

ONTAP Select HA aprimora a proteção de dados
 Sugerir alterações
Sugerir alterações
O heartbeat de disco de alta disponibilidade (HA), a caixa de correio de HA, o heartbeat de HA, o failover de HA e o Giveback funcionam para aprimorar a proteção de dados.
Disco pulsante
Embora a arquitetura ONTAP Select HA aproveite muitos dos caminhos de código usados pelos arrays FAS tradicionais, existem algumas exceções. Uma delas está na implementação de heartbeating baseado em disco, um método de comunicação não baseado em rede usado por nós de cluster para evitar que o isolamento da rede cause comportamento de "split-brain". Um cenário de "split-brain" é o resultado do particionamento de cluster, normalmente causado por falhas de rede, em que cada lado acredita que o outro está inativo e tenta assumir o controle dos recursos do cluster.
Implementações de HA de nível empresarial devem lidar com esse tipo de cenário com elegância. O ONTAP faz isso por meio de um método personalizado de heartbeat baseado em disco. Essa é a função da caixa de correio de HA, um local no armazenamento físico usado pelos nós do cluster para transmitir mensagens de heartbeat. Isso ajuda o cluster a determinar a conectividade e, portanto, a definir o quorum em caso de failover.
Em matrizes FAS , que usam uma arquitetura de HA de armazenamento compartilhado, o ONTAP resolve problemas de split-brain das seguintes maneiras:
-
Reservas persistentes SCSI
-
Metadados de HA persistentes
-
Estado HA enviado por interconexão HA
No entanto, na arquitetura "shared nothing" de um cluster ONTAP Select , um nó só consegue visualizar seu próprio armazenamento local e não o do parceiro de HA. Portanto, quando o particionamento de rede isola cada lado de um par de HA, os métodos anteriores para determinar o quórum do cluster e o comportamento de failover não estão disponíveis.
Embora o método atual de detecção e prevenção de split-brain não possa ser utilizado, ainda é necessário um método de mediação que se ajuste às restrições de um ambiente sem compartilhamento. O ONTAP Select amplia ainda mais a infraestrutura de caixa de correio existente, permitindo que ela atue como um método de mediação em caso de particionamento de rede. Como o armazenamento compartilhado não está disponível, a mediação é realizada por meio do acesso aos discos da caixa de correio via NAS. Esses discos são distribuídos por todo o cluster, incluindo o mediador em um cluster de dois nós, usando o protocolo iSCSI. Portanto, decisões inteligentes de failover podem ser tomadas por um nó do cluster com base no acesso a esses discos. Se um nó puder acessar os discos da caixa de correio de outros nós fora de seu parceiro de alta disponibilidade, é provável que ele esteja ativo e íntegro.

|
A arquitetura de caixa de correio e o método de pulsação baseado em disco para resolver problemas de quorum de cluster e de cérebro dividido são os motivos pelos quais a variante multinó do ONTAP Select requer quatro nós separados ou um mediador para um cluster de dois nós. |
Postagem de caixa de correio HA
A arquitetura de caixa de correio de alta disponibilidade utiliza um modelo de postagem de mensagens. Em intervalos repetidos, os nós do cluster enviam mensagens para todos os outros discos de caixa de correio do cluster, incluindo o mediador, informando que o nó está ativo e em execução. Em um cluster íntegro, a qualquer momento, um único disco de caixa de correio em um nó do cluster recebe mensagens de todos os outros nós do cluster.
Anexado a cada nó do cluster Select, há um disco virtual usado especificamente para acesso compartilhado à caixa de correio. Esse disco é chamado de disco de caixa de correio mediador, pois sua principal função é atuar como um método de mediação do cluster em caso de falhas de nós ou particionamento de rede. Esse disco de caixa de correio contém partições para cada nó do cluster e é montado em uma rede iSCSI por outros nós do cluster Select. Periodicamente, esses nós publicam status de integridade na partição apropriada do disco da caixa de correio. O uso de discos de caixa de correio acessíveis pela rede, distribuídos pelo cluster, permite inferir a integridade do nó por meio de uma matriz de acessibilidade. Por exemplo, os nós A e B do cluster podem publicar na caixa de correio do nó D, mas não na caixa de correio do nó C. Além disso, o nó D do cluster não pode publicar na caixa de correio do nó C, portanto, é provável que o nó C esteja inativo ou isolado da rede e deva ser assumido.
HA pulsação
Assim como nas plataformas NetApp FAS , o ONTAP Select envia periodicamente mensagens de heartbeat de HA pela interconexão de HA. No cluster do ONTAP Select , isso é feito por meio de uma conexão de rede TCP/IP existente entre os parceiros de HA. Além disso, mensagens de heartbeat baseadas em disco são passadas para todos os discos da caixa de correio de HA, incluindo os discos da caixa de correio do mediador. Essas mensagens são passadas a cada poucos segundos e lidas periodicamente. A frequência com que são enviadas e recebidas permite que o cluster do ONTAP Select detecte eventos de falha de HA em aproximadamente 15 segundos, o mesmo período disponível nas plataformas FAS . Quando as mensagens de heartbeat não estão mais sendo lidas, um evento de failover é acionado.
A figura a seguir mostra o processo de envio e recebimento de mensagens de pulsação pelos discos de interconexão e mediador de HA da perspectiva de um único nó de cluster ONTAP Select , o nó C.
|
|
As pulsações de rede são enviadas pela interconexão de HA para o parceiro de HA, nó D, enquanto as pulsações de disco usam discos de caixa de correio em todos os nós do cluster, A, B, C e D. |
Pulsação cardíaca HA em um cluster de quatro nós: estado estável 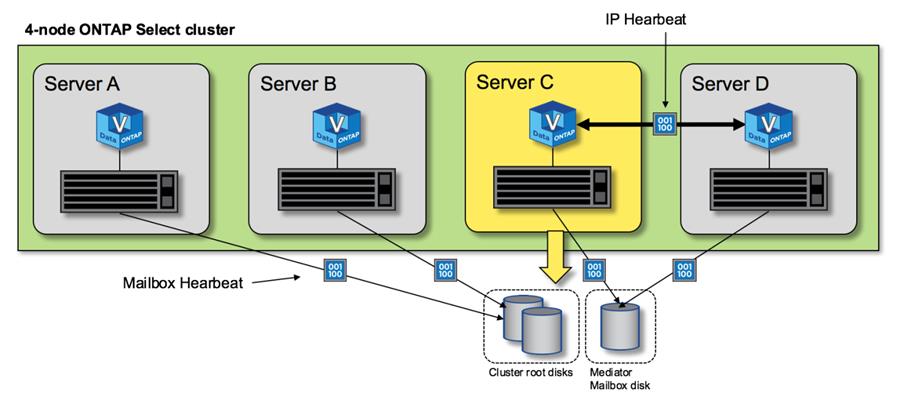
Failover e devolução de HA
Durante uma operação de failover, o nó sobrevivente assume as responsabilidades de fornecimento de dados para seu nó par, usando a cópia local dos dados do seu parceiro de HA. A E/S do cliente pode continuar ininterrupta, mas as alterações nesses dados devem ser replicadas antes que o retorno possa ocorrer. Observe que o ONTAP Select não suporta um retorno forçado, pois isso causa a perda das alterações armazenadas no nó sobrevivente.
A operação de sincronização reversa é acionada automaticamente quando o nó reinicializado se junta novamente ao cluster. O tempo necessário para a sincronização reversa depende de vários fatores. Esses fatores incluem o número de alterações que devem ser replicadas, a latência da rede entre os nós e a velocidade dos subsistemas de disco em cada nó. É possível que o tempo necessário para a sincronização reversa exceda a janela de retorno automático de 10 minutos. Nesse caso, é necessário um retorno manual após a sincronização reversa. O progresso da sincronização reversa pode ser monitorado usando o seguinte comando:
storage aggregate status -r -aggregate <aggregate name>