

Substitua um DIMM - FAS8300 e FAS8700
 Sugerir alterações
Sugerir alterações
Você deve substituir um DIMM no controlador quando seu sistema de armazenamento encontrar erros como erros CECC excessivos (códigos de correção de erros Correctable) que são baseados em alertas do Monitor de integridade ou erros ECC incorrigíveis, geralmente causados por uma única falha de DIMM que impede o sistema de armazenamento de inicializar o ONTAP.
Todos os outros componentes do sistema devem estar funcionando corretamente; caso contrário, você deve entrar em Contato com o suporte técnico.
Você deve substituir o componente com falha por um componente FRU de substituição que você recebeu de seu provedor.
Passo 1: Desligue o controlador desativado
Você pode desligar ou assumir o controlador prejudicado usando procedimentos diferentes, dependendo da configuração do hardware do sistema de armazenamento.
Assuma o controle e interrompa o controlador com defeito para que o controlador em bom estado continue a fornecer dados do armazenamento do controlador com defeito. Para fazer isso, você suprime a criação automática de casos em AutoSupport, desativa o giveback automático e leva o controlador com defeito ao prompt LOADER. O prompt LOADER é o estado de parada segura a partir do qual você pode substituir a FRU.
-
Se você tiver um sistema SAN, você deve ter verificado mensagens de
cluster kernel-service show`evento ) para o blade SCSI do controlador afetado. O `cluster kernel-service showcomando (do modo avançado priv) exibe o nome do nó, "status do quorum"desse nó, o status de disponibilidade desse nó e o status operacional desse nó.Cada processo SCSI-blade deve estar em quórum com os outros nós no cluster. Qualquer problema deve ser resolvido antes de prosseguir com a substituição.
-
Se você tiver um cluster com mais de dois nós, ele deverá estar no quórum. Se o cluster não estiver em quórum ou se um controlador íntegro exibir false para qualificação e integridade, você deverá corrigir o problema antes de encerrar o controlador prejudicado; "Sincronize um nó com o cluster"consulte .
-
Se o AutoSupport estiver ativado, suprimir a criação automática de casos invocando uma mensagem AutoSupport:
system node autosupport invoke -node * -type all -message MAINT=<number of hours down>hIsso impede a abertura automática de chamados de suporte durante sua janela de manutenção planejada. A duração máxima da supressão é de 72 horas. Se a manutenção for concluída antes do prazo, você pode reativar a criação de chamados enviando uma mensagem AutoSupport com
MAINT=END. Para mais informações, consulte "Como impedir a criação automática de chamados durante janelas de manutenção programadas".A seguinte mensagem AutoSupport suprime a criação automática de casos por duas horas:
cluster1:> system node autosupport invoke -node * -type all -message MAINT=2h -
Desabilitar devolução automática:
-
Digite o seguinte comando no console do controlador íntegro:
storage failover modify -node impaired_node_name -auto-giveback false -
Digitar
yquando você vê o prompt Você quer desabilitar o retorno automático?
-
-
Leve o controlador prejudicado para o prompt Loader:
Se o controlador afetado estiver a apresentar… Então… O prompt Loader
Vá para a próxima etapa.
A aguardar pela giveback…
Pressione Ctrl-C e responda
yquando solicitado.Prompt do sistema ou prompt de senha
Assuma ou interrompa o controlador prejudicado do controlador saudável:
storage failover takeover -ofnode impaired_node_name -halt trueO parâmetro -halt True traz para o prompt Loader.
Para desligar o controlador desativado, você deve determinar o status do controlador e, se necessário, trocar o controlador para que o controlador saudável continue fornecendo dados do armazenamento do controlador prejudicado.
-
Você deve deixar as fontes de alimentação ligadas no final deste procedimento para fornecer energia ao controlador de integridade.
-
Verifique o estado do MetroCluster para determinar se o controlador afetado mudou automaticamente para o controlador saudável:
metrocluster show -
Dependendo se ocorreu uma mudança automática, proceda de acordo com a seguinte tabela:
Se o controlador deficiente… Então… Mudou automaticamente
Avance para o passo seguinte.
Não mudou automaticamente
Execute uma operação de comutação planejada a partir do controlador íntegro:
metrocluster switchoverNão mudou automaticamente, tentou mudar com o comando e o switchover
metrocluster switchoverfoi vetadoReveja as mensagens de veto e, se possível, resolva o problema e tente novamente. Se você não conseguir resolver o problema, entre em Contato com o suporte técnico.
-
Ressincronize os agregados de dados executando o
metrocluster heal -phase aggregatescomando do cluster sobrevivente.controller_A_1::> metrocluster heal -phase aggregates [Job 130] Job succeeded: Heal Aggregates is successful.
Se a cura for vetada, você tem a opção de reemitir o
metrocluster healcomando com o-override-vetoesparâmetro. Se você usar esse parâmetro opcional, o sistema substituirá quaisquer vetos de software que impeçam a operação de recuperação. -
Verifique se a operação foi concluída usando o comando MetroCluster operation show.
controller_A_1::> metrocluster operation show Operation: heal-aggregates State: successful Start Time: 7/25/2016 18:45:55 End Time: 7/25/2016 18:45:56 Errors: - -
Verifique o estado dos agregados utilizando o
storage aggregate showcomando.controller_A_1::> storage aggregate show Aggregate Size Available Used% State #Vols Nodes RAID Status --------- -------- --------- ----- ------- ------ ---------------- ------------ ... aggr_b2 227.1GB 227.1GB 0% online 0 mcc1-a2 raid_dp, mirrored, normal...
-
Curar os agregados raiz usando o
metrocluster heal -phase root-aggregatescomando.mcc1A::> metrocluster heal -phase root-aggregates [Job 137] Job succeeded: Heal Root Aggregates is successful
Se a recuperação for vetada, você terá a opção de reemitir o
metrocluster healcomando com o parâmetro -override-vetos. Se você usar esse parâmetro opcional, o sistema substituirá quaisquer vetos de software que impeçam a operação de recuperação. -
Verifique se a operação heal está concluída usando o
metrocluster operation showcomando no cluster de destino:mcc1A::> metrocluster operation show Operation: heal-root-aggregates State: successful Start Time: 7/29/2016 20:54:41 End Time: 7/29/2016 20:54:42 Errors: - -
No módulo do controlador desativado, desligue as fontes de alimentação.
Passo 2: Remova o módulo do controlador
Para aceder aos componentes no interior do módulo do controlador, tem de remover o módulo do controlador do chassis.
Você pode usar a animação, ilustração ou as etapas escritas a seguir para remover o módulo do controlador do chassi.

-
Se você ainda não está aterrado, aterre-se adequadamente.
-
Solte os fixadores do cabo de alimentação e, em seguida, desconete os cabos das fontes de alimentação.
-
Solte o gancho e a alça de loop que prendem os cabos ao dispositivo de gerenciamento de cabos e, em seguida, desconete os cabos do sistema e os SFPs (se necessário) do módulo do controlador, mantendo o controle de onde os cabos estavam conetados.
Deixe os cabos no dispositivo de gerenciamento de cabos para que, ao reinstalar o dispositivo de gerenciamento de cabos, os cabos sejam organizados.
-
Retire o dispositivo de gestão de cabos do módulo do controlador e coloque-o de lado.
-
Prima ambos os trincos de bloqueio para baixo e, em seguida, rode ambos os trincos para baixo ao mesmo tempo.
O módulo do controlador desloca-se ligeiramente para fora do chassis.
-
Faça deslizar o módulo do controlador para fora do chassis.
Certifique-se de que suporta a parte inferior do módulo do controlador enquanto o desliza para fora do chassis.
-
Coloque o módulo do controlador numa superfície estável e plana.
Etapa 3: Substitua os DIMMs do sistema
A substituição de um DIMM do sistema envolve a identificação do DIMM de destino através da mensagem de erro associada, a localização do DIMM de destino usando o mapa da FRU no duto de ar e, em seguida, a substituição do DIMM.
Você pode usar a animação, ilustração ou as etapas escritas a seguir para substituir um DIMM do sistema.

|
A animação e a ilustração mostram slots vazios para soquetes sem DIMMs. Esses soquetes vazios são preenchidos com espaços em branco. |
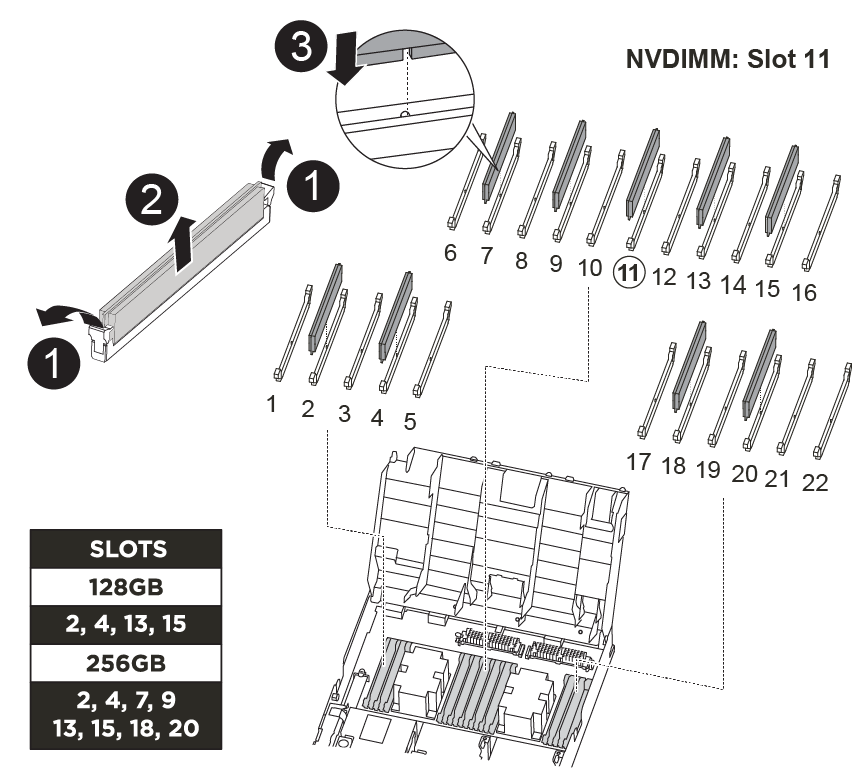
O número e a localização dos DIMMS no seu sistema dependem do modelo do seu sistema. Consulte o mapa da FRU na conduta de ar para obter mais informações.
-
Se você tiver um sistema FAS8300, os DIMMs do sistema estão localizados nos soquetes 2, 4, 13 e 15.
-
Se você tiver um sistema FAS8700, os DIMMs do sistema estão localizados nos slots 2, 4, 7, 9, 13, 15, 18 e 20.
-
O NVDIMM está localizado no slot 11.
-
Abrir a conduta de ar:
-
Pressione as patilhas de bloqueio nas laterais da conduta de ar para dentro, em direção ao centro do módulo do controlador.
-
Faça deslizar a conduta de ar em direção à parte de trás do módulo do controlador e, em seguida, rode-a para cima até à posição completamente aberta.
-
-
Localize os DIMMs no módulo do controlador.
-
Observe a orientação do DIMM no soquete para que você possa inserir o DIMM de substituição na orientação adequada.
-
Ejete o DIMM do soquete empurrando lentamente as duas abas do ejetor do DIMM em ambos os lados do DIMM e, em seguida, deslize o DIMM para fora do soquete.
Segure cuidadosamente o DIMM pelas bordas para evitar a pressão nos componentes da placa de circuito DIMM. -
Remova o DIMM de substituição do saco de transporte antiestático, segure o DIMM pelos cantos e alinhe-o com o slot.
O entalhe entre os pinos no DIMM deve estar alinhado com a guia no soquete.
-
Certifique-se de que as abas do ejetor DIMM no conetor estão na posição aberta e insira o DIMM diretamente no slot.
O DIMM encaixa firmemente no slot, mas deve entrar facilmente. Caso contrário, realinhar o DIMM com o slot e reinseri-lo.
Inspecione visualmente o DIMM para verificar se ele está alinhado uniformemente e totalmente inserido no slot. -
Empurre com cuidado, mas firmemente, na borda superior do DIMM até que as abas do ejetor se encaixem no lugar sobre os entalhes nas extremidades do DIMM.
-
Feche a conduta de ar.
Passo 4: Instale o módulo do controlador
Depois de ter substituído o componente no módulo do controlador, tem de reinstalar o módulo do controlador no chassis.
Você pode usar a animação, desenho ou as etapas escritas a seguir para instalar o módulo do controlador no chassi.
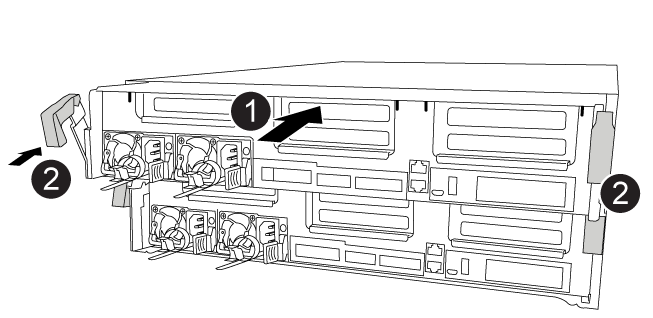
-
Se ainda não o tiver feito, feche a conduta de ar.
-
Alinhe a extremidade do módulo do controlador com a abertura no chassis e, em seguida, empurre cuidadosamente o módulo do controlador até meio do sistema.
Não introduza completamente o módulo do controlador no chassis até ser instruído a fazê-lo. -
Faça o cabeamento apenas das portas de gerenciamento e console, para que você possa acessar o sistema para executar as tarefas nas seções a seguir.
Você conetará o resto dos cabos ao módulo do controlador posteriormente neste procedimento. -
Conclua a instalação do módulo do controlador:
-
Utilizando os trincos de bloqueio, empurre firmemente o módulo do controlador para dentro do chassis até que os trincos de bloqueio comecem a subir.
Não utilize força excessiva ao deslizar o módulo do controlador para dentro do chassis para evitar danificar os conetores. -
Assente totalmente o módulo do controlador no chassis, rodando os trincos de bloqueio para cima, inclinando-os para que estes limpem os pinos de bloqueio, empurre cuidadosamente o controlador totalmente para dentro e, em seguida, baixe os trincos de bloqueio para a posição de bloqueio.
-
Conete os cabos de alimentação às fontes de alimentação, reinstale o colar de travamento do cabo de alimentação e, em seguida, conete as fontes de alimentação à fonte de alimentação.
O módulo do controlador começa a inicializar assim que a energia é restaurada. Esteja preparado para interromper o processo de inicialização.
-
Se ainda não o tiver feito, reinstale o dispositivo de gerenciamento de cabos.
-
Interrompa o processo normal de inicialização e inicialize no Loader pressionando
Ctrl-C.
Se o sistema parar no menu de inicialização, selecione a opção para inicializar NO Loader. -
No prompt Loader, digite
byepara reinicializar as placas PCIe e outros componentes.
-
Passo 5: Restaure o módulo do controlador para a operação
Você deve reajustar o sistema, devolver o módulo do controlador e, em seguida, reativar a giveback automática.
-
Recable o sistema, conforme necessário.
Se você removeu os conversores de Mídia (QSFPs ou SFPs), lembre-se de reinstalá-los se você estiver usando cabos de fibra ótica.
-
Volte a colocar o controlador em funcionamento normal, devolvendo o respetivo armazenamento:
storage failover giveback -ofnode impaired_node_name -
Se a giveback automática foi desativada, reative-a:
storage failover modify -node local -auto-giveback true
Etapa 6: Alterne agregados de volta em uma configuração de MetroCluster de dois nós
Esta tarefa só se aplica a configurações de MetroCluster de dois nós.
-
Verifique se todos os nós estão no
enabledestado:metrocluster node showcluster_B::> metrocluster node show DR Configuration DR Group Cluster Node State Mirroring Mode ----- ------- -------------- -------------- --------- -------------------- 1 cluster_A controller_A_1 configured enabled heal roots completed cluster_B controller_B_1 configured enabled waiting for switchback recovery 2 entries were displayed. -
Verifique se a ressincronização está concluída em todos os SVMs:
metrocluster vserver show -
Verifique se todas as migrações automáticas de LIF que estão sendo executadas pelas operações de recuperação foram concluídas com sucesso:
metrocluster check lif show -
Execute o switchback usando o
metrocluster switchbackcomando de qualquer nó no cluster sobrevivente. -
Verifique se a operação de comutação foi concluída:
metrocluster showA operação de switchback ainda está em execução quando um cluster está no
waiting-for-switchbackestado:cluster_B::> metrocluster show Cluster Configuration State Mode -------------------- ------------------- --------- Local: cluster_B configured switchover Remote: cluster_A configured waiting-for-switchback
A operação de switchback é concluída quando os clusters estão no
normalestado.:cluster_B::> metrocluster show Cluster Configuration State Mode -------------------- ------------------- --------- Local: cluster_B configured normal Remote: cluster_A configured normal
Se um switchback estiver demorando muito tempo para terminar, você pode verificar o status das linhas de base em andamento usando o
metrocluster config-replication resync-status showcomando. -
Restabelecer qualquer configuração SnapMirror ou SnapVault.
Passo 7: Devolva a peça com falha ao NetApp
Devolva a peça com falha ao NetApp, conforme descrito nas instruções de RMA fornecidas com o kit. Consulte a "Devolução de peças e substituições" página para obter mais informações.