

Substitua o módulo NVRAM ou DIMMs NVRAM - FAS9000
 Sugerir alterações
Sugerir alterações
O módulo NVRAM consiste no NVRAM10 e DIMMs e até dois módulos de cache flash SSD NVMe (módulos de cache ou cache) por módulo NVRAM. Você pode substituir um módulo NVRAM com falha ou os DIMMs dentro do módulo NVRAM.
Para substituir um módulo NVRAM com falha, você deve removê-lo do chassi, remover o módulo Flash Cache ou módulos do módulo NVRAM, mover os DIMMs para o módulo de substituição, reinstalar o módulo Flash Cache ou módulos e instalar o módulo NVRAM de substituição no chassi.
Uma vez que a ID do sistema é derivada do módulo NVRAM, se substituir o módulo, os discos pertencentes ao sistema são reatribuídos à nova ID do sistema.
-
Todas as gavetas de disco devem estar funcionando corretamente.
-
Se o seu sistema estiver em um par de HA, o nó do parceiro precisará ser capaz de assumir o nó associado ao módulo NVRAM que está sendo substituído.
-
Este procedimento utiliza a seguinte terminologia:
-
O nó prejudicado é o nó no qual você está realizando a manutenção.
-
O nó Healthy é o parceiro de HA do nó prejudicado.
-
-
Este procedimento inclui etapas para reatribuir discos automaticamente ou manualmente ao módulo de controladora associado ao novo módulo NVRAM. Você deve reatribuir os discos quando direcionado para o procedimento. Concluir a reatribuição do disco antes da giveback pode causar problemas.
-
Você deve substituir o componente com falha por um componente FRU de substituição que você recebeu de seu provedor.
-
Não é possível alterar nenhum disco ou compartimentos de disco como parte deste procedimento.
Passo 1: Desligue o controlador desativado
Encerre ou assuma o controlador afetado utilizando uma das seguintes opções.
Assuma o controle e interrompa o controlador com defeito para que o controlador em bom estado continue a fornecer dados do armazenamento do controlador com defeito. Para fazer isso, você suprime a criação automática de casos em AutoSupport, desativa o giveback automático e leva o controlador com defeito ao prompt LOADER. O prompt LOADER é o estado de parada segura a partir do qual você pode substituir a FRU.
-
Se você tiver um sistema SAN, você deve ter verificado mensagens de
cluster kernel-service show`evento ) para o blade SCSI do controlador afetado. O `cluster kernel-service showcomando (do modo avançado priv) exibe o nome do nó, "status do quorum"desse nó, o status de disponibilidade desse nó e o status operacional desse nó.Cada processo SCSI-blade deve estar em quórum com os outros nós no cluster. Qualquer problema deve ser resolvido antes de prosseguir com a substituição.
-
Se você tiver um cluster com mais de dois nós, ele deverá estar no quórum. Se o cluster não estiver em quórum ou se um controlador íntegro exibir false para qualificação e integridade, você deverá corrigir o problema antes de encerrar o controlador prejudicado; "Sincronize um nó com o cluster"consulte .
-
Se o AutoSupport estiver ativado, suprimir a criação automática de casos invocando uma mensagem AutoSupport:
system node autosupport invoke -node * -type all -message MAINT=<number of hours down>hIsso impede a abertura automática de chamados de suporte durante sua janela de manutenção planejada. A duração máxima da supressão é de 72 horas. Se a manutenção for concluída antes do prazo, você pode reativar a criação de chamados enviando uma mensagem AutoSupport com
MAINT=END. Para mais informações, consulte "Como impedir a criação automática de chamados durante janelas de manutenção programadas".A seguinte mensagem AutoSupport suprime a criação automática de casos por duas horas:
cluster1:> system node autosupport invoke -node * -type all -message MAINT=2h -
Desabilitar devolução automática:
-
Digite o seguinte comando no console do controlador íntegro:
storage failover modify -node impaired_node_name -auto-giveback false -
Digitar
yquando você vê o prompt Você quer desabilitar o retorno automático?
-
-
Leve o controlador prejudicado para o prompt Loader:
Se o controlador afetado estiver a apresentar… Então… O prompt Loader
Vá para a próxima etapa.
A aguardar pela giveback…
Pressione Ctrl-C e responda
yquando solicitado.Prompt do sistema ou prompt de senha
Assuma ou interrompa o controlador prejudicado do controlador saudável:
storage failover takeover -ofnode impaired_node_name -halt trueO parâmetro -halt True traz para o prompt Loader.
Para desligar o controlador desativado, você deve determinar o status do controlador e, se necessário, trocar o controlador para que o controlador saudável continue fornecendo dados do armazenamento do controlador prejudicado.
-
Você deve deixar as fontes de alimentação ligadas no final deste procedimento para fornecer energia ao controlador de integridade.
-
Verifique o estado do MetroCluster para determinar se o controlador afetado mudou automaticamente para o controlador saudável:
metrocluster show -
Dependendo se ocorreu uma mudança automática, proceda de acordo com a seguinte tabela:
Se o controlador deficiente… Então… Mudou automaticamente
Avance para o passo seguinte.
Não mudou automaticamente
Execute uma operação de comutação planejada a partir do controlador íntegro:
metrocluster switchoverNão mudou automaticamente, tentou mudar com o comando e o switchover
metrocluster switchoverfoi vetadoReveja as mensagens de veto e, se possível, resolva o problema e tente novamente. Se você não conseguir resolver o problema, entre em Contato com o suporte técnico.
-
Ressincronize os agregados de dados executando o
metrocluster heal -phase aggregatescomando do cluster sobrevivente.controller_A_1::> metrocluster heal -phase aggregates [Job 130] Job succeeded: Heal Aggregates is successful.
Se a cura for vetada, você tem a opção de reemitir o
metrocluster healcomando com o-override-vetoesparâmetro. Se você usar esse parâmetro opcional, o sistema substituirá quaisquer vetos de software que impeçam a operação de recuperação. -
Verifique se a operação foi concluída usando o comando MetroCluster operation show.
controller_A_1::> metrocluster operation show Operation: heal-aggregates State: successful Start Time: 7/25/2016 18:45:55 End Time: 7/25/2016 18:45:56 Errors: - -
Verifique o estado dos agregados utilizando o
storage aggregate showcomando.controller_A_1::> storage aggregate show Aggregate Size Available Used% State #Vols Nodes RAID Status --------- -------- --------- ----- ------- ------ ---------------- ------------ ... aggr_b2 227.1GB 227.1GB 0% online 0 mcc1-a2 raid_dp, mirrored, normal...
-
Curar os agregados raiz usando o
metrocluster heal -phase root-aggregatescomando.mcc1A::> metrocluster heal -phase root-aggregates [Job 137] Job succeeded: Heal Root Aggregates is successful
Se a recuperação for vetada, você terá a opção de reemitir o
metrocluster healcomando com o parâmetro -override-vetos. Se você usar esse parâmetro opcional, o sistema substituirá quaisquer vetos de software que impeçam a operação de recuperação. -
Verifique se a operação heal está concluída usando o
metrocluster operation showcomando no cluster de destino:mcc1A::> metrocluster operation show Operation: heal-root-aggregates State: successful Start Time: 7/29/2016 20:54:41 End Time: 7/29/2016 20:54:42 Errors: - -
No módulo do controlador desativado, desligue as fontes de alimentação.
Passo 2: Substitua o módulo NVRAM
Para substituir o módulo NVRAM, localize-o na ranhura 6 no chassis e siga a sequência específica de passos.
-
Se você ainda não está aterrado, aterre-se adequadamente.
-
Mova o módulo Flash Cache do módulo NVRAM antigo para o novo módulo NVRAM:
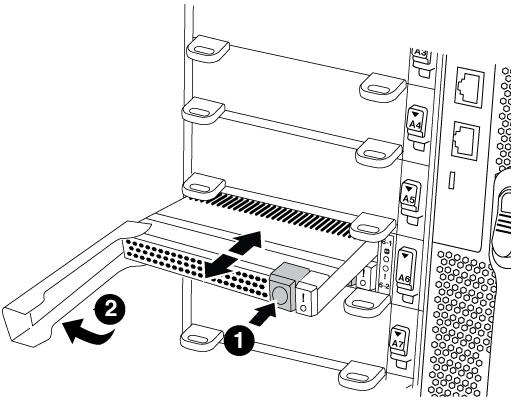

Botão de liberação laranja (cinza nos módulos Flash Cache vazios)

Pega da câmara Flash Cache
-
Pressione o botão laranja na parte frontal do módulo Flash Cache.

O botão de liberação nos módulos vazios do Flash Cache está cinza. -
Rode o manípulo do excêntrico para fora até que o módulo comece a deslizar para fora do módulo NVRAM antigo.
-
Segure a pega do came do módulo e deslize-a para fora do módulo NVRAM e insira-a na parte frontal do novo módulo NVRAM.
-
Empurre cuidadosamente o módulo Flash Cache totalmente para dentro do módulo NVRAM e, em seguida, gire a alavanca do came para fechar até que ele bloqueie o módulo no lugar.
-
-
Retire o módulo NVRAM alvo do chassis:
-
Prima o botão de came com letras e numerados.
O botão do came afasta-se do chassis.
-
Rode o trinco da árvore de cames para baixo até estar na posição horizontal.
O módulo NVRAM desengata-se do chassis e desloca-se para fora alguns centímetros.
-
Retire o módulo NVRAM do chassis puxando as patilhas de puxar nas laterais da face do módulo.
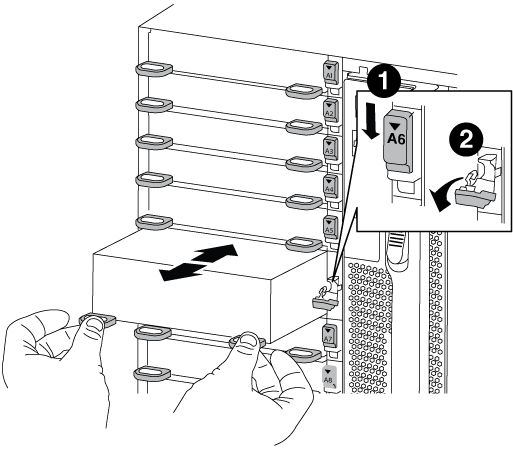
Trinco do came de e/S com letras e numerado
Trinco de e/S completamente desbloqueado
-
-
Coloque o módulo NVRAM numa superfície estável e retire a tampa do módulo NVRAM, premindo o botão azul de bloqueio na tampa e, em seguida, mantendo premido o botão azul, deslize a tampa para fora do módulo NVRAM.
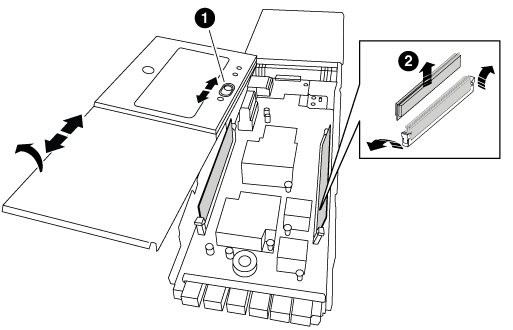
Botão de bloqueio da tampa
Guias de ejetor DIMM e DIMM
-
Remova os DIMMs, um de cada vez, do módulo NVRAM antigo e instale-os no módulo NVRAM de substituição.
-
Feche a tampa do módulo.
-
Instale o módulo NVRAM de substituição no chassis:
-
Alinhe o módulo com as extremidades da abertura do chassis na ranhura 6.
-
Deslize cuidadosamente o módulo para dentro da ranhura até que o trinco do came de e/S com letras e numerado comece a engatar com o pino do came de e/S e, em seguida, empurre o trinco do came de e/S totalmente para cima para bloquear o módulo no lugar.
-
Etapa 3: Substitua um DIMM NVRAM
Para substituir DIMMs NVRAM no módulo NVRAM, você deve remover o módulo NVRAM, abrir o módulo e, em seguida, substituir o DIMM de destino.
-
Se você ainda não está aterrado, aterre-se adequadamente.
-
Retire o módulo NVRAM alvo do chassis:
-
Prima o botão de came com letras e numerados.
O botão do came afasta-se do chassis.
-
Rode o trinco da árvore de cames para baixo até estar na posição horizontal.
O módulo NVRAM desengata-se do chassis e desloca-se para fora alguns centímetros.
-
Retire o módulo NVRAM do chassis puxando as patilhas de puxar nas laterais da face do módulo.
Trinco do came de e/S com letras e numerado
Trinco de e/S completamente desbloqueado
-
-
Coloque o módulo NVRAM numa superfície estável e retire a tampa do módulo NVRAM, premindo o botão azul de bloqueio na tampa e, em seguida, mantendo premido o botão azul, deslize a tampa para fora do módulo NVRAM.
Botão de bloqueio da tampa
Guias de ejetor DIMM e DIMM
-
Localize o DIMM a ser substituído dentro do módulo NVRAM e, em seguida, remova-o pressionando as abas de travamento do DIMM e levantando o DIMM para fora do soquete.
-
Instale o DIMM de substituição alinhando o DIMM com o soquete e empurrando cuidadosamente o DIMM para dentro do soquete até que as abas de travamento travem posição.
-
Feche a tampa do módulo.
-
Instale o módulo NVRAM de substituição no chassis:
-
Alinhe o módulo com as extremidades da abertura do chassis na ranhura 6.
-
Deslize cuidadosamente o módulo para dentro da ranhura até que o trinco do came de e/S com letras e numerado comece a engatar com o pino do came de e/S e, em seguida, empurre o trinco do came de e/S totalmente para cima para bloquear o módulo no lugar.
-
Passo 4: Reinicie o controlador após a substituição FRU
Depois de substituir a FRU, você deve reiniciar o módulo do controlador.
-
Para inicializar o ONTAP a partir do prompt Loader, digite
bye.
Etapa 5: Reatribuir discos
Dependendo se você tem um par de HA ou uma configuração de MetroCluster de dois nós, você deve verificar a reatribuição de discos para o novo módulo de controladora ou reatribuir manualmente os discos.
Selecione uma das opções a seguir para obter instruções sobre como reatribuir discos ao novo controlador.
Você deve confirmar a alteração do ID do sistema quando você inicializar o nó replacement e, em seguida, verificar se a alteração foi implementada.

|
A reatribuição de disco só é necessária quando substituir o módulo NVRAM e não se aplica à substituição do DIMM NVRAM. |
-
Se o nó de substituição estiver no modo Manutenção (mostrando o
*>prompt, saia do modo Manutenção e vá para o prompt Loader:halt -
A partir do prompt Loader no nó de substituição, inicialize o nó, inserindo
yse for solicitado a substituir o ID do sistema devido a uma incompatibilidade de ID do sistema.boot_ontap byeO nó será reiniciado, se o autoboot estiver definido.
-
Aguarde até que a
Waiting for giveback…mensagem seja exibida no console do nó replacement e, em seguida, a partir do nó de integridade, verifique se o novo ID do sistema do parceiro foi atribuído automaticamente:storage failover showNa saída do comando, você verá uma mensagem informando que a ID do sistema foi alterada no nó prejudicado, mostrando as IDs antigas e novas corretas. No exemplo a seguir, o node2 foi substituído e tem um novo ID de sistema de 151759706.
node1> `storage failover show` Takeover Node Partner Possible State Description ------------ ------------ -------- ------------------------------------- node1 node2 false System ID changed on partner (Old: 151759755, New: 151759706), In takeover node2 node1 - Waiting for giveback (HA mailboxes) -
A partir do nó saudável, verifique se todos os coredumps são salvos:
-
Mude para o nível de privilégio avançado:
set -privilege advancedVocê pode responder
Yquando solicitado a continuar no modo avançado. O prompt do modo avançado é exibido (*>). -
Salve quaisquer coredumps:
system node run -node local-node-name partner savecore -
Aguarde que o comando "avecore" seja concluído antes de emitir o giveback.
Você pode inserir o seguinte comando para monitorar o progresso do comando savecore:
system node run -node local-node-name partner savecore -s -
Voltar ao nível de privilégio de administrador:
set -privilege admin
-
-
Devolver o nó:
-
A partir do nó íntegro, devolva o armazenamento do nó substituído:
storage failover giveback -ofnode replacement_node_nameO nó replacement recupera seu armazenamento e completa a inicialização.
Se você for solicitado a substituir a ID do sistema devido a uma incompatibilidade de ID do sistema,
ydigite .
Se o giveback for vetado, você pode considerar substituir os vetos.
-
Após a conclusão do giveback, confirme que o par de HA está saudável e que a aquisição é possível:
storage failover showA saída do
storage failover showcomando não deve incluir aSystem ID changed on partnermensagem.
-
-
Verifique se os discos foram atribuídos corretamente:
storage disk show -ownershipOs discos pertencentes ao nó replacement devem mostrar o novo ID do sistema. No exemplo a seguir, os discos de propriedade de node1 agora mostram o novo ID do sistema, 1873775277:
node1> `storage disk show -ownership` Disk Aggregate Home Owner DR Home Home ID Owner ID DR Home ID Reserver Pool ----- ------ ----- ------ -------- ------- ------- ------- --------- --- 1.0.0 aggr0_1 node1 node1 - 1873775277 1873775277 - 1873775277 Pool0 1.0.1 aggr0_1 node1 node1 1873775277 1873775277 - 1873775277 Pool0 . . .
-
Se o sistema estiver em uma configuração MetroCluster, monitore o status do nó:
metrocluster node showA configuração do MetroCluster leva alguns minutos após a substituição para retornar a um estado normal, quando cada nó mostrará um estado configurado, com espelhamento de DR ativado e um modo normal. O
metrocluster node show -fields node-systemidcomando output exibe o ID do sistema antigo até que a configuração do MetroCluster retorne a um estado normal. -
Se o nó estiver em uma configuração do MetroCluster, dependendo do estado do MetroCluster, verifique se o campo ID inicial do DR mostra o proprietário original do disco se o proprietário original for um nó no local do desastre.
Isso é necessário se ambos os seguintes itens forem verdadeiros:
-
A configuração do MetroCluster está em um estado de switchover.
-
O nó replacement é o proprietário atual dos discos no local de desastre.
-
-
Se o sistema estiver em uma configuração do MetroCluster, verifique se cada nó está configurado:
metrocluster node show - fields configuration-statenode1_siteA::> metrocluster node show -fields configuration-state dr-group-id cluster node configuration-state ----------- ---------------------- -------------- ------------------- 1 node1_siteA node1mcc-001 configured 1 node1_siteA node1mcc-002 configured 1 node1_siteB node1mcc-003 configured 1 node1_siteB node1mcc-004 configured 4 entries were displayed.
-
Verifique se os volumes esperados estão presentes para cada nó:
vol show -node node-name -
Se você desativou o controle automático na reinicialização, ative-o a partir do nó de integridade:
storage failover modify -node replacement-node-name -onreboot true
Em uma configuração MetroCluster de dois nós executando o ONTAP, você deve reatribuir manualmente os discos à ID do sistema da nova controladora antes de retornar o sistema à condição operacional normal.
Este procedimento aplica-se apenas a sistemas em uma configuração de MetroCluster de dois nós executando o ONTAP.
Você deve ter certeza de emitir os comandos neste procedimento no nó correto:
-
O nó prejudicado é o nó no qual você está realizando a manutenção.
-
O nó replacement é o novo nó que substituiu o nó prejudicado como parte deste procedimento.
-
O nó Healthy é o parceiro de DR do nó prejudicado.
-
Se ainda não o tiver feito, reinicie o nó replacement, interrompa o processo de inicialização entrando `Ctrl-C`e selecione a opção para inicializar no modo Manutenção no menu exibido.
Você deve digitar
Yquando solicitado para substituir a ID do sistema devido a uma incompatibilidade de ID do sistema. -
Veja os IDs de sistema antigos a partir do nó saudável:
`metrocluster node show -fields node-systemid,dr-Partner-systemid'Neste exemplo, o Node_B_1 é o nó antigo, com o ID do sistema antigo de 118073209:
dr-group-id cluster node node-systemid dr-partner-systemid ----------- --------------------- -------------------- ------------- ------------------- 1 Cluster_A Node_A_1 536872914 118073209 1 Cluster_B Node_B_1 118073209 536872914 2 entries were displayed.
-
Veja a nova ID do sistema no prompt do modo de manutenção no nó prejudicado:
disk showNeste exemplo, o novo ID do sistema é 118065481:
Local System ID: 118065481 ... ... -
Reatribua a propriedade do disco (para sistemas FAS), usando as informações de ID do sistema obtidas do comando disk show:
disk reassign -s old system IDNo caso do exemplo anterior, o comando é:
disk reassign -s 118073209Você pode responder
Yquando solicitado a continuar. -
Verifique se os discos foram atribuídos corretamente:
disk show -aVerifique se os discos pertencentes ao nó replacement mostram o novo ID do sistema para o nó replacement. No exemplo a seguir, os discos pertencentes ao System-1 agora mostram a nova ID do sistema, 118065481:
*> disk show -a Local System ID: 118065481 DISK OWNER POOL SERIAL NUMBER HOME ------- ------------- ----- ------------- ------------- disk_name system-1 (118065481) Pool0 J8Y0TDZC system-1 (118065481) disk_name system-1 (118065481) Pool0 J8Y09DXC system-1 (118065481) . . .
-
A partir do nó saudável, verifique se todos os coredumps são salvos:
-
Mude para o nível de privilégio avançado:
set -privilege advancedVocê pode responder
Yquando solicitado a continuar no modo avançado. O prompt do modo avançado é exibido (*>). -
Verifique se os coredumps estão salvos:
system node run -node local-node-name partner savecoreSe o comando output indicar que o savecore está em andamento, aguarde que o savecore seja concluído antes de emitir o giveback. Você pode monitorar o progresso do savecore usando o
system node run -node local-node-name partner savecore -s command.</info>. -
Voltar ao nível de privilégio de administrador:
set -privilege admin
-
-
Se o nó replacement estiver no modo Manutenção (mostrando o prompt *>), saia do modo Manutenção e vá para o prompt Loader:
halt -
Inicialize o nó replacement:
boot_ontap -
Após o nó replacement ter sido totalmente inicializado, execute um switchback:
metrocluster switchback -
Verifique a configuração do MetroCluster:
metrocluster node show - fields configuration-statenode1_siteA::> metrocluster node show -fields configuration-state dr-group-id cluster node configuration-state ----------- ---------------------- -------------- ------------------- 1 node1_siteA node1mcc-001 configured 1 node1_siteA node1mcc-002 configured 1 node1_siteB node1mcc-003 configured 1 node1_siteB node1mcc-004 configured 4 entries were displayed.
-
Verifique a operação da configuração do MetroCluster no Data ONTAP:
-
Verifique se há alertas de integridade em ambos os clusters:
system health alert show -
Confirme se o MetroCluster está configurado e no modo normal:
metrocluster show -
Execute uma verificação MetroCluster:
metrocluster check run -
Apresentar os resultados da verificação MetroCluster:
metrocluster check show -
Execute o Config Advisor. Vá para a página Config Advisor no site de suporte da NetApp em "Support.NetApp.com/NOW/download/Tools/config_ADVISOR/".
Depois de executar o Config Advisor, revise a saída da ferramenta e siga as recomendações na saída para resolver quaisquer problemas descobertos.
-
-
Simular uma operação de comutação:
-
A partir do prompt de qualquer nó, altere para o nível de privilégio avançado:
set -privilege advancedVocê precisa responder com
yquando solicitado para continuar no modo avançado e ver o prompt do modo avançado (*>). -
Execute a operação de switchback com o parâmetro -simule:
metrocluster switchover -simulate -
Voltar ao nível de privilégio de administrador:
set -privilege admin
-
Passo 6: Devolva a peça com falha ao NetApp
Devolva a peça com falha ao NetApp, conforme descrito nas instruções de RMA fornecidas com o kit. Consulte a "Devolução de peças e substituições" página para obter mais informações.