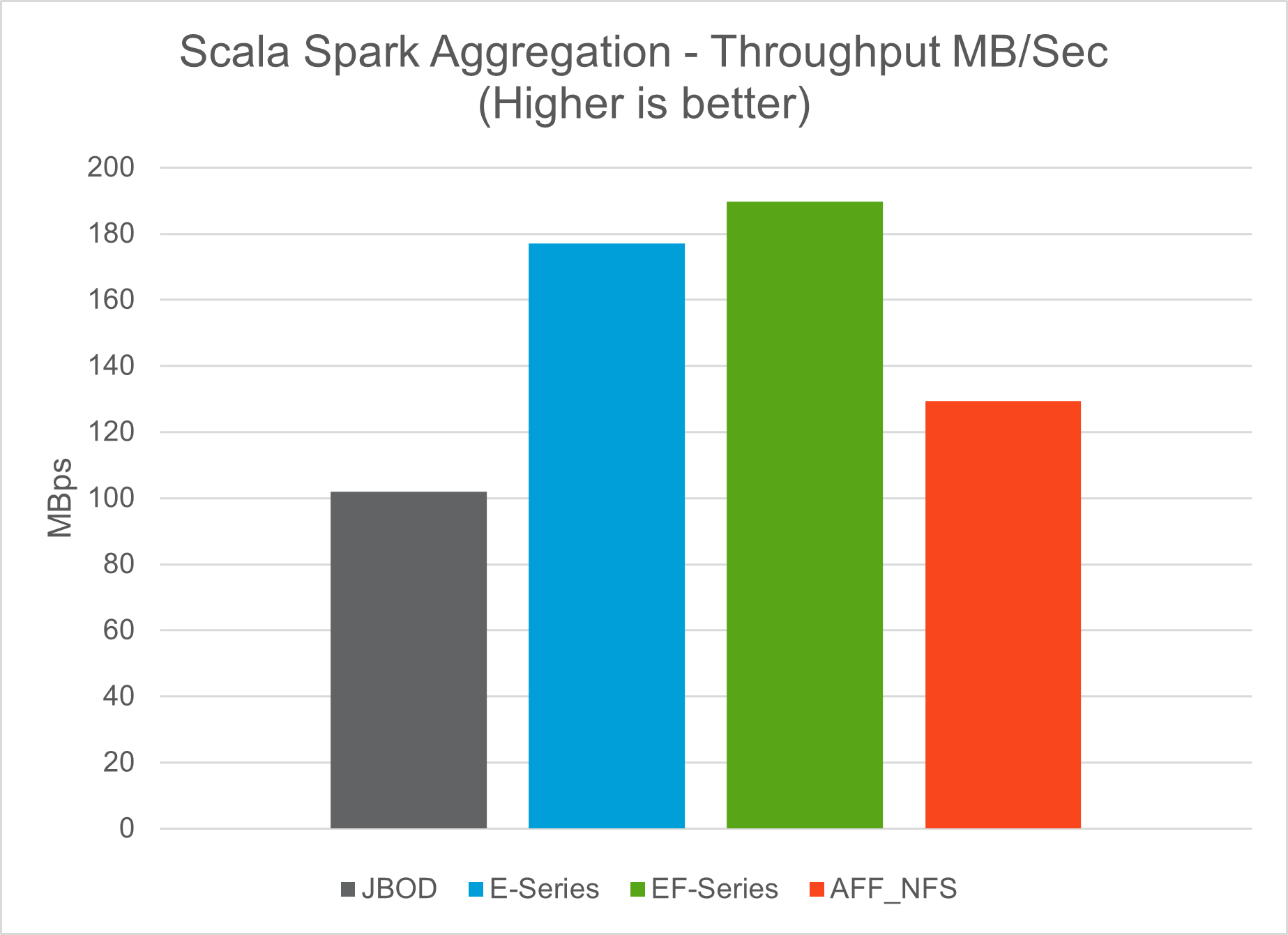
测试结果
 建议更改
建议更改
我们使用 TeraGen 基准测试工具中的 TeraSort 和 TeraValidate 脚本来测量 E5760、E5724 和AFF-A800 配置的 Spark 性能验证。此外,还测试了三个主要用例:Spark NLP 管道和 TensorFlow 分布式训练、Horovod 分布式训练以及使用 Keras 进行 DeepFM CTR 预测的多工深度学习。
对于 E 系列和StorageGRID验证,我们使用了 Hadoop 复制因子 2。对于AFF验证,我们仅使用一个数据源。
下表列出了 Spark 性能验证的硬件配置。
| 类型 | Hadoop 工作节点 | 驱动器类型 | 每个节点的驱动器 | 存储控制器 |
|---|---|---|---|---|
SG6060 |
4 |
SAS |
12 |
单个高可用性 (HA) 对 |
E5760 |
4 |
SAS |
60 |
单个 HA 对 |
E5724 |
4 |
SAS |
24 |
单个 HA 对 |
AFF800 |
4 |
SSD |
6 |
单个 HA 对 |
下表列出了软件要求。
| 软件 | 版本 |
|---|---|
RHEL |
7.9 |
OpenJDK 运行环境 |
1.8.0 |
OpenJDK 64 位服务器虚拟机 |
25.302 |
Git |
2.24.1 |
GCC/G++ |
11.2.1 |
火花 |
3.2.1 |
PySpark |
3.1.2 |
SparkNLP |
3.4.2 |
TensorFlow |
2.9.0 |
喀拉拉 |
2.9.0 |
霍罗沃德 |
0.24.3 |
金融情绪分析
我们发表了"TR-4910:利用NetApp AI 对客户沟通进行情绪分析",其中使用 "NetApp DataOps 工具包"、 AFF存储和NVIDIA DGX 系统。该管道利用 DataOps Toolkit 执行批量音频信号处理、自动语音识别 (ASR)、迁移学习和情绪分析, "NVIDIA Riva SDK" ,以及 "道框架"。将情绪分析用例扩展到金融服务行业,我们构建了 SparkNLP 工作流程,为各种 NLP 任务(例如命名实体识别)加载了三个 BERT 模型,并获得了纳斯达克十大公司季度收益电话会议的句子级情绪。
以下脚本 `sentiment_analysis_spark. py`使用 FinBERT 模型处理 HDFS 中的转录本,并产生正面、中性和负面情绪计数,如下表所示:
-bash-4.2$ time ~/anaconda3/bin/spark-submit --packages com.johnsnowlabs.nlp:spark-nlp_2.12:3.4.3 --master yarn --executor-memory 5g --executor-cores 1 --num-executors 160 --conf spark.driver.extraJavaOptions="-Xss10m -XX:MaxPermSize=1024M" --conf spark.executor.extraJavaOptions="-Xss10m -XX:MaxPermSize=512M" /sparkusecase/tr-4570-nlp/sentiment_analysis_spark.py hdfs:///data1/Transcripts/ > ./sentiment_analysis_hdfs.log 2>&1 real13m14.300s user557m11.319s sys4m47.676s
下表列出了 2016 年至 2020 年纳斯达克十大公司的收益电话会议句子级情绪分析。
| 情绪计数和百分比 | 全部 10 家公司 | 苹果 | AMD | 亚马逊 | 思科 | 谷歌 | 国际贸易中心 | 微软 | NVDA |
|---|---|---|---|---|---|---|---|---|---|
正计数 |
7447 |
1567 |
743 |
290 |
682 |
826 |
824 |
904 |
417 |
中立计数 |
64067 |
6856 |
7596 |
5086 |
6650 |
5914 |
6099 |
5715 |
6189 |
负数 |
1787 |
253 |
213 |
84 |
189 |
97 |
282 |
202 |
89 |
未分类的计数 |
196 |
0 |
0 |
76 |
0 |
0 |
0 |
1 |
0 |
(总数) |
73497 |
8676 |
8552 |
5536 |
7521 |
6837 |
7205 |
6822 |
6695 |
从百分比来看,首席执行官和首席财务官所说的大多数句子都是事实,因此带有中立的情绪。在收益电话会议期间,分析师提出的问题可能会传达积极或消极的情绪。值得进一步定量研究负面或正面情绪如何影响交易当天或次日的股票价格。
下表列出了纳斯达克十大公司的句子级情感分析,以百分比表示。
| 情绪百分比 | 全部 10 家公司 | 苹果 | AMD | 亚马逊 | 思科 | 谷歌 | 国际贸易中心 | 微软 | NVDA |
|---|---|---|---|---|---|---|---|---|---|
积极的 |
10.13% |
18.06% |
8.69% |
5.24% |
9.07% |
12.08% |
11.44% |
13.25% |
6.23% |
中性的 |
87.17% |
79.02% |
88.82% |
91.87% |
88.42% |
86.50% |
84.65% |
83.77% |
92.44% |
消极的 |
2.43% |
2.92% |
2.49% |
1.52% |
2.51% |
1.42% |
3.91% |
2.96% |
1.33% |
未分类 |
0.27% |
0% |
0% |
1.37% |
0% |
0% |
0% |
0.01% |
0% |
在工作流运行时方面,我们看到了显著的 4.78 倍改进 `local`模式到 HDFS 中的分布式环境,并通过利用 NFS 进一步提高 0.14%。
-bash-4.2$ time ~/anaconda3/bin/spark-submit --packages com.johnsnowlabs.nlp:spark-nlp_2.12:3.4.3 --master yarn --executor-memory 5g --executor-cores 1 --num-executors 160 --conf spark.driver.extraJavaOptions="-Xss10m -XX:MaxPermSize=1024M" --conf spark.executor.extraJavaOptions="-Xss10m -XX:MaxPermSize=512M" /sparkusecase/tr-4570-nlp/sentiment_analysis_spark.py file:///sparkdemo/sparknlp/Transcripts/ > ./sentiment_analysis_nfs.log 2>&1 real13m13.149s user537m50.148s sys4m46.173s
如下图所示,数据和模型并行提高了数据处理和分布式 TensorFlow 模型推理的速度。 NFS 中的数据位置产生了稍微更好的运行时间,因为工作流瓶颈是预训练模型的下载。如果我们增加成绩单数据集的大小,NFS 的优势就更加明显。
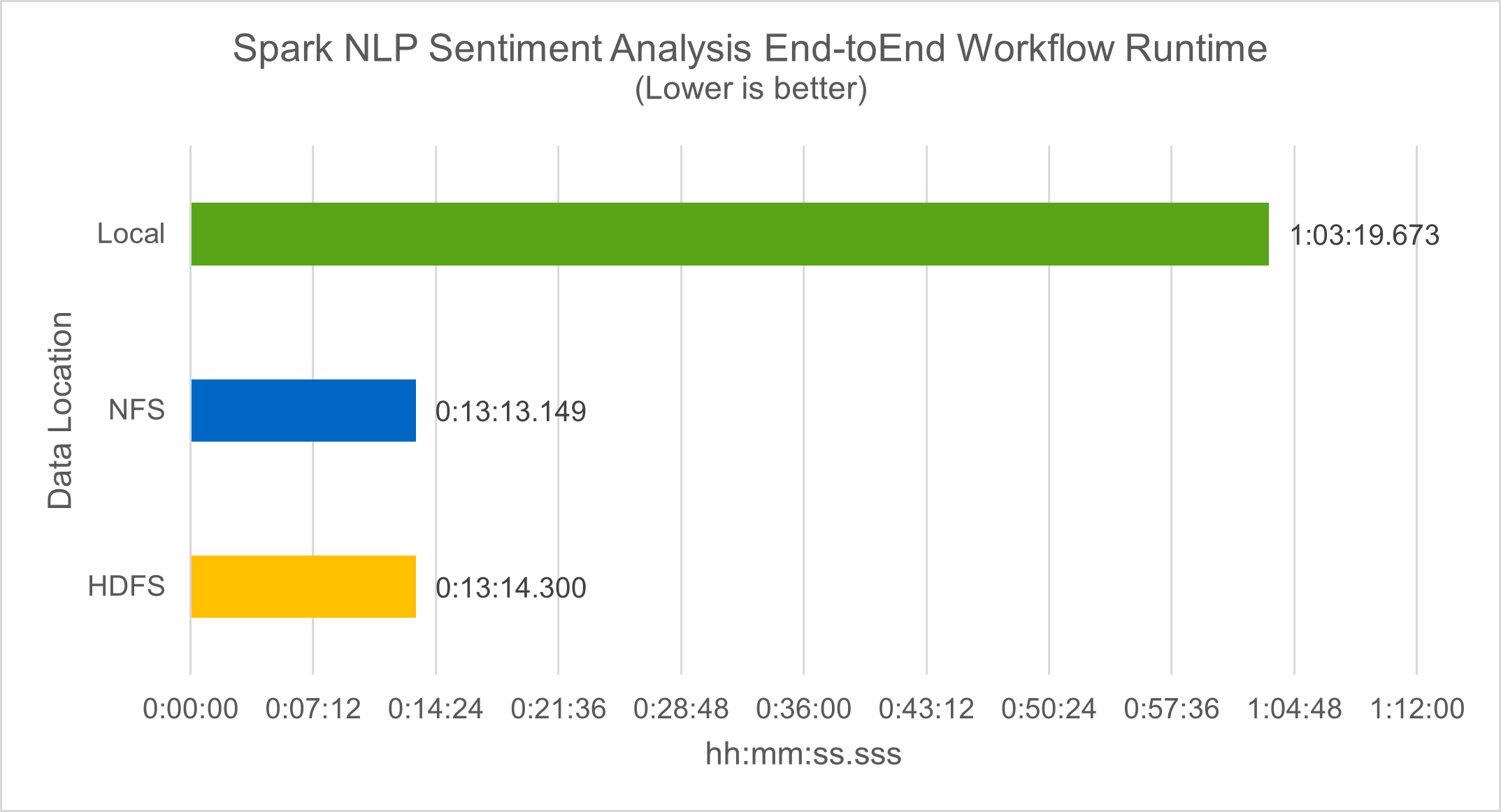
Horovod 性能的分布式训练
以下命令使用单个 master`具有 160 个执行器的节点,每个执行器都有一个核心。执行器内存限制为 5GB,以避免内存不足错误。请参阅"针对每个主要用例的 Python 脚本"有关数据处理、模型训练和模型准确率计算的更多详细信息,请参阅 `keras_spark_horovod_rossmann_estimator.py。
(base) [root@n138 horovod]# time spark-submit --master local --executor-memory 5g --executor-cores 1 --num-executors 160 /sparkusecase/horovod/keras_spark_horovod_rossmann_estimator.py --epochs 10 --data-dir file:///sparkusecase/horovod --local-submission-csv /tmp/submission_0.csv --local-checkpoint-file /tmp/checkpoint/ > /tmp/keras_spark_horovod_rossmann_estimator_local. log 2>&1
经过 10 个训练周期后,最终的运行时间如下:
real43m34.608s user12m22.057s sys2m30.127s
处理输入数据、训练 DNN 模型、计算准确度以及生成 TensorFlow 检查点和预测结果的 CSV 文件花费了超过 43 分钟。我们将训练周期数限制为 10,在实践中通常设置为 100,以确保令人满意的模型准确率。训练时间通常与训练次数呈线性关系。
接下来,我们使用集群中可用的四个工作节点,并在 `yarn`HDFS 中的数据模式:
(base) [root@n138 horovod]# time spark-submit --master yarn --executor-memory 5g --executor-cores 1 --num-executors 160 /sparkusecase/horovod/keras_spark_horovod_rossmann_estimator.py --epochs 10 --data-dir hdfs:///user/hdfs/tr-4570/experiments/horovod --local-submission-csv /tmp/submission_1.csv --local-checkpoint-file /tmp/checkpoint/ > /tmp/keras_spark_horovod_rossmann_estimator_yarn.log 2>&1
最终的运行时间改进如下:
real8m13.728s user7m48.421s sys1m26.063s
借助 Horovod 模型和 Spark 中的数据并行性,我们看到运行速度提高了 5.29 倍 yarn`相对 `local`具有十个训练阶段的模式。下图中图例显示了这一点 `HDFS`和 `Local。如果可用的话,可以使用 GPU 进一步加速底层 TensorFlow DNN 模型训练。我们计划进行此项测试并在未来的技术报告中发布结果。
我们的下一个测试比较了 NFS 和 HDFS 中的输入数据的运行时间。 AFF A800上的 NFS 卷已安装在 `/sparkdemo/horovod`分布于 Spark 集群的五个节点(一个主节点,四个工作节点)上。我们运行了与之前的测试类似的命令, `--data- dir`参数现在指向 NFS 挂载:
(base) [root@n138 horovod]# time spark-submit --master yarn --executor-memory 5g --executor-cores 1 --num-executors 160 /sparkusecase/horovod/keras_spark_horovod_rossmann_estimator.py --epochs 10 --data-dir file:///sparkdemo/horovod --local-submission-csv /tmp/submission_2.csv --local-checkpoint-file /tmp/checkpoint/ > /tmp/keras_spark_horovod_rossmann_estimator_nfs.log 2>&1
使用 NFS 的运行结果如下:
real 5m46.229s user 5m35.693s sys 1m5.615s
速度又提高了 1.43 倍,如下图所示。因此,通过将NetApp全闪存存储连接到其集群,客户可以享受 Horovod Spark 工作流的快速数据传输和分发优势,与在单个节点上运行相比,可实现 7.55 倍的加速。
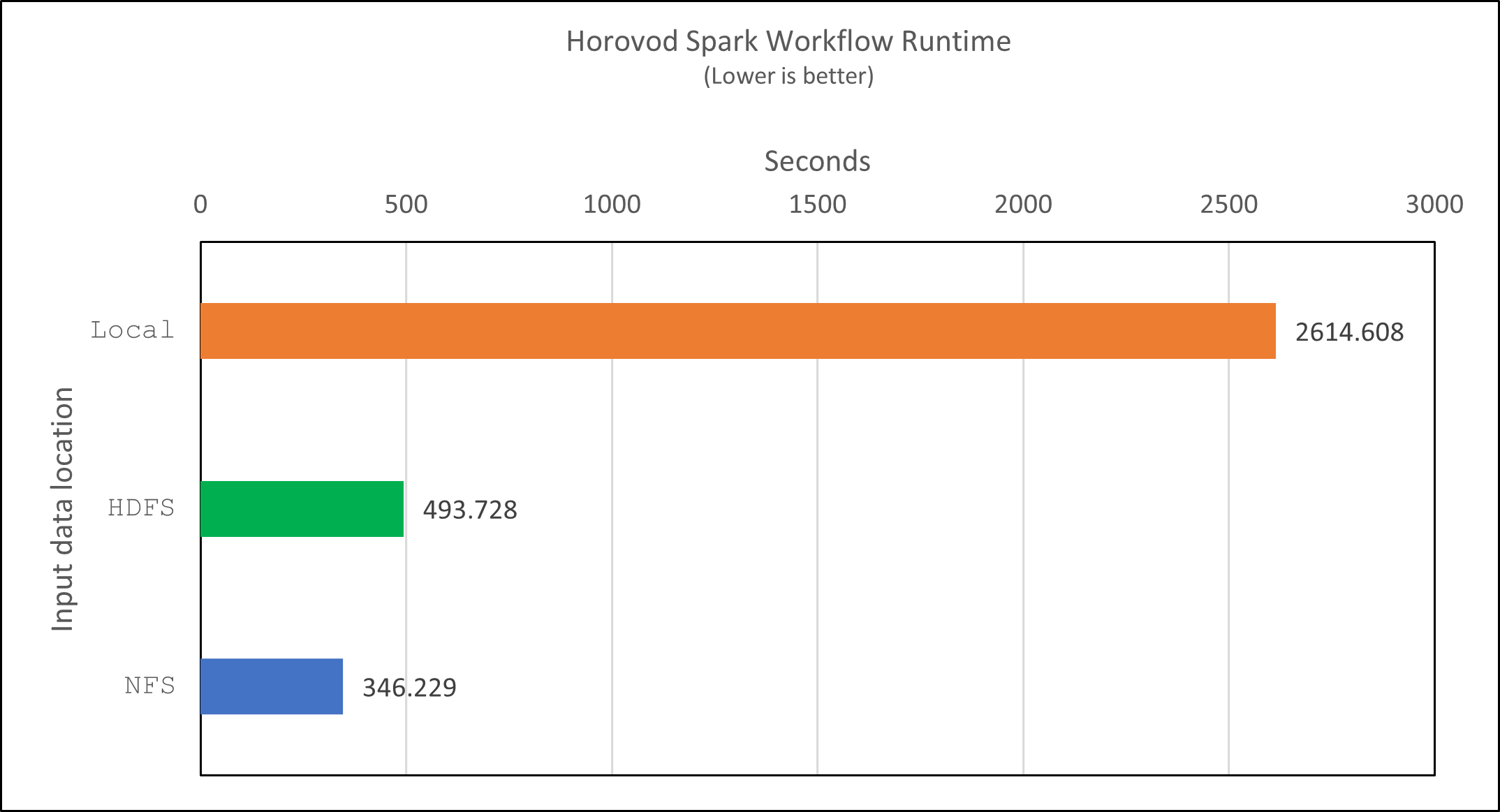
CTR预测性能的深度学习模型
对于旨在最大化点击率的推荐系统,必须学习用户行为背后复杂的特征交互,这些特征交互可以通过数学方式从低阶到高阶计算。对于良好的深度学习模型来说,低阶和高阶特征交叉应该同等重要,而不应偏向其中任何一方。深度分解机(DeepFM)是一种基于分解机的神经网络,它将用于推荐的分解机和用于特征学习的深度学习结合在一种新的神经网络架构中。
虽然传统的分解机将成对的特征交叉建模为特征之间潜在向量的内积,并且理论上可以捕获高阶信息,但在实践中,机器学习从业者通常只使用二阶特征交叉,因为计算和存储复杂度很高。深度神经网络变体,例如谷歌的 "广度与深度模型"另一方面,通过结合线性宽模型和深度模型,在混合网络结构中学习复杂的特征交互。
这个 Wide & Deep 模型有两个输入,一个用于底层的广度模型,另一个用于深度模型,后者仍然需要专家的特征工程,因此该技术不太适用于其他领域。与广度和深度模型不同,DeepFM 可以使用原始特征进行有效训练,而无需任何特征工程,因为它的广度部分和深度部分共享相同的输入和嵌入向量。
我们首先处理了 Criteo train.txt (11GB)文件转换为名为 `ctr_train.csv`存储在 NFS 挂载中 `/sparkdemo/tr-4570-data`使用 `run_classification_criteo_spark.py`来自部分"每个主要用例的 Python 脚本。"在此脚本中,函数 `process_input_file`执行几个字符串方法来删除制表符并插入 ','`作为分隔符和 '\n'`作为换行符。请注意,您只需处理原始 `train.txt`一次,这样代码块就显示为注释。
为了对不同的 DL 模型进行以下测试,我们使用 ctr_train.csv`作为输入文件。在后续的测试运行中,输入的 CSV 文件被读入 Spark DataFrame,其模式包含以下字段 'label',整数密集特征 ['I1', 'I2', 'I3', …, 'I13']`和稀疏特征 `['C1', 'C2', 'C3', …, 'C26']。下列 `spark-submit`命令接受输入 CSV,以 20% 的比例训练 DeepFM 模型进行交叉验证,并在十个训练周期后选出最佳模型来计算测试集上的预测准确率:
(base) [root@n138 ~]# time spark-submit --master yarn --executor-memory 5g --executor-cores 1 --num-executors 160 /sparkusecase/DeepCTR/examples/run_classification_criteo_spark.py --data-dir file:///sparkdemo/tr-4570-data > /tmp/run_classification_criteo_spark_local.log 2>&1
请注意,由于数据文件 `ctr_train.csv`超过 11GB,则必须设置足够的 `spark.driver.maxResultSize`大于数据集大小以避免错误。
spark = SparkSession.builder \
.master("yarn") \
.appName("deep_ctr_classification") \
.config("spark.jars.packages", "io.github.ravwojdyla:spark-schema-utils_2.12:0.1.0") \
.config("spark.executor.cores", "1") \
.config('spark.executor.memory', '5gb') \
.config('spark.executor.memoryOverhead', '1500') \
.config('spark.driver.memoryOverhead', '1500') \
.config("spark.sql.shuffle.partitions", "480") \
.config("spark.sql.execution.arrow.enabled", "true") \
.config("spark.driver.maxResultSize", "50gb") \
.getOrCreate()
在上述 `SparkSession.builder`配置我们还启用了 "阿帕奇箭",将 Spark DataFrame 转换为 Pandas DataFrame, `df.toPandas()`方法。
22/06/17 15:56:21 INFO scheduler.DAGScheduler: Job 2 finished: toPandas at /sparkusecase/DeepCTR/examples/run_classification_criteo_spark.py:96, took 627.126487 s Obtained Spark DF and transformed to Pandas DF using Arrow.
随机分割后,训练数据集中有超过 3600 万行,测试集中有 900 万个样本:
Training dataset size = 36672493 Testing dataset size = 9168124
由于本技术报告专注于不使用任何 GPU 的 CPU 测试,因此必须使用适当的编译器标志构建 TensorFlow。此步骤避免调用任何 GPU 加速库,并充分利用 TensorFlow 的高级矢量扩展 (AVX) 和 AVX2 指令。这些特征是为线性代数计算而设计的,例如矢量加法、前馈中的矩阵乘法或反向传播 DNN 训练。 AVX2 提供的融合乘加 (FMA) 指令使用 256 位浮点 (FP) 寄存器,非常适合整数代码和数据类型,可实现高达 2 倍的加速。对于 FP 代码和数据类型,AVX2 比 AVX 实现了 8% 的加速。
2022-06-18 07:19:20.101478: I tensorflow/core/platform/cpu_feature_guard.cc:151] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 FMA To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
要从源代码构建 TensorFlow, NetApp建议使用 "巴泽尔"。对于我们的环境,我们在 shell 提示符下执行以下命令来安装 dnf, dnf-plugins ,以及 Bazel。
yum install dnf dnf install 'dnf-command(copr)' dnf copr enable vbatts/bazel dnf install bazel5
您必须启用 GCC 5 或更新版本才能在构建过程中使用 C++17 功能,该功能由 RHEL 通过软件集合库 (SCL) 提供。以下命令安装 `devtoolset`以及 RHEL 7.9 集群上的 GCC 11.2.1:
subscription-manager repos --enable rhel-server-rhscl-7-rpms yum install devtoolset-11-toolchain yum install devtoolset-11-gcc-c++ yum update scl enable devtoolset-11 bash . /opt/rh/devtoolset-11/enable
请注意,最后两个命令启用 devtoolset-11,使用 /opt/rh/devtoolset-11/root/usr/bin/gcc(GCC 11.2.1)。此外,请确保您的 `git`版本高于 1.8.3(随 RHEL 7.9 提供)。参考这个 "文章"用于更新 `git`至 2.24.1。
我们假设您已经克隆了最新的 TensorFlow 主仓库。然后创建一个 `workspace`目录与 `WORKSPACE`文件使用 AVX、AVX2 和 FMA 从源代码构建 TensorFlow。运行 `configure`文件并指定正确的 Python 二进制位置。 "CUDA"由于我们没有使用 GPU,因此在我们的测试中被禁用。一个 `.bazelrc`文件根据您的设置生成。此外,我们编辑了文件并设置 `build --define=no_hdfs_support=false`启用 HDFS 支持。参考 `.bazelrc`在本节中"每个主要用例的 Python 脚本,"以获得完整的设置和标志列表。
./configure bazel build -c opt --copt=-mavx --copt=-mavx2 --copt=-mfma --copt=-mfpmath=both -k //tensorflow/tools/pip_package:build_pip_package
使用正确的标志构建 TensorFlow 后,运行以下脚本来处理 Criteo Display Ads 数据集,训练 DeepFM 模型,并根据预测分数计算接收者操作特征曲线下面积 (ROC AUC)。
(base) [root@n138 examples]# ~/anaconda3/bin/spark-submit --master yarn --executor-memory 15g --executor-cores 1 --num-executors 160 /sparkusecase/DeepCTR/examples/run_classification_criteo_spark.py --data-dir file:///sparkdemo/tr-4570-data > . /run_classification_criteo_spark_nfs.log 2>&1
经过十次训练后,我们获得了测试数据集上的 AUC 分数:
Epoch 1/10 125/125 - 7s - loss: 0.4976 - binary_crossentropy: 0.4974 - val_loss: 0.4629 - val_binary_crossentropy: 0.4624 Epoch 2/10 125/125 - 1s - loss: 0.3281 - binary_crossentropy: 0.3271 - val_loss: 0.5146 - val_binary_crossentropy: 0.5130 Epoch 3/10 125/125 - 1s - loss: 0.1948 - binary_crossentropy: 0.1928 - val_loss: 0.6166 - val_binary_crossentropy: 0.6144 Epoch 4/10 125/125 - 1s - loss: 0.1408 - binary_crossentropy: 0.1383 - val_loss: 0.7261 - val_binary_crossentropy: 0.7235 Epoch 5/10 125/125 - 1s - loss: 0.1129 - binary_crossentropy: 0.1102 - val_loss: 0.7961 - val_binary_crossentropy: 0.7934 Epoch 6/10 125/125 - 1s - loss: 0.0949 - binary_crossentropy: 0.0921 - val_loss: 0.9502 - val_binary_crossentropy: 0.9474 Epoch 7/10 125/125 - 1s - loss: 0.0778 - binary_crossentropy: 0.0750 - val_loss: 1.1329 - val_binary_crossentropy: 1.1301 Epoch 8/10 125/125 - 1s - loss: 0.0651 - binary_crossentropy: 0.0622 - val_loss: 1.3794 - val_binary_crossentropy: 1.3766 Epoch 9/10 125/125 - 1s - loss: 0.0555 - binary_crossentropy: 0.0527 - val_loss: 1.6115 - val_binary_crossentropy: 1.6087 Epoch 10/10 125/125 - 1s - loss: 0.0470 - binary_crossentropy: 0.0442 - val_loss: 1.6768 - val_binary_crossentropy: 1.6740 test AUC 0.6337
以与以前的用例类似的方式,我们将 Spark 工作流运行时与位于不同位置的数据进行了比较。下图显示了 Spark 工作流运行时深度学习 CTR 预测的比较。