

Arquivos de banco de dados e grupos de arquivos
 Sugerir alterações
Sugerir alterações
O posicionamento adequado do arquivo de banco de dados do SQL Server no ONTAP é fundamental durante a fase inicial de implantação. Isso garante um desempenho ideal, gerenciamento de espaço, backup e tempos de restauração que podem ser configurados para atender aos requisitos da sua empresa.
Em teoria, o SQL Server (64 bits) suporta 32.767 bancos de dados por instância e 524.272TB GB de tamanho de banco de dados, embora a instalação típica geralmente tenha vários bancos de dados. No entanto, o número de bancos de dados que o SQL Server pode manipular depende da carga e do hardware. Não é incomum ver instâncias do SQL Server hospedando dezenas, centenas ou até milhares de bancos de dados pequenos.
Ficheiros da base de dados e grupo de ficheiros
Cada banco de dados consiste em um ou mais arquivos de dados e um ou mais arquivos de log de transações. O log de transações armazena as informações sobre transações de banco de dados e todas as modificações de dados feitas por cada sessão. Sempre que os dados são modificados, o SQL Server armazena informações suficientes no log de transações para desfazer (reverter) ou refazer (reproduzir) a ação. Um log de transações do SQL Server é parte integrante da reputação do SQL Server em relação à integridade e robustez dos dados. O log de transações é vital para os recursos de atomicidade, consistência, isolamento e durabilidade (ACID) do SQL Server. O SQL Server grava no log de transações assim que qualquer alteração na página de dados ocorrer. Cada declaração DML (Data Manipulation Language) (por exemplo, selecionar, inserir, atualizar ou excluir) é uma transação completa, e o log de transações garante que toda a operação baseada em conjunto ocorra, certificando-se da atomicidade da transação.
Cada banco de dados tem um arquivo de dados primário, que, por padrão, tem a extensão .mdf. Além disso, cada banco de dados pode ter arquivos de banco de dados secundários. Esses arquivos, por padrão, têm extensões .ndf.
Todos os arquivos de banco de dados são agrupados em grupos de arquivos. Um grupo de arquivos é a unidade lógica, o que simplifica a administração do banco de dados. Eles permitem a separação entre o posicionamento lógico de objetos e arquivos de banco de dados físicos. Quando você cria as tabelas de objetos de banco de dados, você especifica em que grupo de arquivos eles devem ser colocados sem se preocupar com a configuração do arquivo de dados subjacente.
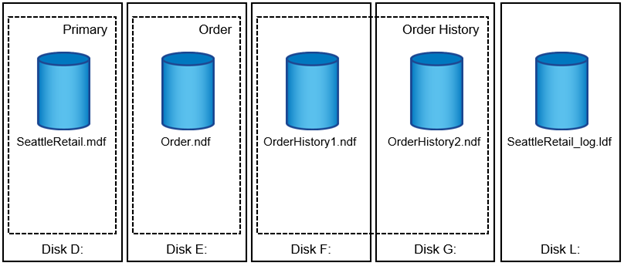
A capacidade de colocar vários arquivos de dados dentro do grupo de arquivos permite que você espalhe a carga entre diferentes dispositivos de armazenamento, o que ajuda a melhorar o desempenho de e/S do sistema. O log de transação em contraste não se beneficia dos vários arquivos porque o SQL Server grava no log de transação de forma sequencial.
A separação entre o posicionamento lógico de objetos nos grupos de arquivos e arquivos físicos de banco de dados permite ajustar o layout do arquivo do banco de dados, obtendo o máximo do subsistema de armazenamento. O número de arquivos de dados que suportam uma determinada carga de trabalho pode ser variado conforme necessário para dar suporte aos requisitos de e/S e à capacidade esperada, sem afetar a aplicação. Essas variações no layout do banco de dados são transparentes para os desenvolvedores de aplicativos, que estão colocando os objetos do banco de dados nos grupos de arquivos em vez de arquivos do banco de dados.

|
NetApp recomenda evitar o uso do grupo de arquivos primário para qualquer coisa além de objetos do sistema. Criar um grupo de arquivos separado ou um conjunto de grupos de arquivos para os objetos do usuário simplifica a administração do banco de dados e a recuperação de desastres, especialmente no caso de bancos de dados grandes. |
Inicialização do arquivo de instância do banco de dados
Você pode especificar o tamanho inicial do arquivo e os parâmetros de crescimento automático no momento em que você cria o banco de dados ou adiciona novos arquivos a um banco de dados existente. O SQL Server usa um algoritmo de preenchimento proporcional ao escolher em qual arquivo de dados ele deve gravar dados. Ele grava uma quantidade de dados proporcionalmente ao espaço livre disponível nos arquivos. Quanto mais espaço livre no arquivo, mais escreve ele lida.
|
|
A NetApp recomenda que todos os arquivos no único grupo de arquivos tenham o mesmo tamanho inicial e parâmetros de crescimento automático, com o tamanho de crescimento definido em megabytes em vez de porcentagens. Isso ajuda o algoritmo de preenchimento proporcional equilibrar uniformemente as atividades de gravação em todos os arquivos de dados. |
Toda vez que o SQL Server cresce arquivos, ele preenche o espaço recém-alocado com zeros. Esse processo bloqueia todas as sessões que precisam gravar no arquivo correspondente ou, em caso de crescimento de log de transações, gerar Registros de log de transações.
O SQL Server sempre apaga o log de transações e esse comportamento não pode ser alterado. No entanto, você pode controlar se os arquivos de dados estão zerando para fora habilitando ou desativando a inicialização instantânea de arquivos. Ativar a inicialização instantânea de arquivos ajuda a acelerar o crescimento de arquivos de dados e reduz o tempo necessário para criar ou restaurar o banco de dados.
Um pequeno risco de segurança está associado à inicialização instantânea de arquivos. Quando esta opção está ativada, partes não alocadas do arquivo de dados podem conter informações de arquivos do sistema operacional excluídos anteriormente. Os administradores de banco de dados podem examinar esses dados.
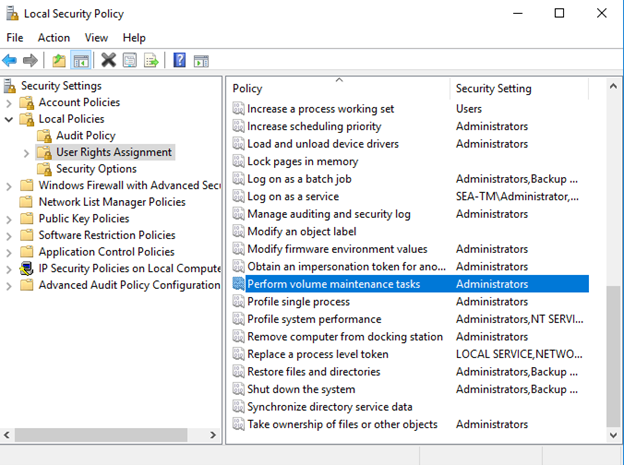
Você pode habilitar a inicialização instantânea de arquivos adicionando a permissão SA_MANAGE_VOLUME_NAME, também conhecida como "executar tarefa de manutenção de volume", à conta de inicialização do SQL Server. Você pode fazer isso sob o aplicativo de gerenciamento de políticas de segurança local (secpol.msc), como mostrado na figura a seguir. Abra as propriedades da permissão "Executar tarefa de manutenção de volume" e adicione a conta de inicialização do SQL Server à lista de usuários lá.
Para verificar se a permissão está ativada, você pode usar o código do exemplo a seguir. Esse código define dois sinalizadores de rastreamento que forçam o SQL Server a gravar informações adicionais no log de erros, criar um pequeno banco de dados e ler o conteúdo do log.
DBCC TRACEON(3004,3605,-1) GO CREATE DATABASE DelMe GO EXECUTE sp_readerrorlog GO DROP DATABASE DelMe GO DBCC TRACEOFF(3004,3605,-1) GO
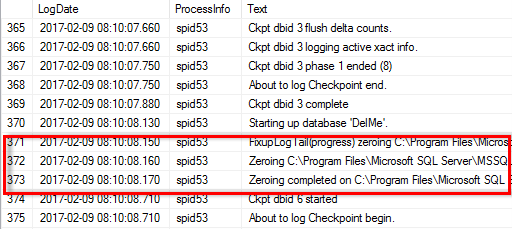
Quando a inicialização instantânea do arquivo não está ativada, o log de erro do SQL Server mostra que o SQL Server está zerando o arquivo de dados do mdf, além de zerar o arquivo de log ldf, como mostrado no exemplo a seguir. Quando a inicialização instantânea do arquivo está ativada, ele exibe apenas a restauração do arquivo de log.
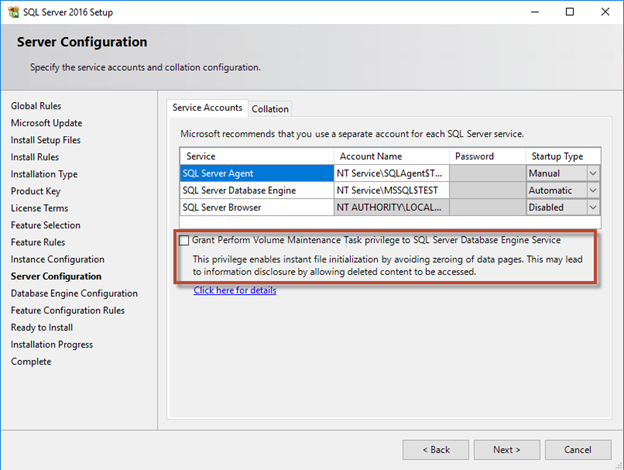
A tarefa realizar manutenção de volume é simplificada no SQL Server 2016 e é fornecida posteriormente como uma opção durante o processo de instalação. Esta figura exibe a opção de conceder ao serviço do mecanismo de banco de dados SQL Server o privilégio de executar a tarefa de manutenção de volume.
Outra opção importante de banco de dados que controla os tamanhos de arquivo de banco de dados é o auto-retrátil. Quando essa opção está ativada, o SQL Server diminui regularmente os arquivos do banco de dados, reduz seu tamanho e libera espaço para o sistema operacional. Esta operação é intensiva em recursos e raramente é útil porque os arquivos de banco de dados crescem novamente após algum tempo quando novos dados entram no sistema. O Autoshink não deve ser ativado no banco de dados.
Diretório de log
O diretório de log é especificado no SQL Server para armazenar dados de backup de log de transação no nível do host. Se você estiver usando o SnapCenter para fazer backup de arquivos de log, cada host do SQL Server usado pelo SnapCenter deve ter um diretório de log do host configurado para executar backups de log. O SnapCenter tem um repositório de banco de dados, portanto, os metadados relacionados a operações de backup, restauração ou clonagem são armazenados em um repositório de banco de dados central.
Os tamanhos do diretório de log do host são calculados da seguinte forma: Tamanho do diretório de log do host ( (tamanho máximo de DB LDF x taxa de alteração diária de log %) x (retenção de snapshot) ÷ (1 - LUN overhead space %) a fórmula de dimensionamento do diretório de log do host assume um espaço de sobrecarga de LUN de 10%
Coloque o diretório de log em um volume dedicado ou LUN. A quantidade de dados no diretório de log do host depende do tamanho dos backups e do número de dias em que os backups são mantidos. O SnapCenter permite apenas um diretório de log de host por host do SQL Server. Você pode configurar os diretórios de log do host em SnapCenter -→ Host -→ Configurar Plug-in.
|
|
A NetApp recomenda o seguinte para um diretório de log do host:
|