

Oracle Single-Instance
 Suggest changes
Suggest changes
The examples explained below show some of the many options for to deploying Oracle Single Instance databases with SnapMirror active sync replication.
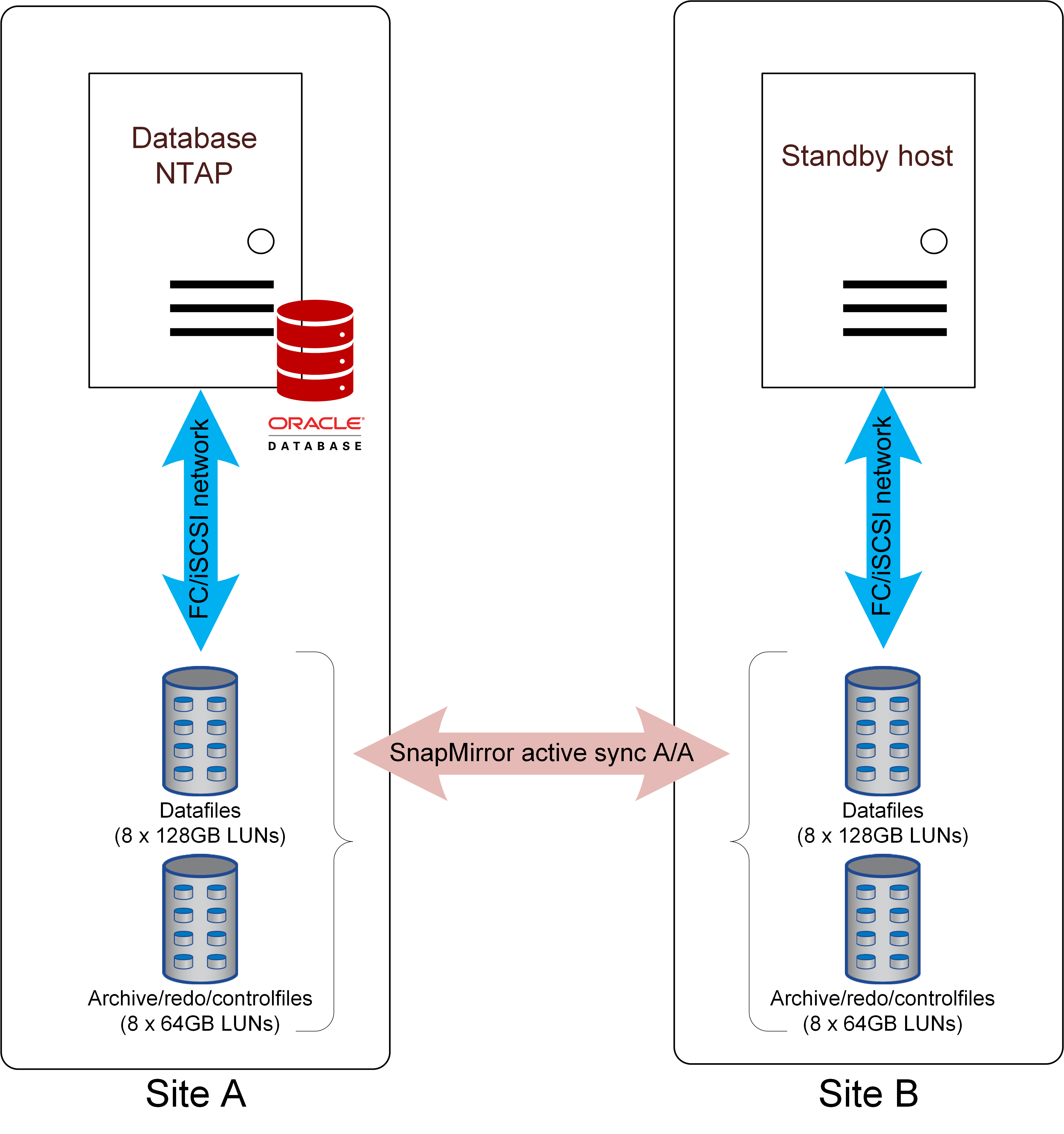
Failover with a preconfigured OS
SnapMirror active sync delivers a synchronous copy of the data at the disaster recovery site, but making that data available requires an operating system and the associated applications. Basic automation can dramatically improve the failover time of the overall environment. Clusterware products such as Pacemaker are often used to create a cluster across the sites, and in many cases the failover process can be driven with simple scripts.
If the primary nodes are lost, the clusterware (or scripts) will bring the databases online at the alternate site. One option is to create standby servers that are preconfigured for the SAN resources that make up the database. If the primary site fails, the clusterware or scripted alternative performs a sequence of actions similar to the following:
-
Detect failure of primary site
-
Perform discovery of FC or iSCSI LUNs
-
Mounting file systems and/or mounting ASM disk groups
-
Starting the database
The primary requirement of this approach is a running OS in place on the remote site. It must be preconfigured with Oracle binaries, which also means that tasks such as Oracle patching must be performed on the primary and standby site. Alternatively, the Oracle binaries can be mirrored to the remote site and mounted if a disaster is declared.
The actual activation procedure is simple. Commands such as LUN discovery require just a few commands per FC port. File system mounting is nothing more than a mount command, and both databases and ASM can be started and stopped at the CLI with a single command.
Failover with a virtualized OS
Failover of database environments can be extended to include the operating system itself. In theory, this failover can be done with boot LUNs, but most often it is done with a virtualized OS. The procedure is similar to the following steps:
-
Detect failure of primary site
-
Mounting the datastores hosting the database server virtual machines
-
Starting the virtual machines
-
Starting databases manually or configuring the virtual machines to automatically start the databases.
For example, an ESX cluster could span sites. In the event of disaster, the virtual machines can be brought online at the disaster recovery site after the switchover.
Storage failure protection
The diagram above shows the use of nonuniform access, where the SAN is not stretched across sites. This may be simpler to configure, and in some cases may be the only option given the current SAN capabilities, but it also means that failure of the primary storage system would cause a database outage until the application was failed over.
For additional resilience, the solution could be deployed with uniform access. This would allow the applications to continue operating using the paths advertized from the opposite site.