

Substitua uma placa PCIe - FAS8200
 Sugerir alterações
Sugerir alterações
Para substituir uma placa PCIe, é necessário executar uma sequência específica de tarefas.
-
Pode utilizar este procedimento com todas as versões do ONTAP suportadas pelo seu sistema
-
Todos os outros componentes do sistema devem estar funcionando corretamente; caso contrário, você deve entrar em Contato com o suporte técnico.
Passo 1: Desligue o controlador desativado
Você pode desligar ou assumir o controlador prejudicado usando procedimentos diferentes, dependendo da configuração do hardware do sistema de armazenamento.
Assuma o controle e interrompa o controlador com defeito para que o controlador em bom estado continue a fornecer dados do armazenamento do controlador com defeito. Para fazer isso, você suprime a criação automática de casos em AutoSupport, desativa o giveback automático e leva o controlador com defeito ao prompt LOADER. O prompt LOADER é o estado de parada segura a partir do qual você pode substituir a FRU.
-
Se você tiver um sistema SAN, você deve ter verificado mensagens de
cluster kernel-service show`evento ) para o blade SCSI do controlador afetado. O `cluster kernel-service showcomando (do modo avançado priv) exibe o nome do nó, "status do quorum"desse nó, o status de disponibilidade desse nó e o status operacional desse nó.Cada processo SCSI-blade deve estar em quórum com os outros nós no cluster. Qualquer problema deve ser resolvido antes de prosseguir com a substituição.
-
Se você tiver um cluster com mais de dois nós, ele deverá estar no quórum. Se o cluster não estiver em quórum ou se um controlador íntegro exibir false para qualificação e integridade, você deverá corrigir o problema antes de encerrar o controlador prejudicado; "Sincronize um nó com o cluster"consulte .
-
Se o AutoSupport estiver ativado, suprimir a criação automática de casos invocando uma mensagem AutoSupport:
system node autosupport invoke -node * -type all -message MAINT=<number of hours down>hIsso impede a abertura automática de chamados de suporte durante sua janela de manutenção planejada. A duração máxima da supressão é de 72 horas. Se a manutenção for concluída antes do prazo, você pode reativar a criação de chamados enviando uma mensagem AutoSupport com
MAINT=END. Para mais informações, consulte "Como impedir a criação automática de chamados durante janelas de manutenção programadas".A seguinte mensagem AutoSupport suprime a criação automática de casos por duas horas:
cluster1:> system node autosupport invoke -node * -type all -message MAINT=2h -
Desabilitar devolução automática:
-
Digite o seguinte comando no console do controlador íntegro:
storage failover modify -node impaired_node_name -auto-giveback false -
Digitar
yquando você vê o prompt Você quer desabilitar o retorno automático?
-
-
Leve o controlador prejudicado para o prompt Loader:
Se o controlador afetado estiver a apresentar… Então… O prompt Loader
Vá para a próxima etapa.
A aguardar pela giveback…
Pressione Ctrl-C e responda
yquando solicitado.Prompt do sistema ou prompt de senha
Assuma ou interrompa o controlador prejudicado do controlador saudável:
storage failover takeover -ofnode impaired_node_name -halt trueO parâmetro -halt True traz para o prompt Loader.
Para desligar o controlador desativado, você deve determinar o status do controlador e, se necessário, trocar o controlador para que o controlador saudável continue fornecendo dados do armazenamento do controlador prejudicado.
-
Você deve deixar as fontes de alimentação ligadas no final deste procedimento para fornecer energia ao controlador de integridade.
-
Verifique o estado do MetroCluster para determinar se o controlador afetado mudou automaticamente para o controlador saudável:
metrocluster show -
Dependendo se ocorreu uma mudança automática, proceda de acordo com a seguinte tabela:
Se o controlador deficiente… Então… Mudou automaticamente
Avance para o passo seguinte.
Não mudou automaticamente
Execute uma operação de comutação planejada a partir do controlador íntegro:
metrocluster switchoverNão mudou automaticamente, tentou mudar com o comando e o switchover
metrocluster switchoverfoi vetadoReveja as mensagens de veto e, se possível, resolva o problema e tente novamente. Se você não conseguir resolver o problema, entre em Contato com o suporte técnico.
-
Ressincronize os agregados de dados executando o
metrocluster heal -phase aggregatescomando do cluster sobrevivente.controller_A_1::> metrocluster heal -phase aggregates [Job 130] Job succeeded: Heal Aggregates is successful.
Se a cura for vetada, você tem a opção de reemitir o
metrocluster healcomando com o-override-vetoesparâmetro. Se você usar esse parâmetro opcional, o sistema substituirá quaisquer vetos de software que impeçam a operação de recuperação. -
Verifique se a operação foi concluída usando o comando MetroCluster operation show.
controller_A_1::> metrocluster operation show Operation: heal-aggregates State: successful Start Time: 7/25/2016 18:45:55 End Time: 7/25/2016 18:45:56 Errors: - -
Verifique o estado dos agregados utilizando o
storage aggregate showcomando.controller_A_1::> storage aggregate show Aggregate Size Available Used% State #Vols Nodes RAID Status --------- -------- --------- ----- ------- ------ ---------------- ------------ ... aggr_b2 227.1GB 227.1GB 0% online 0 mcc1-a2 raid_dp, mirrored, normal...
-
Curar os agregados raiz usando o
metrocluster heal -phase root-aggregatescomando.mcc1A::> metrocluster heal -phase root-aggregates [Job 137] Job succeeded: Heal Root Aggregates is successful
Se a recuperação for vetada, você terá a opção de reemitir o
metrocluster healcomando com o parâmetro -override-vetos. Se você usar esse parâmetro opcional, o sistema substituirá quaisquer vetos de software que impeçam a operação de recuperação. -
Verifique se a operação heal está concluída usando o
metrocluster operation showcomando no cluster de destino:mcc1A::> metrocluster operation show Operation: heal-root-aggregates State: successful Start Time: 7/29/2016 20:54:41 End Time: 7/29/2016 20:54:42 Errors: - -
No módulo do controlador desativado, desligue as fontes de alimentação.
Passo 2: Abra o módulo do controlador
Para aceder aos componentes no interior do controlador, tem de remover primeiro o módulo do controlador do sistema e, em seguida, remover a tampa do módulo do controlador.
-
Se você ainda não está aterrado, aterre-se adequadamente.
-
Solte o gancho e a alça de loop que prendem os cabos ao dispositivo de gerenciamento de cabos e, em seguida, desconete os cabos do sistema e os SFPs (se necessário) do módulo do controlador, mantendo o controle de onde os cabos estavam conetados.
Deixe os cabos no dispositivo de gerenciamento de cabos para que, ao reinstalar o dispositivo de gerenciamento de cabos, os cabos sejam organizados.
-
Retire e reserve os dispositivos de gerenciamento de cabos dos lados esquerdo e direito do módulo do controlador.
![Remover os braços de gestão do cabo][](../media/drw_32xx_cbl_mgmt_arm.png)
-
Desaperte o parafuso de aperto manual na pega do excêntrico no módulo do controlador.
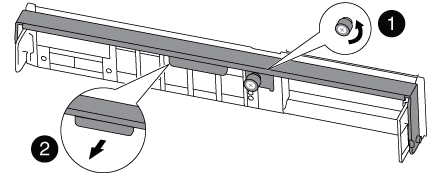

Parafuso de aperto manual

Pega do came
-
Puxe a alavanca do came para baixo e comece a deslizar o módulo do controlador para fora do chassis.
Certifique-se de que suporta a parte inferior do módulo do controlador enquanto o desliza para fora do chassis.
Etapa 3: Substitua uma placa PCIe
Para substituir uma placa PCIe, localize-a dentro da controladora e siga a sequência específica de etapas.
-
Desaperte o parafuso de aperto manual no painel lateral do módulo do controlador.
-
Rode o painel lateral para fora do módulo do controlador.
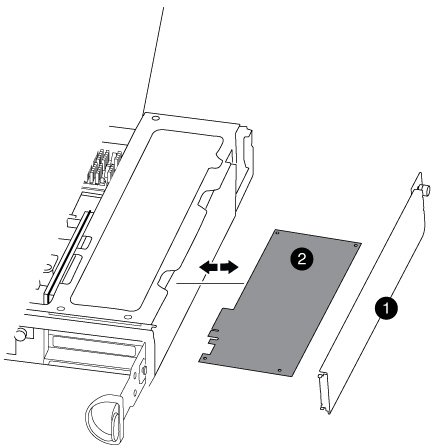
Painel lateral
Placa PCIe
-
Retire a placa PCIe do módulo da controladora e reserve-a.
-
Instale a placa PCIe de substituição.
Certifique-se de que alinha corretamente a placa na ranhura e exerce uma pressão uniforme sobre a placa quando a coloca na tomada. A placa PCIe deve estar totalmente e uniformemente encaixada no slot.

Se você estiver instalando uma placa no slot inferior e não conseguir ver bem o soquete da placa, remova a placa superior para que você possa ver o soquete da placa, instalar a placa e reinstalar a placa que você removeu do slot superior. -
Feche o painel lateral e aperte o parafuso de aperto manual.
Etapa 4: Reinstale o controlador
Depois de substituir um componente dentro do módulo do controlador, você deve reinstalar o módulo do controlador no chassi do sistema e iniciá-lo.
-
Alinhe a extremidade do módulo do controlador com a abertura no chassis e, em seguida, empurre cuidadosamente o módulo do controlador até meio do sistema.
Não introduza completamente o módulo do controlador no chassis até ser instruído a fazê-lo. -
Recable o sistema, conforme necessário.
Se você removeu os conversores de Mídia (QSFPs ou SFPs), lembre-se de reinstalá-los se você estiver usando cabos de fibra ótica.
-
Conclua a reinstalação do módulo do controlador:
O módulo do controlador começa a arrancar assim que estiver totalmente assente no chassis.
Se o seu sistema estiver em… Em seguida, execute estas etapas… Um par de HA
-
Com a alavanca do came na posição aberta, empurre firmemente o módulo do controlador até que ele atenda ao plano médio e esteja totalmente assentado e, em seguida, feche a alavanca do came para a posição travada. Aperte o parafuso de aperto manual na pega do came na parte de trás do módulo do controlador.
Não utilize força excessiva ao deslizar o módulo do controlador para dentro do chassis para evitar danificar os conetores. -
Se ainda não o tiver feito, reinstale o dispositivo de gerenciamento de cabos.
-
Se ainda não o tiver feito, volte a ligar os cabos ao módulo do controlador.
-
Prenda os cabos ao dispositivo de gerenciamento de cabos com o gancho e a alça de loop.
Uma configuração de MetroCluster de dois nós
-
Com a alavanca do came na posição aberta, empurre firmemente o módulo do controlador até que ele atenda ao plano médio e esteja totalmente assentado e, em seguida, feche a alavanca do came para a posição travada. Aperte o parafuso de aperto manual na pega do came na parte de trás do módulo do controlador.
Não utilize força excessiva ao deslizar o módulo do controlador para dentro do chassis para evitar danificar os conetores. -
Se ainda não o tiver feito, reinstale o dispositivo de gerenciamento de cabos.
-
Se ainda não o tiver feito, volte a ligar os cabos ao módulo do controlador.
-
Prenda os cabos ao dispositivo de gerenciamento de cabos com o gancho e a alça de loop.
-
Volte a ligar os cabos de alimentação às fontes de alimentação e às fontes de alimentação e, em seguida, ligue a alimentação para iniciar o processo de arranque.
-
-
Se o sistema estiver configurado para suportar interconexão de cluster de 10 GbE e conexões de dados em NICs de 40 GbE ou portas integradas, converta essas portas em conexões de 10 GbE usando o comando nicadmin Convert do modo de manutenção.
Certifique-se de sair do modo de manutenção depois de concluir a conversão. -
Volte a colocar o controlador em funcionamento normal:
Se o seu sistema estiver em… Emita este comando a partir do console do parceiro… Um par de HA
storage failover giveback -ofnode impaired_node_nameUma configuração de MetroCluster de dois nós
Avance para o passo seguinte. O procedimento de switchback do MetroCluster é feito na próxima tarefa no processo de substituição.
-
Se a giveback automática foi desativada, reative-a:
storage failover modify -node local -auto-giveback true
Etapa 5 (somente MetroCluster de dois nós): Alterne o agregado de volta
Esta tarefa só se aplica a configurações de MetroCluster de dois nós.
-
Verifique se todos os nós estão no
enabledestado:metrocluster node showcluster_B::> metrocluster node show DR Configuration DR Group Cluster Node State Mirroring Mode ----- ------- -------------- -------------- --------- -------------------- 1 cluster_A controller_A_1 configured enabled heal roots completed cluster_B controller_B_1 configured enabled waiting for switchback recovery 2 entries were displayed. -
Verifique se a ressincronização está concluída em todos os SVMs:
metrocluster vserver show -
Verifique se todas as migrações automáticas de LIF que estão sendo executadas pelas operações de recuperação foram concluídas com sucesso:
metrocluster check lif show -
Execute o switchback usando o
metrocluster switchbackcomando de qualquer nó no cluster sobrevivente. -
Verifique se a operação de comutação foi concluída:
metrocluster showA operação de switchback ainda está em execução quando um cluster está no
waiting-for-switchbackestado:cluster_B::> metrocluster show Cluster Configuration State Mode -------------------- ------------------- --------- Local: cluster_B configured switchover Remote: cluster_A configured waiting-for-switchback
A operação de switchback é concluída quando os clusters estão no
normalestado.:cluster_B::> metrocluster show Cluster Configuration State Mode -------------------- ------------------- --------- Local: cluster_B configured normal Remote: cluster_A configured normal
Se um switchback estiver demorando muito tempo para terminar, você pode verificar o status das linhas de base em andamento usando o
metrocluster config-replication resync-status showcomando. -
Restabelecer qualquer configuração SnapMirror ou SnapVault.
Passo 6: Devolva a peça com falha ao NetApp
Devolva a peça com falha ao NetApp, conforme descrito nas instruções de RMA fornecidas com o kit. Consulte a "Devolução de peças e substituições" página para obter mais informações.