

Tiering data from on-premises ONTAP clusters to StorageGRID in NetApp Cloud Tiering
 Suggest changes
Suggest changes
Free space on your on-premises ONTAP clusters by tiering inactive data to StorageGRID in NetApp Cloud Tiering.
Quick start
Get started quickly by following these steps, or scroll down to the remaining sections for full details.
 Prepare to tier data to StorageGRID
Prepare to tier data to StorageGRIDYou need the following:
-
A source on-premises ONTAP cluster that's running ONTAP 9.4 or later that you have added to the NetApp Console, and a connection over a user-specified port to StorageGRID. Learn how to discover a cluster.
-
StorageGRID 10.3 or later with AWS access keys that have S3 permissions.
-
A Console agent installed on your premises.
-
Networking for the agent that enables an outbound HTTPS connection to the ONTAP cluster, to StorageGRID, and to the Cloud Tiering service.
 Set up tiering
Set up tieringIn the NetApp Console, select an on-premises system, select Enable for Cloud Tiering, and follow the prompts to tier data to StorageGRID.
Requirements
Verify support for your ONTAP cluster, set up your networking, and prepare your object storage.
The following image shows each component and the connections that you need to prepare between them:
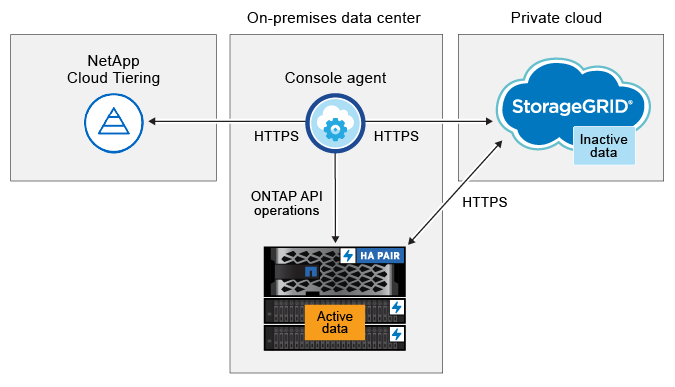

|
Communication between the agent and StorageGRID is for object storage setup only. |
Prepare your ONTAP clusters
Your ONTAP clusters must meet the following requirements when tiering data to StorageGRID.
- Supported ONTAP platforms
-
-
When using ONTAP 9.8 and later: You can tier data from AFF systems, or FAS systems with all-SSD aggregates or all-HDD aggregates.
-
When using ONTAP 9.7 and earlier: You can tier data from AFF systems, or FAS systems with all-SSD aggregates.
-
- Supported ONTAP version
-
ONTAP 9.4 or later
- Licensing
-
A Cloud Tiering license isn't required in your NetApp Console organization, nor is a FabricPool license required on the ONTAP cluster, when tiering data to StorageGRID.
- Cluster networking requirements
-
-
The ONTAP cluster initiates an HTTPS connection over a user-specified port to the StorageGRID Gateway Node (the port is configurable during tiering setup).
ONTAP reads and writes data to and from object storage. The object storage never initiates, it just responds.
-
An inbound connection is required from the agent, which must reside on your premises.
A connection between the cluster and the Cloud Tiering service is not required.
-
An intercluster LIF is required on each ONTAP node that hosts the volumes you want to tier. The LIF must be associated with the IPspace that ONTAP should use to connect to object storage.
-
- Supported volumes and aggregates
-
The total number of volumes that Cloud Tiering can tier might be less than the number of volumes on your ONTAP system. That's because volumes can't be tiered from some aggregates. Refer to the ONTAP documentation for functionality or features not supported by FabricPool.
|
|
Cloud Tiering supports FlexGroup volumes, starting with ONTAP 9.5. Setup works the same as any other volume. |
Discover an ONTAP cluster
You need to add an on-premises ONTAP system to the NetApp Console before you can start tiering cold data.
Prepare StorageGRID
StorageGRID must meet the following requirements.
- Supported StorageGRID versions
-
StorageGRID 10.3 and later is supported.
- S3 credentials
-
When you set up tiering to StorageGRID, you need to provide Cloud Tiering with an S3 access key and secret key. Cloud Tiering uses the keys to access your buckets.
These access keys must be associated with a user who has the following permissions:
"s3:ListAllMyBuckets", "s3:ListBucket", "s3:GetObject", "s3:PutObject", "s3:DeleteObject", "s3:CreateBucket" - Object versioning
-
You must not enable StorageGRID object versioning on the object store bucket.
Create or switch Console agents
The Console agent is required to tier data to the cloud. When tiering data to StorageGRID, an agent must be available on your premises.
You must have the Organization admin role to create an agent.
Prepare networking for the Console agent
Ensure that the agent has the required networking connections.
-
Ensure that the network where the agent is installed enables the following connections:
-
An HTTPS connection over port 443 to the Cloud Tiering service (see the list of endpoints)
-
An HTTPS connection over port 443 to your StorageGRID system
-
An HTTPS connection over port 443 to your ONTAP cluster management LIF
-
Tier inactive data from your first cluster to StorageGRID
After you prepare your environment, start tiering inactive data from your first cluster.
-
The FQDN of the StorageGRID Gateway Node, and the port that will be used for HTTPS communications.
-
An AWS access key that has the required S3 permissions.
-
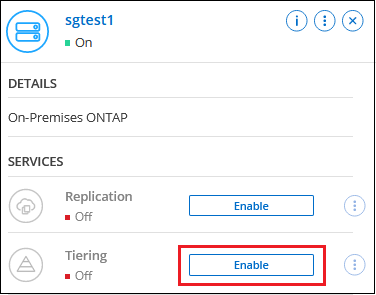
Select the on-premises ONTAP system.
-
Click Enable for Cloud Tiering from the right panel.
If the StorageGRID tiering destination exists as a system in the NetApp Console you can drag the cluster onto the StorageGRID system to initiate the setup wizard.
-
Define Object Storage Name: Enter a name for this object storage. It must be unique from any other object storage you may be using with aggregates on this cluster.
-
Select Provider: Select StorageGRID and select Continue.
-
Complete the steps on the Create Object Storage pages:
-
Server: Enter the FQDN of the StorageGRID Gateway Node, the port that ONTAP should use for HTTPS communication with StorageGRID, and the access key and secret key for an account that has the required S3 permissions.
-
Bucket: Add a new bucket or select an existing bucket that starts with the prefix fabric-pool and select Continue.
The fabric-pool prefix is required because the IAM policy for the agent enables the instance to perform S3 actions on buckets named with that exact prefix. For example, you could name the S3 bucket fabric-pool-AFF1, where AFF1 is the name of the cluster.
-
Cluster Network: Select the IPspace that ONTAP should use to connect to object storage and select Continue.
Selecting the correct IPspace ensures that Cloud Tiering can set up a connection from ONTAP to StorageGRID object storage.
You can also set the network bandwidth available to upload inactive data to object storage by defining the "Maximum transfer rate". Select the Limited radio button and enter the maximum bandwidth that can be used, or select Unlimited to indicate that there is no limit.
-
-
On the Tier Volumes page, select the volumes that you want to configure tiering for and launch the Tiering Policy page:
-
To select all volumes, check the box in the title row (
 ) and select Configure volumes.
) and select Configure volumes. -
To select multiple volumes, check the box for each volume (
 ) and select Configure volumes.
) and select Configure volumes. -
To select a single volume, select the row (or
 icon) for the volume.
icon) for the volume.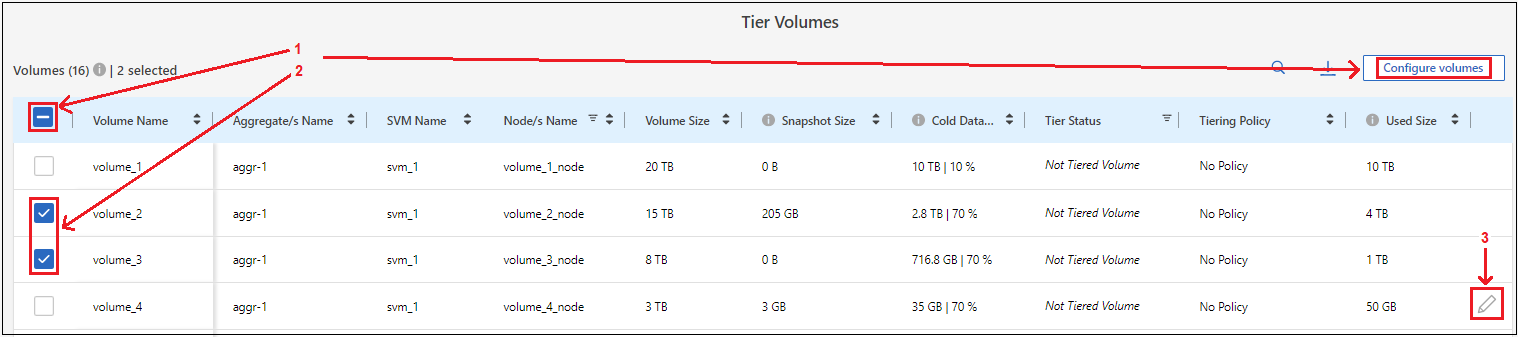
-
-
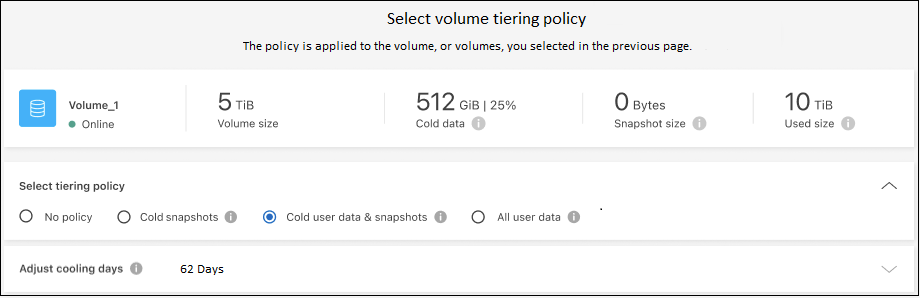
In the Tiering Policy dialog, select a tiering policy, optionally adjust the cooling days for the selected volumes, and select Apply.
You can review information about the active and inactive data on the cluster. Learn more about managing your tiering settings.
You can also create additional object storage in cases where you may want to tier data from certain aggregates on a cluster to different object stores. Or if you plan to use FabricPool Mirroring where your tiered data is replicated to an additional object store. Learn more about managing object stores.