

Design verification
 Suggest changes
Suggest changes
The second-generation design for the BeeGFS on NetApp solution was verified using three building block configuration profiles.
The configuration profiles include the following:
-
A single base building block, including BeeGFS management, metadata, and storage services.
-
A BeeGFS metadata plus a storage building block.
-
A BeeGFS storage-only building block.
The building blocks were attached to two NVIDIA Quantum InfiniBand (MQM8700) switches. Ten BeeGFS clients were also attached to the InfiniBand switches and used to run synthetic benchmark utilities.
The following figure shows the BeeGFS configuration used to validate the BeeGFS on NetApp solution.

BeeGFS file striping
A benefit of parallel file systems is the ability to stripe individual files across multiple storage targets, which could represent volumes on the same or different underlying storage systems.
In BeeGFS, you can configure striping on a per-directory and per-file basis to control the number of targets used for each file and to control the chunksize (or block size) used for each file stripe. This configuration allows the file system to support different types of workloads and I/O profiles without the need for reconfiguring or restarting services. You can apply stripe settings using the beegfs-ctl command line tool or with applications that use the striping API. For more information, see the BeeGFS documentation for Striping and Striping API.
To achieve the best performance, stripe patterns were adjusted throughout testing, and the parameters used for each test are noted.
IOR bandwidth tests: Multiple clients
The IOR bandwidth tests used OpenMPI to run parallel jobs of the synthetic I/O generator tool IOR (available from HPC GitHub) across all 10 client nodes to one or more BeeGFS building blocks. Unless otherwise noted:
-
All tests used direct I/O with a 1MiB transfer size.
-
BeeGFS file striping was set to a 1MB chunksize and one target per file.
The following parameters were used for IOR with the segment count adjusted to keep the aggregate file size to 5TiB for one building block and 40TiB for three building blocks.
mpirun --allow-run-as-root --mca btl tcp -np 48 -map-by node -hostfile 10xnodes ior -b 1024k --posix.odirect -e -t 1024k -s 54613 -z -C -F -E -k
The following figure shows the IOR test results with a single BeeGFS base (management, metadata, and storage) building block.
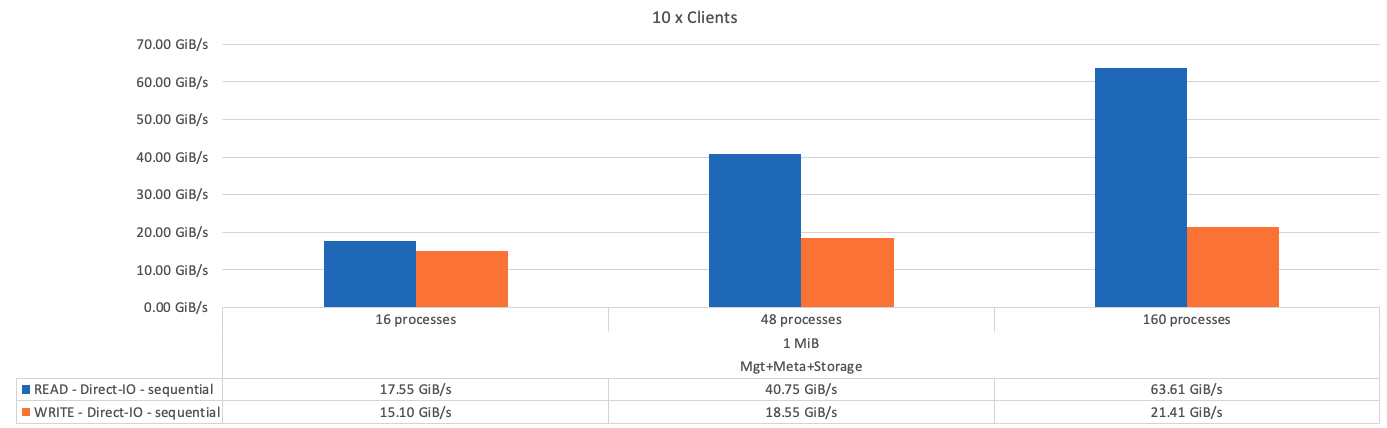
The following figure shows the IOR test results with a single BeeGFS metadata + storage building block.
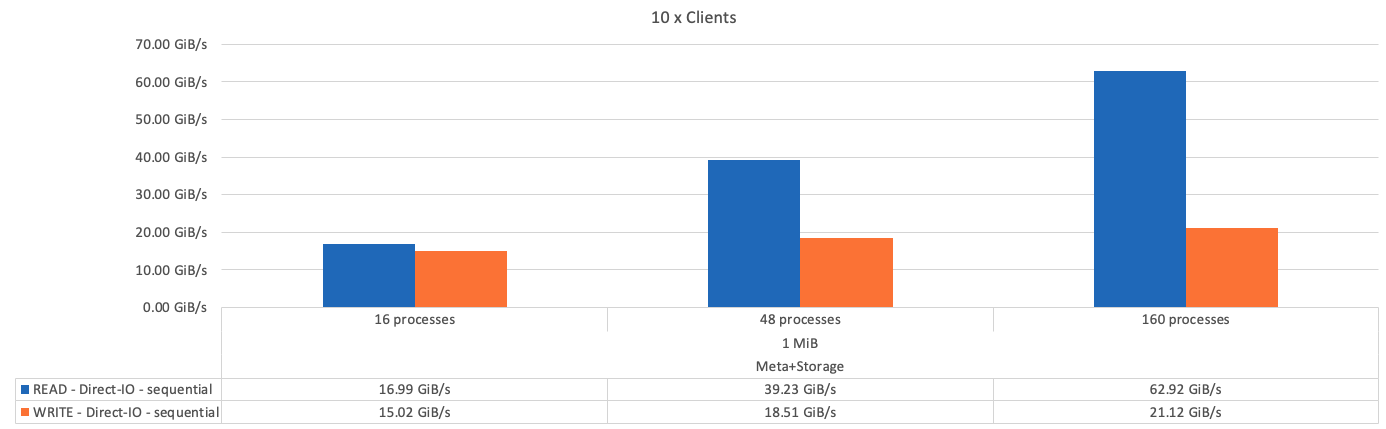
The following figure shows the IOR test results with a single BeeGFS storage-only building block.
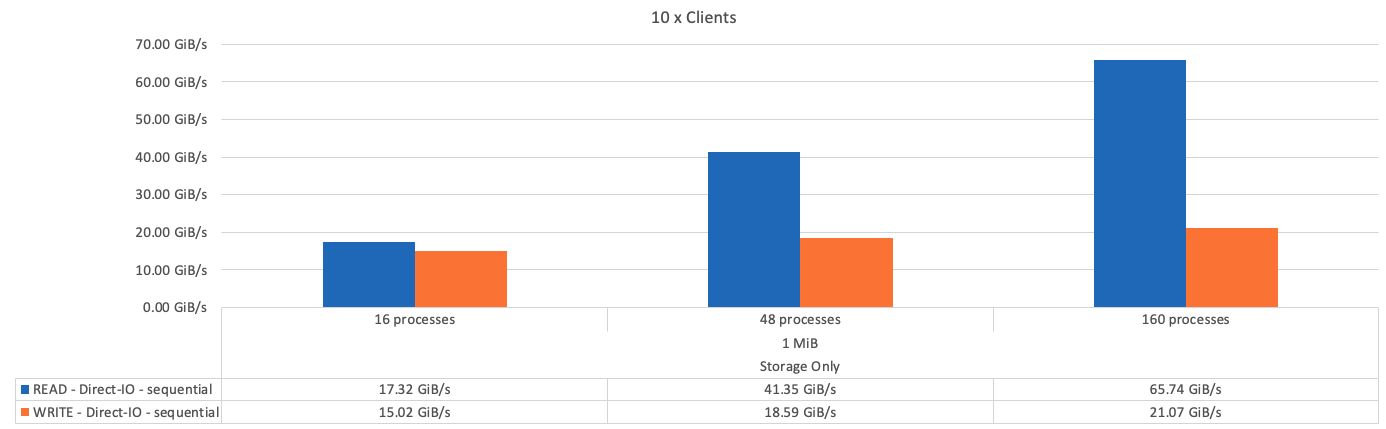
The following figure shows the IOR test results with three BeeGFS building blocks.
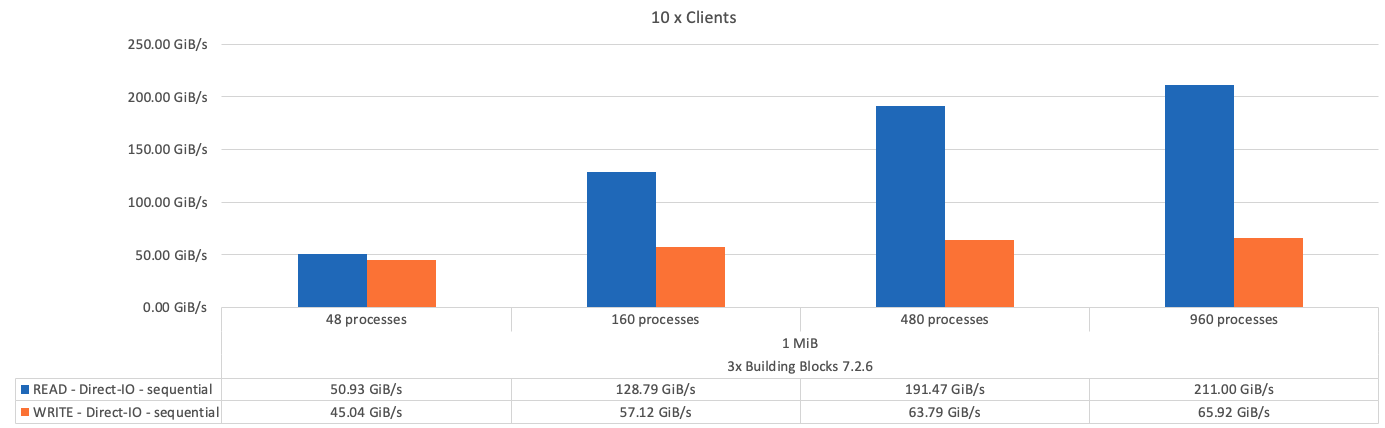
As expected, the performance difference between the base building block and the subsequent metadata + storage building block is negligible. Comparing the metadata + storage building block and a storage-only building block shows a slight increase in read performance due to the additional drives used as storage targets. However, there is no significant difference in write performance. To achieve higher performance, you can add multiple building blocks together to scale performance in a linear fashion.
IOR bandwidth tests: Single client
The IOR bandwidth test used OpenMPI to run multiple IOR processes using a single high-performance GPU server to explore the performance achievable to a single client.
This test also compares the reread behavior and performance of BeeGFS when the client is configured to use the Linux kernel page-cache (tuneFileCacheType = native) versus the default buffered setting.
The native caching mode uses the Linux kernel page-cache on the client, allowing reread operations to come from local memory instead of being retransmitted over the network.
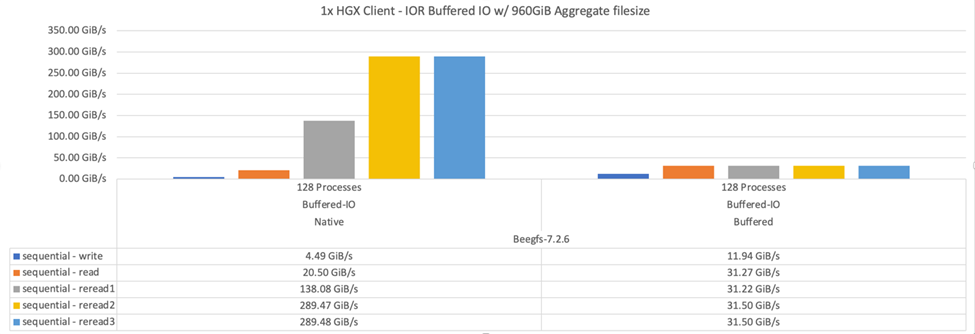
The following diagram shows the IOR test results with three BeeGFS building blocks and a single client.

|
BeeGFS striping for these tests was set to a 1MB chunksize with eight targets per file. |
Although write and initial read performance is higher using the default buffered mode, for workloads that reread the same data multiple times, a significant performance boost is seen with the native caching mode. This improved reread performance is important for workloads like deep learning that reread the same dataset multiple times across many epochs.
Metadata performance test
The Metadata performance tests used the MDTest tool (included as part of IOR) to measure the metadata performance of BeeGFS. The tests utilized OpenMPI to run parallel jobs across all ten client nodes.
The following parameters were used to run the benchmark test with the total number of processes scaled from 10 to 320 in step of 2x and with a file size of 4k.
mpirun -h 10xnodes –map-by node np $processes mdtest -e 4k -w 4k -i 3 -I 16 -z 3 -b 8 -u
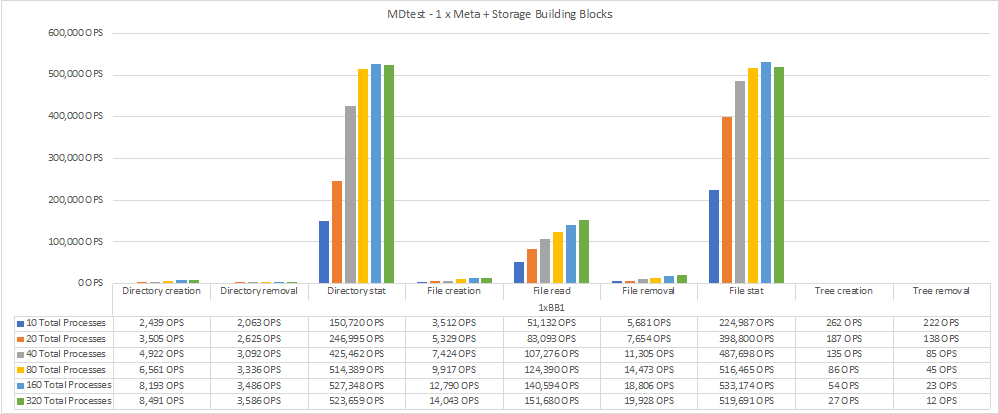
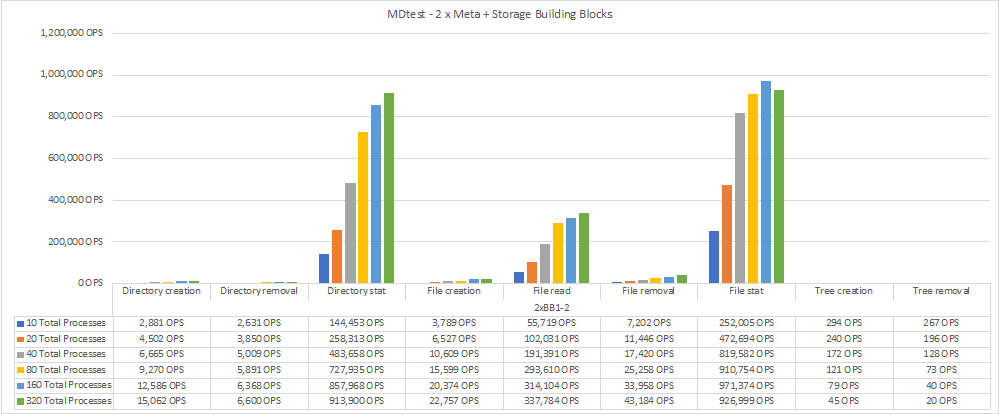
Metadata performance was measured first with one then two metadata + storage building blocks to show how performance scales by adding additional building blocks.
The following diagram shows the MDTest results with one BeeGFS metadata + storage building blocks.
The following diagram shows the MDTest results with two BeeGFS metadata + storage building blocks.
Functional validation
As part of validating this architecture, NetApp executed several functional tests including the following:
-
Failing a single client InfiniBand port by disabling the switch port.
-
Failing a single server InfiniBand port by disabling the switch port.
-
Triggering an immediate server power off using the BMC.
-
Gracefully placing a node in standby and failing over service to another node.
-
Gracefully placing a node back online and failing back services to the original node.
-
Powering off one of the InfiniBand switches using the PDU. All tests were performed while stress testing was in progress with the
sysSessionChecksEnabled: falseparameter set on the BeeGFS clients. No errors or disruption to I/O was observed.
|
|
There is a known issue (see the Changelog) when BeeGFS client/server RDMA connections are disrupted unexpectedly, either through loss of the primary interface (as defined in connInterfacesFile) or a BeeGFS server failing; active client I/O can hang for up to ten minutes before resuming. This issue does not occur when BeeGFS nodes are gracefully placed in and out of standby for planned maintenance or if TCP is in use.
|
NVIDIA DGX SuperPOD and BasePOD validation
NetApp validated a storage solution for NVIDIAs DGX A100 SuperPOD using a similar BeeGFS file system consisting of three building blocks with the metadata plus storage configuration profile applied. The qualification effort involved testing the solution described by this NVA with twenty DGX A100 GPU servers running a variety of storage, machine learning, and deep learning benchmarks. Building on the validation established with NVIDIA’s DGX A100 SuperPOD, the BeeGFS on NetApp solution has been approved for DGX SuperPOD H100, H200, and B200 systems. This extension is based on meeting the previously established benchmarks and system requirements as validated with the NVIDIA DGX A100.
For more information, see NVIDIA DGX SuperPOD with NetApp and NVIDIA DGX BasePOD.