

解决方案技术
 建议更改
建议更改
Apache Spark 是一种流行的编程框架,用于编写可直接与 Hadoop 分布式文件系统 (HDFS) 协同工作的 Hadoop 应用程序。 Spark 已准备好投入生产,支持流数据处理,并且比 MapReduce 更快。 Spark 具有可配置的内存数据缓存,可实现高效迭代,并且 Spark shell 具有交互性,可用于学习和探索数据。使用 Spark,您可以用 Python、Scala 或 Java 创建应用程序。 Spark 应用程序由一个或多个具有一个或多个任务的作业组成。
每个 Spark 应用程序都有一个 Spark 驱动程序。在 YARN-Client 模式下,驱动程序在客户端本地运行。在 YARN-Cluster 模式下,驱动程序在应用程序主机上的集群中运行。在集群模式下,即使客户端断开连接,应用程序仍继续运行。
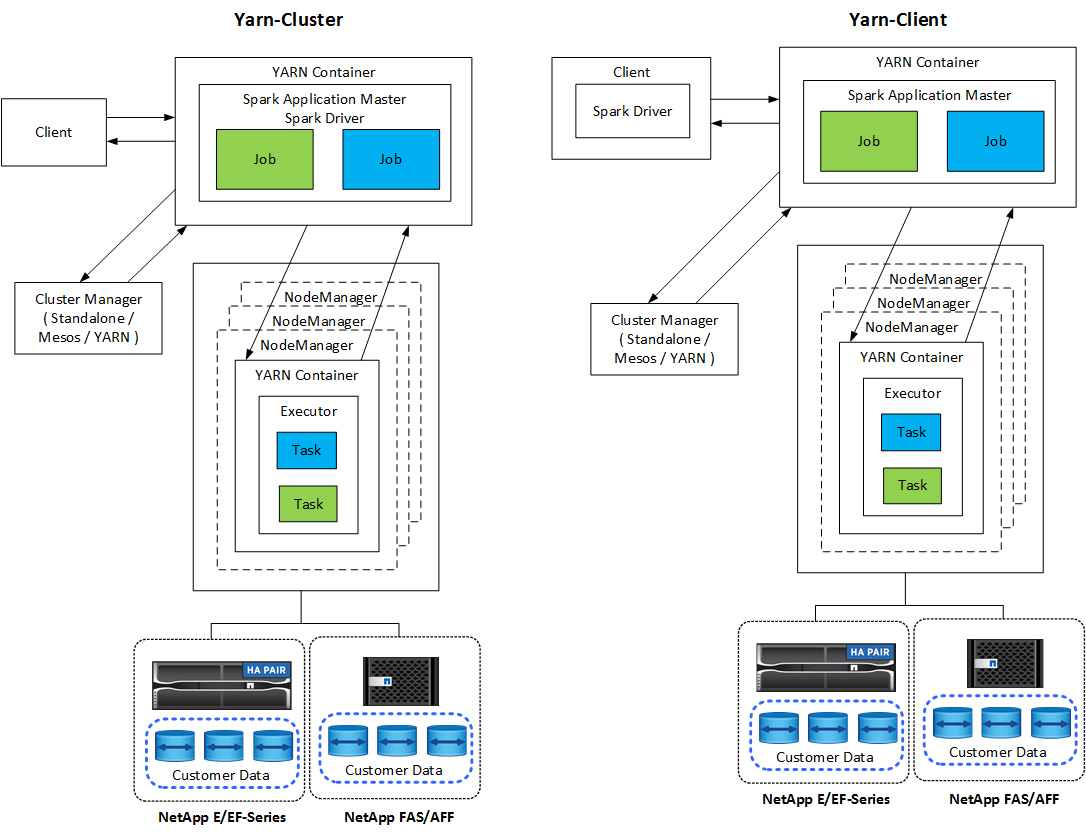
有三个集群管理器:
-
*独立。*该管理器是 Spark 的一部分,可以轻松设置集群。
-
Apache Mesos。这是一个通用集群管理器,也运行 MapReduce 和其他应用程序。
-
Hadoop YARN。这是 Hadoop 3 中的资源管理器。
弹性分布式数据集(RDD)是 Spark 的主要组件。 RDD 从集群内存中存储的数据中重新创建丢失和缺失的数据,并存储来自文件或以编程方式创建的初始数据。 RDD 是从文件、内存中的数据或另一个 RDD 创建的。 Spark 编程执行两种操作:转换和操作。转换基于现有 RDD 创建新的 RDD。操作从 RDD 返回一个值。
转换和操作也适用于 Spark 数据集和 DataFrames。数据集是分布式数据集合,它兼具 RDD 的优势(强类型、使用 lambda 函数)和 Spark SQL 优化执行引擎的优势。可以从 JVM 对象构建数据集,然后使用功能转换(map、flatMap、filter 等)进行操作。 DataFrame 是按命名列组织起来的数据集。它在概念上等同于关系数据库中的表或 R/Python 中的数据框。 DataFrames 可以从多种来源构建,例如结构化数据文件、Hive/HBase 中的表、本地或云端的外部数据库或现有的 RDD。
Spark 应用程序包括一个或多个 Spark 作业。作业在执行器中运行任务,执行器在 YARN 容器中运行。每个执行器都在单个容器中运行,并且执行器在应用程序的整个生命周期中都存在。应用程序启动后,执行器就固定了,YARN 不会调整已分配的容器的大小。执行器可以对内存数据同时运行任务。