
Intelligent tiering and cost savings
 Suggest changes
Suggest changes
As customers realize the power and ease of using Splunk data analytics, they naturally want to index an ever-growing amount of data. As the amount of data grows, so does the compute and storage infrastructure required to service it. Since older data is referenced less frequently, committing the same amount of compute resources and consuming expensive primary storage becomes increasingly inefficient. To operate at scale, customers benefit from moving warm data to a more cost-effective tier, freeing compute and primary storage for hot data.
Splunk SmartStore with StorageGRID offers organizations a scalable, performant, and cost-effective solution. Because SmartStore is data-aware, it automatically evaluates data-access patterns to determine which data needs to be accessible for real-time analytics (hot data) and which data should reside in lower-cost long-term storage (warm data). SmartStore uses the industry-standard AWS S3 API dynamically and intelligently, placing data in S3 storage provided by StorageGRID. The flexible scale-out architecture of StorageGRID allows the warm data tier to grow cost effectively as needed. The node-based architecture of StorageGRID makes sure that performance and cost requirements are met optimally.
The following image illustrates the Splunk and StorageGRID tiering.
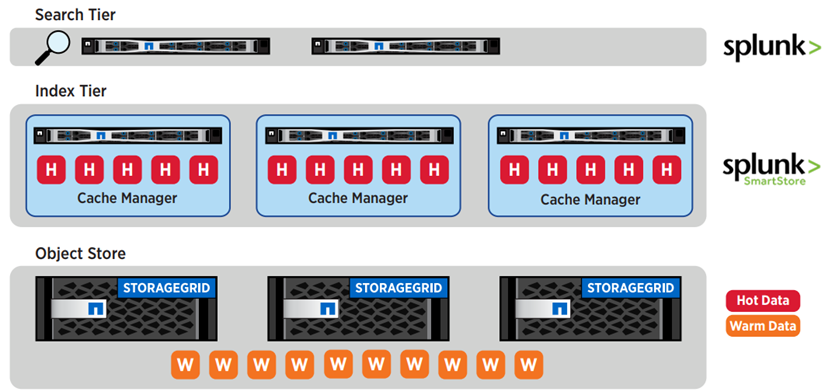
The industry-leading combination of Splunk SmartStore with NetApp StorageGRID delivers the benefits of decoupled architecture through a full-stack solution.