

Desempenho
 Sugerir alterações
Sugerir alterações
NetApp AFX foi desenvolvido com foco em desempenho e escalabilidade, sendo especificamente voltado para cargas de trabalho que exigem alta taxa de transferência de leitura e gravação e que podem fornecer escalabilidade simples e linear.
Desempenho por nó
Cada nó de storage NetApp AFX fornece uma quantidade específica de throughput para leituras e gravações. À medida que nós são adicionados ao cluster, eles aumentam linearmente esse desempenho, conforme abordado na seção "Escalamento linear do desempenho do nó" deste documento.
Atualmente, os tipos de nós são "AFX 1K" e fornecem taxas de transferência para leitura e gravação aproximadamente nos valores abaixo. À medida que novos hardwares forem disponibilizados para NetApp AFX, esses limites poderão ser alterados. NOTA: O desempenho máximo foi alcançado utilizando vários clientes lendo e gravando vários arquivos, conforme mostrado na seção "Resultados do benchmark" abaixo.
Estimativas de desempenho por nó
| Tipo de nó | Desempenho máximo de leitura | Desempenho de gravação máximo |
|---|---|---|
AFX 1K |
~35GB/s |
~10GB/s |

|
Para obter as estimativas de desempenho mais recentes, consulte sua equipe de vendas NetApp. |
Desempenho por prateleira
Cada prateleira contém módulos de prateleira de alto desempenho com 16 portas Ethernet de 100 GB que utilizam a comunicação RoCEv2 para interação de storage de alta largura de banda com os nós de computação no cluster. Como qualquer recurso físico, essas prateleiras têm máximos que podem ser alcançados – principalmente porque NetApp AFX pode apresentar vários nós apontando para o mesmo conjunto de discos. A tabela a seguir mostra o desempenho máximo estimado de leitura e gravação para uma única prateleira para unidades TLC e QLC. Para obter mais informações sobre as diferenças entre TLC e QLC, consulte "TLC vs. QLC".
Estimativas de desempenho por prateleira
| Tipo de módulo de prateleira | Desempenho máximo de leitura | Desempenho de gravação máximo |
|---|---|---|
NSM 140 |
140GB/s (TLC e QLC) |
70GB/s TLC 35GB/s QLC |
|
|
Para obter as estimativas de desempenho mais recentes, consulte sua equipe de vendas NetApp. |
Densidade de performance
Desacoplar os nós de storage dos shelves na arquitetura ONTAP desagregada permite que mais nós direcionem o tráfego para menos shelves, o que ajuda a reduzir a área total do datacenter necessária para obter o máximo desempenho com apenas a capacidade de que você precisa.
Esse conceito de "densidade de desempenho" permite que os administradores de storage aproveitem ao máximo o hardware disponível, sem precisar superdimensionar o ambiente de storage.
Por exemplo, em um cluster ONTAP unificado, como cada nó possui seu próprio conjunto de discos, o desempenho é direcionado apenas aos discos pertencentes ao nó e, como apenas um nó pode acessar um conjunto de discos, ele não pode necessariamente saturar os discos disponíveis e atingir seu desempenho máximo.
Unified ONTAP – Como o desempenho é distribuído
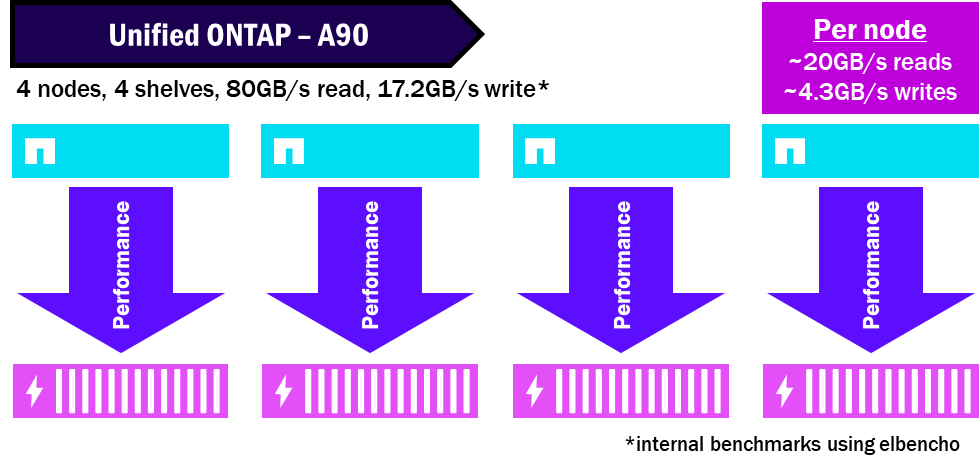
NetApp AFX agrupa todos os discos em uma única Storage Availability Zone, permitindo que todos os nós utilizem todos os discos. E como os discos e os nós são independentes, você não precisará de tantas shelves para obter o mesmo desempenho. Isso condensa o desempenho e maximiza o potencial máximo de desempenho da shelf.
NetApp AFX – densidade de desempenho
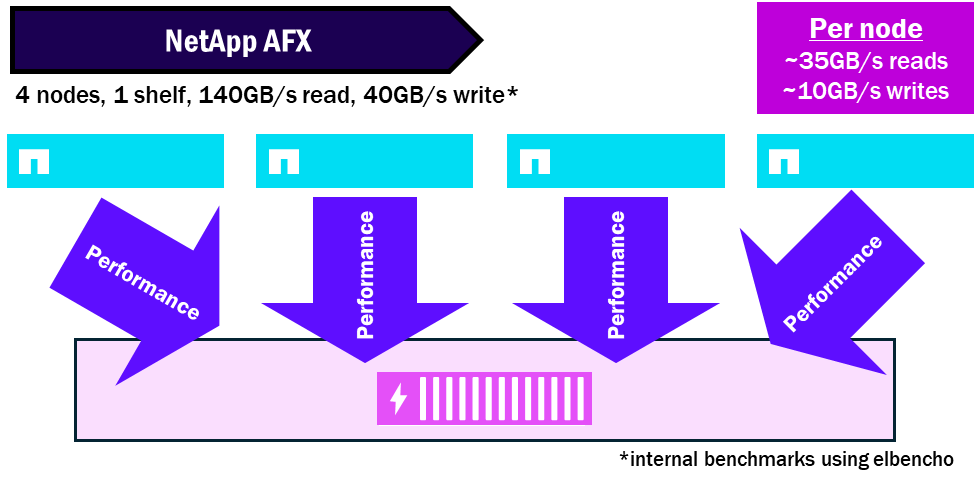
Relações nó-prateleira
Os nós Unified ONTAP exigem pelo menos um conjunto de discos por nó e podem ter várias gavetas conectadas a um único nó. Consequentemente, podem ocorrer gargalos de desempenho no nó individual, que pode não ser capaz de saturar seus próprios discos.
NetApp AFX apresenta todos os gabinetes de discos a todos os nós. Cada gabinete contém módulos com 16 x 100GB interfaces compatíveis com RoCE para aumentar a quantidade total de desempenho permitida por gabinete. Devido a isso, você pode saturar um único gabinete com vários nós que estarão lendo e gravando no mesmo conjunto de discos.
A partir do ONTAP 9.19.1, a proporção de saturação nó:prateleira é de aproximadamente 4:1.
Resultados de benchmark
A seção a seguir aborda os resultados de benchmark usando um cluster AFX NetApp com os seguintes parâmetros de configuração.
-
4 nós, 4 interfaces de dados
-
2 prateleiras (discos de 7,6TB)
-
ONTAP 9.19.1
-
NFSv4.2 (pNFS, trunking de sessão)
-
Volume FlexGroup
-
"ElBencho" benchmark
-
Gravações: elbencho --hosts=x.x.x.[y-z] -d -w -b 1M -t 80 --iodepth 1 --direct -s 600g /fio_vol1/
-
Leituras: elbencho --hosts=x.x.x.[y-z] -r -b 256k -t 80 --lat --iodepth 2 --direct -s 600g --infloop /fio_vol1/
-
4 servidores Cisco C240 M8, 2 portas * placas CX-7 de 200GbE, 80 threads
-
Opções de montagem NFS: rw,vers=4.2,rsize=1048576,wsize=1048576,trunkdiscovery,proto=tcp
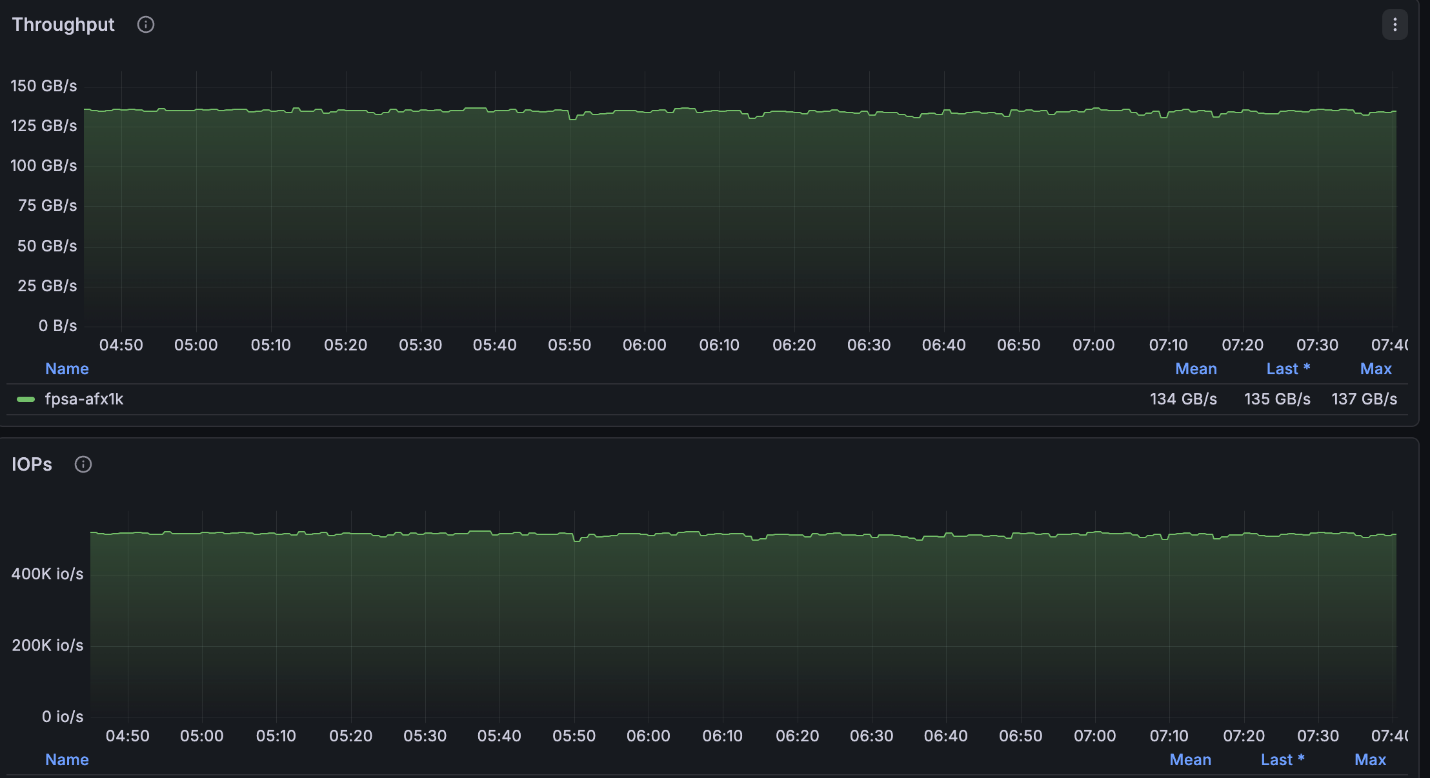
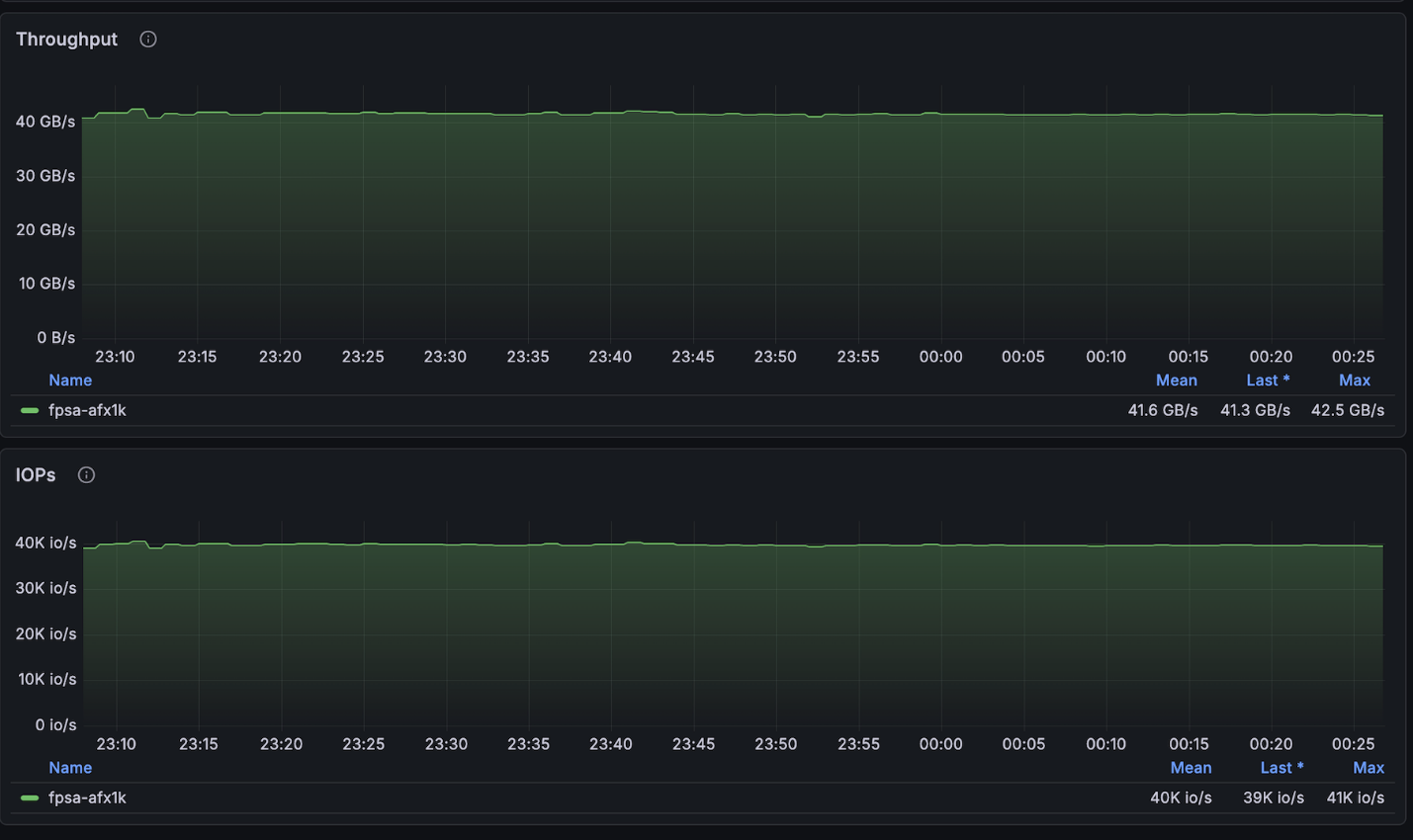
A configuração acima atingiu um valor muito próximo do máximo de leituras disponível para o cluster de 4 nós (~134GB/s) e ficou exatamente no limite máximo de gravações permitidas por nó (40GB/s).
NetApp AFX – ElBencho desempenho de leitura, 4 nós
NetApp AFX – ElBencho desempenho de gravação, 4 nós
Leitura antecipada agressiva
Em fluxos de trabalho de streaming de mídia, um filme 4K é frequentemente dividido em dezenas de milhares de arquivos, cada um com tamanho típico entre 50 MB e 250 MB. Cada arquivo representa um quadro, e o aplicativo lê um quadro inteiro em uma única solicitação. Para manter um fluxo contínuo e sem interrupções, sem buffering visível, essas leituras de quadros devem ser concluídas sem perdas.
ONTAP oferece uma opção em nível de volume (-aggressive-readahead-mode para otimizar essas cargas de trabalho. A partir do ONTAP 9.19.1, um novo cross_file_sequential_read modo para leitura antecipada agressiva foi introduzido no AFX para acelerar cargas de trabalho com padrões de E/S previsíveis em tipos de arquivo semelhantes (por exemplo, renderização e streaming de mídia).
A função cross_file_sequential_read prevê o próximo arquivo a ser lido com base em seu nome e inicia a leitura antecipada desses arquivos antes que o cliente emita a chamada de leitura. A lógica de previsão pressupõe que todos os arquivos em um diretório seguem um padrão de nomenclatura com um sufixo numérico crescente (por exemplo, arquivo1, arquivo2, arquivo3). Todos os arquivos no diretório devem seguir esse padrão, usando numeração decimal ou hexadecimal. Os nomes de arquivo podem ter até 255 caracteres. A lógica é independente da extensão e gera o próximo conjunto de nomes de arquivo no diretório atual com base apenas no nome do arquivo atual. Se um nome de arquivo gerado anteriormente usando numeração em base 10 não existir no diretório, os nomes são regenerados usando numeração hexadecimal. Se nenhum dos nomes de arquivo gerados existir, nenhuma pré-busca é emitida para esse conjunto. A pré-busca é retomada quando a próxima leitura do cliente é emitida.
Com essas opções ativadas, "teste de quadro" benchmarks de desempenho conseguiram ler 30.000 quadros 4K a 30 quadros por segundo com 30 clientes (NFSv3 e SMB3) e 34 clientes (NFSv4.1), sem nenhuma perda de quadro.
Embora a leitura sequencial entre arquivos seja projetada principalmente para cargas de trabalho de mídia, outras cargas de trabalho com grande volume de leitura e padrões de acesso e nomes de arquivos previsíveis - como treinamento e inferência de IA - também podem se beneficiar.
Considerações e ressalvas
-
Cache de buffer compartilhado – A leitura antecipada agressiva usa o mesmo buffer cache que outros volumes no nó. Habilitá-lo pode afetar o desempenho de leitura de outros volumes nesse nó.
-
Desempenho do armazenamento subjacente – Se os arquivos não puderem ser lidos com rapidez suficiente (por exemplo, em sistemas FAS baseados em HDD), os dados em cache podem ser removidos antes que a leitura do cliente ocorra, anulando os benefícios da leitura antecipada.
-
Requisitos de padrão de acesso – Se o padrão de leitura da carga de trabalho não for sequencial, ou se os arquivos em um diretório não estiverem nomeados em ordem sequencial crescente, o modo de leitura antecipada agressiva cross_file_sequential_read não proporcionará benefícios significativos.
Melhorias de desempenho do NFSv4.x
A versão de NFS 3 tem sido um padrão de excelência para aplicações NFS por décadas – desde 1995, quando foi oficialmente lançada. Sua combinação de desempenho e resiliência tornou difícil considerar a migração para versões mais recentes de NFS, e com razão.
No entanto, o NFSv3 não está isento de limitações. A ausência de estado no protocolo, embora excelente para o desempenho e para minimizar interrupções em caso de failover de storage, não é tão boa para consistência de dados e gerenciamento de bloqueios. Um servidor NFS não mantém um registro dos estados de bloqueio, então, se ocorrer uma falha, o servidor NFS pode ou não liberar os bloqueios, e o cliente NFS pode não saber se um arquivo está bloqueado ou não.
Security for NFSv3 is also a bit lacking. The protocol requires multiple open firewall ports to function properly and numeric IDs are sent in plaintext over the wire. Furthermore, NFS does not have robust ACL support, and does not include native file and folder auditing. As a result of these limitations, NFSv4 was created in 2003 via link:https://datatracker.ietf.org/doc/html/rfc3530[RFC-3530^] (obsoleted in 2015 by link:https://datatracker.ietf.org/doc/html/rfc7530[RFC-7530^]). Embora o NFSv4.x exista há mais de 20 anos, ainda não houve ampla adoção por alguns motivos.
-
Complexidade do gerenciamento de identidades: muitos ambientes não possuem uma infraestrutura de serviço de nomes implementada para aproveitar adequadamente os requisitos de string de nome e de segurança Kerberos no NFSv4.x.
-
Necessidade de clientes NFS mais recentes: essa preocupação é menos urgente nos ambientes NFS modernos de hoje, à medida que nos distanciamos da data de lançamento inicial do NFSv4. Quase todos os sistemas operacionais atualmente em uso incluem clientes NFS com suporte completo ao NFSv4, mas ainda existem sistemas legados que podem não ter os pacotes NFSv4.x necessários. De fato, alguns aplicativos ainda exigem o uso de versões mais antigas do NFS.
-
Mentalidade de "em time que está ganhando não se mexe": as organizações de TI corporativas são notoriamente conservadoras na adoção de novas tecnologias – mesmo aquelas que existem há mais de 20 anos. E se a versão de NFS está funcionando bem, por que mudar?
-
Preocupações com o desempenho: o desempenho de um protocolo com estado como o NFSv4.x ficou atrás do NFSv3 sem estado durante grande parte dos últimos 20 anos. No passado, o impacto no desempenho muitas vezes superava os benefícios do NFSv4.x.
Melhorias no NFSv4.x no ONTAP 9.18.1 usando AFX
Algumas mudanças arquitetônicas no ONTAP proporcionaram um aumento de desempenho muito necessário ao NFS em geral e contribuíram significativamente para a melhoria do desempenho do NFSv4.x de forma geral.
A seguir está um resumo de alto nível de algumas dessas mudanças.
Aprimoramento de leitura sequencial: NFSv4.1 30% melhor que NFSv3
ONTAP 9.18.1 introduz suporte para multipath IO com NFSv4.1. Em vez de processar leituras do sistema de arquivos WAFL, o MPIO transfere as operações de leitura para um domínio de rede para serem atendidas de maneira segura para multipath. Essa abordagem reduz as trocas de contexto, proporcionando maior paralelismo geral no tráfego de leitura sequencial, além de reduzir a sobrecarga do gerenciamento de buffers ao ignorar WAFL.
Aprimoramento de leitura aleatória para FlexGroup volumes: NFSv4.1 dentro de 7% do NFSv3
FlexGroup volumes são volumes que combinam vários volumes constituintes subjacentes e os apresentam como um único namespace unificado. No AFX, volumes FlexGroup têm o Balanceamento Avançado de Capacidade habilitado por padrão, o que grava arquivos maiores que 10GB em vários volumes constituintes como arquivos multipartes. Devido à localização remota dessas partes de arquivo, as leituras aleatórias tradicionalmente apresentavam uma pequena desvantagem de desempenho com NFSv4.x (cerca de 18% a menos que NFSv3). ONTAP 9.18.1 introduz suporte para IO em cache para leituras multipartes com NFSv4.x para ajudar a resolver isso. NOTA: Esta alteração não se aplica a volumes FlexVol.
Gravações sequenciais: melhoria de +10% em relação às versões anteriores
Uma melhoria na forma como replicamos os dados NVLOG usados para a funcionalidade de failover de alta disponibilidade aumentou o desempenho geral de gravação sequencial para NetApp AFX systems.
Operações de metadados: desempenho dentro de 15% do NFSv3 para benchmarks de EDA
O NFSv4.1 tradicionalmente serializa todas as operações de OPEN e CLOSE, com um nó de cluster processando-as uma de cada vez antes que possam ser enviadas da rede para WAFL. ONTAP 9.18.1 introduz Concurrent Open Close (COC), que elimina a serialização de rede ao alterar a forma como as condições de corrida são resolvidas, removendo assim os gargalos de OPEN/CLOSE observados em versões anteriores.
Todas essas mudanças – juntamente com as alterações de arquitetura introduzidas no AFX – possibilitaram a melhoria do desempenho geral do NFSv4.1 no ONTAP 9.18.1.
Resultados de IO sequencial
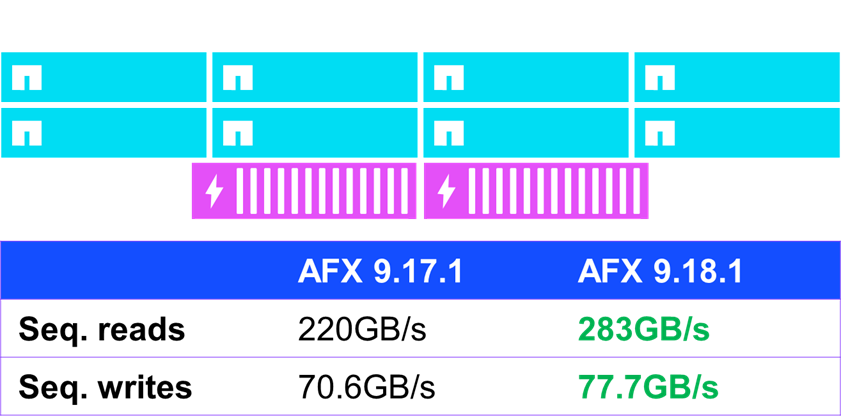
Uma das áreas em que foram observadas melhorias modestas de desempenho foi na E/S sequencial (ou seja, E/S previsível e emitida consecutivamente). Em testes de desempenho padrão usando fio, o AFX executando ONTAP 9.18.1 apresentou uma melhoria de quase 30% no desempenho de leitura sequencial e de 10% no desempenho de gravação sequencial.
NetApp AFX – desempenho de E/S sequencial NFSv4.1 no ONTAP 9.18.1
Resultados de carga de trabalho com grande volume de metadados
Ainda mais impressionantes são as melhorias em um dos principais pontos fracos de desempenho do NFSv4.x – metadados. Trata-se de operações de IO aleatórias, geralmente na faixa de 4K, usadas para gerenciar proprietários e atributos de arquivos, criar e listar arquivos, e assim por diante. Devido à natureza stateful do NFSv4.x, esses tipos de operações tendem a consumir mais CPU e latência, o que, por sua vez, reduz o desempenho geral possível.
Com as alterações no AFX ONTAP 9.18.1, o desempenho do NFSv4.x para esses tipos de cargas de trabalho melhorou substancialmente e reduziu a diferença em relação ao desempenho do NFSv3 (em até 15%).
Nossas equipes de engenharia de desempenho compararam o desempenho de benchmarks padrão de IA para imagens, EDA e compilação de software e constataram ganhos significativos em relação à versão anterior do ONTAP.
NetApp AFX – desempenho de E/S de metadados NFSv4.1 no ONTAP 9.18.1
