

Manual failover
Contributors

 Suggest changes
Suggest changes
The term "failover" does not refer to the direction of replication with SnapMirror active sync because it is a bidirectional replication technology. Instead, 'failover' refers to which storage system will be the preferred site in the event of failure.
For example, you may want to perform a failover to change the preferred site before you shut down a site for maintenance, or before performing a DR test.
Changing the preferred site requires a simple operation. IO will pause for a second or two as authority over replication behavior switches between clusters, but IO is otherwise unaffected.
GUI example:
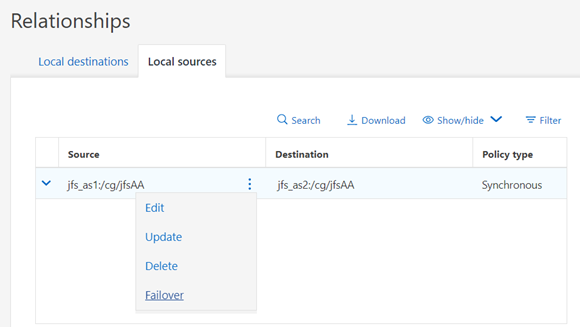
Example of changing it back via the CLI:
Cluster2::> snapmirror failover start -destination-path jfs_as2:/cg/jfsAA
[Job 9575] Job is queued: SnapMirror failover for destination "jfs_as2:/cg/jfsAA ".
Cluster2::> snapmirror failover show
Source Destination Error
Path Path Type Status start-time end-time Reason
-------- ----------- -------- --------- ---------- ---------- ----------
jfs_as1:/cg/jfsAA
jfs_as2:/cg/jfsAA
planned completed 9/11/2024 9/11/2024
09:29:22 09:29:32
The new destination path can be verified as follows:
Cluster1::> snapmirror show -destination-path jfs_as1:/cg/jfsAA
Source Path: jfs_as2:/cg/jfsAA
Destination Path: jfs_as1:/cg/jfsAA
Relationship Type: XDP
Relationship Group Type: consistencygroup
SnapMirror Policy Type: automated-failover-duplex
SnapMirror Policy: AutomatedFailOverDuplex
Tries Limit: -
Mirror State: Snapmirrored
Relationship Status: InSync