AWS 中的性能概述和验证
 建议更改
建议更改
在NetApp NFS 上安装存储层的 Kafka 集群在 AWS 云中进行了性能基准测试。基准测试示例在以下章节中描述。
AWS 云中的 Kafka 与NetApp Cloud Volumes ONTAP (高可用性对和单节点)
对带有NetApp Cloud Volumes ONTAP (HA 对)的 Kafka 集群在 AWS 云中进行了性能基准测试。以下章节描述了此基准测试。
建筑设置
下表展示了使用NAS的Kafka集群的环境配置。
| 平台组件 | 环境配置 |
|---|---|
卡夫卡 3.2.3 |
|
所有节点上的操作系统 |
RHEL8.6 |
NetApp Cloud Volumes ONTAP实例 |
HA 对实例 – m5dn.12xLarge x 2node 单节点实例 - m5dn.12xLarge x 1 节点 |
NetApp集群卷ONTAP设置
-
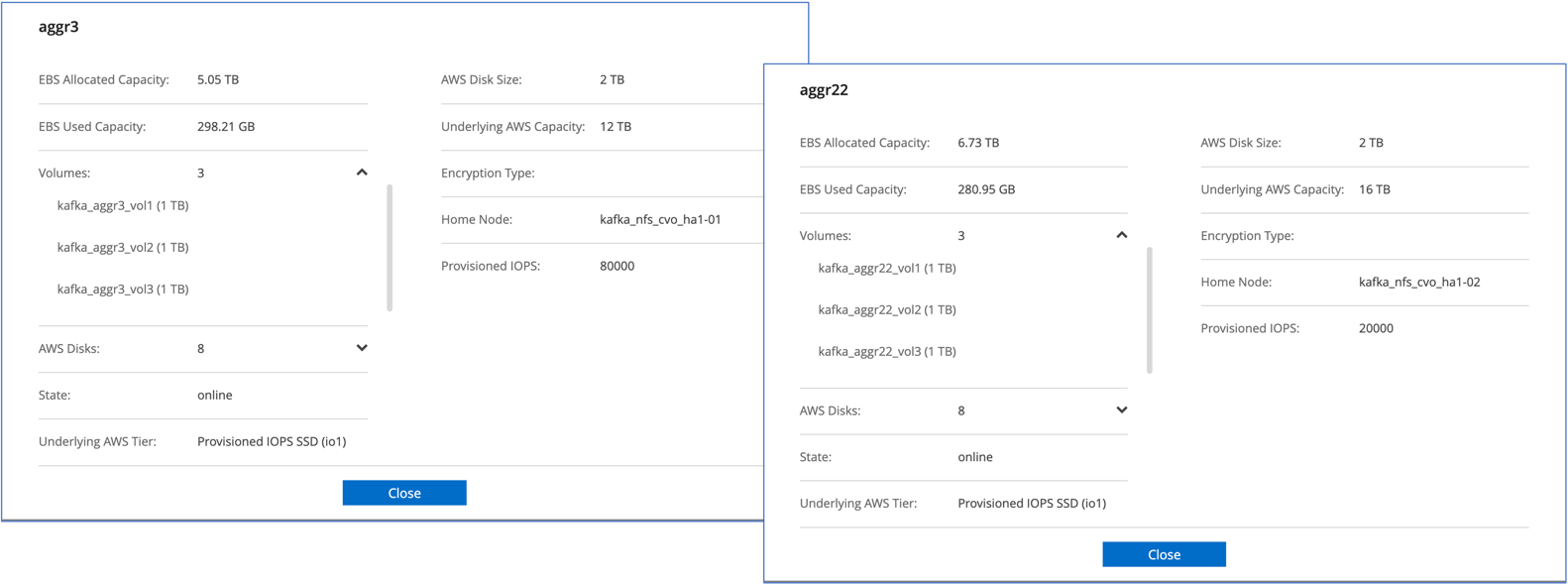
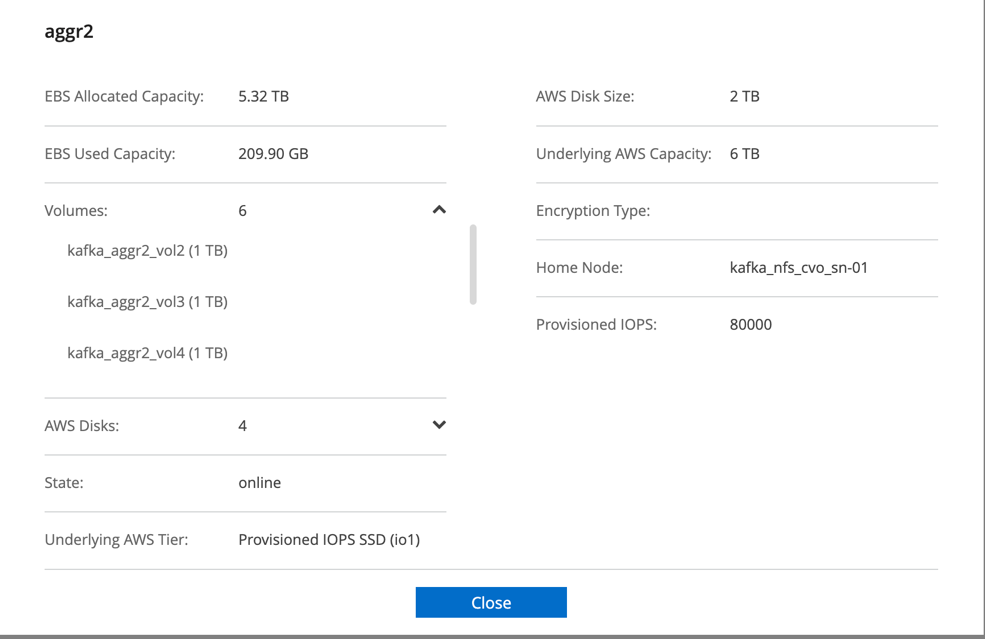
对于Cloud Volumes ONTAP HA 对,我们创建了两个聚合,每个存储控制器上的每个聚合上有三个卷。对于单个Cloud Volumes ONTAP节点,我们在一个聚合中创建六个卷。
-
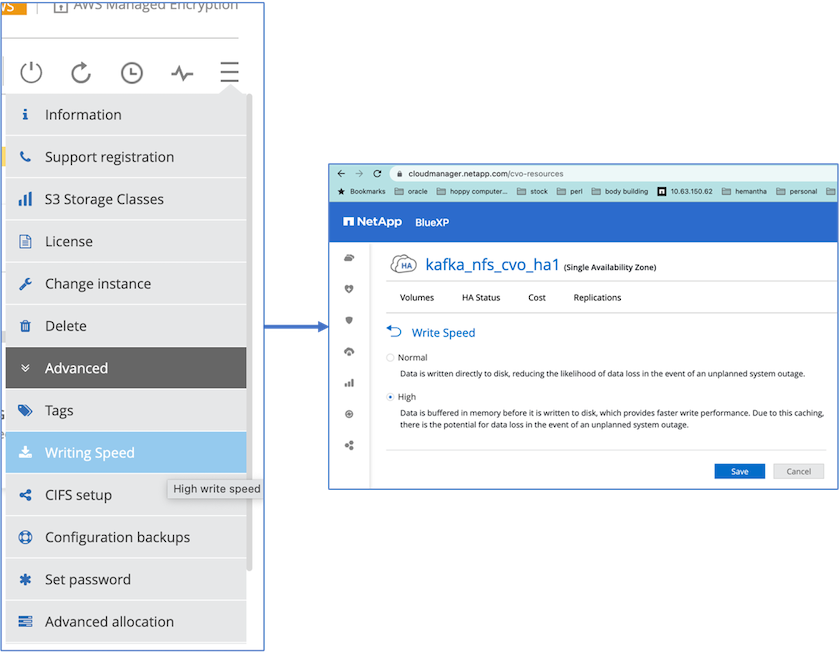
为了实现更好的网络性能,我们为 HA 对和单个节点都启用了高速网络。
-
我们注意到ONTAP NVRAM具有更多的 IOPS,因此我们将Cloud Volumes ONTAP根卷的 IOPS 更改为 2350。 Cloud Volumes ONTAP中的根卷磁盘大小为 47GB。以下ONTAP命令适用于 HA 对,相同步骤也适用于单个节点。
statistics start -object vnvram -instance vnvram -counter backing_store_iops -sample-id sample_555 kafka_nfs_cvo_ha1::*> statistics show -sample-id sample_555 Object: vnvram Instance: vnvram Start-time: 1/18/2023 18:03:11 End-time: 1/18/2023 18:03:13 Elapsed-time: 2s Scope: kafka_nfs_cvo_ha1-01 Counter Value -------------------------------- -------------------------------- backing_store_iops 1479 Object: vnvram Instance: vnvram Start-time: 1/18/2023 18:03:11 End-time: 1/18/2023 18:03:13 Elapsed-time: 2s Scope: kafka_nfs_cvo_ha1-02 Counter Value -------------------------------- -------------------------------- backing_store_iops 1210 2 entries were displayed. kafka_nfs_cvo_ha1::*>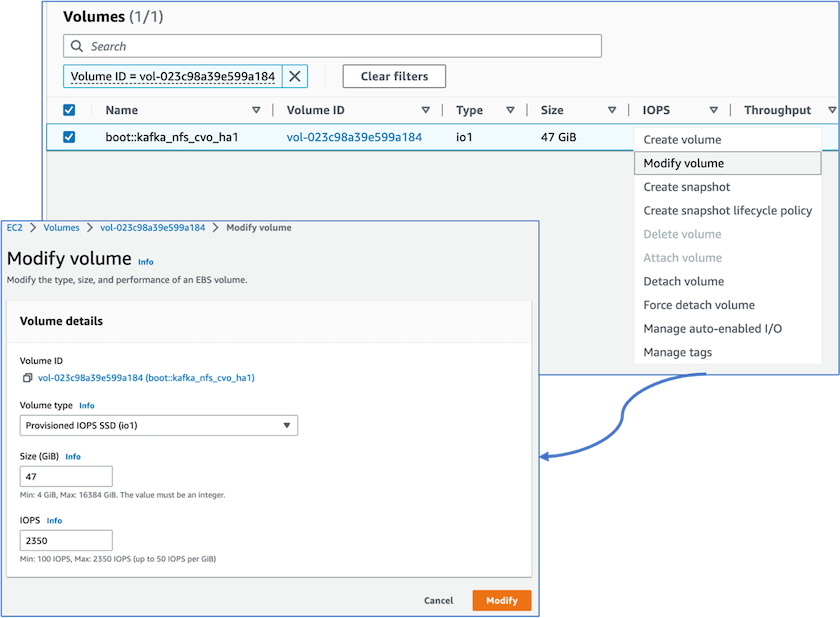
下图是基于NAS的Kafka集群架构图。
-
*计算。*我们使用了三节点 Kafka 集群,并在专用服务器上运行三节点 zookeeper 集合。每个代理通过专用 LIF 拥有两个指向Cloud Volumes ONTAP实例上的单个卷的 NFS 挂载点。
-
*监控*我们使用两个节点来实现 Prometheus-Grafana 组合。为了生成工作负载,我们使用了一个单独的三节点集群,该集群可以为该 Kafka 集群生产和消费。
-
*贮存。*我们使用了 HA 对 Cloud Volumes ONTAP实例,并在该实例上安装了一个 6TB GP3 AWS-EBS 卷。然后通过 NFS 挂载将该卷导出到 Kafka 代理。
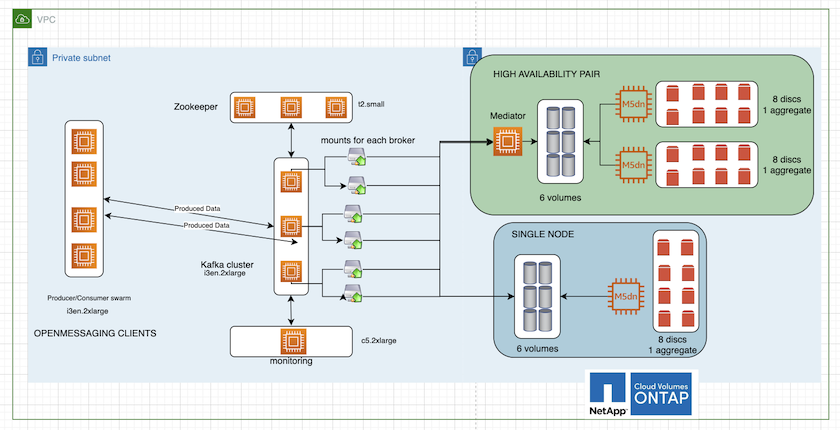
OpenMessage 基准测试配置
-
为了获得更好的 NFS 性能,我们需要在 NFS 服务器和 NFS 客户端之间建立更多的网络连接,可以使用 nconnect 创建。通过运行以下命令,使用 nconnect 选项将 NFS 卷挂载到代理节点上:
[root@ip-172-30-0-121 ~]# cat /etc/fstab UUID=eaa1f38e-de0f-4ed5-a5b5-2fa9db43bb38/xfsdefaults00 /dev/nvme1n1 /mnt/data-1 xfs defaults,noatime,nodiscard 0 0 /dev/nvme2n1 /mnt/data-2 xfs defaults,noatime,nodiscard 0 0 172.30.0.233:/kafka_aggr3_vol1 /kafka_aggr3_vol1 nfs defaults,nconnect=16 0 0 172.30.0.233:/kafka_aggr3_vol2 /kafka_aggr3_vol2 nfs defaults,nconnect=16 0 0 172.30.0.233:/kafka_aggr3_vol3 /kafka_aggr3_vol3 nfs defaults,nconnect=16 0 0 172.30.0.242:/kafka_aggr22_vol1 /kafka_aggr22_vol1 nfs defaults,nconnect=16 0 0 172.30.0.242:/kafka_aggr22_vol2 /kafka_aggr22_vol2 nfs defaults,nconnect=16 0 0 172.30.0.242:/kafka_aggr22_vol3 /kafka_aggr22_vol3 nfs defaults,nconnect=16 0 0 [root@ip-172-30-0-121 ~]# mount -a [root@ip-172-30-0-121 ~]# df -h Filesystem Size Used Avail Use% Mounted on devtmpfs 31G 0 31G 0% /dev tmpfs 31G 249M 31G 1% /run tmpfs 31G 0 31G 0% /sys/fs/cgroup /dev/nvme0n1p2 10G 2.8G 7.2G 28% / /dev/nvme1n1 2.3T 248G 2.1T 11% /mnt/data-1 /dev/nvme2n1 2.3T 245G 2.1T 11% /mnt/data-2 172.30.0.233:/kafka_aggr3_vol1 1.0T 12G 1013G 2% /kafka_aggr3_vol1 172.30.0.233:/kafka_aggr3_vol2 1.0T 5.5G 1019G 1% /kafka_aggr3_vol2 172.30.0.233:/kafka_aggr3_vol3 1.0T 8.9G 1016G 1% /kafka_aggr3_vol3 172.30.0.242:/kafka_aggr22_vol1 1.0T 7.3G 1017G 1% /kafka_aggr22_vol1 172.30.0.242:/kafka_aggr22_vol2 1.0T 6.9G 1018G 1% /kafka_aggr22_vol2 172.30.0.242:/kafka_aggr22_vol3 1.0T 5.9G 1019G 1% /kafka_aggr22_vol3 tmpfs 6.2G 0 6.2G 0% /run/user/1000 [root@ip-172-30-0-121 ~]#
-
检查Cloud Volumes ONTAP中的网络连接。以下ONTAP命令从单个Cloud Volumes ONTAP节点使用。相同的步骤适用于Cloud Volumes ONTAP HA 对。
Last login time: 1/20/2023 00:16:29 kafka_nfs_cvo_sn::> network connections active show -service nfs* -fields remote-host node cid vserver remote-host ------------------- ---------- -------------------- ------------ kafka_nfs_cvo_sn-01 2315762628 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762629 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762630 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762631 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762632 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762633 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762634 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762635 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762636 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762637 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762639 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762640 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762641 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762642 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762643 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762644 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762645 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762646 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762647 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762648 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762649 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762650 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762651 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762652 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762653 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762656 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762657 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762658 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762659 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762660 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762661 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762662 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762663 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762664 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762665 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762666 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762667 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762668 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762669 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762670 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762671 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762672 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762673 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762674 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762676 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762677 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762678 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762679 svm_kafka_nfs_cvo_sn 172.30.0.223 48 entries were displayed. kafka_nfs_cvo_sn::>
-
我们使用以下 Kafka `server.properties`在Cloud Volumes ONTAP HA 对的所有 Kafka 代理中。这 `log.dirs`属性对于每个经纪人来说是不同的,其余属性对于经纪人来说是共同的。对于 broker1 来说, `log.dirs`值如下:
[root@ip-172-30-0-121 ~]# cat /opt/kafka/config/server.properties broker.id=0 advertised.listeners=PLAINTEXT://172.30.0.121:9092 #log.dirs=/mnt/data-1/d1,/mnt/data-1/d2,/mnt/data-1/d3,/mnt/data-2/d1,/mnt/data-2/d2,/mnt/data-2/d3 log.dirs=/kafka_aggr3_vol1/broker1,/kafka_aggr3_vol2/broker1,/kafka_aggr3_vol3/broker1,/kafka_aggr22_vol1/broker1,/kafka_aggr22_vol2/broker1,/kafka_aggr22_vol3/broker1 zookeeper.connect=172.30.0.12:2181,172.30.0.30:2181,172.30.0.178:2181 num.network.threads=64 num.io.threads=64 socket.send.buffer.bytes=102400 socket.receive.buffer.bytes=102400 socket.request.max.bytes=104857600 num.partitions=1 num.recovery.threads.per.data.dir=1 offsets.topic.replication.factor=1 transaction.state.log.replication.factor=1 transaction.state.log.min.isr=1 replica.fetch.max.bytes=524288000 background.threads=20 num.replica.alter.log.dirs.threads=40 num.replica.fetchers=20 [root@ip-172-30-0-121 ~]#
-
对于 broker2, `log.dirs`属性值如下:
log.dirs=/kafka_aggr3_vol1/broker2,/kafka_aggr3_vol2/broker2,/kafka_aggr3_vol3/broker2,/kafka_aggr22_vol1/broker2,/kafka_aggr22_vol2/broker2,/kafka_aggr22_vol3/broker2
-
对于 broker3, `log.dirs`属性值如下:
log.dirs=/kafka_aggr3_vol1/broker3,/kafka_aggr3_vol2/broker3,/kafka_aggr3_vol3/broker3,/kafka_aggr22_vol1/broker3,/kafka_aggr22_vol2/broker3,/kafka_aggr22_vol3/broker3
-
-
对于单个Cloud Volumes ONTAP节点,Kafka `servers.properties`与Cloud Volumes ONTAP HA 对相同,但 `log.dirs`财产。
-
对于 broker1 来说, `log.dirs`值如下:
log.dirs=/kafka_aggr2_vol1/broker1,/kafka_aggr2_vol2/broker1,/kafka_aggr2_vol3/broker1,/kafka_aggr2_vol4/broker1,/kafka_aggr2_vol5/broker1,/kafka_aggr2_vol6/broker1
-
对于 broker2, `log.dirs`值如下:
log.dirs=/kafka_aggr2_vol1/broker2,/kafka_aggr2_vol2/broker2,/kafka_aggr2_vol3/broker2,/kafka_aggr2_vol4/broker2,/kafka_aggr2_vol5/broker2,/kafka_aggr2_vol6/broker2
-
对于 broker3, `log.dirs`属性值如下:
log.dirs=/kafka_aggr2_vol1/broker3,/kafka_aggr2_vol2/broker3,/kafka_aggr2_vol3/broker3,/kafka_aggr2_vol4/broker3,/kafka_aggr2_vol5/broker3,/kafka_aggr2_vol6/broker3
-
-
OMB 中的工作负载配置有以下属性:
(/opt/benchmark/workloads/1-topic-100-partitions-1kb.yaml)。topics: 4 partitionsPerTopic: 100 messageSize: 32768 useRandomizedPayloads: true randomBytesRatio: 0.5 randomizedPayloadPoolSize: 100 subscriptionsPerTopic: 1 consumerPerSubscription: 80 producersPerTopic: 40 producerRate: 1000000 consumerBacklogSizeGB: 0 testDurationMinutes: 5
这 `messageSize`根据每个用例可能会有所不同。在我们的性能测试中,我们使用了 3K。
我们使用了来自 OMB 的两个不同的驱动程序(Sync 或 Throughput)来在 Kafka 集群上生成工作负载。
-
用于同步驱动程序属性的 yaml 文件如下
(/opt/benchmark/driver- kafka/kafka-sync.yaml):name: Kafka driverClass: io.openmessaging.benchmark.driver.kafka.KafkaBenchmarkDriver # Kafka client-specific configuration replicationFactor: 3 topicConfig: | min.insync.replicas=2 flush.messages=1 flush.ms=0 commonConfig: | bootstrap.servers=172.30.0.121:9092,172.30.0.72:9092,172.30.0.223:9092 producerConfig: | acks=all linger.ms=1 batch.size=1048576 consumerConfig: | auto.offset.reset=earliest enable.auto.commit=false max.partition.fetch.bytes=10485760
-
用于吞吐量驱动程序属性的 yaml 文件如下
(/opt/benchmark/driver- kafka/kafka-throughput.yaml):name: Kafka driverClass: io.openmessaging.benchmark.driver.kafka.KafkaBenchmarkDriver # Kafka client-specific configuration replicationFactor: 3 topicConfig: | min.insync.replicas=2 commonConfig: | bootstrap.servers=172.30.0.121:9092,172.30.0.72:9092,172.30.0.223:9092 default.api.timeout.ms=1200000 request.timeout.ms=1200000 producerConfig: | acks=all linger.ms=1 batch.size=1048576 consumerConfig: | auto.offset.reset=earliest enable.auto.commit=false max.partition.fetch.bytes=10485760
-
测试方法
-
根据上面描述的规范,使用 Terraform 和 Ansible 配置了 Kafka 集群。 Terraform 用于使用 AWS 实例为 Kafka 集群构建基础设施,Ansible 在其上构建 Kafka 集群。
-
使用上面描述的工作负载配置和同步驱动程序触发了 OMB 工作负载。
Sudo bin/benchmark –drivers driver-kafka/kafka- sync.yaml workloads/1-topic-100-partitions-1kb.yaml
-
使用具有相同工作负载配置的吞吐量驱动程序触发了另一个工作负载。
sudo bin/benchmark –drivers driver-kafka/kafka-throughput.yaml workloads/1-topic-100-partitions-1kb.yaml
观察结果
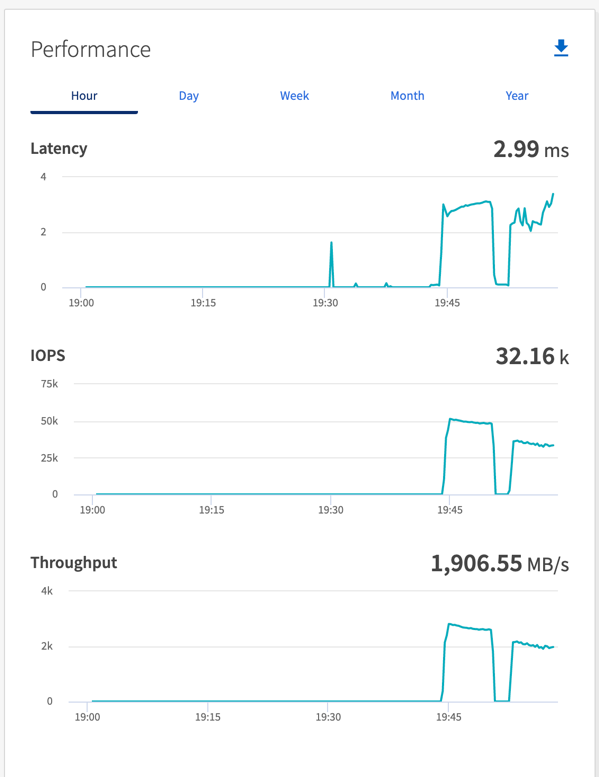
使用两种不同类型的驱动程序来生成工作负载,以对在 NFS 上运行的 Kafka 实例的性能进行基准测试。驱动程序之间的区别在于日志刷新属性。
对于Cloud Volumes ONTAP HA 对:
-
同步驱动程序持续产生的总吞吐量:~1236 MBps。
-
吞吐量驱动程序产生的总吞吐量:峰值~1412 MBps。
对于单个Cloud Volumes ONTAP节点:
-
同步驱动程序持续产生的总吞吐量:~ 1962MBps。
-
吞吐量驱动程序产生的总吞吐量:峰值~1660MBps
由于日志会立即刷新到磁盘,因此同步驱动程序可以生成一致的吞吐量,而由于日志会批量提交到磁盘,因此吞吐量驱动程序会产生突发性的吞吐量。
这些吞吐量数字是针对给定的 AWS 配置生成的。对于更高的性能要求,可以扩大实例类型并进一步调整以获得更好的吞吐量数字。总吞吐量或总速率是生产者和消费者速率的组合。
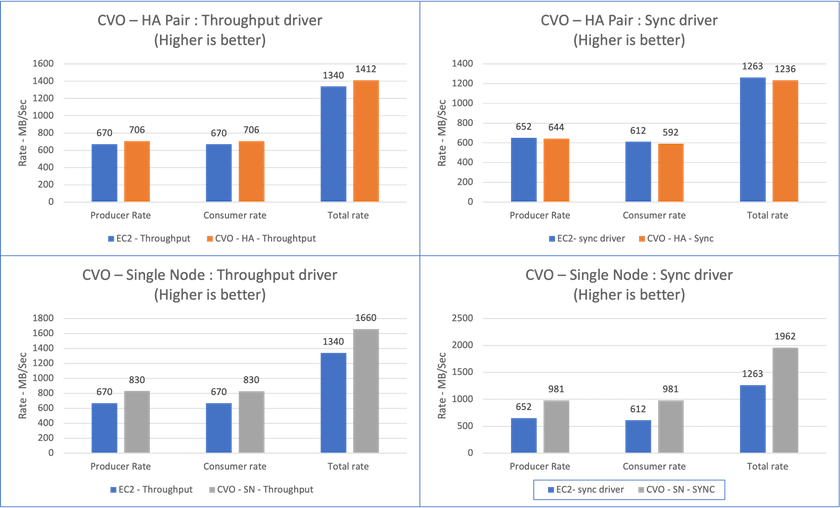
在执行吞吐量或同步驱动程序基准测试时,请务必检查存储吞吐量。