

Rastreabilidade do conjunto de dados ao modelo com NetApp e MLflow
 Sugerir alterações
Sugerir alterações
O "Toolkit DataOps do NetApp para Kubernetes" pode ser usado em conjunto com os recursos de rastreamento de experimentos do MLflow para implementar a rastreabilidade de código para conjunto de dados, conjunto de dados para modelo ou espaço de trabalho para modelo.
As seguintes bibliotecas foram usadas no bloco de notas de exemplo:
Pré-requisitos
Para implementar a rastreabilidade de código-conjunto de dados-modelo ou workspace-to-modelo, basta criar um snapshot do seu conjunto de dados ou volume de workspace usando o DataOps Toolkit como parte da sua execução de treinamento, como mostra o exemplo a seguir. Esse código salvará o nome do volume de dados e o nome do instantâneo como tags associadas à execução de treinamento específica que você está registrando no servidor de rastreamento de experimentos MLflow.
...
from netapp_dataops.k8s import cloneJupyterLab, createJupyterLab, deleteJupyterLab, \
listJupyterLabs, createJupyterLabSnapshot, listJupyterLabSnapshots, restoreJupyterLabSnapshot, \
cloneVolume, createVolume, deleteVolume, listVolumes, createVolumeSnapshot, \
deleteVolumeSnapshot, listVolumeSnapshots, restoreVolumeSnapshot
mlflow.set_tracking_uri("<your_tracking_server_uri>>:<port>>")
os.environ['MLFLOW_HTTP_REQUEST_TIMEOUT'] = '500' # Increase to 500 seconds
mlflow.set_experiment(experiment_id)
with mlflow.start_run() as run:
latest_run_id = run.info.run_id
start_time = datetime.now()
# Preprocess the data
preprocess(input_pdf_file_path, to_be_cleaned_input_file_path)
# Print out sensitive data (passwords, SECRET_TOKEN, API_KEY found)
check_pretrain(to_be_cleaned_input_file_path)
# Tokenize the input file
pretrain_tokenization(to_be_cleaned_input_file_path, model_name, tokenized_output_file_path)
# Load the tokenizer and model
tokenizer = GPT2Tokenizer.from_pretrained(model_name)
model = GPT2LMHeadModel.from_pretrained(model_name)
# Set the pad token
tokenizer.pad_token = tokenizer.eos_token
tokenizer.add_special_tokens({'pad_token': '[PAD]'})
# Encode, generate, and decode the text
with open(tokenized_output_file_path, 'r', encoding='utf-8') as file:
content = file.read()
encode_generate_decode(content, decoded_output_file_path, tokenizer=tokenizer, model=model)
# Save the model
model.save_pretrained(model_save_path)
tokenizer.save_pretrained(model_save_path)
# Finetuning here
with open(decoded_output_file_path, 'r', encoding='utf-8') as file:
content = file.read()
model.finetune(content, tokenizer=tokenizer, model=model)
# Evaluate the model using NLTK
output_set = Dataset.from_dict({"text": [content]})
test_set = Dataset.from_dict({"text": [content]})
scores = nltk_evaluation_gpt(output_set, test_set, model=model, tokenizer=tokenizer)
print(f"Scores: {scores}")
# End time and elapsed time
end_time = datetime.now()
elapsed_time = end_time - start_time
elapsed_minutes = elapsed_time.total_seconds() // 60
elapsed_seconds = elapsed_time.total_seconds() % 60
# Create DOTK snapshots for code, dataset, and model
snapshot = createVolumeSnapshot(pvcName="model-pvc", namespace="default", printOutput=True)
#Log snapshot IDs to MLflow
mlflow.log_param("code_snapshot_id", snapshot)
mlflow.log_param("dataset_snapshot_id", snapshot)
mlflow.log_param("model_snapshot_id", snapshot)
# Log parameters and metrics to MLflow
mlflow.log_param("wf_start_time", start_time)
mlflow.log_param("wf_end_time", end_time)
mlflow.log_param("wf_elapsed_time_minutes", elapsed_minutes)
mlflow.log_param("wf_elapsed_time_seconds", elapsed_seconds)
mlflow.log_artifact(decoded_output_file_path.rsplit('/', 1)[0]) # Remove the filename to log the directory
mlflow.log_artifact(model_save_path) # log the model save path
print(f"Experiment ID: {experiment_id}")
print(f"Run ID: {latest_run_id}")
print(f"Elapsed time: {elapsed_minutes} minutes and {elapsed_seconds} seconds")O snippet de código acima Registra as IDs de snapshot no servidor de rastreamento de experimentos MLflow, que pode ser usado para rastrear de volta para o conjunto de dados e modelo específicos que foram usados para treinar o modelo. Isso permitirá que você rastreie o conjunto de dados e o modelo específicos que foram usados para treinar o modelo, bem como o código específico que foi usado para pré-processar os dados, tokenizar o arquivo de entrada, carregar o tokenizer e modelo, codificar, gerar e decodificar o texto, salvar o modelo, finetune o modelo, avaliar o modelo usando "NLTK"pontuações MLperplexidade e Registrar os parâmetros e métricas de hiperfluxo. Por exemplo, a figura a seguir mostra o erro médio-quadrado (MSE) de um modelo scikit-learn para diferentes execuções de experimentos:

É simples para análise de dados, proprietários de linha de negócios e executivos entender e inferir qual modelo tem o melhor desempenho sob suas restrições específicas, configurações, período de tempo e outras circunstâncias. Para mais detalhes sobre como pré-processar, tokenizar, carregar, codificar, gerar, decodificar, salvar, finetune e avaliar o modelo, consulte o dotk-mlflow exemplo Python empacotado no netapp_dataops.k8s repositório.
Para obter mais detalhes sobre como criar snapshots do conjunto de dados ou do espaço de trabalho do JupyterLab, consulte o "Página do Toolkit DataOps do NetApp".
Em relação aos modelos que foram treinados, os seguintes modelos foram utilizados no caderno dotk-mlflow:
Modelos
-
"GPT2LMHeadModel": O transformador modelo GPT2 com uma cabeça de modelagem de linguagem em cima (camada linear com pesos amarrados aos embutimentos de entrada). É um modelo de transformador que foi pré-treinado em um grande corpus de dados de texto e finetuned em um conjunto de dados específico. Usamos o modelo GPT2 padrão "máscara de atenção"para agrupar sequências de entrada com tokenizador correspondente para o seu modelo de escolha.
-
"PHI-2": Phi-2 é um transformador com 2,7 bilhões de parâmetros. Ele foi treinado usando as mesmas fontes de dados do Phi-1,5, aumentado com uma nova fonte de dados que consiste em vários textos sintéticos de PNL e sites filtrados (para segurança e valor educacional).
-
"XLNet (modelo de tamanho baseado)": Modelo XLNet pré-treinado na língua inglesa. Foi introduzido no artigo "XLNet: Pré-treinamento autorregressivo generalizado para a compreensão da linguagem" por Yang et al. E lançado pela primeira vez neste"repositório".
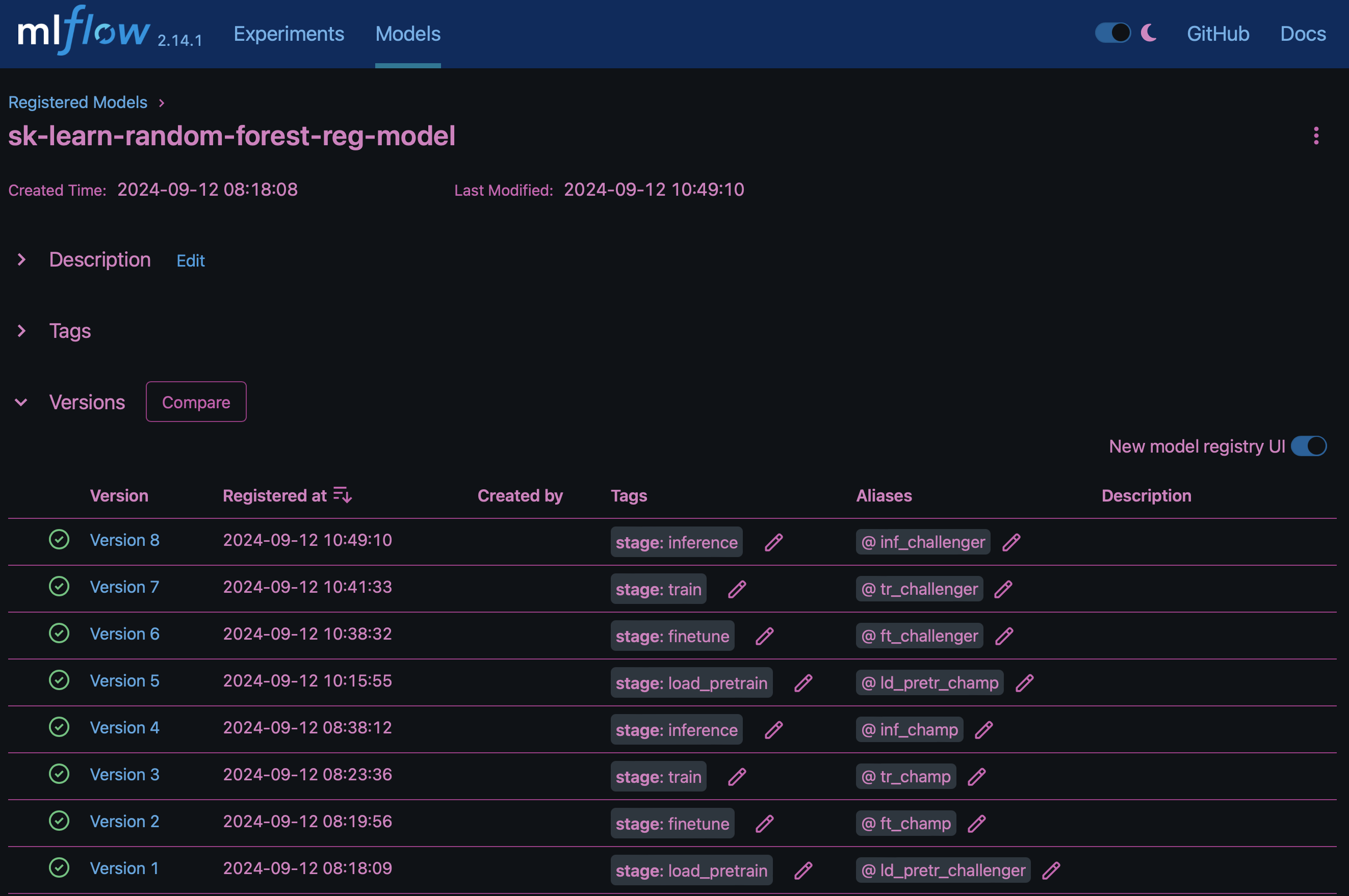
O resultado "Registro de modelo em MLflow"conterá os seguintes modelos de floresta aleatória, versões e tags:
Para implantar o modelo em um servidor de inferência por meio do Kubernetes, basta executar o seguinte Jupyter notebook. Note que neste exemplo em vez de usar o dotk-mlflow pacote, estamos modificando a arquitetura do modelo de regressão de floresta aleatória para minimizar o erro médio-quadrado (MSE) no modelo inicial e, portanto, criando múltiplas versões desse modelo no nosso Registro de modelos.
from mlflow.models import Model
mlflow.set_tracking_uri("http://<tracking_server_URI_with_port>")
experiment_id='<your_specified_exp_id>'
# Alternatively, you can load the Model object from a local MLmodel file
# model1 = Model.load("~/path/to/my/MLmodel")
from sklearn.datasets import make_regression
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
import mlflow
import mlflow.sklearn
from mlflow.models import infer_signature
# Create a new experiment and get its ID
experiment_id = mlflow.create_experiment(experiment_id)
# Or fetch the ID of the existing experiment
# experiment_id = mlflow.get_experiment_by_name("<your_specified_exp_id>").experiment_id
with mlflow.start_run(experiment_id=experiment_id) as run:
X, y = make_regression(n_features=4, n_informative=2, random_state=0, shuffle=False)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
params = {"max_depth": 2, "random_state": 42}
model = RandomForestRegressor(**params)
model.fit(X_train, y_train)
# Infer the model signature
y_pred = model.predict(X_test)
signature = infer_signature(X_test, y_pred)
# Log parameters and metrics using the MLflow APIs
mlflow.log_params(params)
mlflow.log_metrics({"mse": mean_squared_error(y_test, y_pred)})
# Log the sklearn model and register as version 1
mlflow.sklearn.log_model(
sk_model=model,
artifact_path="sklearn-model",
signature=signature,
registered_model_name="sk-learn-random-forest-reg-model",
)O resultado da execução da célula do Jupyter notebook deve ser semelhante ao seguinte, com o modelo sendo registrado como versão 3 no Registro de modelos:
Registered model 'sk-learn-random-forest-reg-model' already exists. Creating a new version of this model... 2024/09/12 15:23:36 INFO mlflow.store.model_registry.abstract_store: Waiting up to 300 seconds for model version to finish creation. Model name: sk-learn-random-forest-reg-model, version 3 Created version '3' of model 'sk-learn-random-forest-reg-model'.
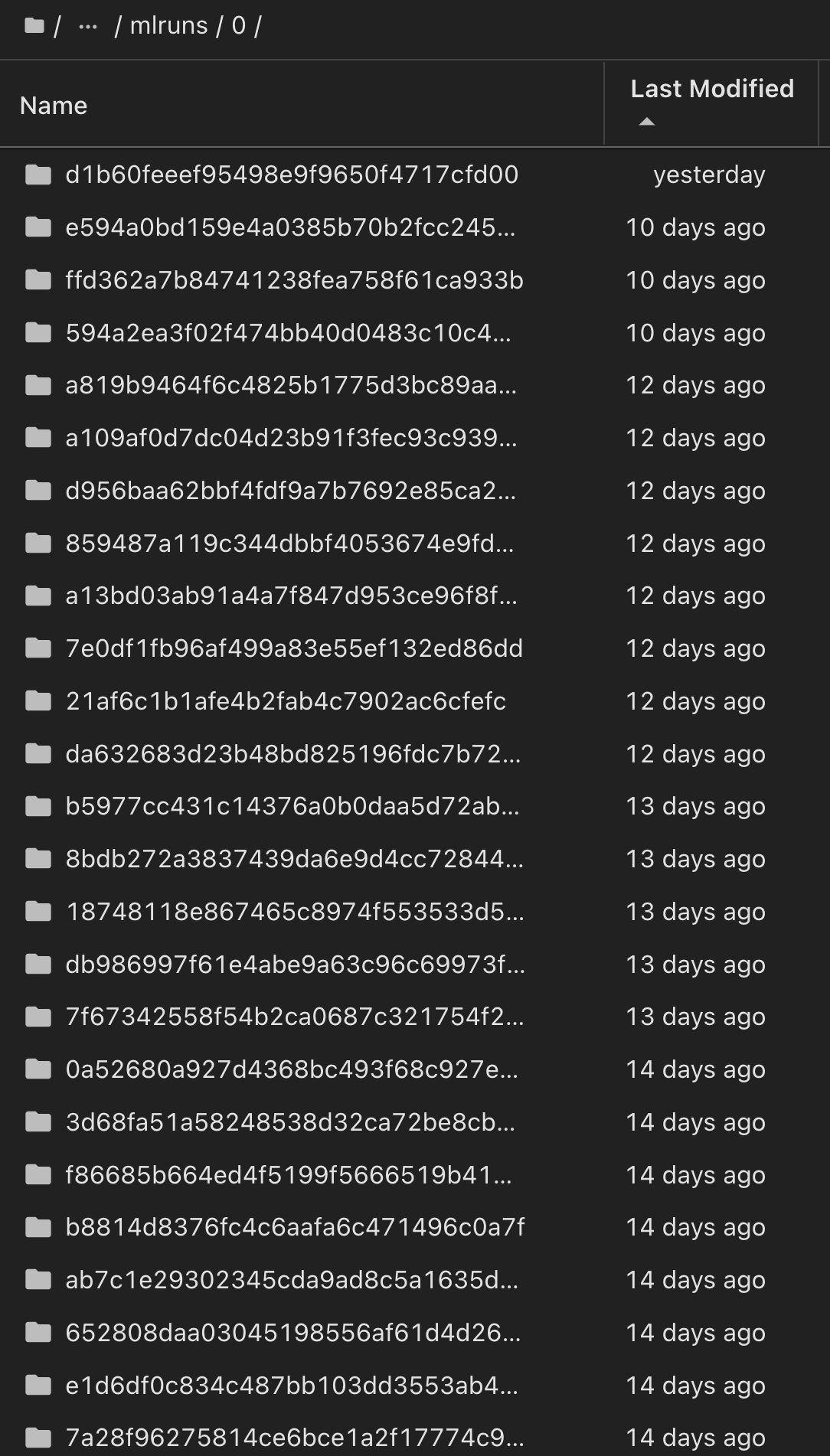
No Registro de modelos, depois de salvar seus modelos, versões e tags desejados, é possível rastrear de volta para o conjunto de dados, modelo e código específicos que foram usados para treinar o modelo, bem como o código específico que foi usado para processar os dados, carregar o tokenizador e modelo, codificar, gerar e decodificar o texto, salvar o modelo, finetune o modelo, avaliar o modelo usando as guias de log do Jupyterity ou outros parâmetros de pastas ativas do Jupylog ativo ou outros parâmetros do Jupylog snapshot_id's and your chosen metrics to MLflow by choosing the corerct experiment under `mlrun ativo do Hub:
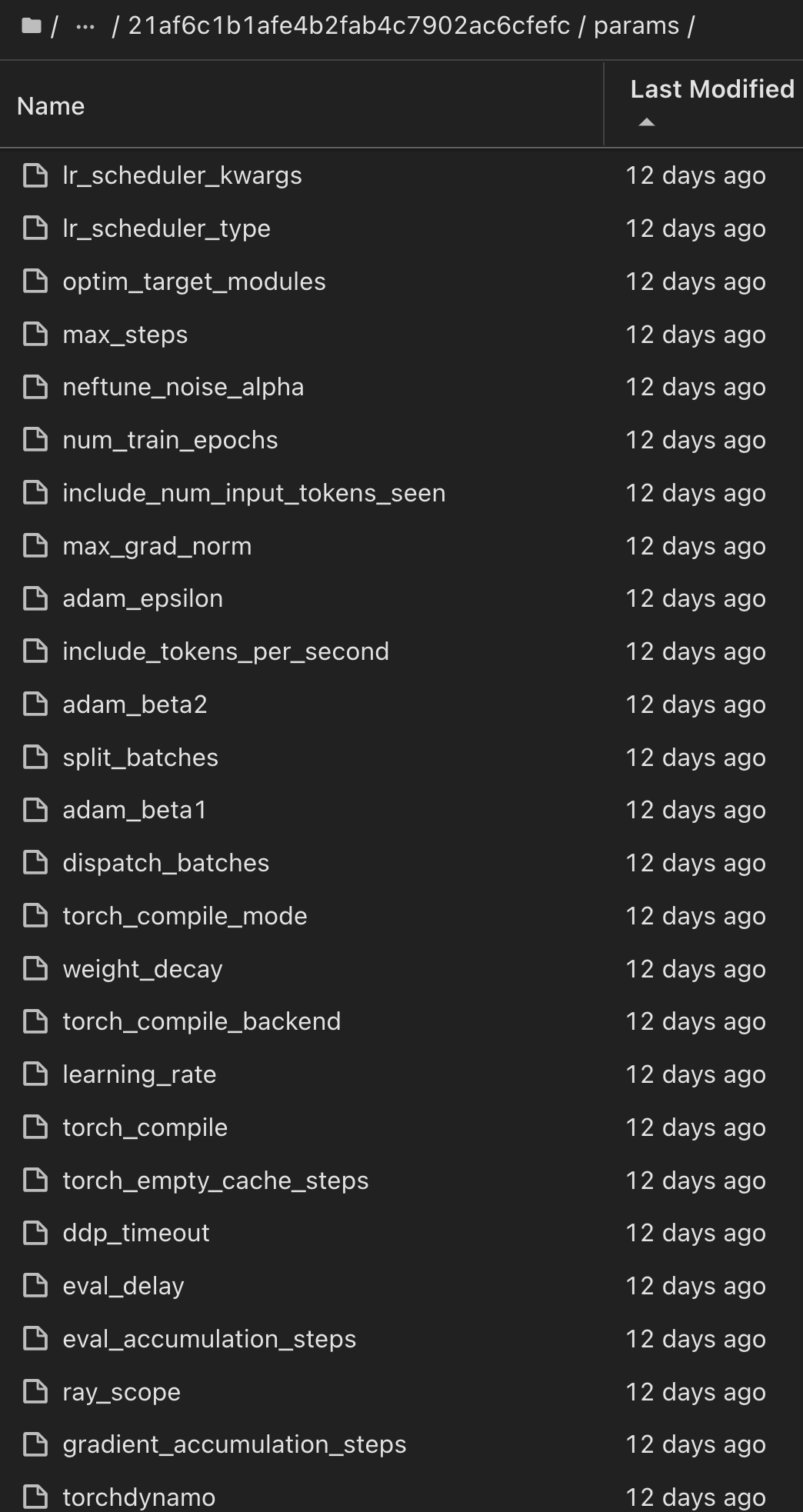
Da mesma forma, para nossos phi-2_finetuned_model cujos pesos quantificados foram calculados via GPU ou vGPU usando a torch biblioteca, podemos inspecionar os seguintes artefatos intermediários, o que permitiria a otimização do desempenho, escalabilidade (throughput/SLA gaurantee) e redução de custos de todo o fluxo de trabalho:
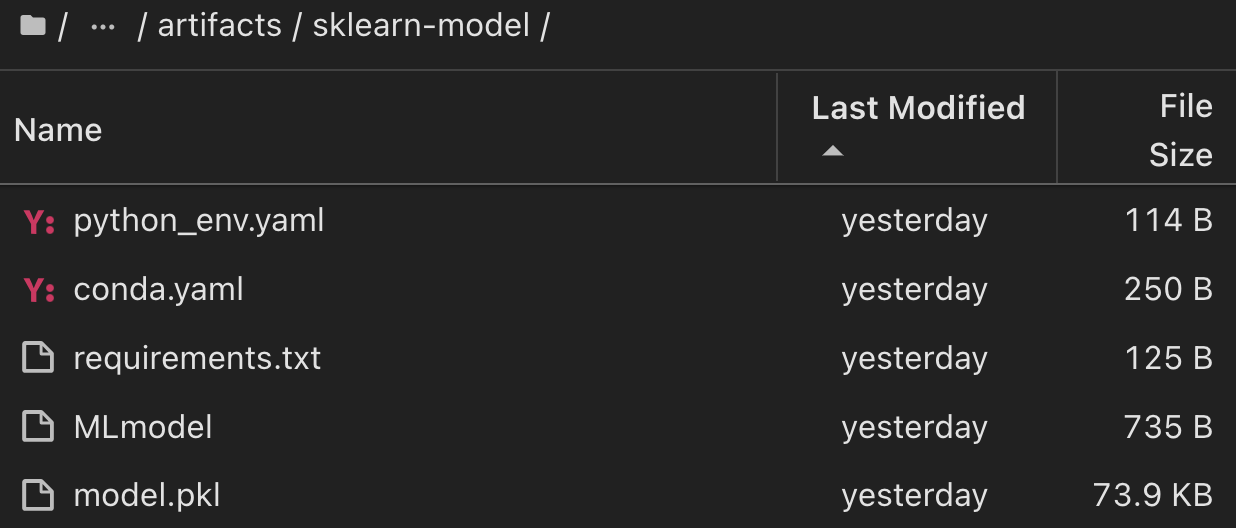
Para uma única experiência executada usando Scikit-learn e MLflow, a figura a seguir exibe os artefatos gerados, conda ambiente, MLmodel arquivo e MLmodel diretório:
Os clientes podem especificar tags, por exemplo, "padrão", "estágio", "processo", "gargalo" para organizar diferentes caraterísticas de suas execuções de fluxo de trabalho de IA, observar seus resultados mais recentes ou definir contributors para acompanhar o progresso do desenvolvedor da equipe de ciência de dados. Se a tag padrão " " ", a guia Saved mlflow.log-model.history, , mlflow.runName, mlflow.source.type, mlflow.source.name e mlflow.user em JupyterHub atualmente ativo file Navigator :
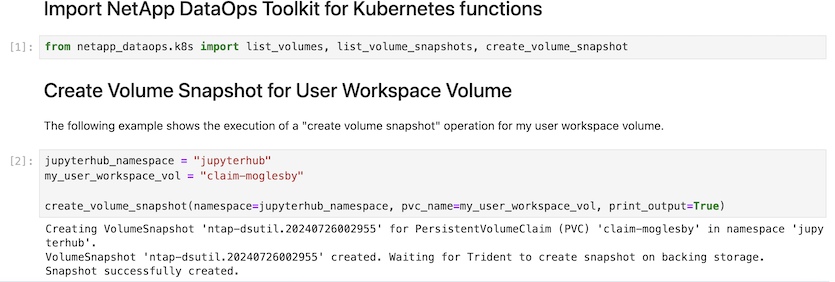
Por fim, os usuários têm seu próprio Jupyter Workspace especificado, que é versionado e armazenado em uma reivindicação de volume persistente (PVC) no cluster do Kubernetes. A figura a seguir exibe o Jupyter Workspace, que contém o netapp_dataops.k8s pacote Python, e os resultados de uma criação bem-sucedida VolumeSnapshot :
Nosso Snapshot e outras tecnologias comprovadas pelo setor foram usadas para garantir proteção de dados, movimentação e compactação eficiente em nível empresarial. Para outros casos de uso de IA, consulte "NetApp AIPod"a documentação.