

Visão geral da solução VMware vSphere
 Sugerir alterações
Sugerir alterações
O vCenter Server Appliance (VCSA) é um poderoso sistema de gerenciamento centralizado e um painel de controle único para o vSphere que permite aos administradores operar clusters ESXi de forma eficaz. Ele facilita funções essenciais como provisionamento de máquinas virtuais, operação vMotion, alta disponibilidade (HA), Distributed Resource Scheduler (DRS), VMware vSphere Kubernetes Service (VKS) e muito mais. É um componente essencial em ambientes de nuvem VMware e deve ser projetado levando em consideração a disponibilidade do serviço.
Alta disponibilidade do vSphere
A tecnologia de cluster da VMware agrupa os servidores ESXi em pools de recursos compartilhados para máquinas virtuais e fornece o vSphere High Availability (HA). O vSphere HA oferece alta disponibilidade e fácil de usar para aplicativos executados em máquinas virtuais. Quando o recurso HA está ativado no cluster, cada servidor ESXi mantém a comunicação com outros hosts para que, se qualquer host ESXi ficar sem resposta ou isolado, o cluster HA possa negociar a recuperação das máquinas virtuais que estavam sendo executadas nesse host ESXi entre os hosts sobreviventes no cluster. No caso de uma falha do sistema operacional convidado, o vSphere HA pode reiniciar a máquina virtual afetada no mesmo servidor físico. O vSphere HA possibilita reduzir o tempo de inatividade planejado, evitar tempo de inatividade não planejado e recuperar rapidamente de interrupções.
Cluster vSphere HA recuperando VMs de um servidor com falha.
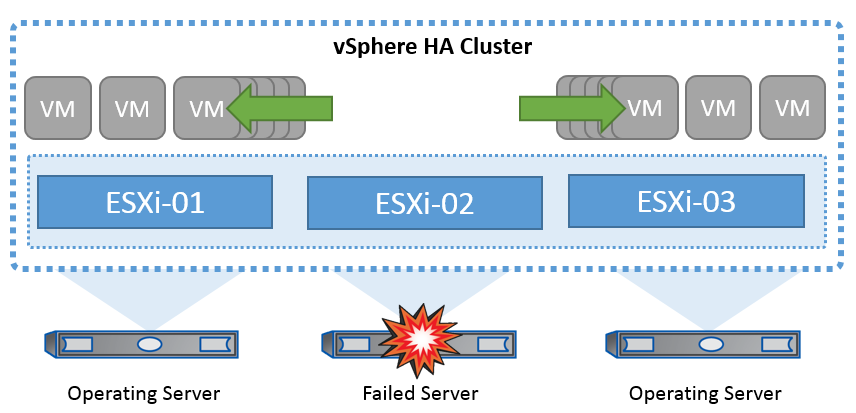
É importante entender que o VMware vSphere não tem conhecimento da sincronização ativa do NetApp MetroCluster ou do SnapMirror e vê todos os hosts ESXi no cluster vSphere como hosts qualificados para operações de cluster de HA, dependendo das configurações de afinidade de host e grupo de VM.
Detecção de falha do host
Assim que o cluster HA é criado, todos os hosts do cluster participam da eleição, e um dos hosts se torna o mestre. Cada servidor escravo envia um sinal de pulsação à rede para o servidor mestre, e o servidor mestre, por sua vez, envia um sinal de pulsação a todos os servidores escravos. O host mestre de um cluster vSphere HA é responsável por detectar a falha dos hosts escravos.
Dependendo do tipo de falha detetada, as máquinas virtuais que estão sendo executadas nos hosts podem precisar ser reexecutadas.
Em um cluster do vSphere HA, três tipos de falha de host são detetados:
-
Falha - Um host pára de funcionar.
-
Isolamento - Um host se torna isolado na rede.
-
Partição - Um host perde a conetividade de rede com o host mestre.
O host principal monitora os hosts escravos no cluster. Esta comunicação é feita através da troca de batimentos cardíacos de rede a cada segundo. Quando o host mestre deixa de receber esses batimentos cardíacos de um host escravo, ele verifica a presença de host antes de declarar que o host falhou. A verificação de vivacidade que o host mestre executa é determinar se o host escravo está trocando heartbeats com um dos datastores. Além disso, o host principal verifica se o host responde aos pings ICMP enviados para seus endereços IP de gerenciamento para detetar se ele é meramente isolado de seu nó mestre ou completamente isolado da rede. Ele faz isso fazendo ping no gateway padrão. Um ou mais endereços de isolamento podem ser especificados manualmente para melhorar a confiabilidade da validação de isolamento.

|
A NetApp recomenda especificar um mínimo de dois endereços de isolamento adicionais e que cada um desses endereços seja local. Isso aumentará a confiabilidade da validação de isolamento. |
Resposta de isolamento do host
A Resposta de Isolamento é uma configuração no vSphere HA que determina a ação acionada nas máquinas virtuais quando um host em um cluster vSphere HA perde suas conexões de rede de gerenciamento, mas continua em execução. Existem três opções para esta configuração: "Desativado", "Desligar e reiniciar VMs" e "Desligar e reiniciar VMs".
"Desligar" é melhor do que "Desligar completamente", que não salva as alterações mais recentes no disco nem confirma as transações. Se as máquinas virtuais não forem desligadas em 300 segundos, elas serão desativadas. Para alterar o tempo de espera, use a opção avançada das.isolationshutdowntimeout.
Antes que o HA inicie a resposta de isolamento, ele primeiro verifica se o agente mestre do vSphere HA possui o datastore que contém os arquivos de configuração da VM. Caso contrário, o host não acionará a resposta de isolamento, porque não há mestre para reiniciar as VMs. O host verificará periodicamente o estado do datastore para determinar se ele é reivindicado por um agente do vSphere HA que detém a função mestre.
|
|
A NetApp recomenda definir a "resposta de isolamento do host" como Desativado. |
Uma condição de split-brain pode ocorrer se um host ficar isolado ou particionado do host master do vSphere HA e o mestre não conseguir se comunicar por meio de datastores de heartbeat ou por ping. O mestre declara o host isolado morto e reinicia as VMs em outros hosts no cluster. Uma condição de split-brain agora existe porque existem duas instâncias da máquina virtual em execução, apenas uma das quais pode ler ou gravar os discos virtuais. As condições de split-brain agora podem ser evitadas configurando a VM Component Protection (VMCP).
Proteção de componentes VM (VMCP)
Um dos aprimoramentos de recursos do vSphere 6, relevantes para o HA, é o VMCP. O VMCP fornece proteção aprimorada contra todas as condições de APD (caminhos para baixo) e PDL (perda permanente de dispositivo) para bloco (FC, iSCSI, FCoE) e armazenamento de arquivos (NFS).
Perda permanente de dispositivo (PDL)
PDL é uma condição que ocorre quando um dispositivo de armazenamento falha permanentemente ou é removido administrativamente e não se espera que retorne. O array de armazenamento NetApp emite um código SCSI Sense para o ESXi, declarando que o dispositivo foi perdido permanentemente. Na seção Condições de Falha e Resposta da VM do vSphere HA, você pode configurar qual deve ser a resposta após a detecção de uma condição PDL.
|
|
A NetApp recomenda definir a "Resposta para armazenamento de dados com PDL" como "Desligar e reiniciar as VMs". Quando essa condição for detectada, uma máquina virtual será reiniciada instantaneamente em um host íntegro dentro do cluster vSphere HA. |
Todos os caminhos para baixo (APD)
APD é uma condição que ocorre quando um dispositivo de armazenamento se torna inacessível ao host e não há caminhos disponíveis para o array. O ESXi considera este um problema temporário com o dispositivo e espera que ele volte a estar disponível em breve.
Quando uma condição APD é detetada, um temporizador é iniciado. Após 140 segundos, a condição APD é oficialmente declarada e o dispositivo é marcado como APD time out. Quando os 140 segundos tiverem passado, o HA começará a contar o número de minutos especificado no atraso para o APD de failover da VM. Quando o tempo especificado tiver passado, o HA reiniciará as máquinas virtuais afetadas. Você pode configurar o VMCP para responder de forma diferente, se desejado (Desativado, Eventos de problemas ou Desligar e reiniciar VMs).
|
|
|
Implementação do VMware DRS para o NetApp SnapMirror ative Sync
O VMware DRS é um recurso que agrega os recursos de host em um cluster e é usado principalmente para o balanceamento de carga em um cluster em uma infraestrutura virtual. O VMware DRS calcula principalmente os recursos de CPU e memória para realizar o balanceamento de carga em um cluster. Como o vSphere não tem conhecimento do clustering estendido, ele considera todos os hosts em ambos os locais quando o balanceamento de carga.
Implementação do VMware DRS para NetApp MetroCluster
To avoid cross-site traffic, NetApp recommends configuring DRS affinity rules to manage a logical separation of VMs. This will ensure that, unless there is a complete site failure, HA and DRS will only use local hosts. Se você criar uma regra de afinidade DRS para o cluster, poderá especificar como o vSphere aplica essa regra durante um failover de máquina virtual.
Existem dois tipos de regras que você pode especificar para o comportamento de failover do vSphere HA:
-
As regras de anti-afinidade da VM forçam as máquinas virtuais especificadas a permanecerem separadas durante as ações de failover.
-
As regras de afinidade de host da VM colocam máquinas virtuais especificadas em um host específico ou em um membro de um grupo definido de hosts durante ações de failover.
Usando regras de afinidade de host de VM no VMware DRS, pode-se ter uma separação lógica entre o local A e o local B para que a VM seja executada no host no mesmo local do array configurado como o controlador de leitura/gravação primário para um determinado datastore. Além disso, as regras de afinidade de host da VM permitem que as máquinas virtuais permaneçam locais para o armazenamento, o que, por sua vez, verifica a conexão da máquina virtual em caso de falhas de rede entre os sites.
A seguir está um exemplo de grupos de hosts de VM e regras de afinidade.
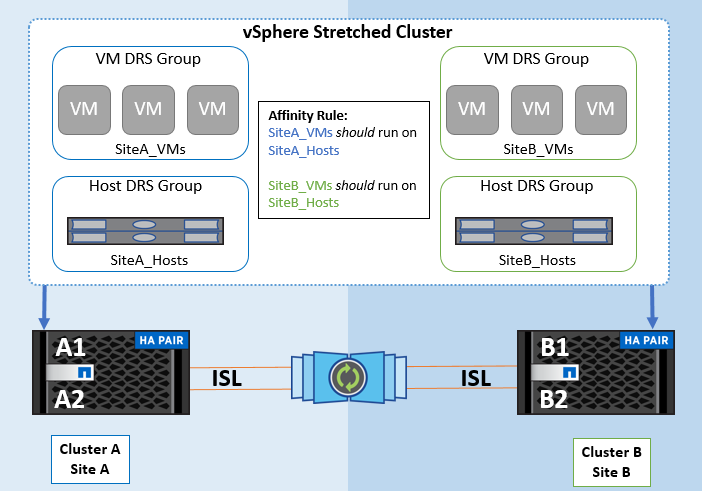
Melhor prática
A NetApp recomenda a implementação de regras "devem" em vez de regras "obrigatórias" porque elas são violadas pelo vSphere HA em caso de falha. O uso de regras "obrigatórias" pode potencialmente levar a interrupções de serviço.
A disponibilidade dos serviços deve sempre prevalecer sobre o desempenho. No cenário em que um data center inteiro falha, as regras "obrigatórias" devem escolher hosts do grupo de afinidade de hosts de VMs e, quando o data center estiver indisponível, as máquinas virtuais não serão reiniciadas.
Implementação do VMware Storage DRS com o NetApp MetroCluster
O recurso VMware Storage DRS permite a agregação de armazenamentos de dados em uma única unidade e equilibra discos de máquina virtual quando os limites de controle de e/S de armazenamento (SIOC) são excedidos.
O controle de e/S de armazenamento é habilitado por padrão nos clusters DRS habilitados para Storage DRS. O controle de e/S de armazenamento permite que um administrador controle a quantidade de e/S de armazenamento que é alocada a máquinas virtuais durante períodos de congestionamento de e/S, o que permite que máquinas virtuais mais importantes tenham preferência sobre máquinas virtuais menos importantes para alocação de recursos de e/S.
O Storage DRS usa o Storage vMotion para migrar as máquinas virtuais para diferentes datastores dentro de um cluster de datastore. Em um ambiente NetApp MetroCluster, a migração de uma máquina virtual precisa ser controlada nos datastores desse site. Por exemplo, a máquina virtual A, em execução em um host no local A, deve idealmente migrar dentro dos armazenamentos de dados do SVM no local A. se não o fizer, a máquina virtual continuará operando, mas com desempenho degradado, uma vez que a leitura/gravação do disco virtual será do local B através de links entre sites.
|
|
*Ao usar o armazenamento ONTAP, é recomendável desativar o DRS de armazenamento.
|