

TR-5000: Backup, recuperação e clonagem de banco de dados PostgreSQL no ONTAP com SnapCenter
 Sugerir alterações
Sugerir alterações
Allen Cao, Niyaz Mohamed, NetApp
A solução fornece uma visão geral e detalhes para backup, recuperação e clonagem de banco de dados PostgreSQL no armazenamento ONTAP na nuvem pública ou no local por meio da ferramenta de interface de usuário de gerenciamento de banco de dados NetApp SnapCenter .
Propósito
O software NetApp SnapCenter software é uma plataforma empresarial fácil de usar para coordenar e gerenciar com segurança a proteção de dados em aplicativos, bancos de dados e sistemas de arquivos. Ele simplifica o gerenciamento do ciclo de vida de backup, restauração e clonagem, transferindo essas tarefas para os proprietários dos aplicativos sem sacrificar a capacidade de supervisionar e regular a atividade nos sistemas de armazenamento. Ao aproveitar o gerenciamento de dados baseado em armazenamento, ele permite maior desempenho e disponibilidade, bem como tempos reduzidos de teste e desenvolvimento.
Nesta documentação, mostramos a proteção e o gerenciamento do banco de dados PostgreSQL no armazenamento NetApp ONTAP na nuvem pública ou no local com uma ferramenta de interface de usuário SnapCenter muito fácil de usar.
Esta solução aborda os seguintes casos de uso:
-
Backup e recuperação de banco de dados PostgreSQL implantado no armazenamento NetApp ONTAP na nuvem pública ou no local.
-
Gerencie snapshots de banco de dados PostgreSQL e clone cópias para acelerar o desenvolvimento de aplicativos e melhorar o gerenciamento do ciclo de vida dos dados.
Público
Esta solução é destinada às seguintes pessoas:
-
Um DBA que gostaria de implantar bancos de dados PostgreSQL no armazenamento NetApp ONTAP .
-
Um arquiteto de soluções de banco de dados que gostaria de testar cargas de trabalho do PostgreSQL no armazenamento NetApp ONTAP .
-
Um administrador de armazenamento que gostaria de implantar e gerenciar bancos de dados PostgreSQL no armazenamento NetApp ONTAP .
-
Um proprietário de aplicativo que gostaria de configurar um banco de dados PostgreSQL no armazenamento NetApp ONTAP .
Ambiente de teste e validação de soluções
Os testes e a validação desta solução foram realizados em um ambiente de laboratório que pode não corresponder ao ambiente de implantação final. Veja a seçãoFatores-chave para consideração de implantação para maiores informações.
Arquitetura
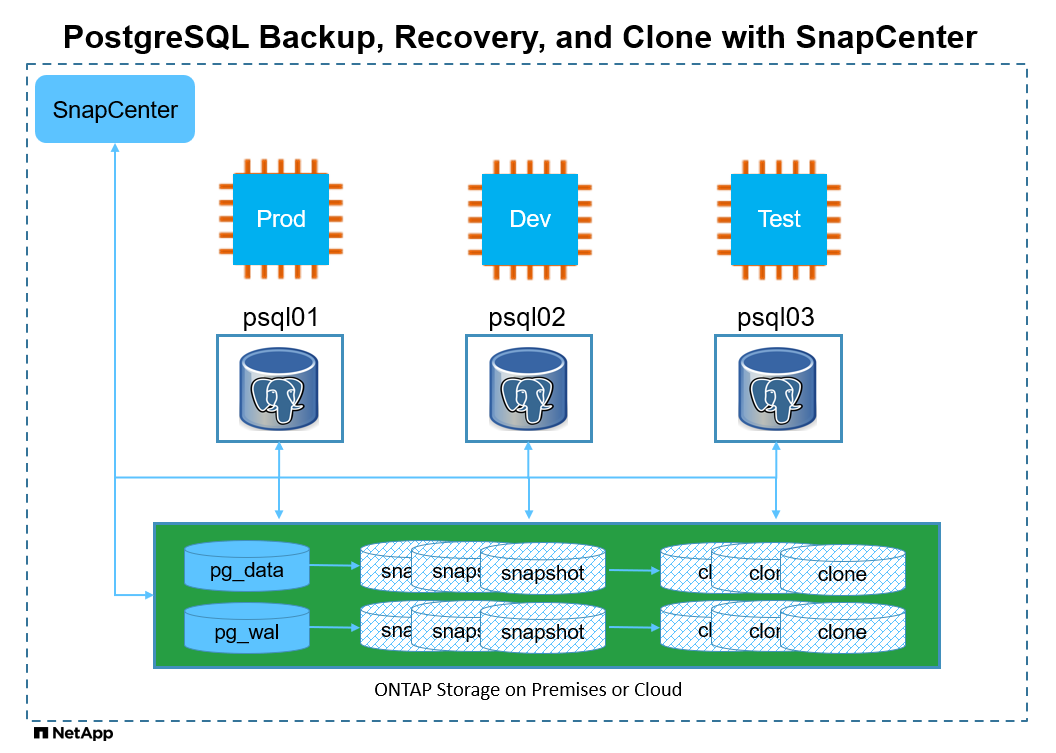
Componentes de hardware e software
Hardware |
||
NetApp AFF A220 |
Versão 9.12.1P2 |
Prateleira de disco DS224-12, módulo IOM12E, capacidade para 24 discos / 12 TiB |
Cluster VMware vSphere |
Versão 6.7 |
4 nós de computação ESXi NetApp HCI H410C |
Software |
||
RedHat Linux |
RHEL Linux 8.6 (LVM) - x64 Gen2 |
Assinatura RedHat implantada para teste |
Servidor Windows |
DataCenter 2022; AE Hotpatch - x64 Gen2 |
Hospedagem do servidor SnapCenter |
Banco de dados PostgreSQL |
Versão 14.13 |
Cluster de banco de dados PostgreSQL preenchido com esquema tpcc do HammerDB |
Servidor SnapCenter |
Versão 6.0 |
Implantação de grupo de trabalho |
Abra o JDK |
Versão java-11-openjdk |
Requisito do plugin SnapCenter em VMs de banco de dados |
NFS |
Versão 3.0 |
Separe os dados e registre em diferentes pontos de montagem |
Ansible |
núcleo 2.16.2 |
Python 3.6.8 |
Configuração do banco de dados PostgreSQL no ambiente de laboratório
Servidor |
Banco de dados |
Armazenamento de banco de dados |
psql01 |
Servidor de banco de dados primário |
/pgdata, /pglogs montagens de volume NFS no armazenamento ONTAP |
psql02 |
Clonar servidor de banco de dados |
/pgdata_clone, /pglogs_clone Montagens de volume de clone fino NFS no armazenamento ONTAP |
Fatores-chave para consideração de implantação
-
* Implantação do SnapCenter .* O SnapCenter pode ser implantado em um domínio do Windows ou em um ambiente de grupo de trabalho. Para implantação baseada em domínio, a conta de usuário do domínio deve ser uma conta de administrador de domínio ou o usuário do domínio deve pertencer ao grupo de administradores locais no servidor de hospedagem do SnapCenter .
-
Resolução de nomes. O servidor SnapCenter precisa resolver o nome para o endereço IP de cada host do servidor de banco de dados de destino gerenciado. Cada host do servidor de banco de dados de destino deve resolver o nome do servidor SnapCenter para o endereço IP. Se um servidor DNS não estiver disponível, adicione nomes aos arquivos do host local para resolução.
-
Configuração do grupo de recursos. O grupo de recursos no SnapCenter é um agrupamento lógico de recursos semelhantes que podem ser copiados juntos. Dessa forma, simplifica e reduz o número de tarefas de backup em um ambiente de banco de dados grande.
-
Backup completo separado do banco de dados e do log de arquivo. O backup completo do banco de dados inclui volumes de dados e volumes de log com instantâneos de grupo consistentes. Um snapshot completo e frequente do banco de dados gera maior consumo de armazenamento, mas melhora o RTO. Uma alternativa é fazer snapshots completos do banco de dados com menos frequência e fazer backups de logs de arquivo com mais frequência, o que consome menos armazenamento e melhora o RPO, mas pode estender o RTO. Considere seus objetivos de RTO e RPO ao configurar o esquema de backup. Também há um limite (1023) do número de backups de instantâneos em um volume.
-
* Delegação de Privileges .* Aproveite o controle de acesso baseado em funções integrado à interface de usuário do SnapCenter para delegar privilégios às equipes de aplicativos e bancos de dados, se desejar.
Implantação da solução
As seções a seguir fornecem procedimentos passo a passo para implantação, configuração, backup, recuperação e clonagem do banco de dados PostgreSQL do SnapCenter no armazenamento NetApp ONTAP na nuvem pública ou no local.
Pré-requisitos para implantação
Details
-
A implantação requer dois bancos de dados PostgreSQL existentes em execução no armazenamento ONTAP , um como servidor de banco de dados principal e o outro como servidor de banco de dados clone. Para referência sobre implantação de banco de dados PostgreSQL no ONTAP, consulte TR-4956:"Implantação automatizada de alta disponibilidade do PostgreSQL e recuperação de desastres no AWS FSx/EC2" , procurando o manual de implantação automatizada do PostgreSQL na instância primária.
-
Provisione um servidor Windows para executar a ferramenta NetApp SnapCenter UI com a versão mais recente. Consulte o link a seguir para obter detalhes:"Instalar o SnapCenter Server" .
Instalação e configuração do SnapCenter
Details
Recomendamos que você faça isso online"Documentação do software SnapCenter" antes de prosseguir com a instalação e configuração do SnapCenter : . A seguir, fornecemos um resumo de alto nível das etapas para instalação e configuração do SnapCenter software para PostgreSQL no ONTAP.
-
No servidor SnapCenter Windows, baixe e instale o Java JDK mais recente em"Obtenha Java para aplicativos de desktop" . Desative o firewall do Windows.
-
No servidor SnapCenter Windows, baixe e instale ou atualize os pré-requisitos do SnapCenter 6.0 Windows: PowerShell - PowerShell-7.4.3-win-x64.msi e pacote de hospedagem .Net - dotnet-hosting-8.0.6-win.
-
No servidor SnapCenter Windows, baixe e instale a versão mais recente (atualmente 6.0) do executável de instalação do SnapCenter do site de suporte da NetApp :"NetApp | Suporte" .
-
A partir das VMs do banco de dados, habilite a autenticação sem senha SSH para o usuário administrador
admine seus privilégios sudo sem senha. -
Nas VMs do banco de dados, pare e desabilite o firewall do Linux. Instale o java-11-openjdk.
-
No servidor SnapCenter Windows, inicie o navegador para efetuar login no SnapCenter com o usuário administrador local do Windows ou com a credencial de usuário de domínio pela porta 8146.
-
Análise
Get Startedcardápio online.
-
Em
Settings-Global Settings, verificarHypervisor Settingse clique em Atualizar.
-
Se necessário, ajuste
Session Timeoutpara SnapCenter UI para o intervalo desejado.
-
Adicione usuários adicionais ao SnapCenter , se necessário.
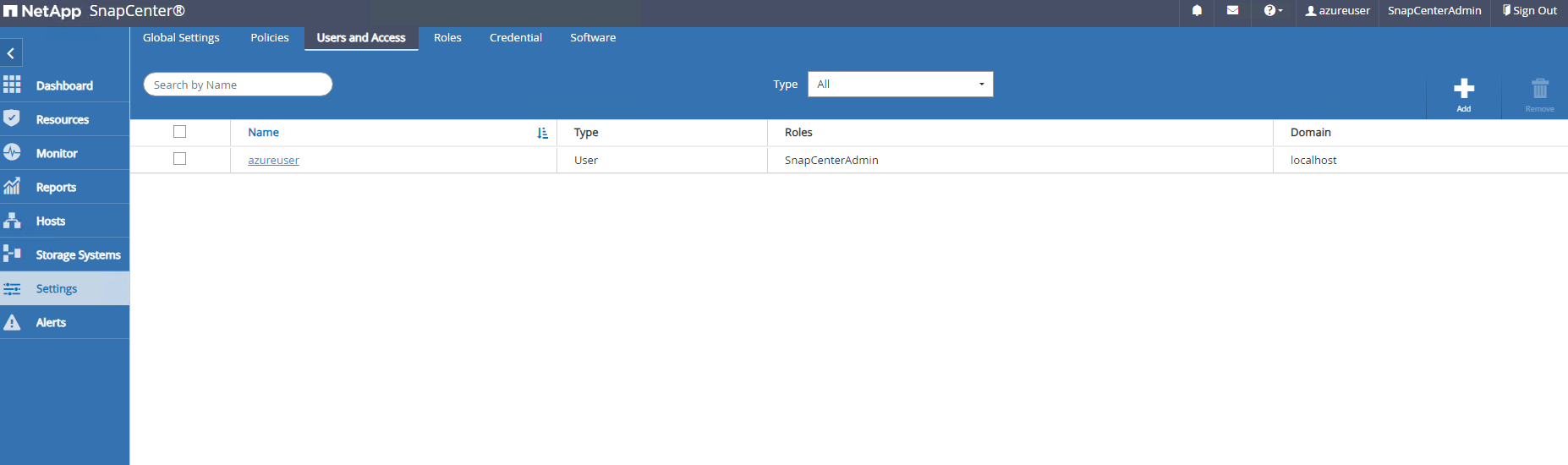
-
O
Roleslista de guias as funções integradas que podem ser atribuídas a diferentes usuários do SnapCenter . Funções personalizadas também podem ser criadas pelo usuário administrador com os privilégios desejados.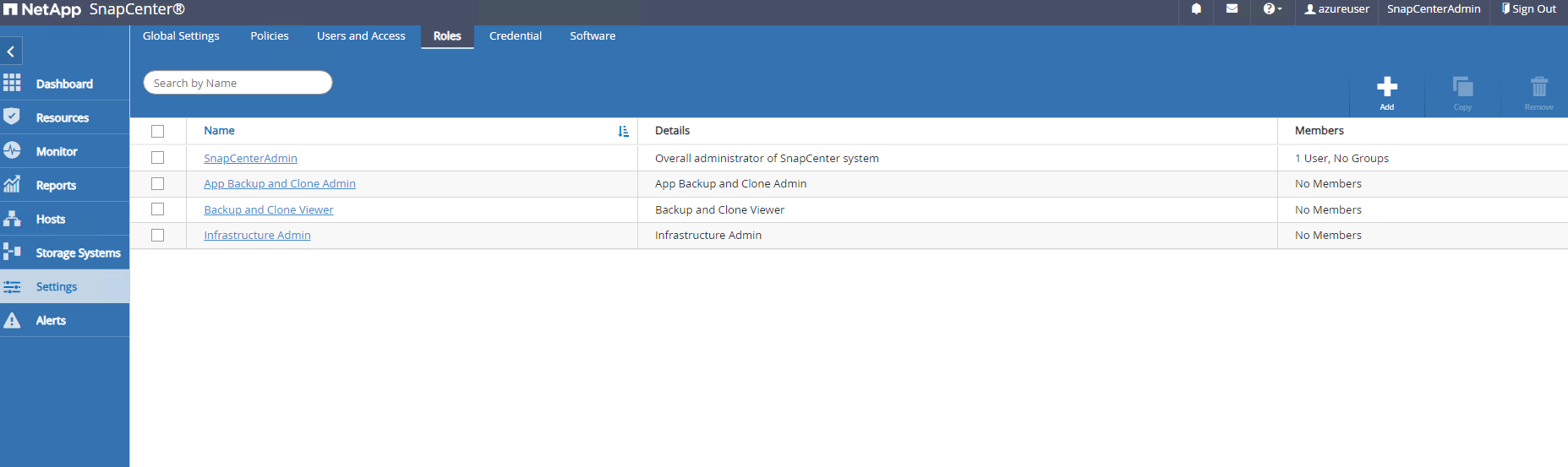
-
De
Settings-Credential, crie credenciais para destinos de gerenciamento do SnapCenter . Neste caso de uso de demonstração, eles são o usuário administrador do Linux para login na VM do servidor de banco de dados e a credencial do Postgres para acesso ao PostgreSQL.

Redefina a senha do usuário postgres do PostgreSQL antes de criar a credencial. -
De
Storage Systemsaba, adicionarONTAP clustercom credencial de administrador de cluster ONTAP . Para o Azure NetApp Files, você precisará criar uma credencial específica para acesso ao pool de capacidade.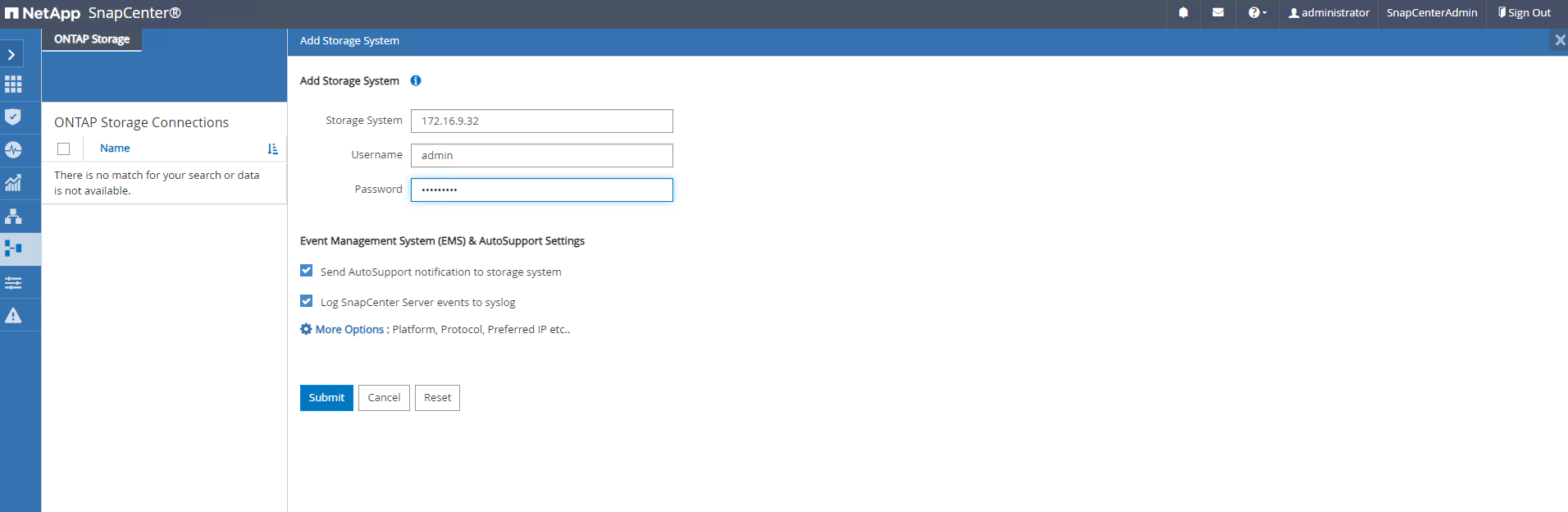
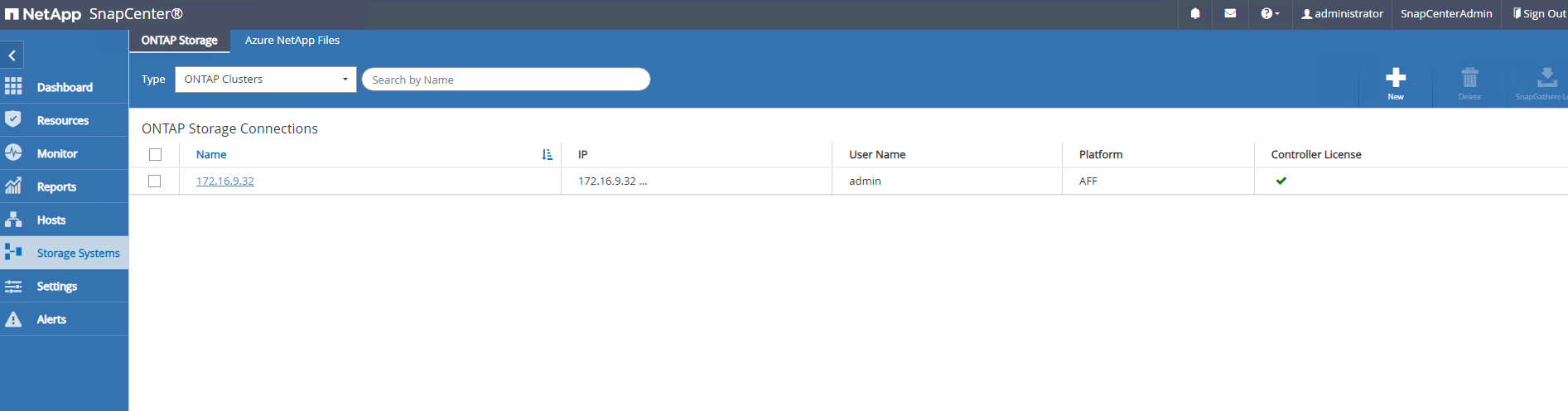
-
De
Hostsguia, adicione VMs do PostgreSQL DB, que instala o plugin SnapCenter para PostgreSQL no Linux.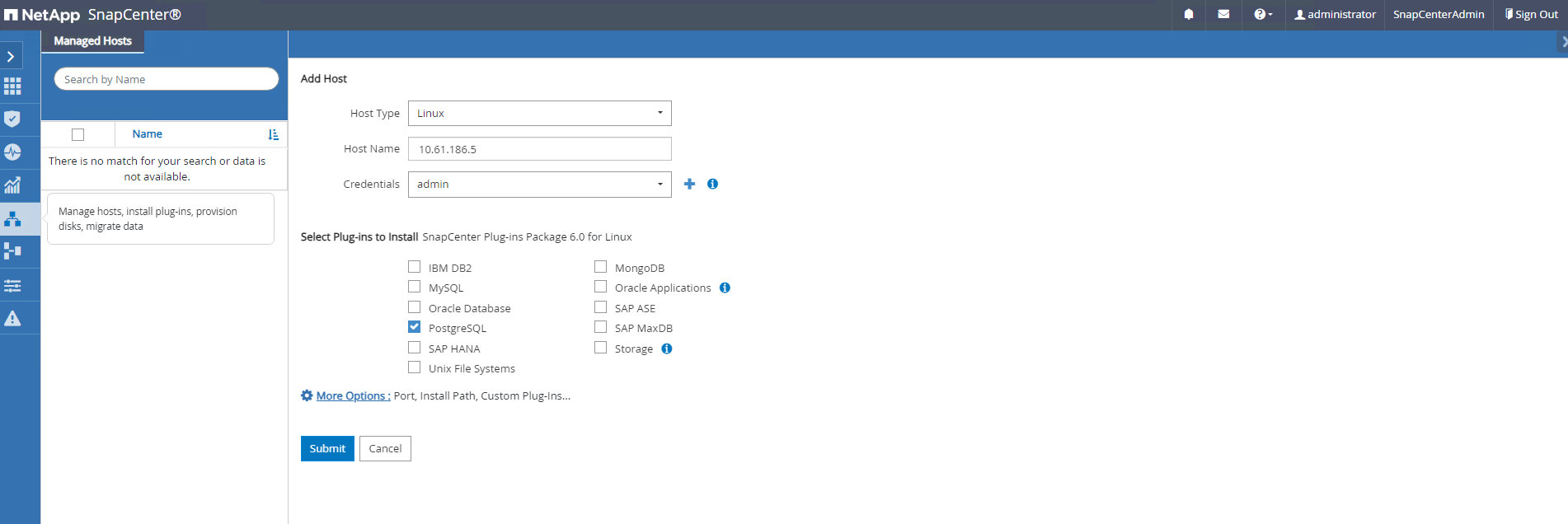
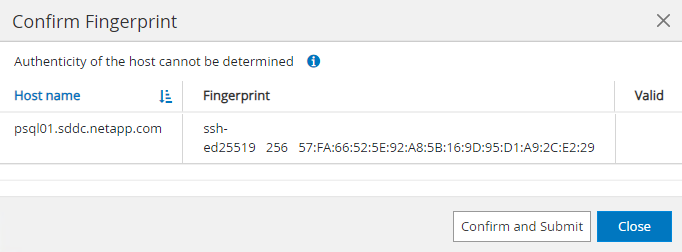
-
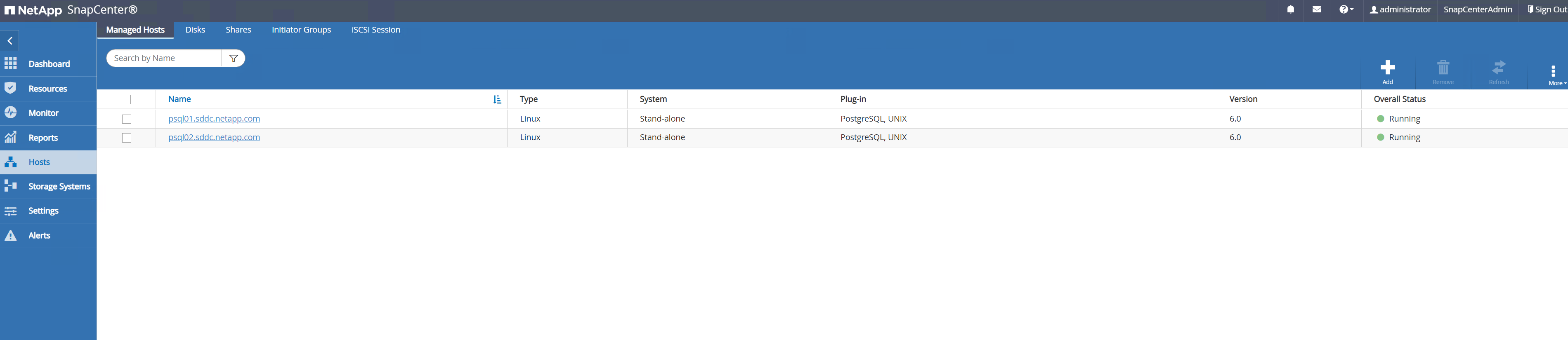
Depois que o plugin do host é instalado na VM do servidor DB, os bancos de dados no host são descobertos automaticamente e ficam visíveis em
Resourcesaba.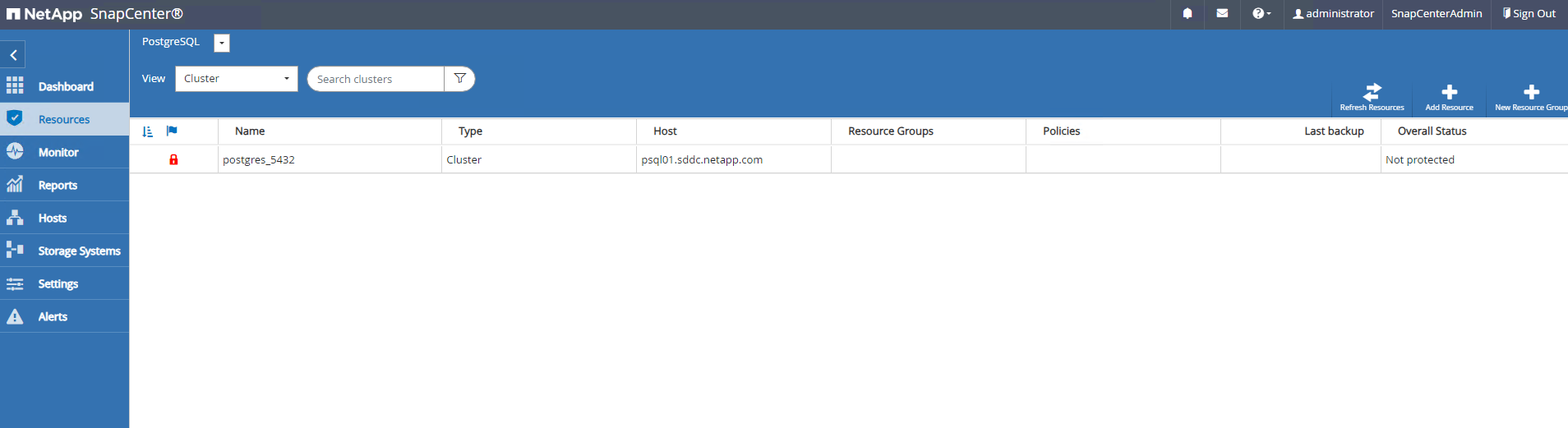
Backup de banco de dados
Details
O cluster PostgreSQL descoberto automaticamente exibe um cadeado vermelho ao lado do nome do cluster. Ele deve ser desbloqueado usando a credencial do banco de dados PostgreSQL criada durante a configuração do SnapCenter na seção anterior. Em seguida, você precisa criar e aplicar uma política de backup para proteger o banco de dados. Por fim, execute o backup manualmente ou por meio de um agendador para criar um backup SnapShot. A seção a seguir demonstra os procedimentos passo a passo.
-
Desbloqueie o cluster PostgreSQL.
-
Navegando para
Resourcesguia, que lista o cluster PostgreSQL descoberto após o plugin SnapCenter ser instalado na VM do banco de dados. Inicialmente, ele está bloqueado e oOverall Statusdo cluster de banco de dados mostra comoNot protected. -
Clique no nome do cluster e então,
Configure Credentialspara abrir a página de configuração de credenciais.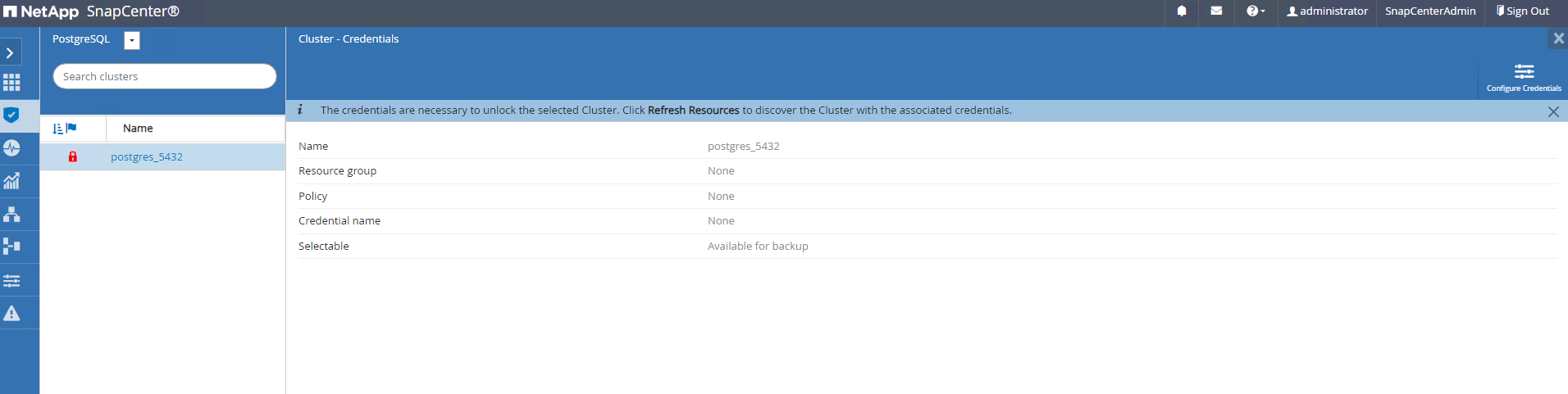
-
Escolher
postgrescredencial criada durante a configuração anterior do SnapCenter .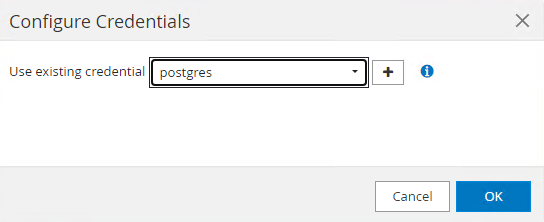
-
Depois que a credencial for aplicada, o cluster será desbloqueado.

-
-
Crie uma política de backup do PostgreSQL.
-
Navegar para
Setting-Policese clique emNewpara criar uma política de backup.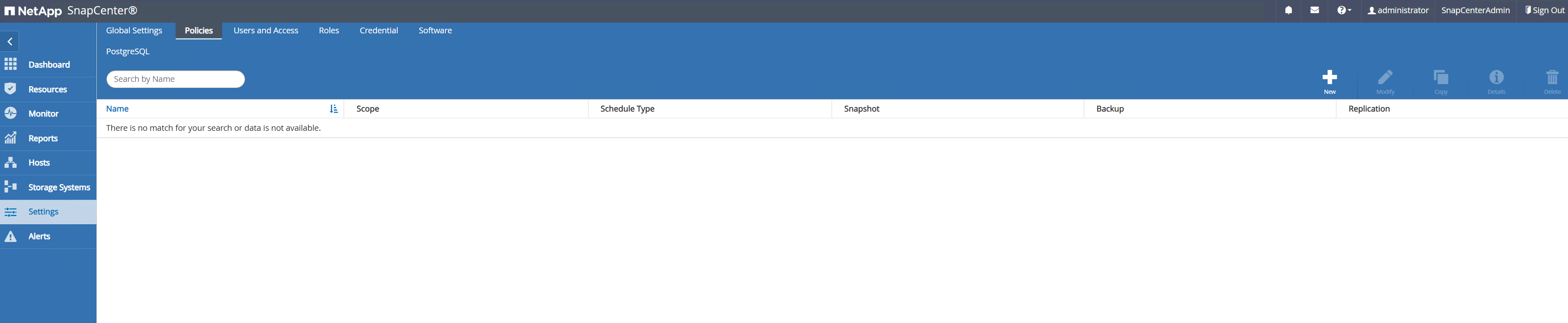
-
Nomeie a política de backup.
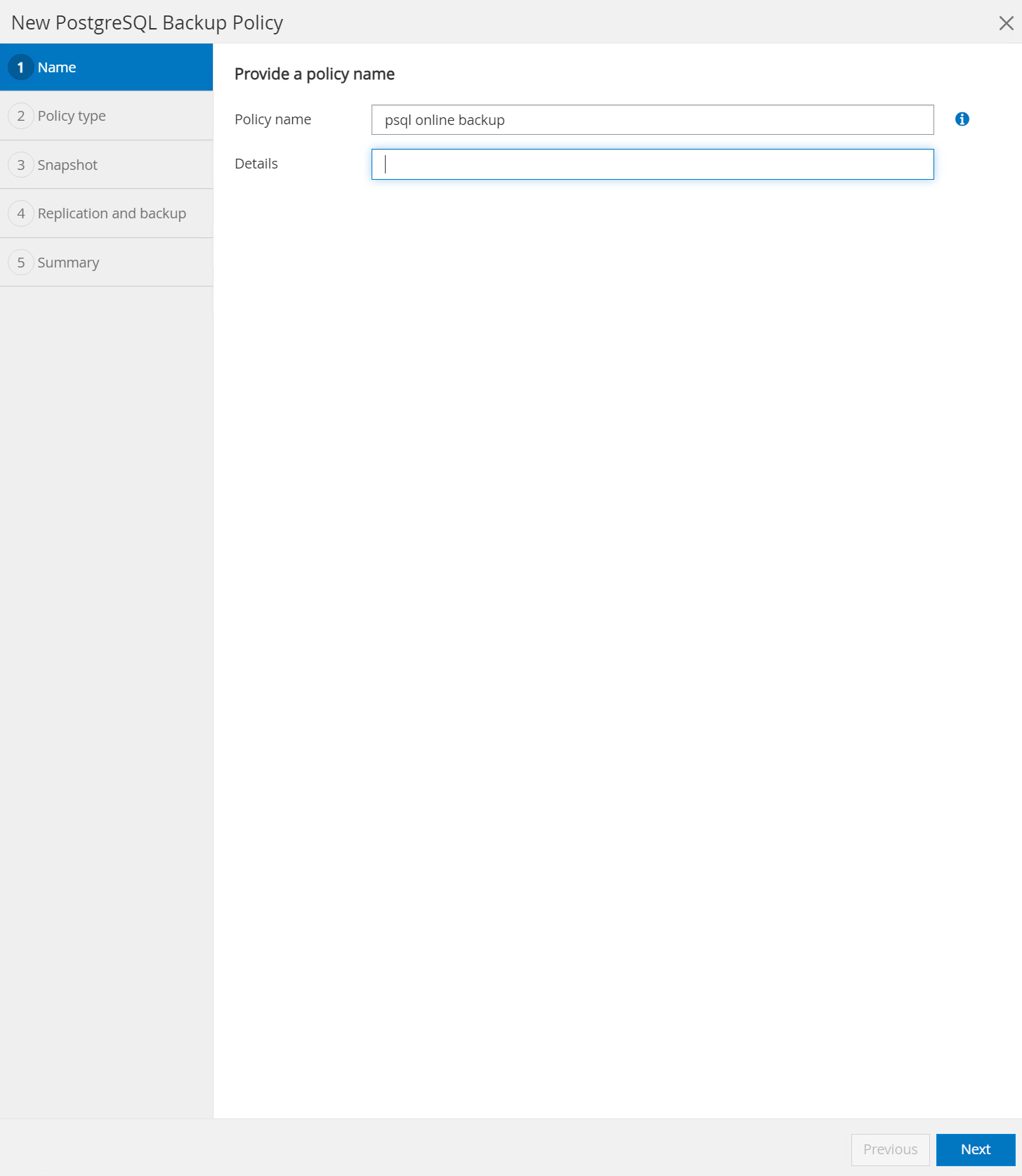
-
Escolha o tipo de armazenamento. A configuração de backup padrão deve ser adequada para a maioria dos cenários.
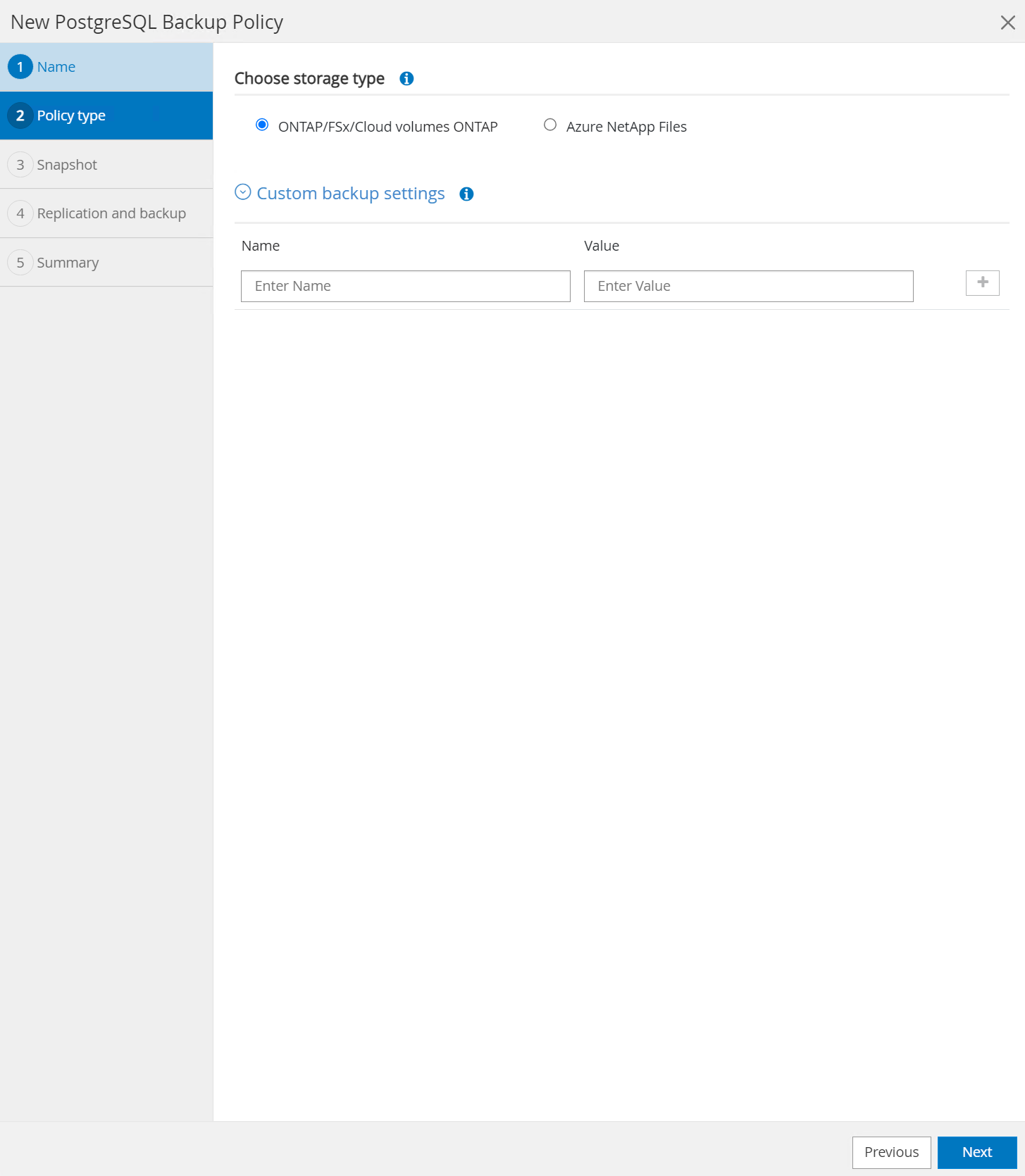
-
Defina a frequência de backup e a retenção do SnapShot.
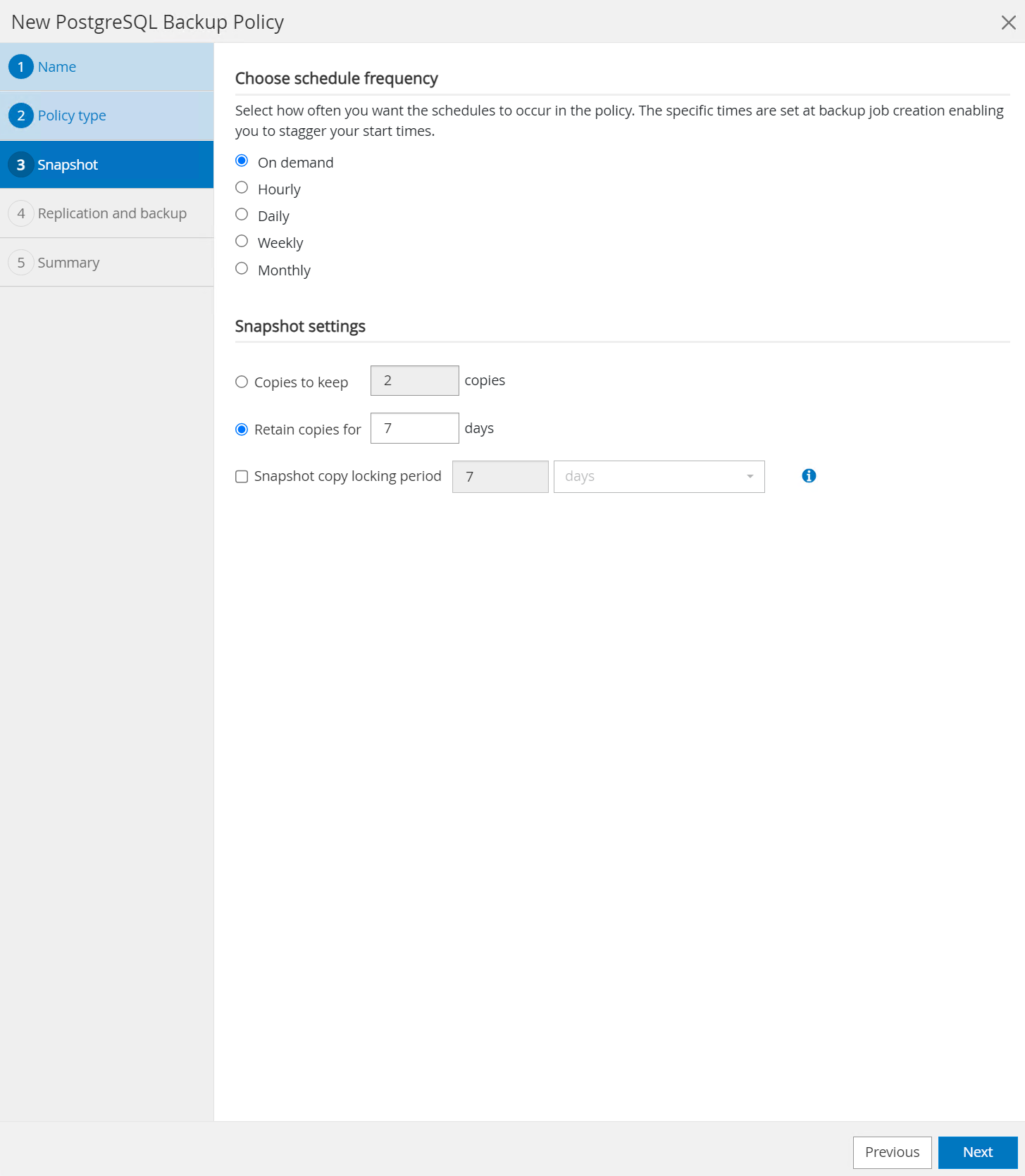
-
Opção para selecionar replicação secundária se os volumes do banco de dados forem replicados para um local secundário.
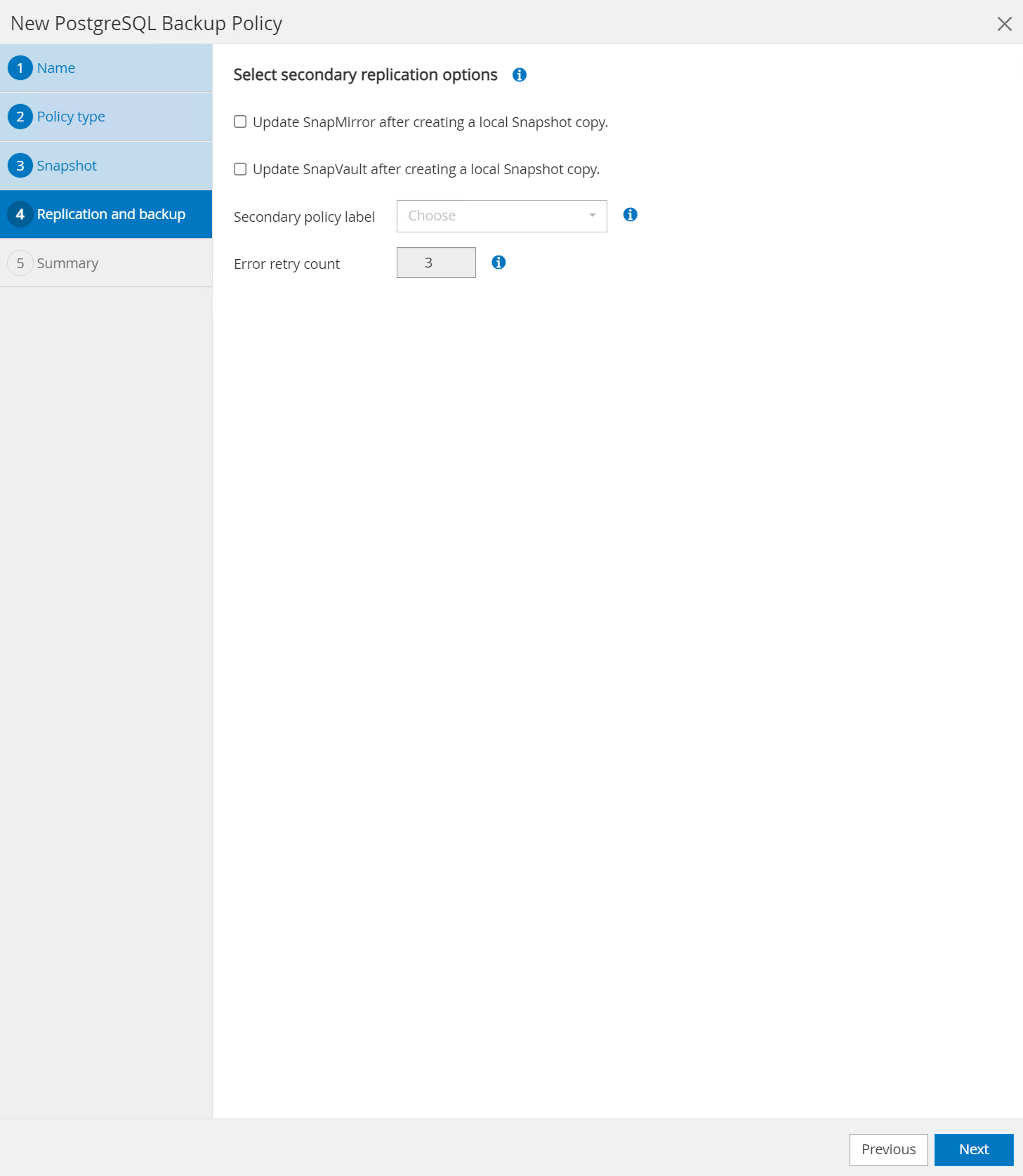
-
Revise o resumo e
Finishpara criar a política de backup.
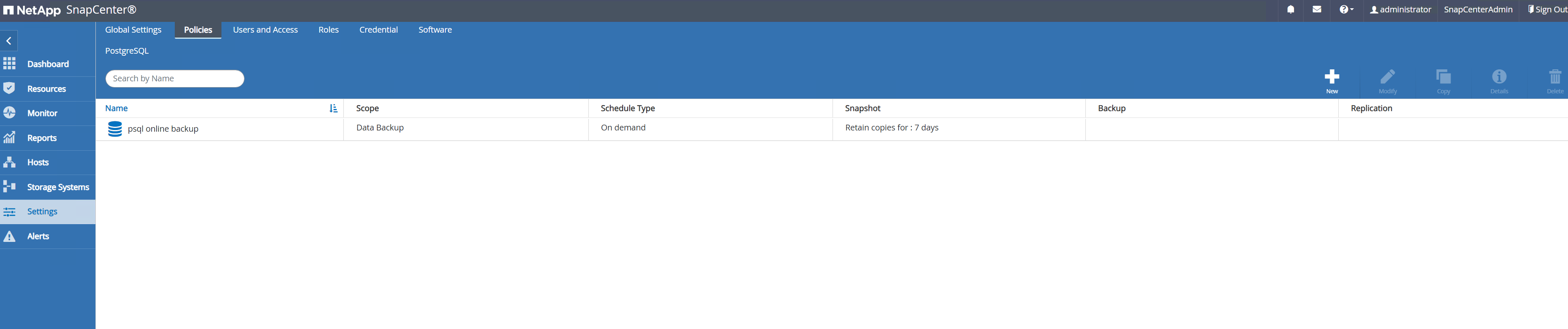
-
-
Aplique uma política de backup para proteger o banco de dados PostgreSQL.
-
Navegar de volta para
Resourceguia, clique no nome do cluster para iniciar o fluxo de trabalho de proteção do cluster PostgreSQL.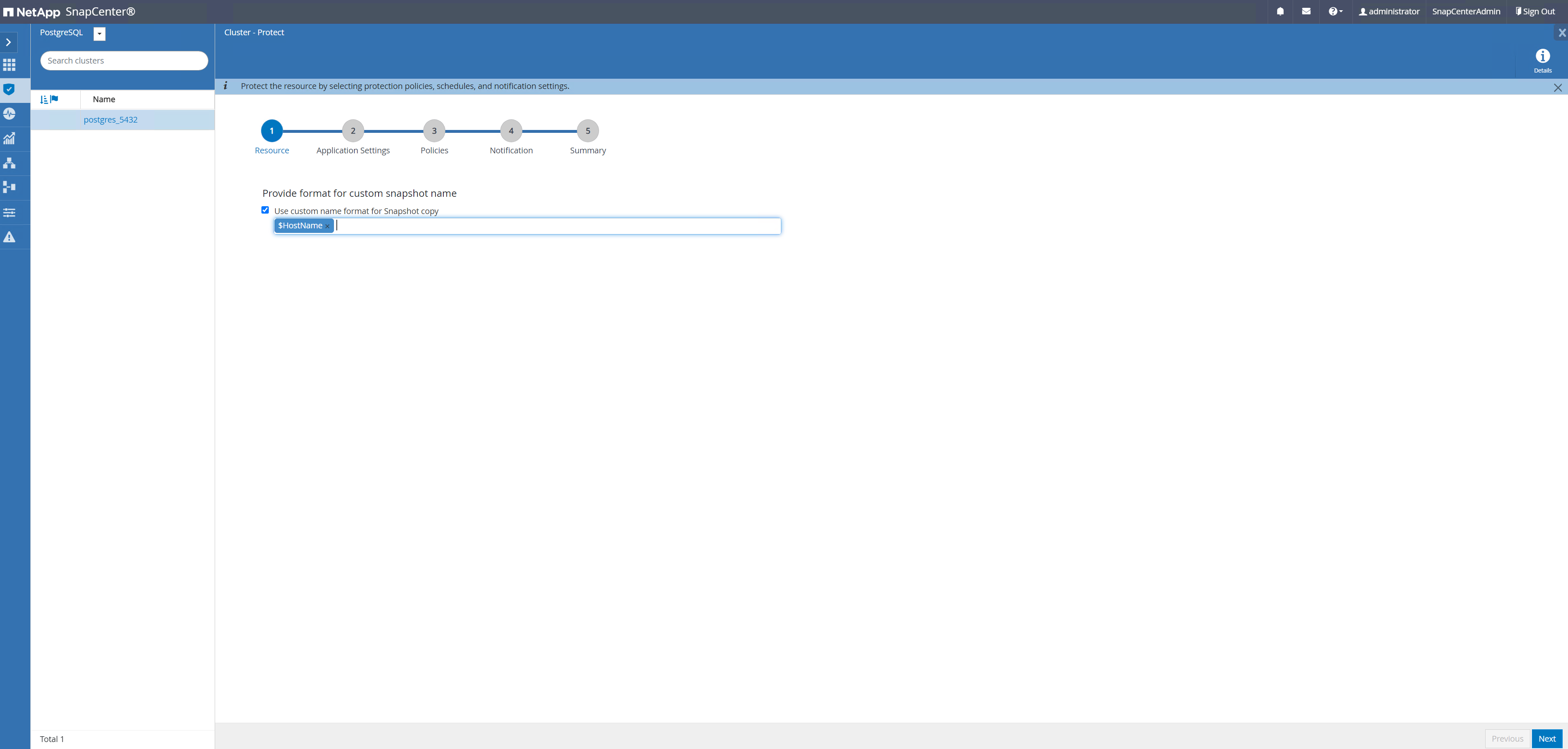
-
Aceitar padrão
Application Settings. Muitas das opções nesta página não se aplicam ao alvo descoberto automaticamente.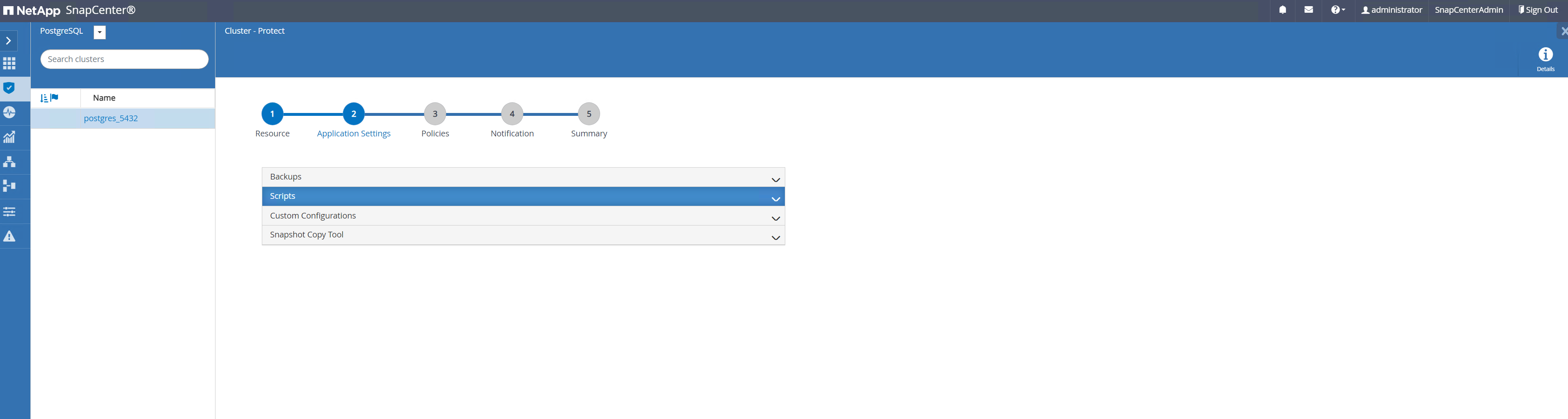
-
Aplique a política de backup recém-criada. Adicione um agendamento de backup, se necessário.
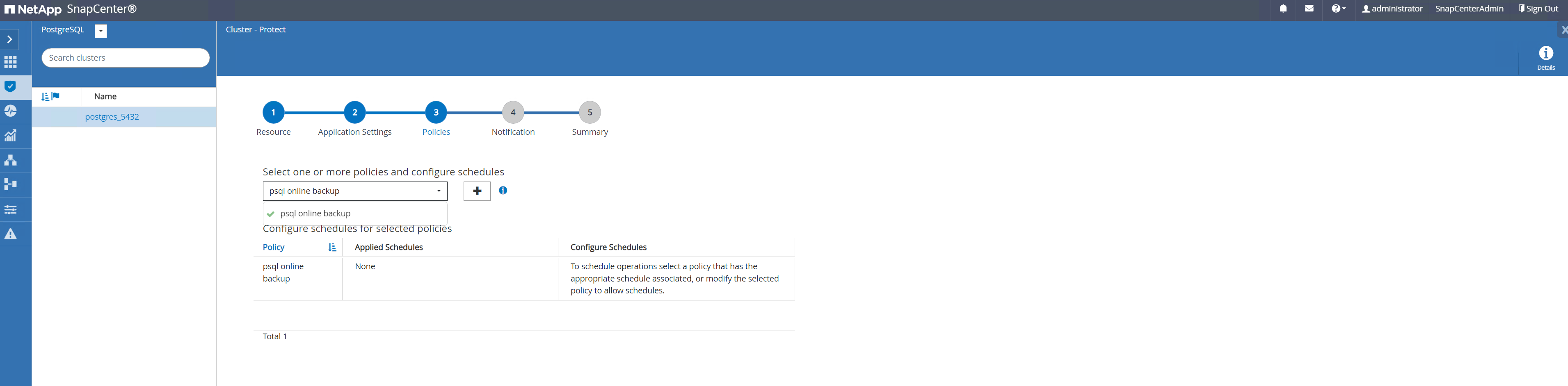
-
Forneça a configuração de e-mail se a notificação de backup for necessária.
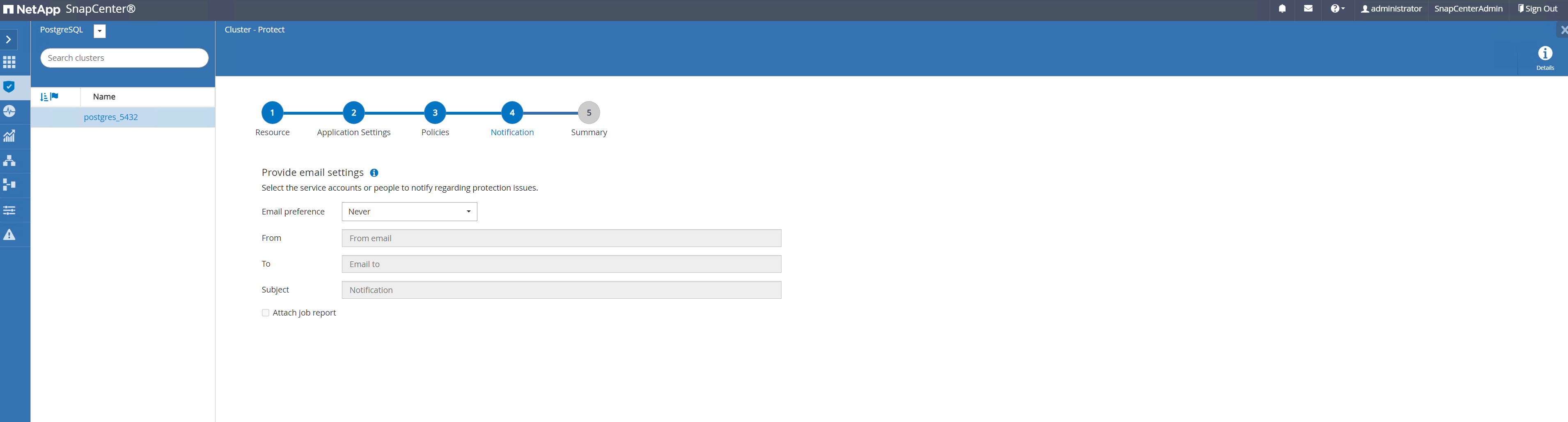
-
Resumo da revisão e
Finishpara implementar a política de backup. Agora o cluster PostgreSQL está protegido.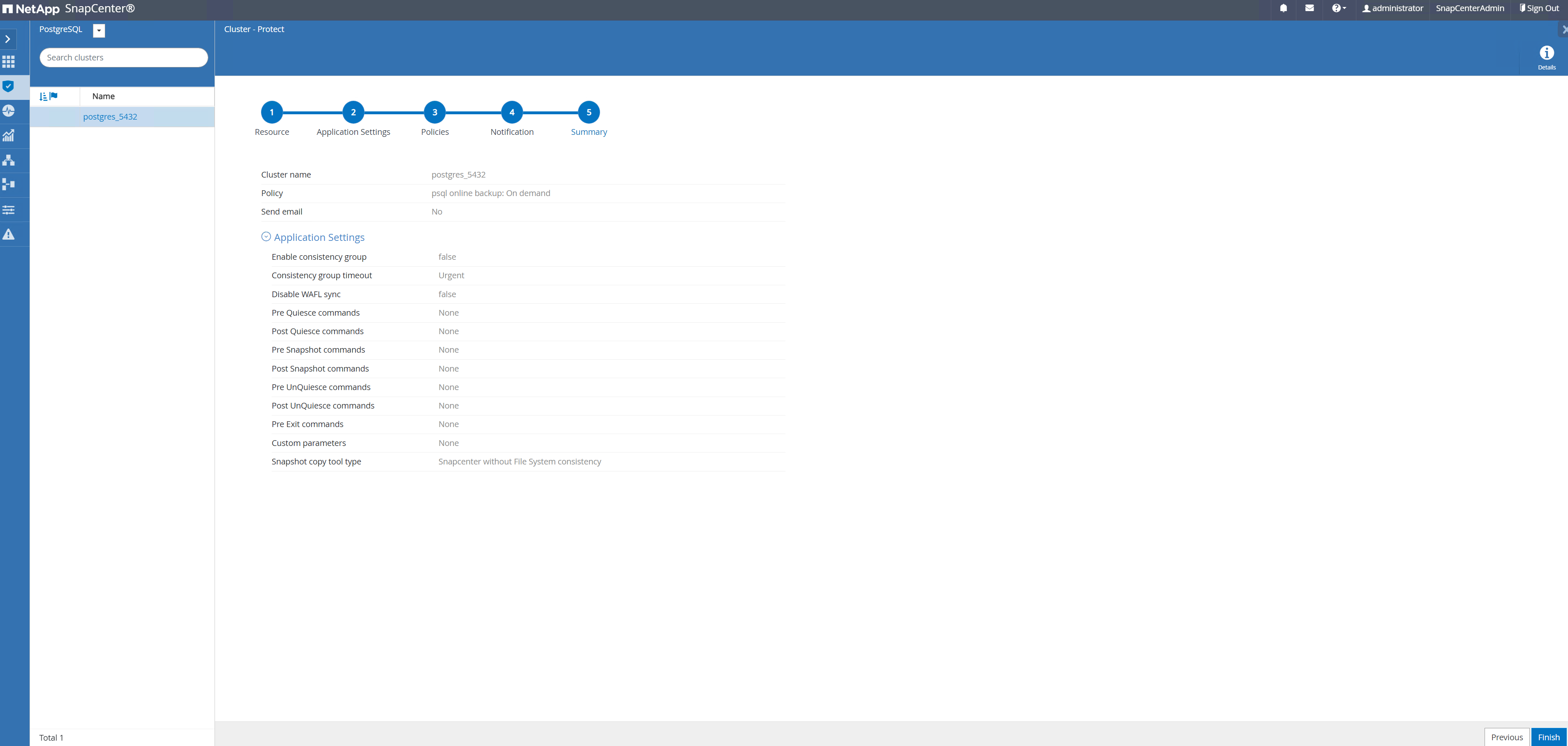
-
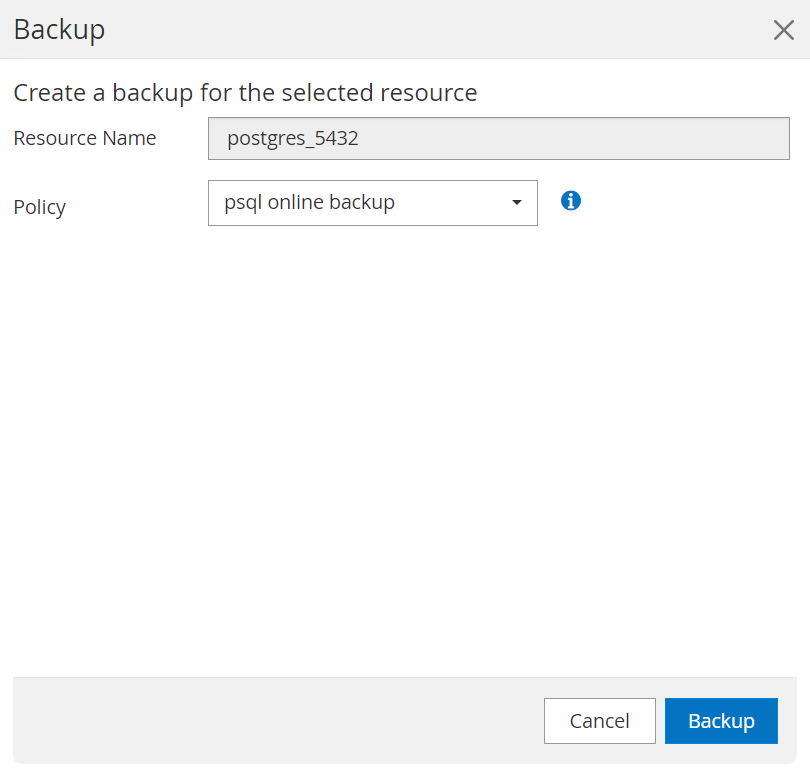
O backup é executado de acordo com o agendamento de backup ou da topologia de backup do cluster, clique em
Backup Nowpara acionar um backup manual sob demanda.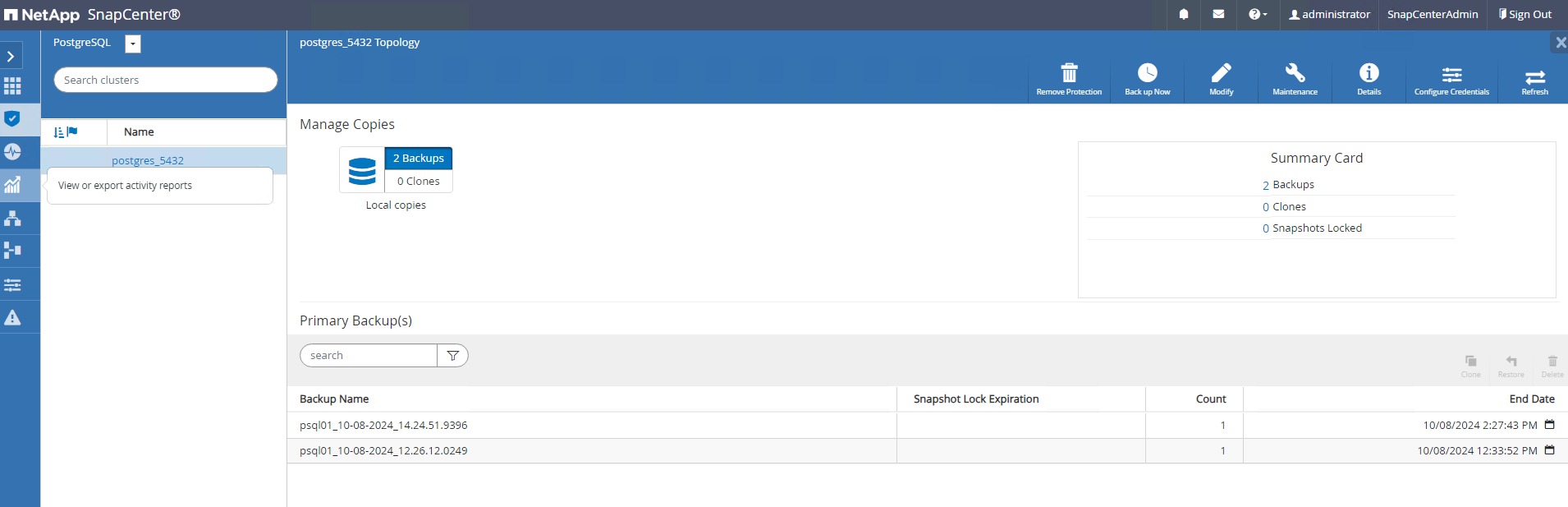
-
Monitore o trabalho de backup de
Monitoraba. Geralmente, leva alguns minutos para fazer backup de um banco de dados grande e, em nosso caso de teste, levou cerca de 4 minutos para fazer backup de volumes de banco de dados próximos a 1 TB.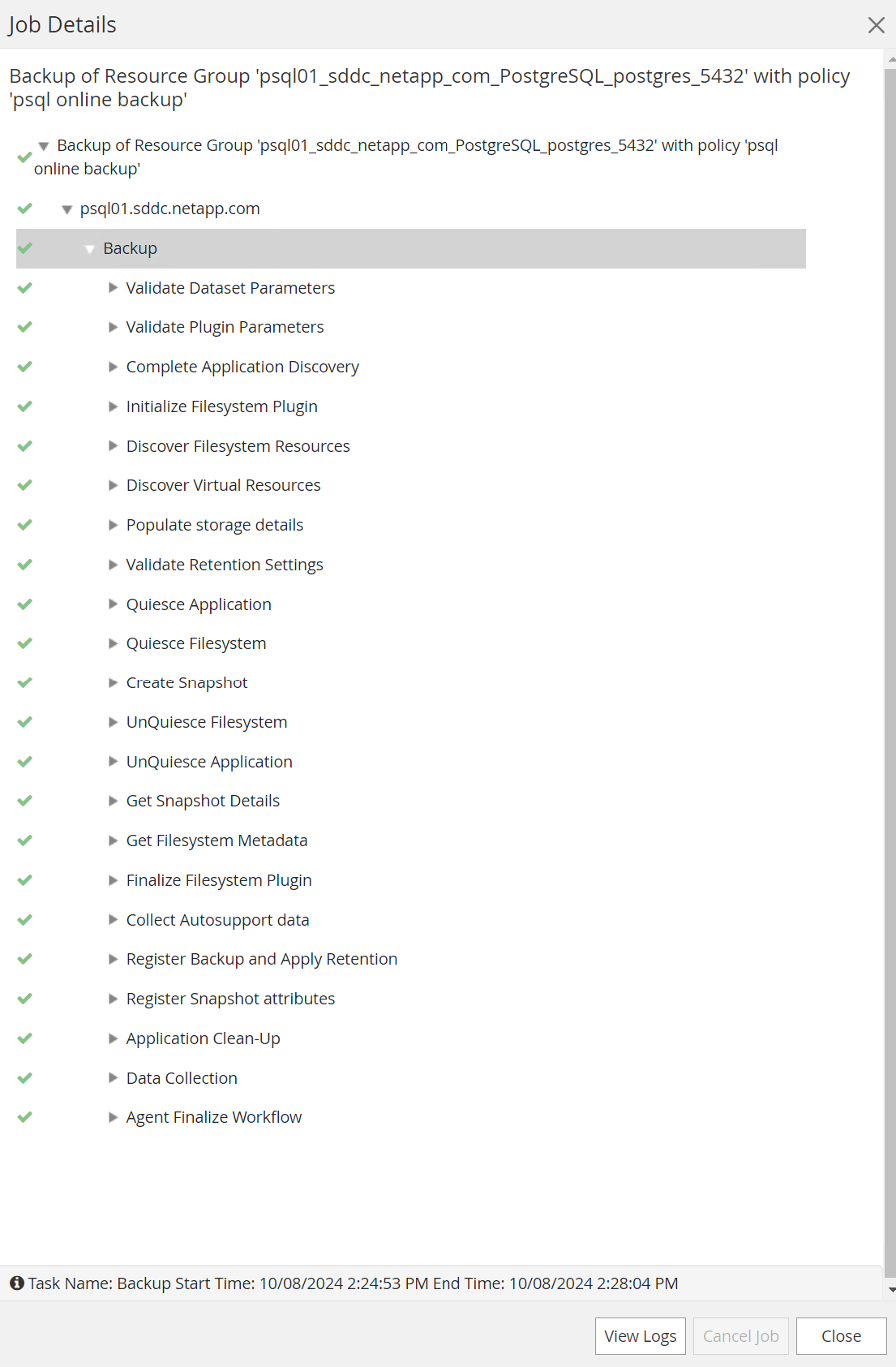
-
Recuperação de banco de dados
Details
Nesta demonstração de recuperação de banco de dados, mostramos uma recuperação pontual do cluster de banco de dados PostgreSQL. Primeiro, crie um backup SnapShot do volume do banco de dados no armazenamento ONTAP usando o SnapCenter. Em seguida, faça login no banco de dados, crie uma tabela de teste, anote o registro de data e hora e exclua a tabela de teste. Agora inicie uma recuperação do backup até o registro de data e hora em que a tabela de teste é criada para recuperar a tabela descartada. A seguir, são capturados os detalhes do fluxo de trabalho e da validação da recuperação de ponto no tempo do banco de dados PostgreSQL com a interface do usuário do SnapCenter .
-
Faça login no PostgreSQL como
postgresusuário. Crie e depois exclua uma tabela de teste.postgres=# \dt Did not find any relations. postgres=# create table test (id integer, dt timestamp, event varchar(100)); CREATE TABLE postgres=# \dt List of relations Schema | Name | Type | Owner --------+------+-------+---------- public | test | table | postgres (1 row) postgres=# insert into test values (1, now(), 'test PostgreSQL point in time recovery with SnapCenter'); INSERT 0 1 postgres=# select * from test; id | dt | event ----+----------------------------+-------------------------------------------------------- 1 | 2024-10-08 17:55:41.657728 | test PostgreSQL point in time recovery with SnapCenter (1 row) postgres=# drop table test; DROP TABLE postgres=# \dt Did not find any relations. postgres=# select current_time; current_time -------------------- 17:59:20.984144+00 -
De
Resourcesguia, abra a página de backup do banco de dados. Selecione o backup do SnapShot a ser restaurado. Em seguida, clique emRestorebotão para iniciar o fluxo de trabalho de recuperação do banco de dados. Observe o registro de data e hora do backup ao executar uma recuperação pontual.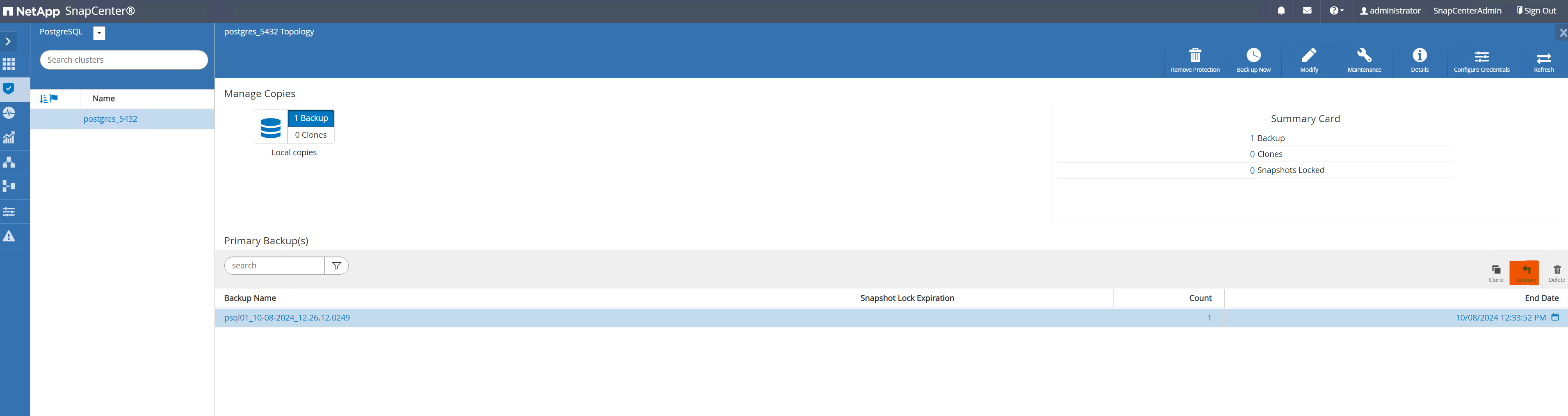
-
Selecione
Restore scope. Neste momento, um recurso completo é a única opção.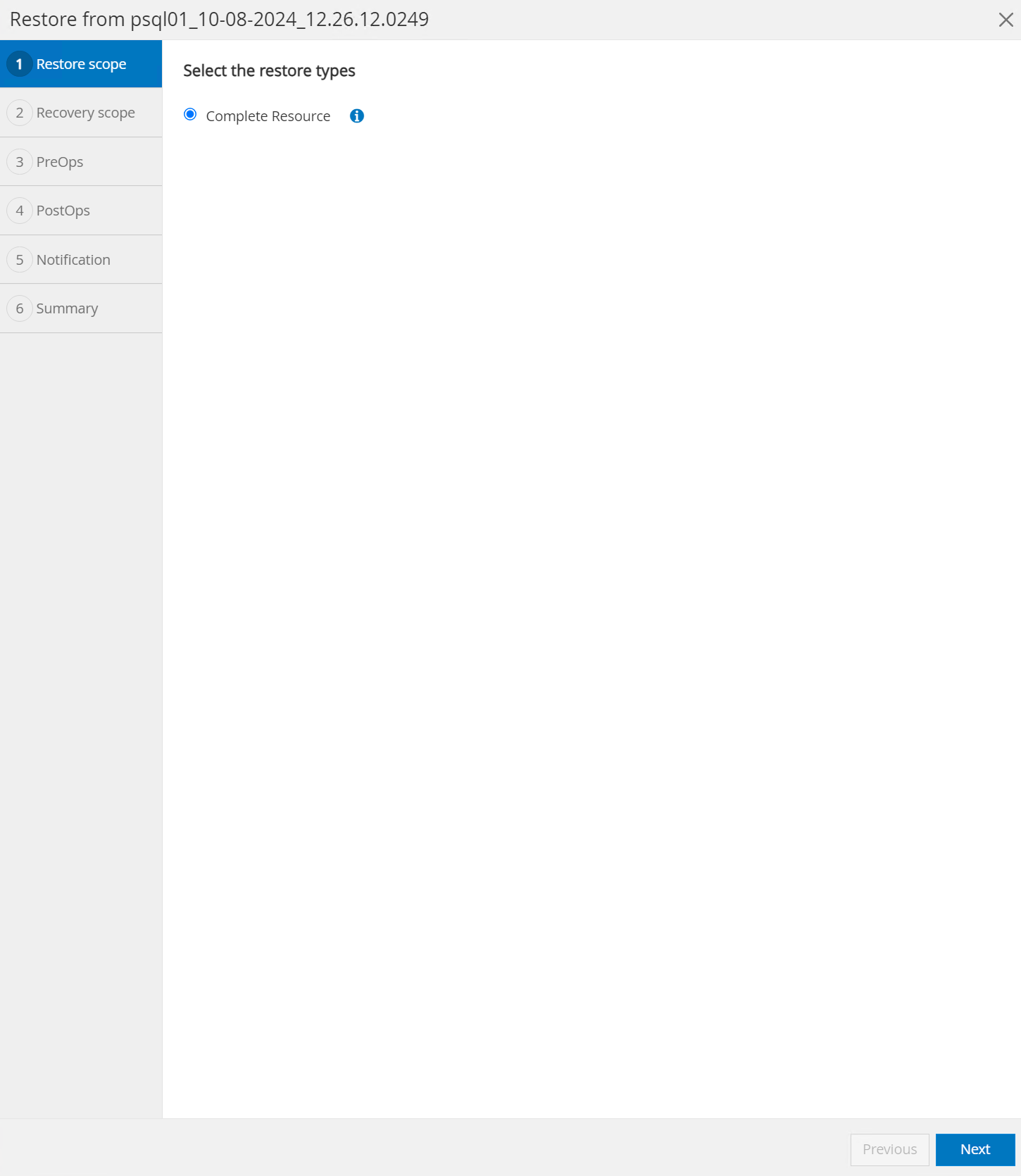
-
Para
Recovery Scope, escolherRecover to point in timee insira o registro de data e hora para o qual a recuperação será rolada para frente.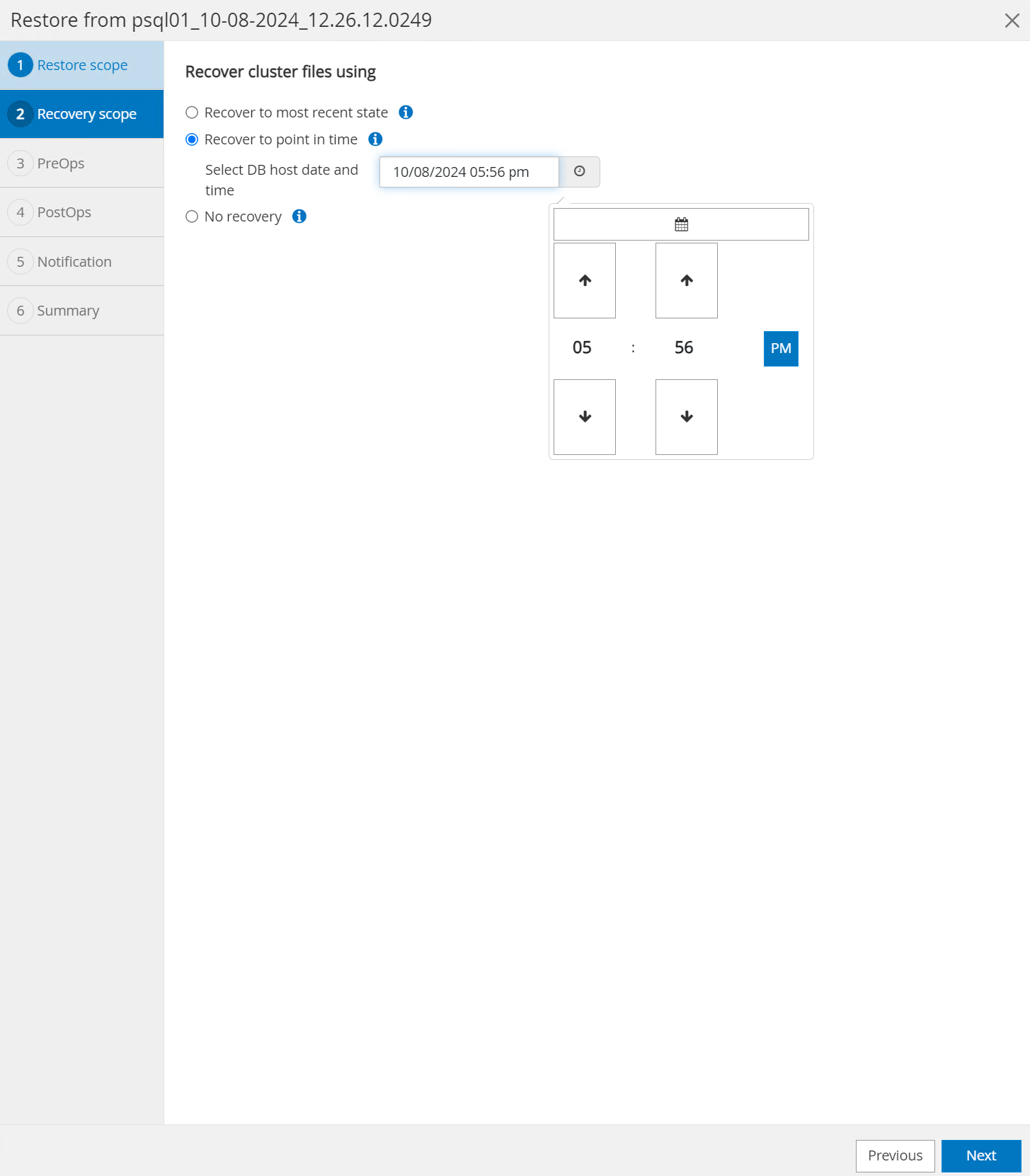
-
O
PreOpspermite a execução de scripts no banco de dados antes da operação de restauração/recuperação ou simplesmente deixá-lo em preto.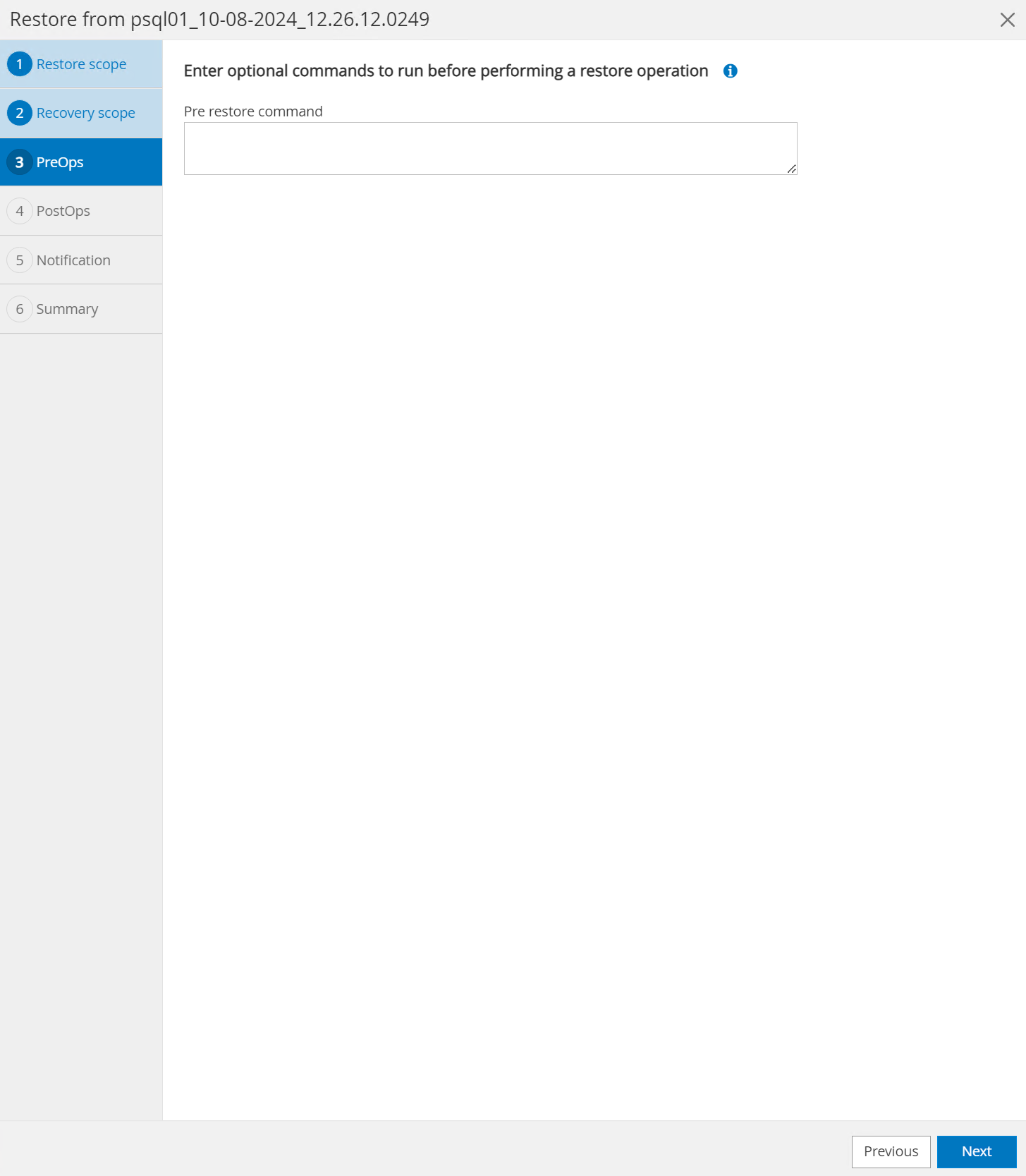
-
O
PostOpspermite a execução de scripts no banco de dados após a operação de restauração/recuperação ou apenas deixá-lo em preto.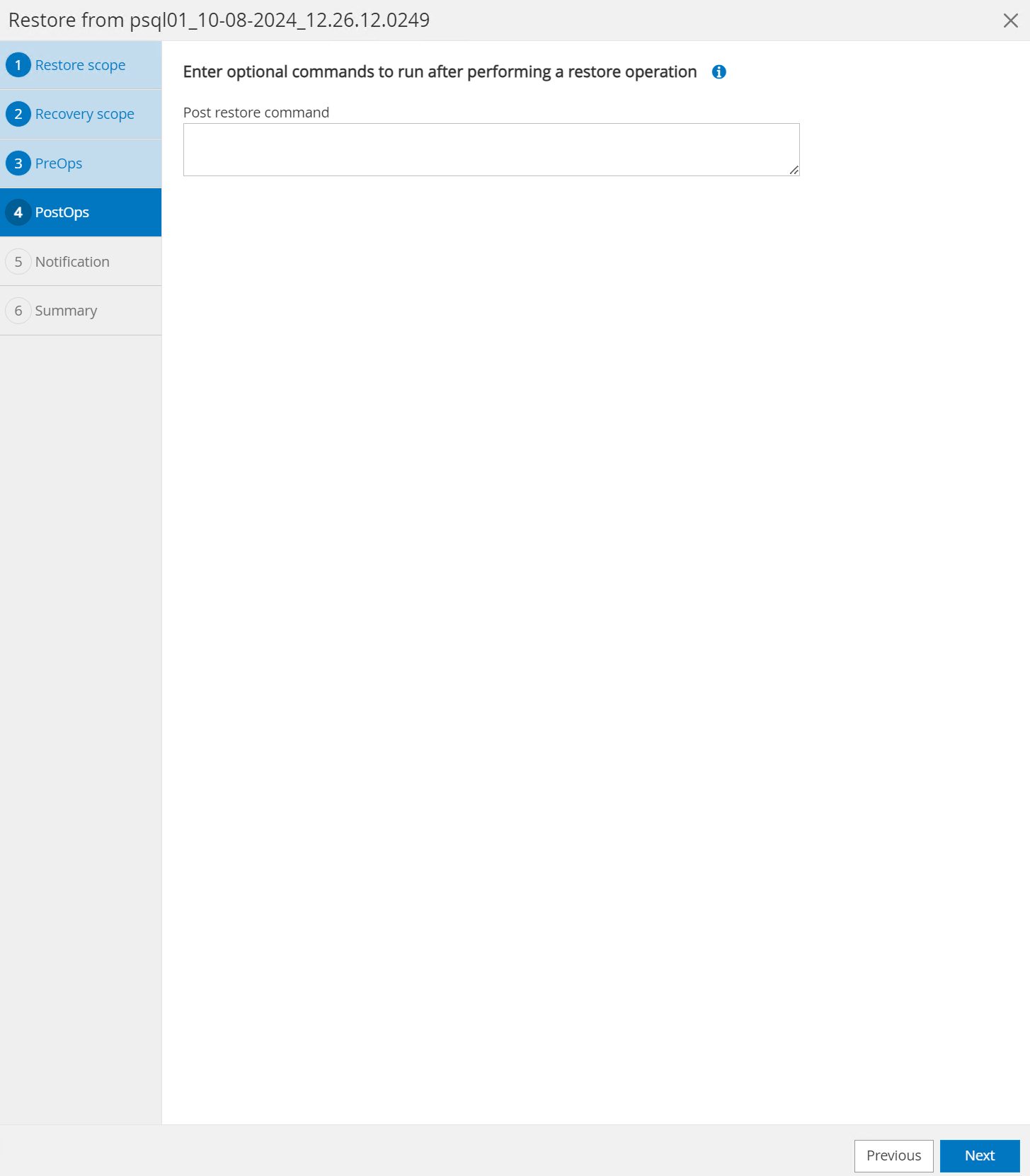
-
Notificação por e-mail, se desejado.
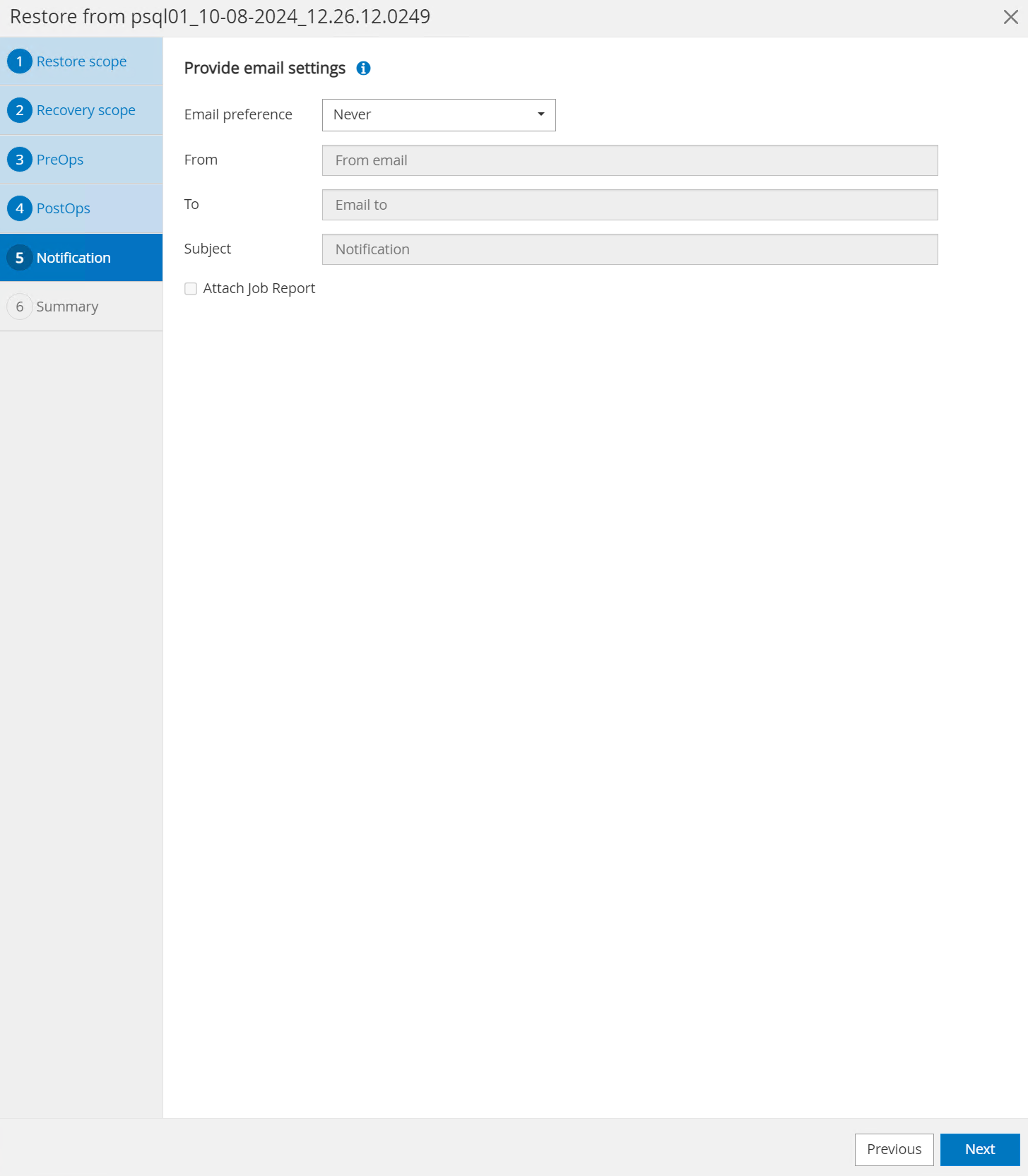
-
Revise o resumo do trabalho e
Finishpara iniciar o trabalho de restauração.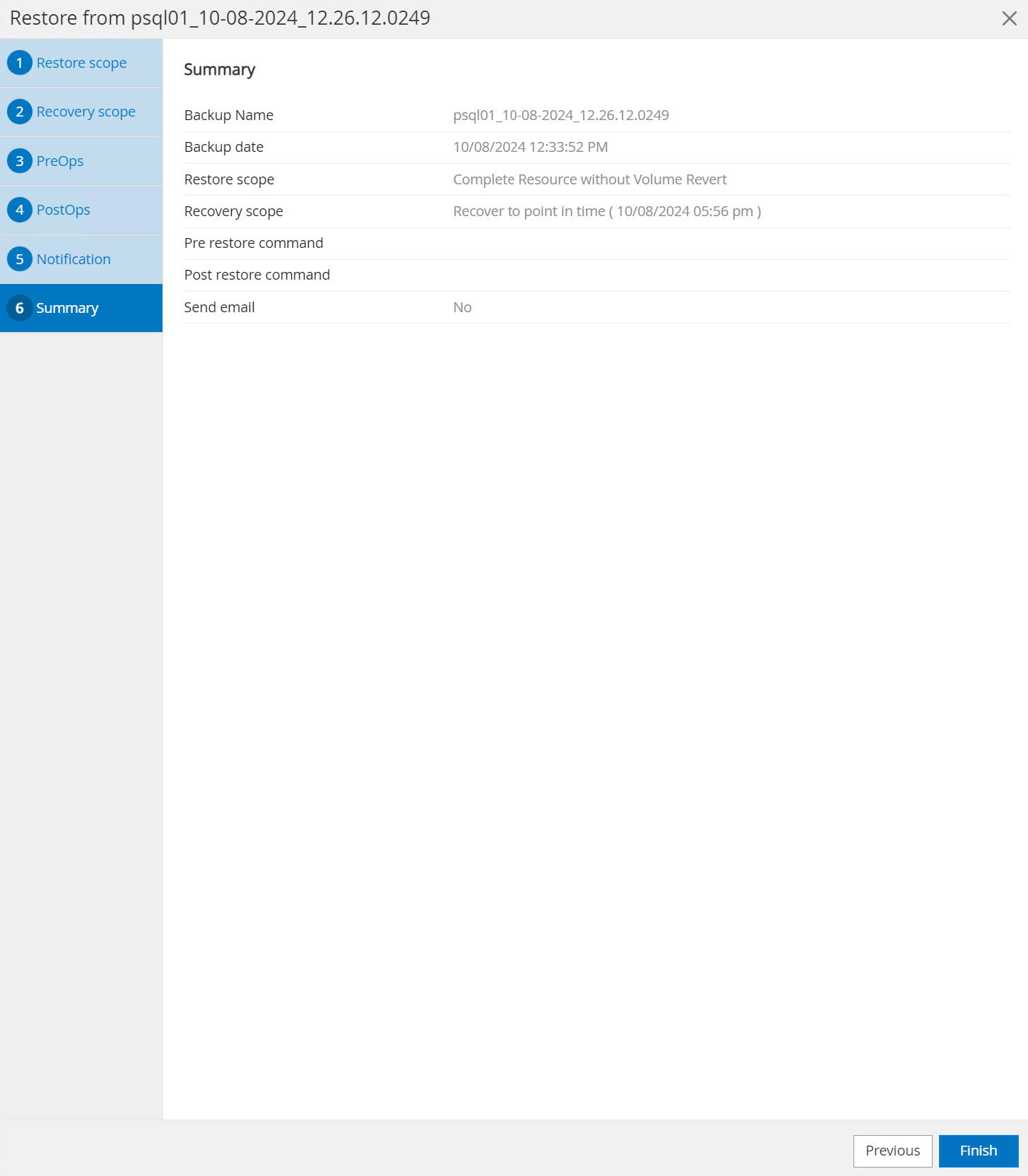
-
Clique no trabalho em execução para abrir
Job Detailsjanela. O status do trabalho também pode ser aberto e visualizado noMonitoraba.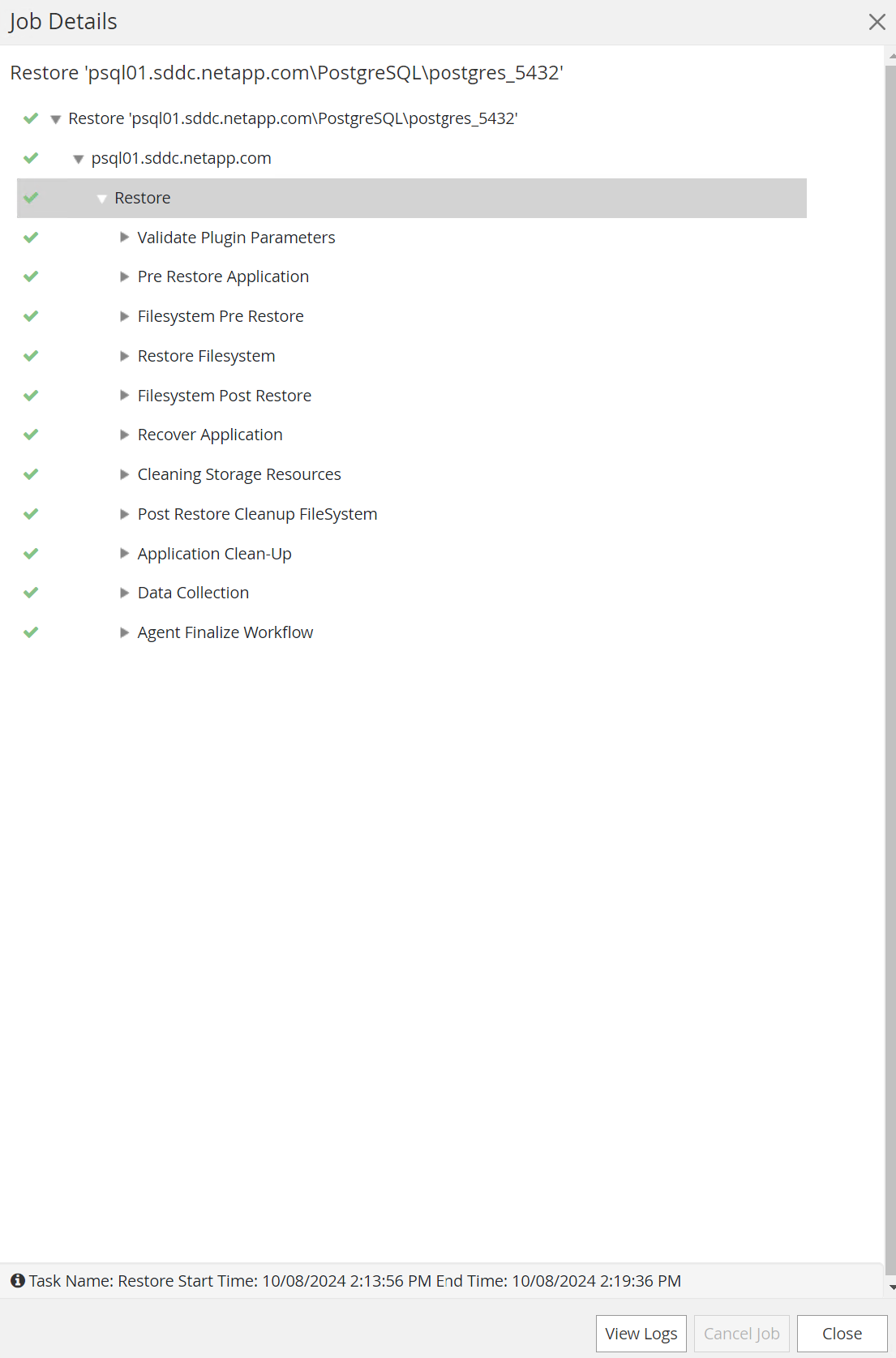
-
Faça login no PostgreSQL como
postgresusuário e validar se a tabela de teste foi recuperada.[postgres@psql01 ~]$ psql psql (14.13) Type "help" for help. postgres=# \dt List of relations Schema | Name | Type | Owner --------+------+-------+---------- public | test | table | postgres (1 row) postgres=# select * from test; id | dt | event ----+----------------------------+-------------------------------------------------------- 1 | 2024-10-08 17:55:41.657728 | test PostgreSQL point in time recovery with SnapCenter (1 row) postgres=# select now(); now ------------------------------- 2024-10-08 18:22:33.767208+00 (1 row)
Clone de banco de dados
Details
A clonagem do cluster de banco de dados PostgreSQL via SnapCenter cria um novo volume clonado fino a partir de um backup instantâneo de um volume de dados do banco de dados de origem. Mais importante, é rápido (alguns minutos) e eficiente em comparação com outros métodos para fazer uma cópia clonada do banco de dados de produção para dar suporte ao desenvolvimento ou testes. Dessa forma, ele reduz drasticamente os custos de armazenamento e melhora o gerenciamento do ciclo de vida do seu aplicativo de banco de dados. A seção a seguir demonstra o fluxo de trabalho do clone do banco de dados PostgreSQL com a interface do usuário do SnapCenter .
-
Para validar o processo de clonagem. Novamente, insira uma linha na tabela de teste. Em seguida, execute um backup para capturar os dados de teste.
postgres=# insert into test values (2, now(), 'test PostgreSQL clone to a different DB server host'); INSERT 0 1 postgres=# select * from test; id | dt | event ----+----------------------------+----------------------------------------------------- 2 | 2024-10-11 20:15:04.252868 | test PostgreSQL clone to a different DB server host (1 row)
-
De
Resourcesguia, abra a página de backup do cluster de banco de dados. Escolha o instantâneo do backup do banco de dados que contém os dados de teste. Em seguida, clique emclonebotão para iniciar o fluxo de trabalho de clonagem do banco de dados.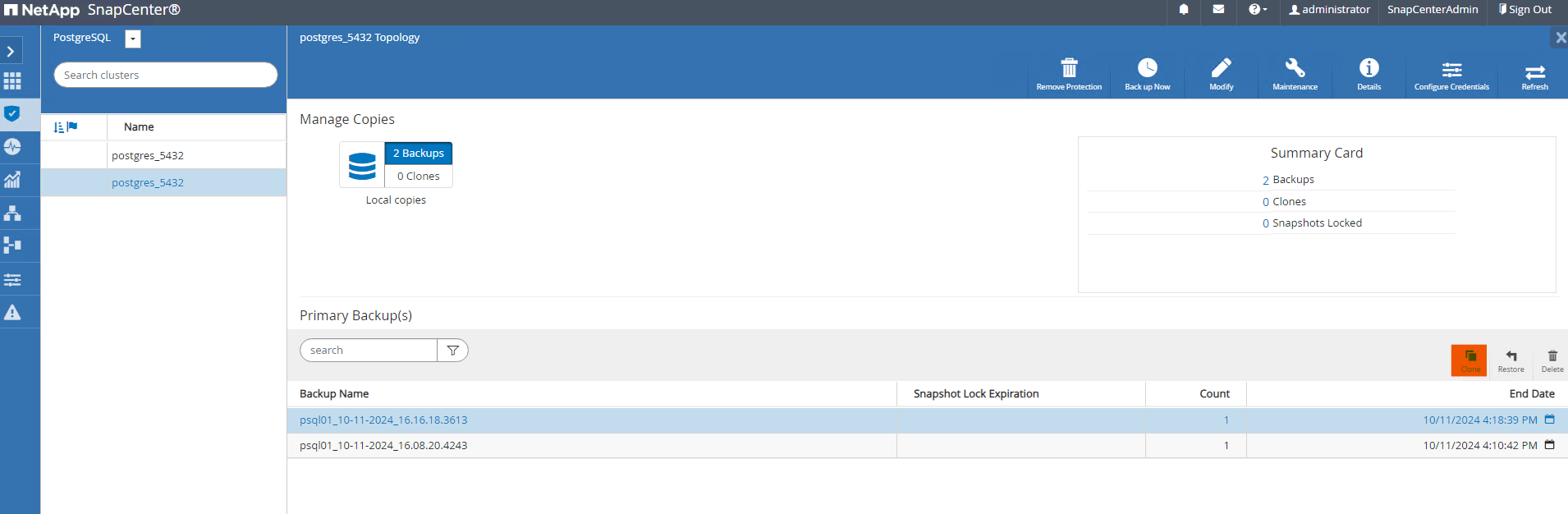
-
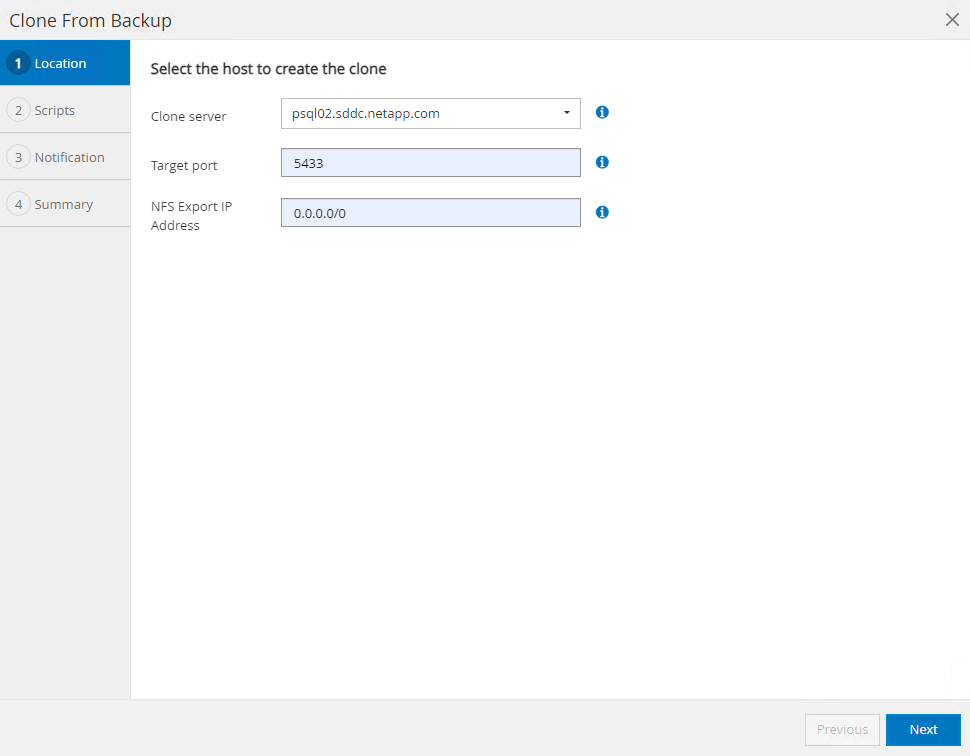
Selecione um host de servidor de banco de dados diferente do servidor de banco de dados de origem. Escolha uma porta TCP 543x não utilizada no host de destino.
-
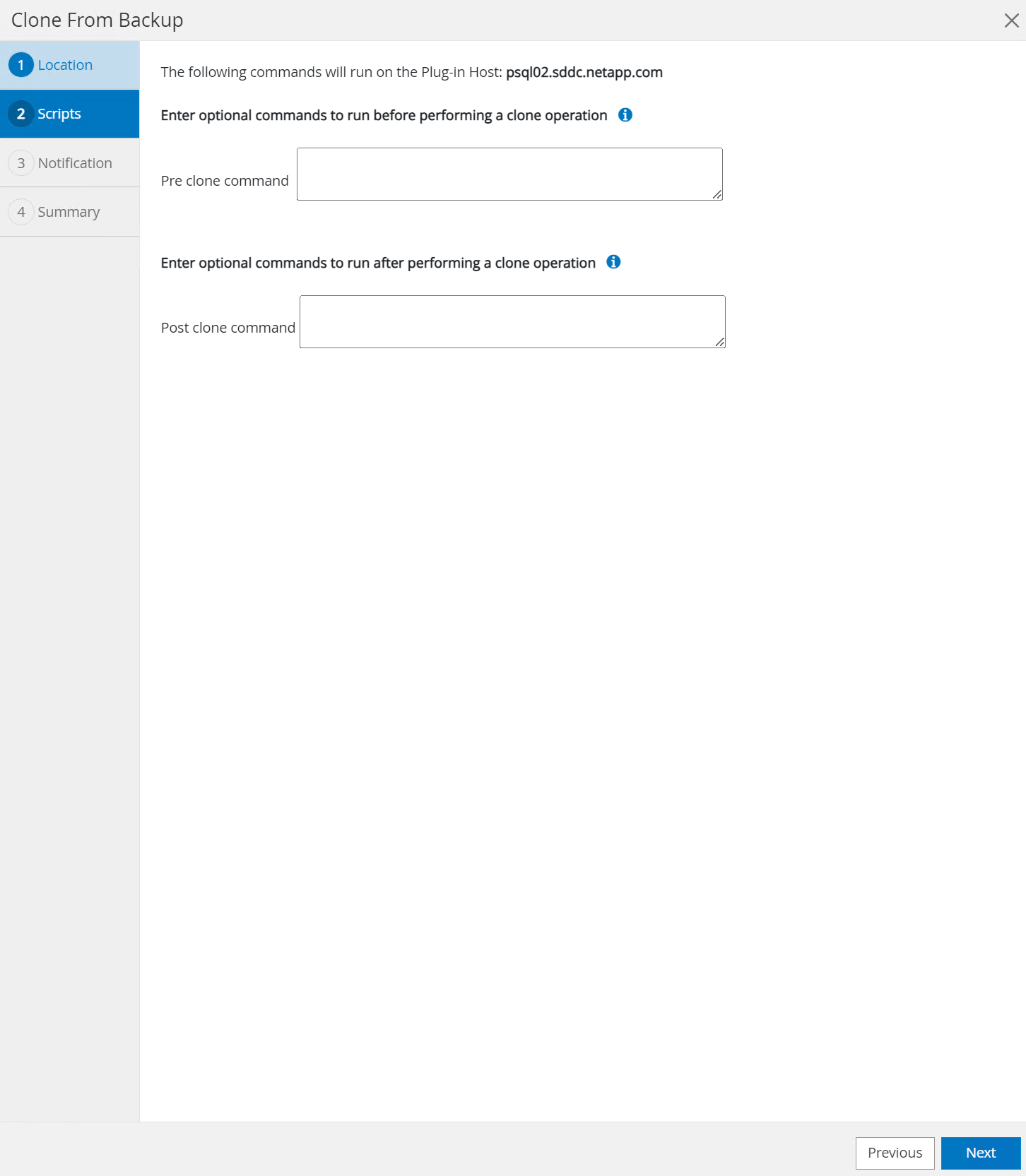
Insira quaisquer scripts para executar antes ou depois da operação de clonagem.
-
Notificação por e-mail, se desejado.
-
Resumo da revisão e
Finishpara iniciar o processo de clonagem.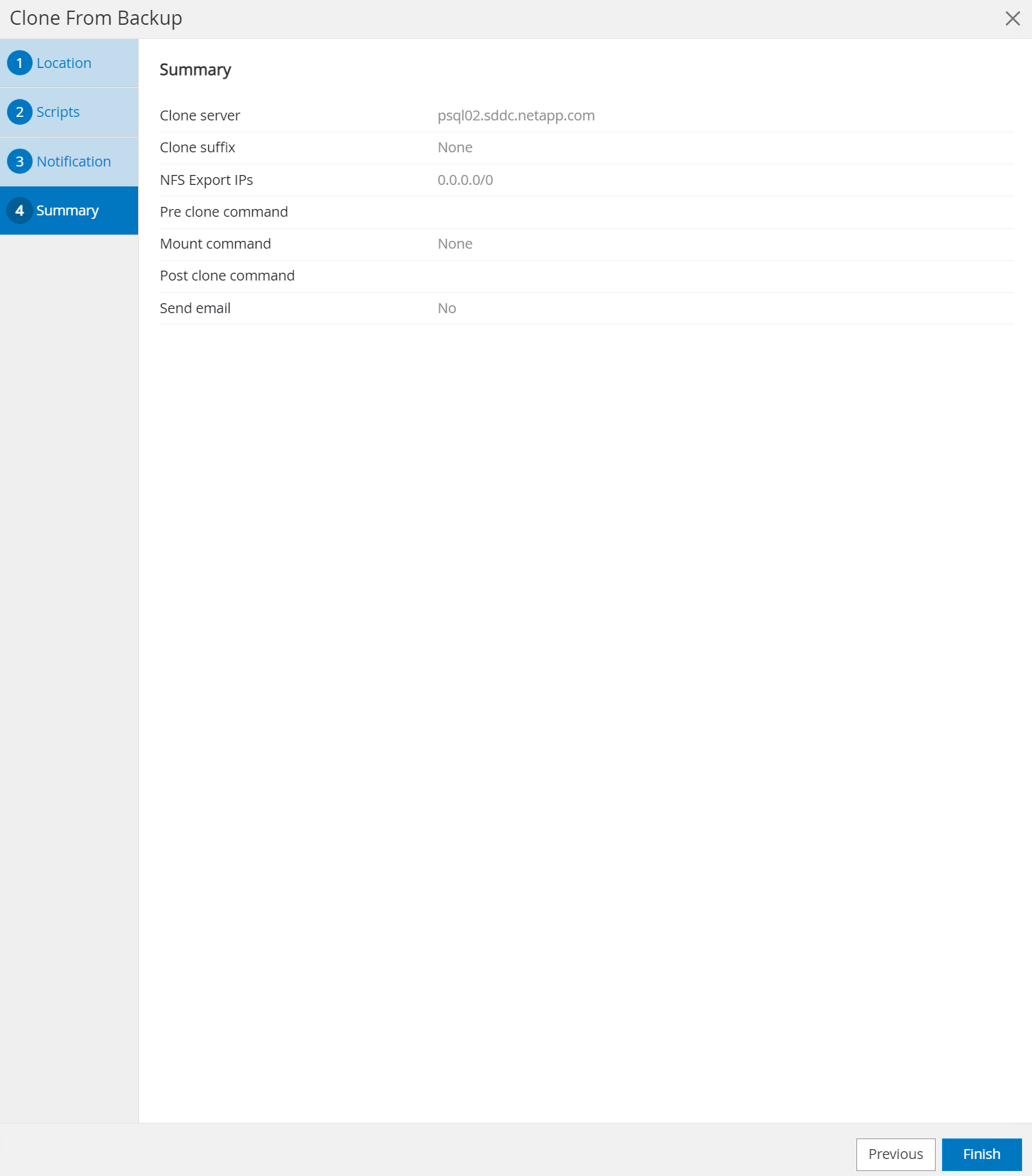
-
Clique no trabalho em execução para abrir
Job Detailsjanela. O status do trabalho também pode ser aberto e visualizado noMonitoraba.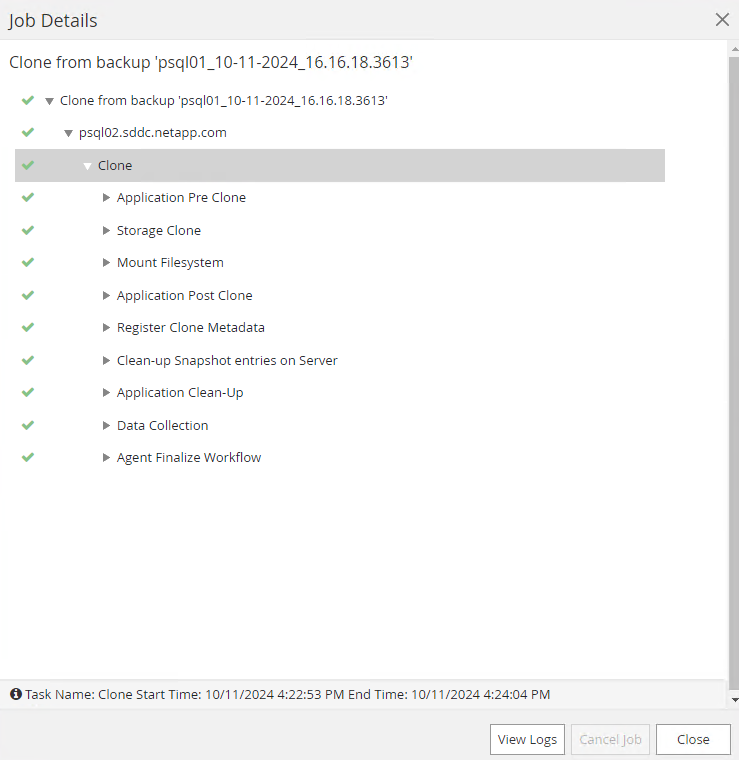
-
O banco de dados clonado é registrado no SnapCenter imediatamente.
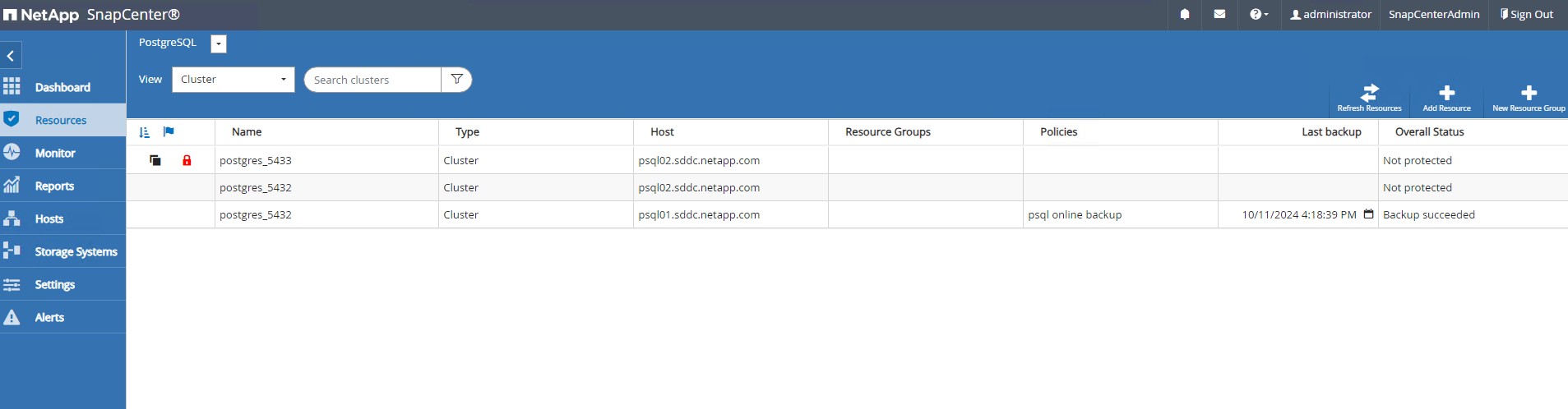
-
Valide o cluster de banco de dados clonado no host do servidor de banco de dados de destino.
[postgres@psql01 ~]$ psql -d postgres -h 10.61.186.7 -U postgres -p 5433 Password for user postgres: psql (14.13) Type "help" for help. postgres=# select * from test; id | dt | event ----+----------------------------+----------------------------------------------------- 2 | 2024-10-11 20:15:04.252868 | test PostgreSQL clone to a different DB server host (1 row) postgres=# select pg_read_file('/etc/hostname') as hostname; hostname ---------- psql02 + (1 row)
Onde encontrar informações adicionais
Para saber mais sobre as informações descritas neste documento, revise os seguintes documentos e/ou sites:
-
Documentação do software SnapCenter
-
TR-4956: Implantação automatizada de alta disponibilidade do PostgreSQL e recuperação de desastres no AWS FSx/EC2