

由NetApp提供支持的适用于大数据架构的数据结构
 建议更改
建议更改
NetApp提供支持的数据结构简化并集成了跨云和本地环境的数据管理,从而加速数字化转型。
NetApp提供支持的数据结构为数据可见性和洞察、数据访问和控制以及数据保护和安全提供了一致且集成的数据管理服务和应用程序(构建块),如下图所示。
经过验证的数据结构客户用例
NetApp支持的数据结构为客户提供了以下九种经过验证的用例:
-
加速分析工作负载
-
加速 DevOps 转型
-
构建云托管基础设施
-
集成云数据服务
-
保护和保障数据安全
-
优化非结构化数据
-
提高数据中心效率
-
提供数据洞察和控制
-
简化和自动化
本文档涵盖九个用例中的两个(及其解决方案):
-
加速分析工作负载
-
保护和保障数据安全
NetApp NFS 直接访问
NetApp NFS 允许客户在其现有或新的 NFSv3 或 NFSv4 数据上运行大数据分析作业,而无需移动或复制数据。它可以防止数据的多次复制,并且无需将数据与源同步。例如,在金融领域,数据从一个地方移动到另一个地方必须满足法律义务,这不是一件容易的事。在这种情况下, NetApp NFS 直接访问会从原始位置分析财务数据。另一个主要优势是,使用NetApp NFS 直接访问可以通过使用本机 Hadoop 命令简化 Hadoop 数据的保护,并利用 NetApp 丰富的数据管理产品组合实现数据保护工作流程。
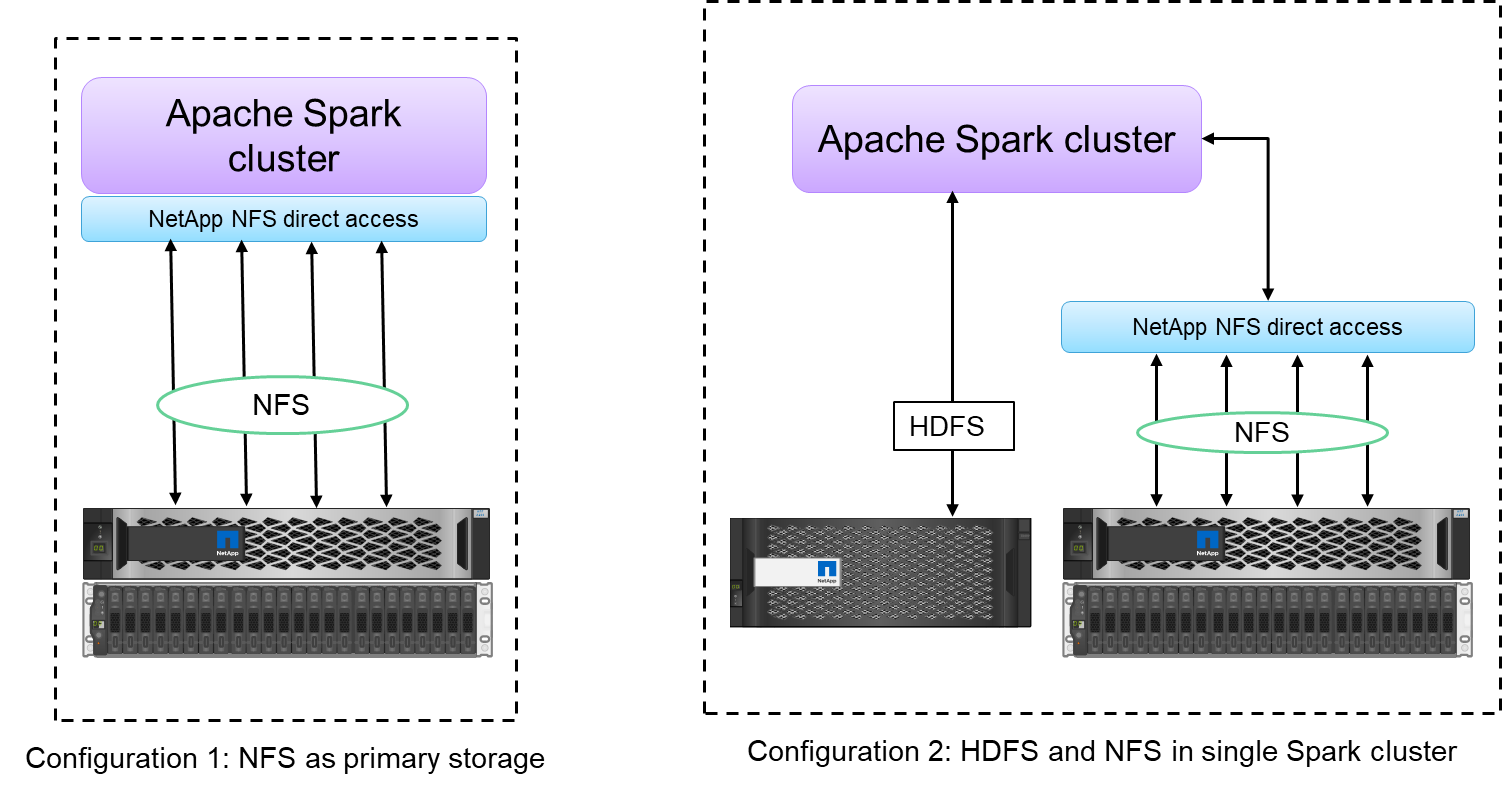
NetApp NFS 直接访问为 Hadoop/Spark 集群提供了两种部署选项:
-
默认情况下,Hadoop/Spark集群使用Hadoop分布式文件系统(HDFS)作为数据存储和默认文件系统。 NetApp NFS 直接访问可以用 NFS 存储替换默认的 HDFS 作为默认文件系统,从而实现对 NFS 数据的直接分析操作。
-
在另一个部署选项中, NetApp NFS 直接访问支持在单个 Hadoop/Spark 集群中将 NFS 与 HDFS 一起配置为附加存储。在这种情况下,客户可以通过 NFS 导出共享数据,并从同一个集群访问数据以及 HDFS 数据。
使用NetApp NFS 直接访问的主要优势包括:
-
从当前位置分析数据,从而避免将分析数据移动到 Hadoop 基础架构(如 HDFS)这一耗时耗能的任务。
-
将副本数量从三个减少到一个。
-
使用户能够分离计算和存储以独立扩展它们。
-
利用ONTAP丰富的数据管理功能提供企业数据保护。
-
已通过 Hortonworks 数据平台认证。
-
支持混合数据分析部署。
-
利用动态多线程功能减少备份时间。
大数据的构建模块
NetApp提供支持的数据结构集成了数据管理服务和应用程序(构建块),用于数据访问、控制、保护和安全,如下图所示。
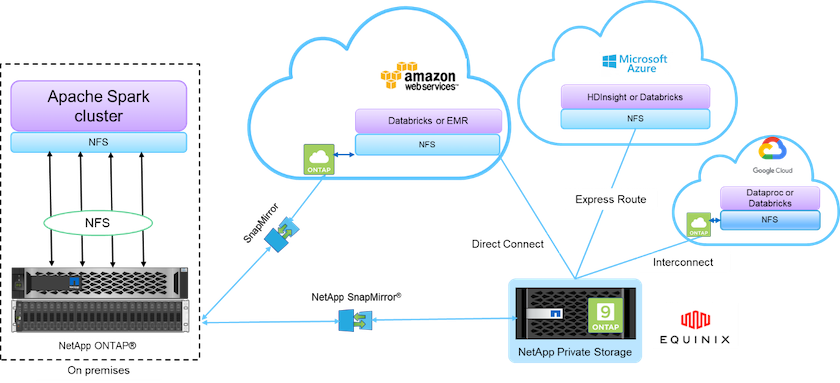
上图中的构建块包括:
-
* NetApp NFS 直接访问。*为最新的 Hadoop 和 Spark 集群提供对NetApp NFS 卷的直接访问,无需额外的软件或驱动程序要求。
-
* NetApp Cloud Volumes ONTAP和Google Cloud NetApp Volumes 。*基于在 Amazon Web Services (AWS) 或 Microsoft Azure 云服务中的Azure NetApp Files (ANF) 中运行的ONTAP的软件定义连接存储。
-
* NetApp SnapMirror技术*。在本地和ONTAP Cloud 或 NPS 实例之间提供数据保护功能。
-
*云服务提供商。*这些提供商包括 AWS、Microsoft Azure、Google Cloud 和 IBM Cloud。
-
*平台即服务 (PaaS)。*基于云的分析服务,例如 AWS 中的 Amazon Elastic MapReduce (EMR) 和 Databricks 以及 Microsoft Azure HDInsight 和 Azure Databricks。