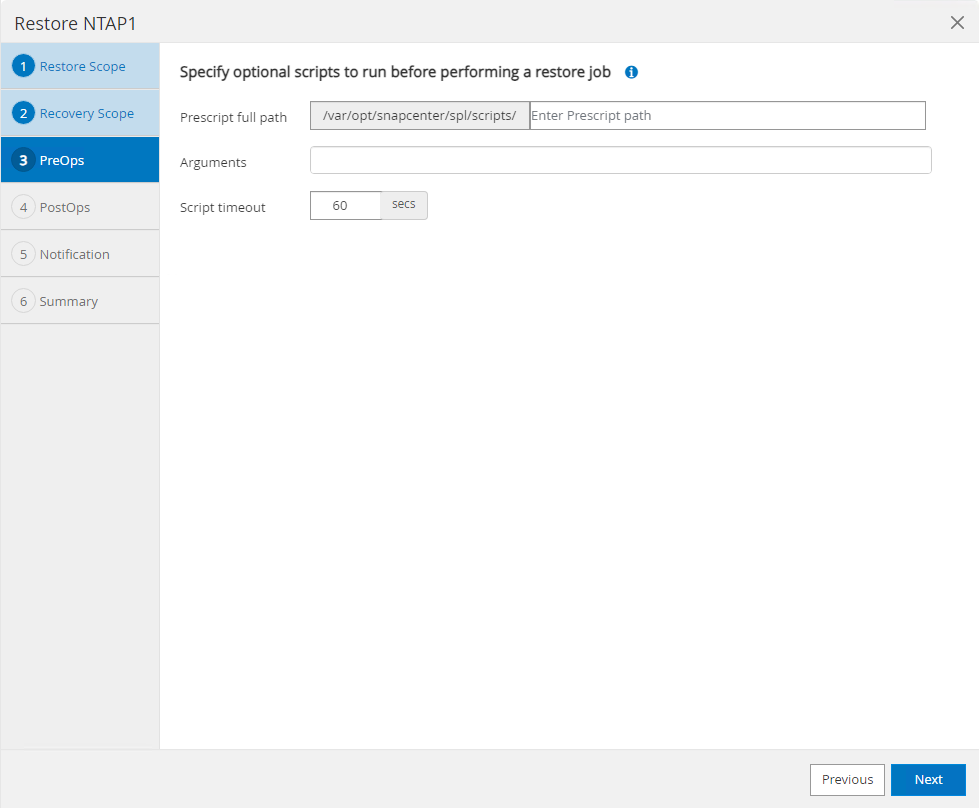
-
O
PostOpspermite a execução de scripts no banco de dados após a operação de restauração/recuperação.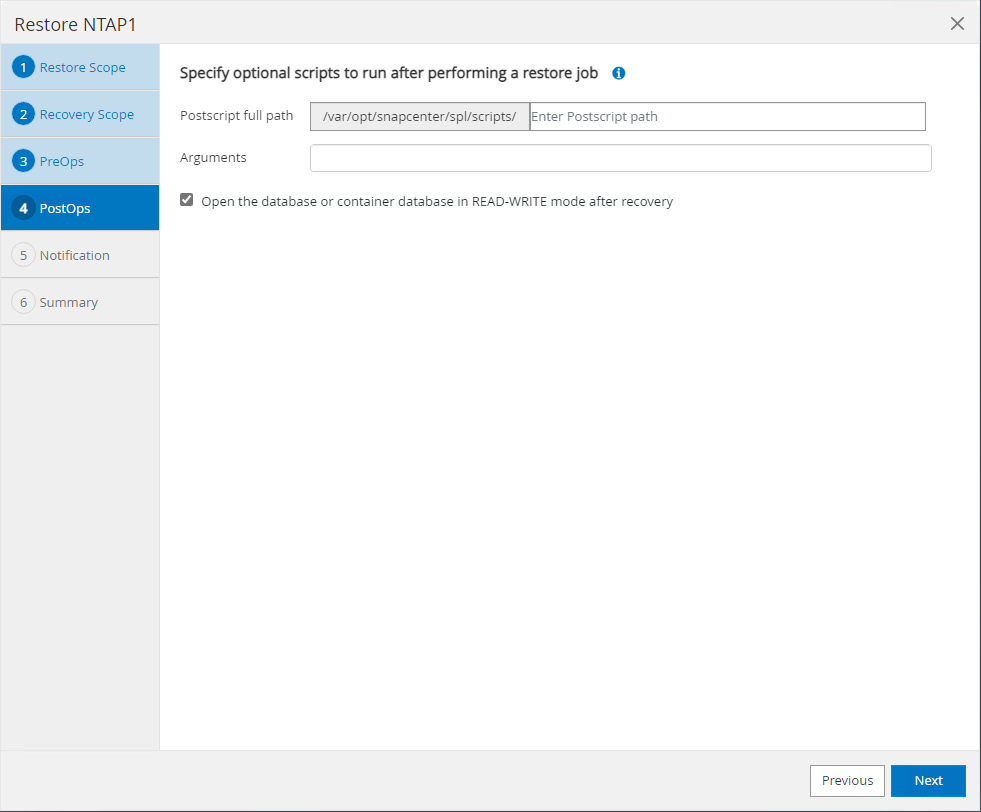
-
Notificação por e-mail, se desejado.
-
Resumo do trabalho de restauração
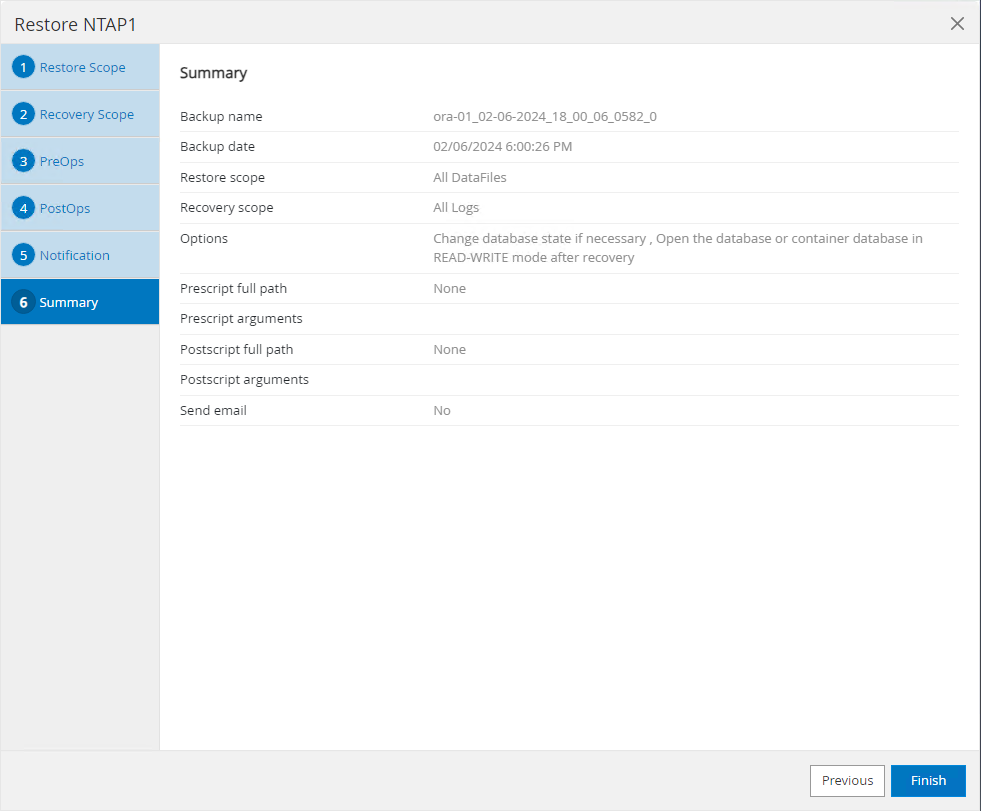
-
Clique no trabalho em execução para abrir
Job Detailsjanela. O status do trabalho também pode ser aberto e visualizado noMonitoraba.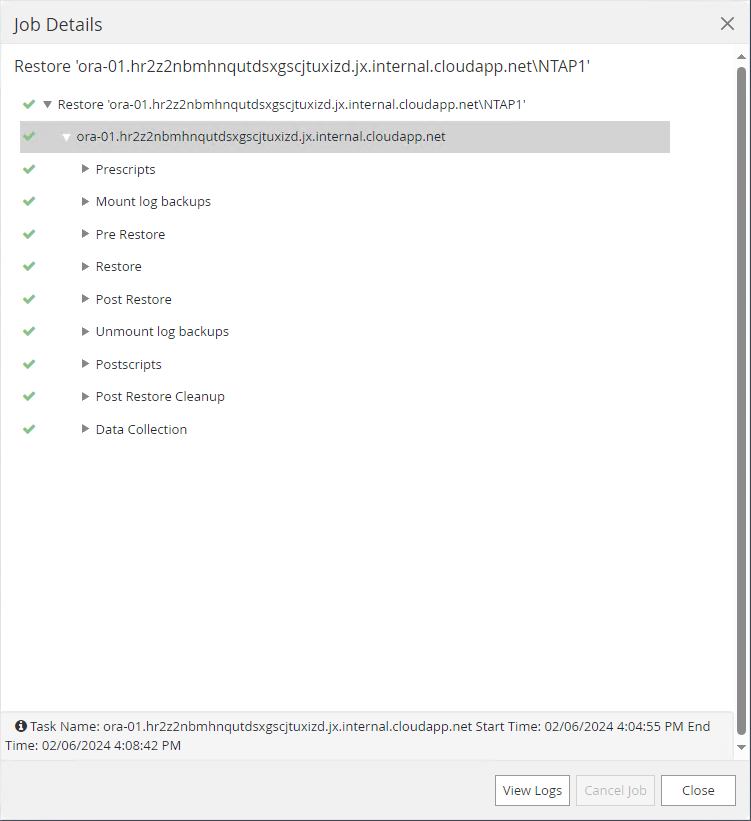
Clone de banco de dados
Details
A clonagem de banco de dados via SnapCenter é realizada pela criação de um novo volume a partir de um instantâneo de um volume. O sistema usa as informações do instantâneo para clonar um novo volume usando os dados no volume quando o instantâneo foi tirado. Mais importante, é rápido (alguns minutos) e eficiente em comparação com outros métodos para fazer uma cópia clonada do banco de dados de produção para dar suporte ao desenvolvimento ou testes. Dessa forma, melhore drasticamente o gerenciamento do ciclo de vida do seu aplicativo de banco de dados. A seção a seguir demonstra o fluxo de trabalho de clonagem de banco de dados com o SnapCenter UI.
-
De
Resourcesguia, abra o banco de dadosPrimary Backup(s)página. Selecione o instantâneo do volume de dados do banco de dados e clique emclonebotão para iniciar o fluxo de trabalho de clonagem do banco de dados.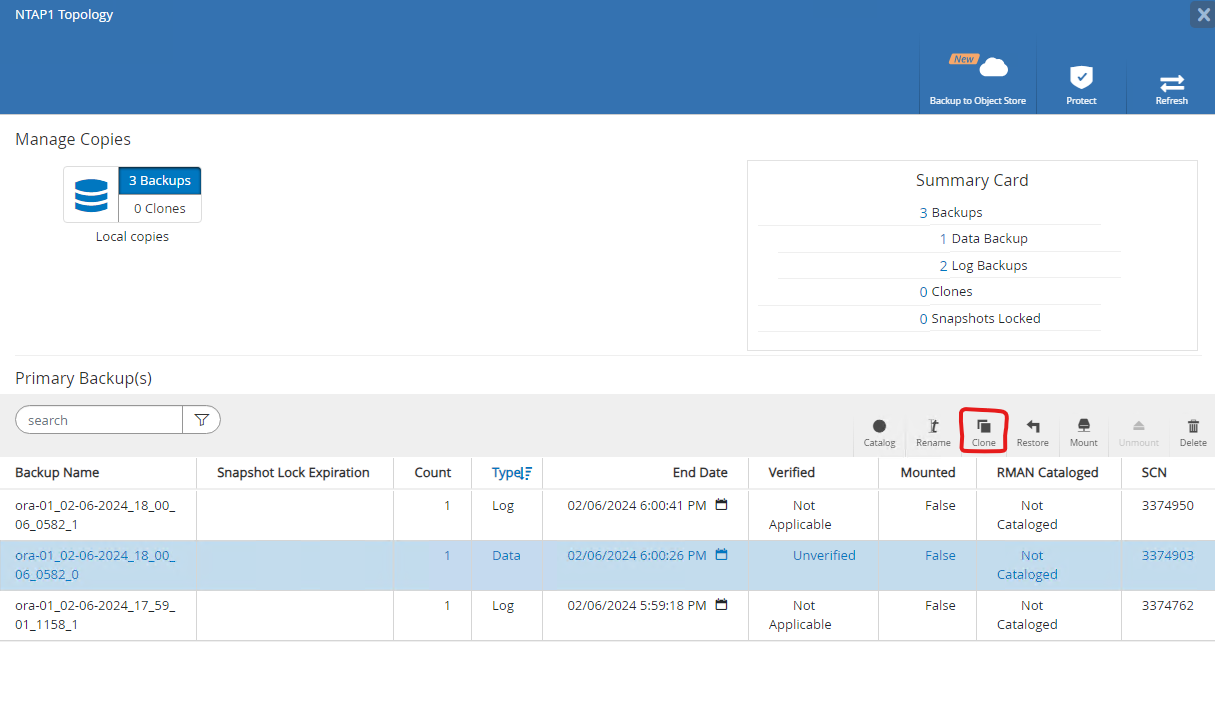
-
Nomeie o SID do banco de dados clone. Opcionalmente, para um banco de dados de contêiner, a clonagem também pode ser feita no nível do PDB.
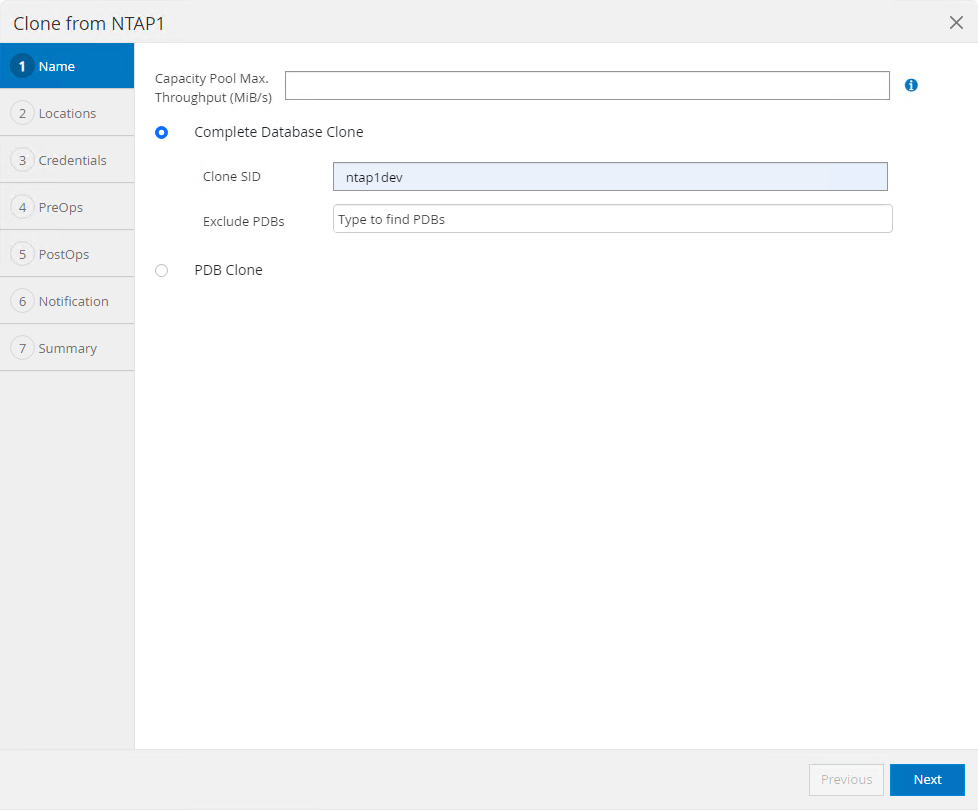
-
Selecione o servidor de banco de dados onde você deseja colocar sua cópia de banco de dados clonada. Mantenha os locais de arquivo padrão, a menos que você queira nomeá-los de forma diferente.
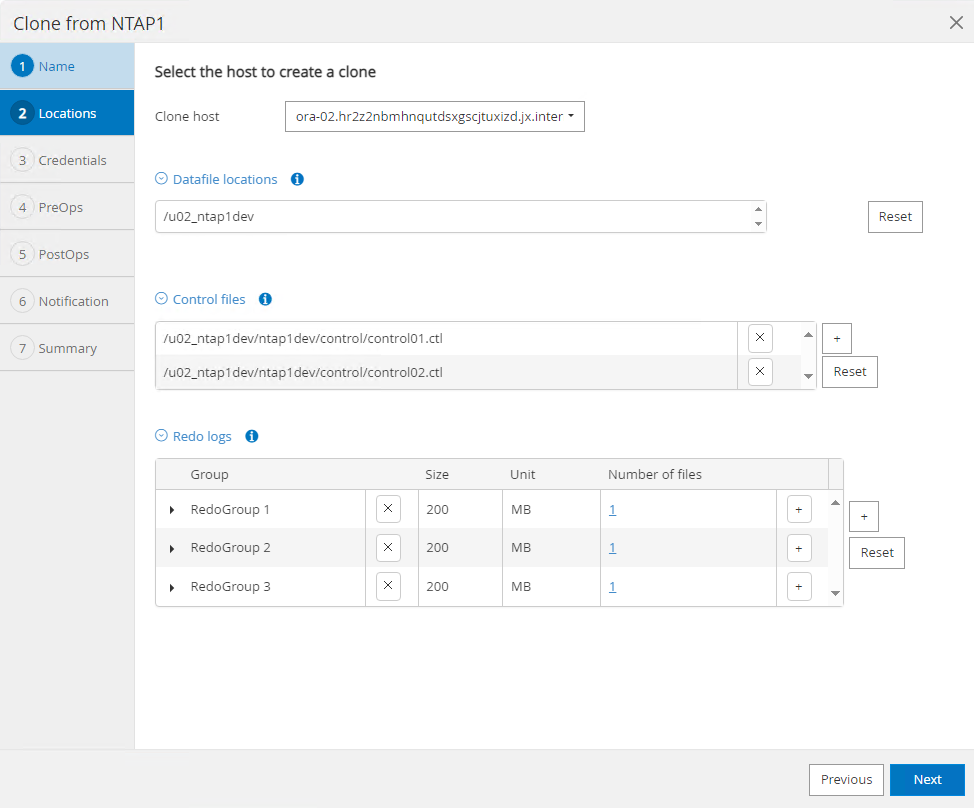
-
A pilha de software Oracle idêntica à do banco de dados de origem deve ter sido instalada e configurada no host do banco de dados clone. Mantenha a credencial padrão, mas altere
Oracle Home Settingspara corresponder às configurações no host do banco de dados clone.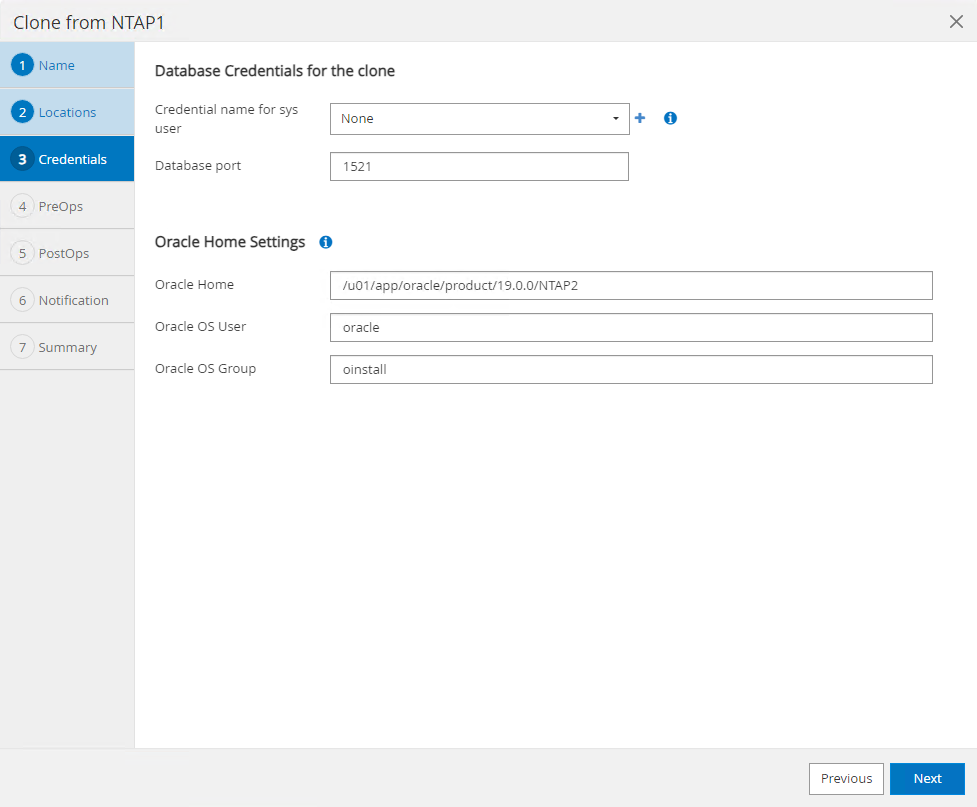
-
O
PreOpspermite a execução de scripts antes da operação de clonagem. Os parâmetros do banco de dados podem ser ajustados para atender às necessidades de um banco de dados clone em comparação a um banco de dados de produção, como uma meta SGA reduzida.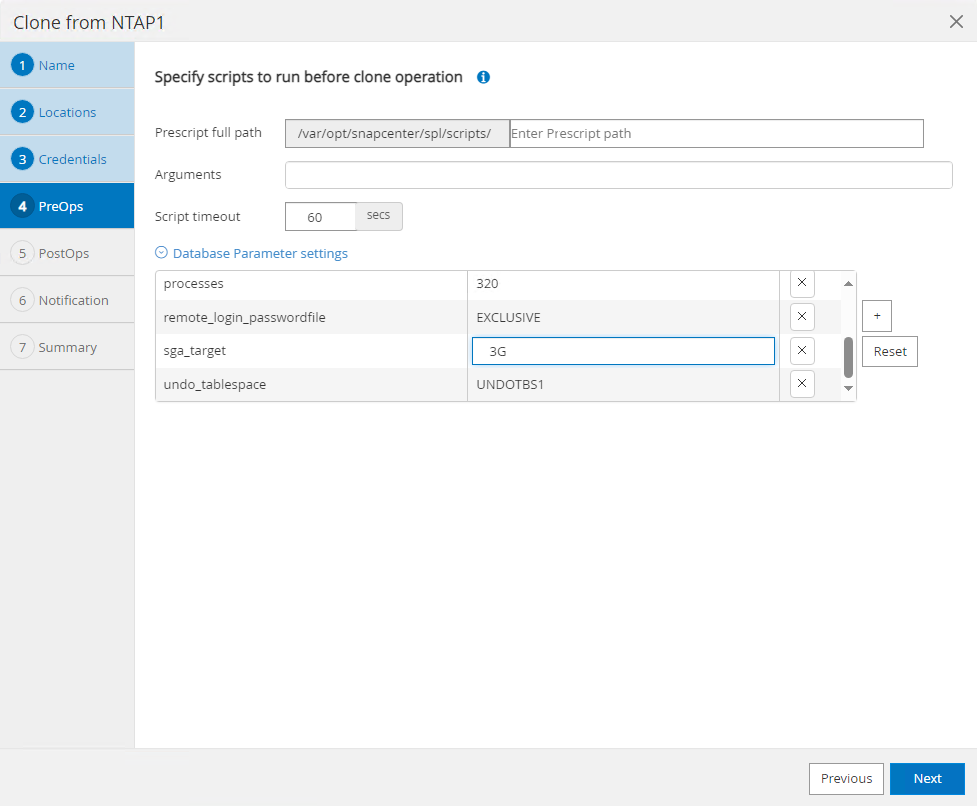
-
O
PostOpspermite a execução de scripts no banco de dados após a operação de clonagem. A recuperação de banco de dados clone pode ser SCN, baseada em registro de data e hora ou até cancelamento (avançando o banco de dados para o último log arquivado no conjunto de backup).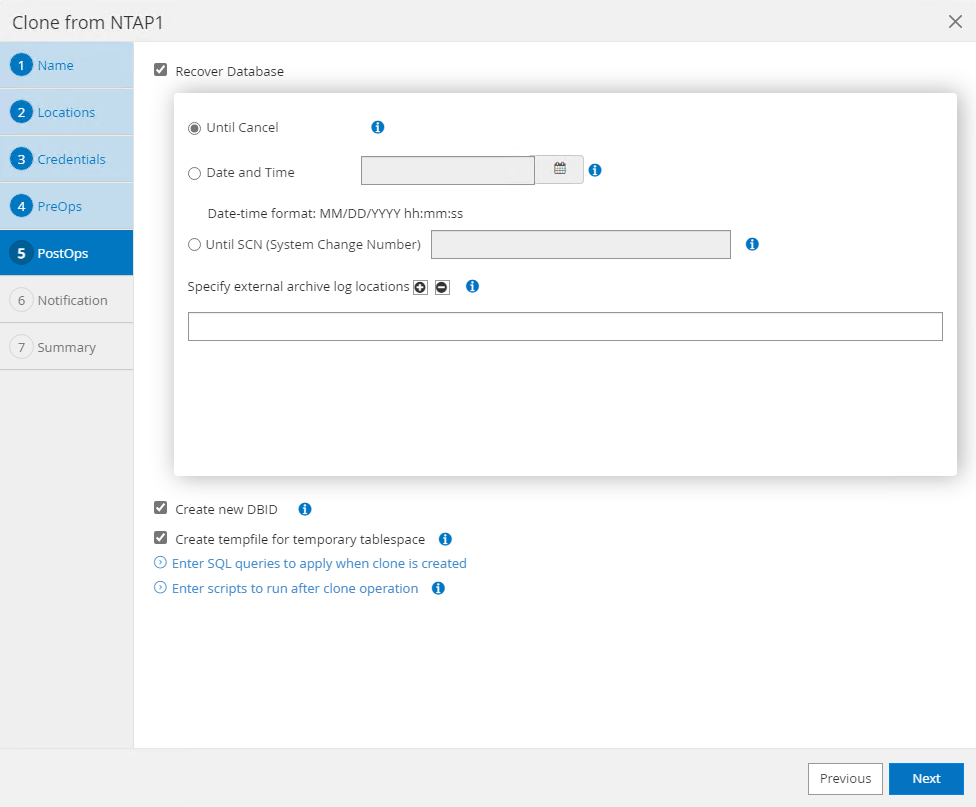
-
Notificação por e-mail, se desejado.
-
Resumo do trabalho de clonagem.
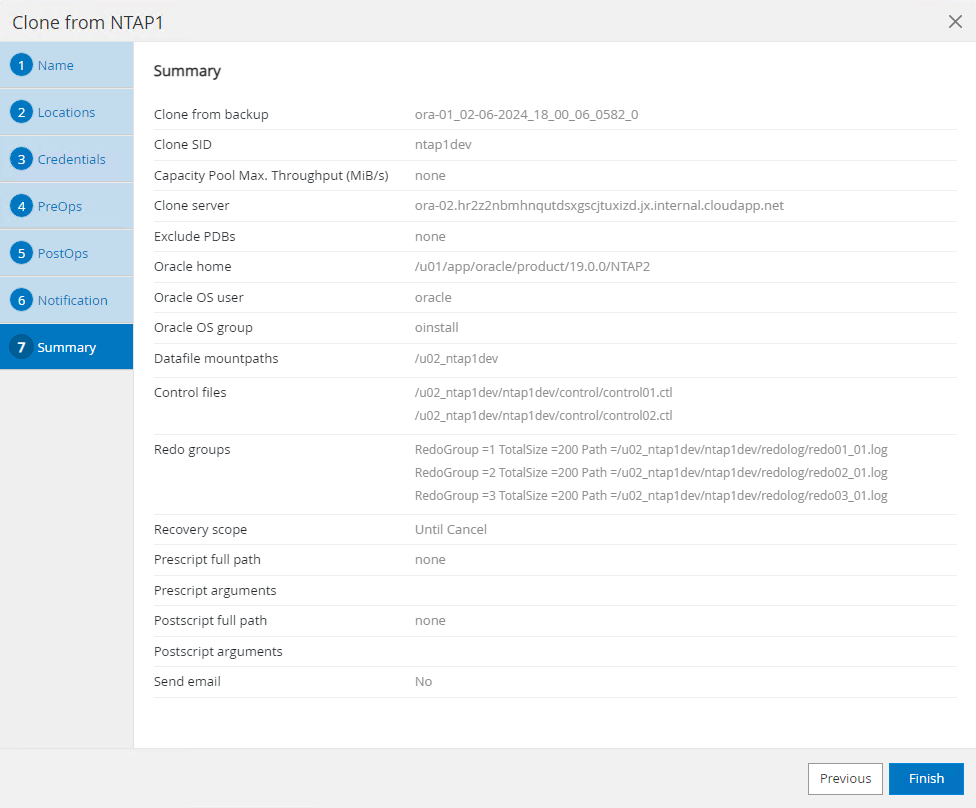
-
Clique no trabalho em execução para abrir
Job Detailsjanela. O status do trabalho também pode ser aberto e visualizado noMonitoraba.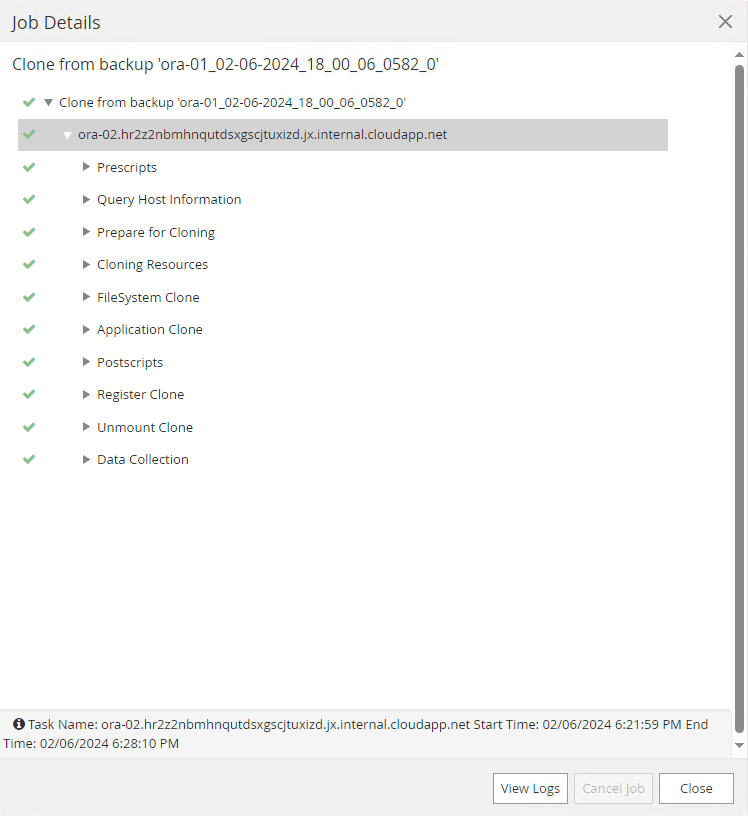
-
O banco de dados clonado é registrado no SnapCenter imediatamente.
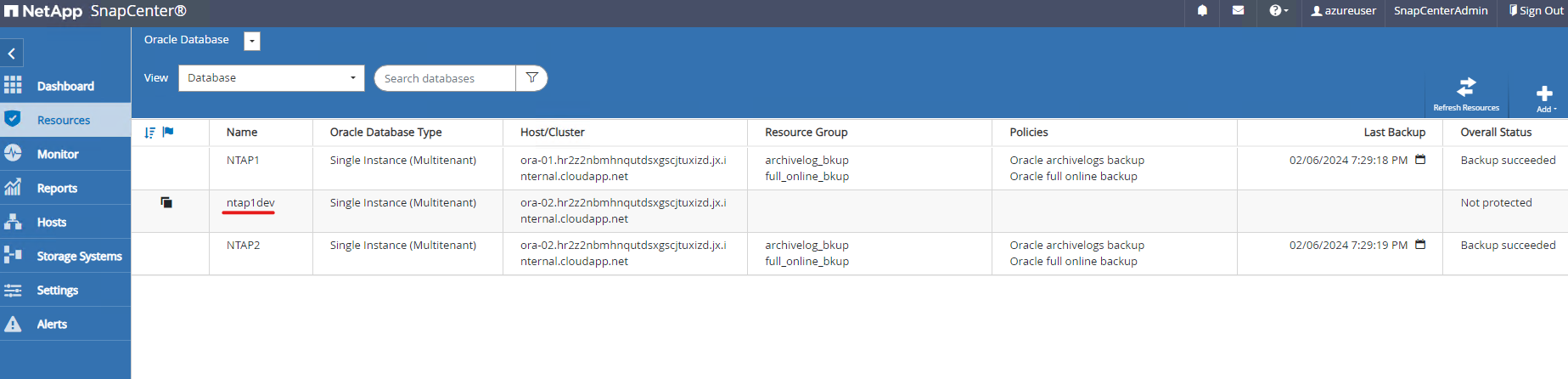
-
Validar banco de dados clone no host do servidor DB. Para um banco de dados de desenvolvimento clonado, o modo de arquivamento de banco de dados deve ser desativado.
[azureuser@ora-02 ~]$ sudo su [root@ora-02 azureuser]# su - oracle Last login: Tue Feb 6 16:26:28 UTC 2024 on pts/0 [oracle@ora-02 ~]$ uname -a Linux ora-02 4.18.0-372.9.1.el8.x86_64 #1 SMP Fri Apr 15 22:12:19 EDT 2022 x86_64 x86_64 x86_64 GNU/Linux [oracle@ora-02 ~]$ df -h Filesystem Size Used Avail Use% Mounted on devtmpfs 7.7G 0 7.7G 0% /dev tmpfs 7.8G 0 7.8G 0% /dev/shm tmpfs 7.8G 49M 7.7G 1% /run tmpfs 7.8G 0 7.8G 0% /sys/fs/cgroup /dev/mapper/rootvg-rootlv 22G 17G 5.6G 75% / /dev/mapper/rootvg-usrlv 10G 2.0G 8.1G 20% /usr /dev/mapper/rootvg-homelv 1014M 40M 975M 4% /home /dev/sda1 496M 106M 390M 22% /boot /dev/mapper/rootvg-varlv 8.0G 958M 7.1G 12% /var /dev/sda15 495M 5.9M 489M 2% /boot/efi /dev/mapper/rootvg-tmplv 12G 8.4G 3.7G 70% /tmp tmpfs 1.6G 0 1.6G 0% /run/user/54321 172.30.136.68:/ora-02-u03 250G 2.1G 248G 1% /u03 172.30.136.68:/ora-02-u01 100G 10G 91G 10% /u01 172.30.136.68:/ora-02-u02 250G 7.5G 243G 3% /u02 tmpfs 1.6G 0 1.6G 0% /run/user/1000 tmpfs 1.6G 0 1.6G 0% /run/user/0 172.30.136.68:/ora-01-u02-Clone-020624161543077 250G 8.2G 242G 4% /u02_ntap1dev [oracle@ora-02 ~]$ cat /etc/oratab # # This file is used by ORACLE utilities. It is created by root.sh # and updated by either Database Configuration Assistant while creating # a database or ASM Configuration Assistant while creating ASM instance. # A colon, ':', is used as the field terminator. A new line terminates # the entry. Lines beginning with a pound sign, '#', are comments. # # Entries are of the form: # $ORACLE_SID:$ORACLE_HOME:<N|Y>: # # The first and second fields are the system identifier and home # directory of the database respectively. The third field indicates # to the dbstart utility that the database should , "Y", or should not, # "N", be brought up at system boot time. # # Multiple entries with the same $ORACLE_SID are not allowed. # # NTAP2:/u01/app/oracle/product/19.0.0/NTAP2:Y # SnapCenter Plug-in for Oracle Database generated entry (DO NOT REMOVE THIS LINE) ntap1dev:/u01/app/oracle/product/19.0.0/NTAP2:N [oracle@ora-02 ~]$ export ORACLE_SID=ntap1dev [oracle@ora-02 ~]$ sqlplus / as sysdba SQL*Plus: Release 19.0.0.0.0 - Production on Tue Feb 6 16:29:02 2024 Version 19.18.0.0.0 Copyright (c) 1982, 2022, Oracle. All rights reserved. Connected to: Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production Version 19.18.0.0.0 SQL> select name, open_mode, log_mode from v$database; NAME OPEN_MODE LOG_MODE --------- -------------------- ------------ NTAP1DEV READ WRITE ARCHIVELOG SQL> shutdown immediate; Database closed. Database dismounted. ORACLE instance shut down. SQL> startup mount; ORACLE instance started. Total System Global Area 3221223168 bytes Fixed Size 9168640 bytes Variable Size 654311424 bytes Database Buffers 2550136832 bytes Redo Buffers 7606272 bytes Database mounted. SQL> alter database noarchivelog; Database altered. SQL> alter database open; Database altered. SQL> select name, open_mode, log_mode from v$database; NAME OPEN_MODE LOG_MODE --------- -------------------- ------------ NTAP1DEV READ WRITE NOARCHIVELOG SQL> show pdbs CON_ID CON_NAME OPEN MODE RESTRICTED ---------- ------------------------------ ---------- ---------- 2 PDB$SEED READ ONLY NO 3 NTAP1_PDB1 MOUNTED 4 NTAP1_PDB2 MOUNTED 5 NTAP1_PDB3 MOUNTED SQL> alter pluggable database all open;
Onde encontrar informações adicionais
Para saber mais sobre as informações descritas neste documento, revise os seguintes documentos e/ou sites:
-
Azure NetApp Files
-
Documentação do software SnapCenter
-
TR-4987: Implantação simplificada e automatizada do Oracle no Azure NetApp Files com NFS