

NetApp StorageGRID and big data analytics
 Suggest changes
Suggest changes
NetApp StorageGRID use cases
NetApp StorageGRID object storage solution offers scalability, data availability, security, and high performance. Organizations of all sizes and across various industries use StorageGRID S3 for a wide range of use cases. Let's explore some typical scenarios:
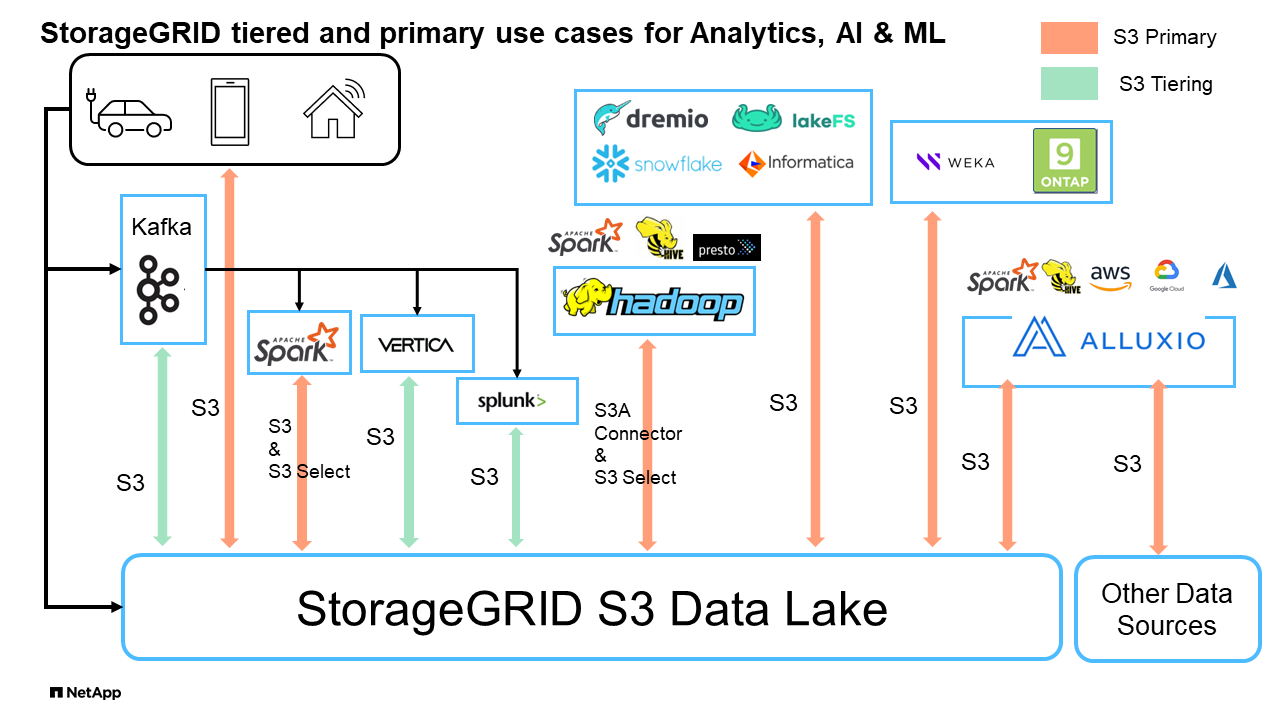
Big data analytics: StorageGRID S3 is frequently used as a data lake, where businesses store large amounts of structured and unstructured data for analysis using tools like Apache Spark, Splunk Smartstore and Dremio.
Data Tiering: NetApp customers use ONTAP's FabricPool feature to automatically move data between a high-performance local tier to StorageGRID. Tiering frees up expensive flash storage for hot data while keeping cold data readily available on low-cost object storage. This maximizes performance and savings.
Data backup and disaster recovery: Businesses can use StorageGRID S3 as a reliable and cost-effective solution for backing up critical data and recovering it in case of a disaster.
Data storage for applications: StorageGRID S3 can be used as a storage backend for applications, enabling developers to easily store and retrieve files, images, videos, and other types of data.
Content delivery: StorageGRID S3 can be used to store and deliver static website content, media files, and software downloads to users around the world, leveraging StorageGRID's geo distribution and global namespace for fast and reliable content delivery.
Data Archive: StorageGRID offers different storage types and supports tiering to public long term low-cost storage options, make it an ideal solution for archiving and long-term retention of data that needs to be retained for compliance or historical purposes.
Object storage use cases
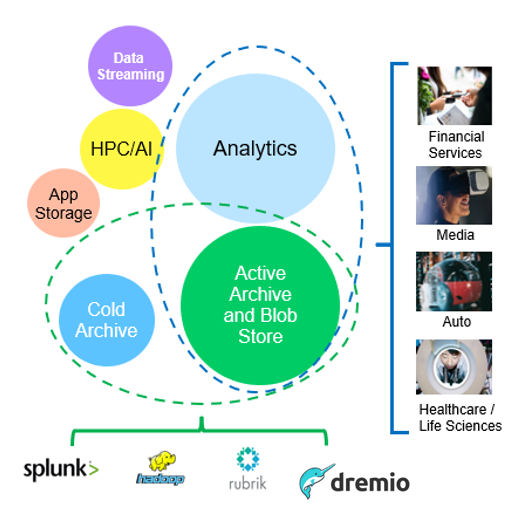
Among the above, big data analytics is one of the topmost use cases and its usage is trending upward.
Why StorageGRID for data lakes?
-
Increased collaboration - Massive shared multi-site, multi-tenancy w/industry standard API access
-
Decreased operational costs - Operational simplicity of a single, self-healing, automated scale-out architecture
-
Scalability - Unlike traditional Hadoop and data warehouse solutions, StorageGRID S3 object storage decouples storage from compute and data, allowing business to scale their storage needs as they grew.
-
Durability and reliability - StorageGRID provides 99.999999999% durability, meaning that data stored is highly resistant to data loss. It also offers high availability, ensuring that data is always accessible.
-
Security - StorageGRID offers various security features, including encryption, access control policy, data lifecycle management, object lock and versioning to protect data stored in S3 buckets
StorageGRID S3 Data Lakes
Benchmarking Data Warehouses and Lakehouses with S3 Object Storage: A Comparative Study
This article presents a comprehensive benchmark of various data warehouse and lakehouse ecosystems using NetApp StorageGRID. The goal is to determine which system performs best with S3 object storage. Refer to this
Apache Iceberg: The Definitive Guide to learn more about datawarehous/lakehouse architectures and table format (Parquet and Iceberg).
-
Benchmark Tool - TPC-DS - https://www.tpc.org/tpcds/
-
Big data ecosystems
-
Cluster of VMs, each with 128G RAM and 24 vCPU, SSD storage for system disk
-
Hadoop 3.3.5 with Hive 3.1.3 (1 name node + 4 data nodes)
-
Delta Lake with Spark 3.2.0 (1 master + 4 workers) and Hadoop 3.3.5
-
Dremio v25.2 (1 coordinator + 5 executors)
-
Trino v438 (1 coordinator + 5 workers)
-
Starburst v453 (1 coordinator + 5 workers)
-
-
Object storage
-
NetApp® StorageGRID® 11.8 with 3 x SG6060 + 1x SG1000 load balancer
-
Object protection - 2 copies (result is similar with EC 2+1)
-
-
Database size 1000GB
-
Cache was disabled across all ecosystems for each query test using the Parquet format. For the Iceberg format, we compared the number of S3 GET requests and total query time between cache-disabled and cache-enabled scenarios.
TPC-DS includes 99 complex SQL queries designed for benchmarking. We measured the total time taken to execute all 99 queries and conducted a detailed analysis by examining the type and number of S3 requests. Our tests compared the efficiency of two popular table formats: Parquet and Iceberg.
TPC-DS query result with Parquet table format
| Ecosystem | Hive | Delta Lake | Dremio | Trino | Starburst |
|---|---|---|---|---|---|
TPCDS 99 queries |
1084 1 |
55 |
36 |
32 |
28 |
S3 Requests breakdown |
|||||
GET |
1,117,184 |
2,074,610 |
3,939,690 |
1,504,212 |
1,495,039 |
observation: |
80% range get of 2KB to 2MB from 32MB objects, 50 - 100 requests/sec |
73% range get below 100KB from 32MB objects, 1000 - 1400 requests/sec |
90% 1M byte range get from 256MB objects, 2500 - 3000 requests/sec |
Range GET size: 50% below 100KB, 16% around 1MB, 27% 2MB-9MB, 3500 - 4000 requests/sec |
Range GET size: 50% below 100KB, 16% around 1MB, 27% 2MB-9MB, 4000 - 5000 request/sec |
List objects |
312,053 |
24,158 |
120 |
509 |
512 |
HEAD |
156,027 |
12,103 |
96 |
0 |
0 |
HEAD |
982,126 |
922,732 |
0 |
0 |
0 |
Total requests |
2,567,390 |
3,033,603 |
3.939,906 |
1,504,721 |
1,499,551 |
1 Hive unable to complete query number 72
TPC-DS query result with Iceberg table format
| Ecosystem | Dremio | Trino | Starburst |
|---|---|---|---|
TPCDS 99 queries |
22 |
28 |
22 |
TPCDS 99 queries |
16 |
28 |
21.5 |
S3 Requests breakdown |
|||
GET (cache disabled) |
1,985,922 |
938,639 |
931,582 |
GET (cache enabled) |
611,347 |
30,158 |
3,281 |
observation: |
Range GET size: 67% 1MB, 15% 100KB, 10% 500KB, 3500 - 4500 requests/sec |
Range GET size: 42% below 100KB, 17% around 1MB, 33% 2MB-9MB, 3500 - 4000 requests/sec |
Range GET size: 43% below 100KB, 17% around 1MB, 33% 2MB-9MB, 4000 - 5000 requests/sec |
List objects |
1465 |
0 |
0 |
HEAD |
1464 |
0 |
0 |
HEAD |
3,702 |
509 |
509 |
Total requests (cache disabled) |
1,992,553 |
939,148 |
932,071 |
2 Trino/Starburst performance is bottlenecked by compute resources; adding more RAM to the cluster reduces the total query time.
As shown in the first table, Hive is significantly slower than other modern data lakehouse ecosystems. We observed that Hive sent a large number of S3 list-objects requests, which are typically slow on all object storage platforms, especially when dealing with buckets containing many objects. This significantly increases the overall query duration. Additionally, modern lakehouse ecosystems can send a high number of GET requests in parallel, ranging from 2,000 to 5,000 requests per second, compared to Hive’s 50 to 100 requests per second. The standard filesystem mimicry by Hive and Hadoop S3A contributes to Hive’s slowness when interacting with S3 object storage.
Using Hadoop (either on HDFS or S3 object storage) with Hive or Spark requires extensive knowledge of both Hadoop and Hive/Spark, as well as an understanding of how the settings from each service interact. Together, they have over 1,000 settings, many of which are interrelated and cannot be changed independently. Finding the optimal combination of settings and values requires a tremendous amount of time and effort.
Comparing the Parquet and Iceberg results, we notice that the table format is a major performance factor. The Iceberg table format is more efficient than the Parquet in terms of the number of S3 requests, with 35% to 50% fewer requests compared to the Parquet format.
The performance of Dremio, Trino, or Starburst is primarily driven by the computing power of the cluster. Although all three use the S3A connector for S3 object storage connection, they do not require Hadoop, and most of Hadoop’s fs.s3a settings are not used by these systems. This simplifies performance tuning, eliminating the need to learn and test various Hadoop S3A settings.
From this benchmark result, we can conclude that big data analytic system optimized for S3-based workloads is a major performance factor. Modern lakehouses optimize query execution, efficiently utilize metadata, and provide seamless access to S3 data, resulting in better performance compared to Hive when working with S3 storage.
Refer to this page to configure Dremio S3 data source with StorageGRID.
Visit the links below to learn more about how StorageGRID and Dremio work together to provide a modern and efficient data lake infrastructure and how NetApp migrated from Hive + HDFS to Dremio + StorageGRID to dramatically enhance big data analytic efficiency.