为什么选择NetApp NFS 来支持 Kafka 工作负载?
 建议更改
建议更改
既然有了针对 Kafka 的 NFS 存储中愚蠢重命名问题的解决方案,您就可以创建利用NetApp ONTAP存储来处理 Kafka 工作负载的强大部署。这不仅显著降低了运营开销,还为您的 Kafka 集群带来以下好处:
-
*降低 Kafka 代理的 CPU 利用率。*使用分解的NetApp ONTAP存储将磁盘 I/O 操作与代理分离,从而减少其 CPU 占用。
-
*更快的经纪人恢复时间。*由于分解的NetApp ONTAP存储在 Kafka 代理节点之间共享,因此与传统的 Kafka 部署相比,新的计算实例可以在很短的时间内随时替换损坏的代理,而无需重建数据。
-
*存储效率。*由于应用程序的存储层现在是通过NetApp ONTAP进行配置的,因此客户可以利用ONTAP带来的所有存储效率优势,例如线内数据压缩、重复数据删除和压缩。
这些好处在本节我们将详细讨论的测试案例中得到了测试和验证。
降低 Kafka 代理的 CPU 利用率
我们发现,当我们在两个技术规格相同但存储技术不同的独立 Kafka 集群上运行类似的工作负载时,整体 CPU 利用率低于其 DAS 对应集群。当 Kafka 集群使用ONTAP存储时,不仅整体 CPU 利用率较低,而且 CPU 利用率的增加比基于 DAS 的 Kafka 集群表现出更平缓的梯度。
建筑设置
下表显示了用于演示降低 CPU 利用率的环境配置。
| 平台组件 | 环境配置 |
|---|---|
Kafka 3.2.3 基准测试工具:OpenMessaging |
|
所有节点上的操作系统 |
RHEL 8.7 或更高版本 |
NetApp Cloud Volumes ONTAP实例 |
单节点实例 – M5.2xLarge |
基准测试工具
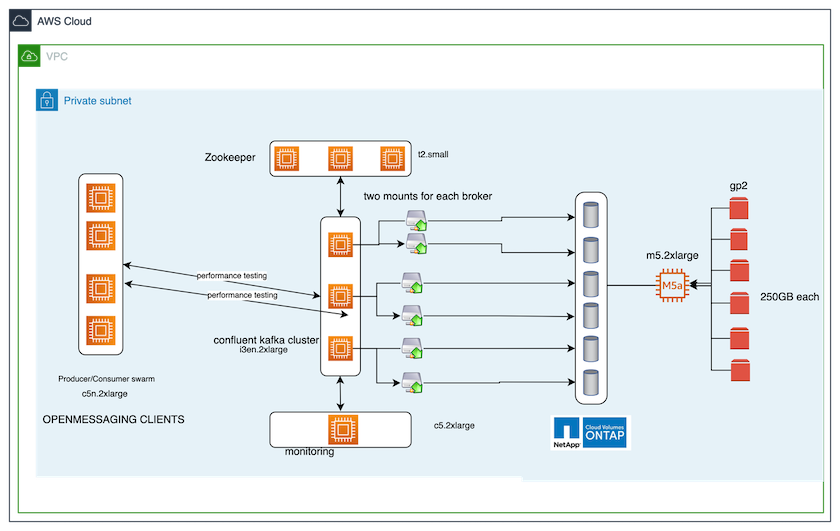
本测试用例中使用的基准测试工具是 "开放消息传递"框架。 OpenMessaging 与供应商无关且与语言无关;它为金融、电子商务、物联网和大数据提供行业指南;并有助于开发跨异构系统和平台的消息传递和流媒体应用程序。下图描述了 OpenMessaging 客户端与 Kafka 集群的交互。
-
*计算。*我们使用了三节点 Kafka 集群,并在专用服务器上运行三节点 zookeeper 集合。每个代理通过专用 LIF 拥有两个 NFSv4.1 挂载点,指向NetApp CVO 实例上的单个卷。
-
*监控*我们使用两个节点来实现 Prometheus-Grafana 组合。为了生成工作负载,我们有一个单独的三节点集群,可以从该 Kafka 集群中生产和消费。
-
*贮存。*我们使用了单节点NetApp Cloud Volumes ONTAP实例,该实例上安装了六个 250GB GP2 AWS-EBS 卷。然后,这些卷通过专用 LIF 作为六个 NFSv4.1 卷公开给 Kafka 集群。
-
*配置。*该测试用例中的两个可配置元素是 Kafka 代理和 OpenMessaging 工作负载。
-
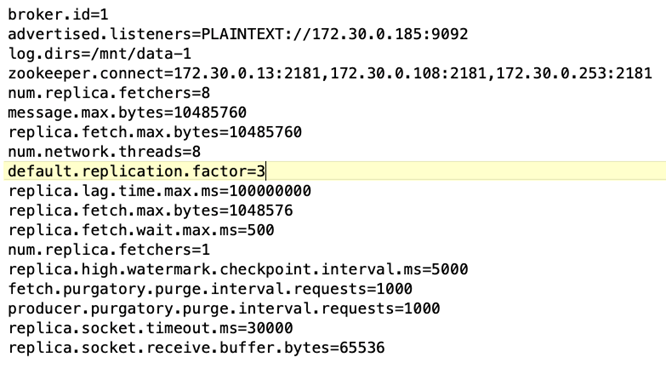
*经纪人配置*为 Kafka 代理选择了以下规格。我们对所有测量使用了 3 的重复因子,如下所示。
-
-
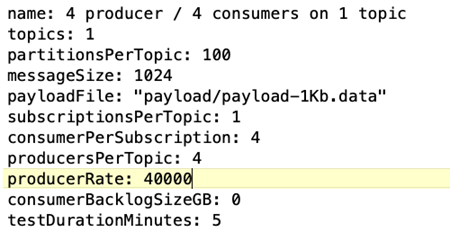
OpenMessaging 基准 (OMB) 工作负载配置。*提供了以下规格。我们指定了目标生产率,如下所示。
测试方法
-
创建了两个类似的集群,每个集群都有自己的一组基准集群群。
-
*集群 1.*基于NFS的Kafka集群。
-
*集群 2.*基于DAS的Kafka集群。
-
-
使用 OpenMessaging 命令,每个集群上都会触发类似的工作负载。
sudo bin/benchmark --drivers driver-kafka/kafka-group-all.yaml workloads/1-topic-100-partitions-1kb.yaml
-
生产率配置在四次迭代中增加,并使用 Grafana 记录 CPU 利用率。生产率设定为以下水平:
-
10,000
-
40,000
-
80,000
-
100,000
-
观察结果
将NetApp NFS 存储与 Kafka 结合使用有两个主要好处:
-
*您可以将 CPU 使用率降低近三分之一。*与 DAS SSD 相比,相似工作负载下 NFS 的总体 CPU 使用率较低;节省范围从较低生产率的 5% 到较高生产率的 32%。
-
*在更高的生产率下,CPU 利用率漂移减少了三倍。*正如预期的那样,随着生产率的提高,CPU 利用率呈上升趋势。然而,使用 DAS 的 Kafka 代理的 CPU 利用率从较低生产率时的 31% 上升到较高生产率时的 70%,增幅为 39%。然而,有了 NFS 存储后端,CPU 利用率从 26% 上升到 38%,增加了 12%。
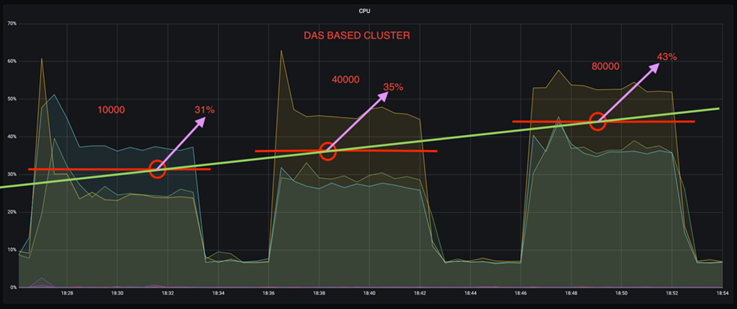
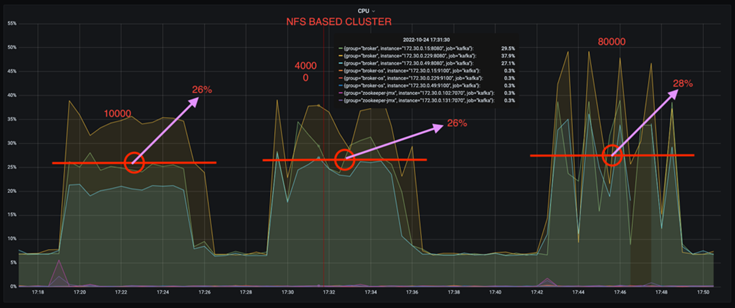
此外,在 100,000 条消息时,DAS 显示的 CPU 利用率比 NFS 集群更高。
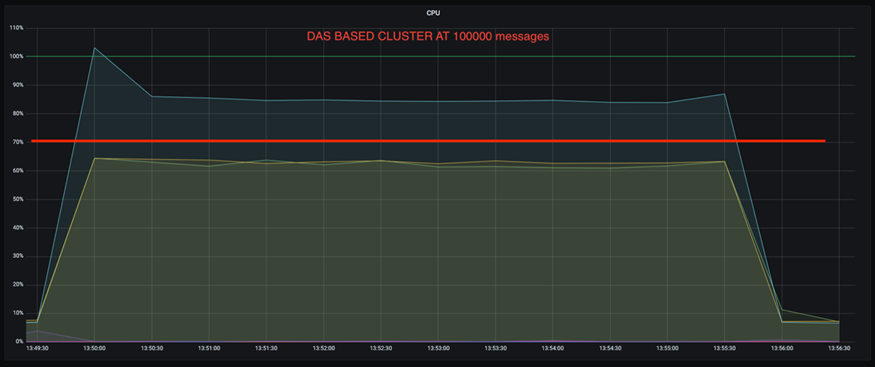
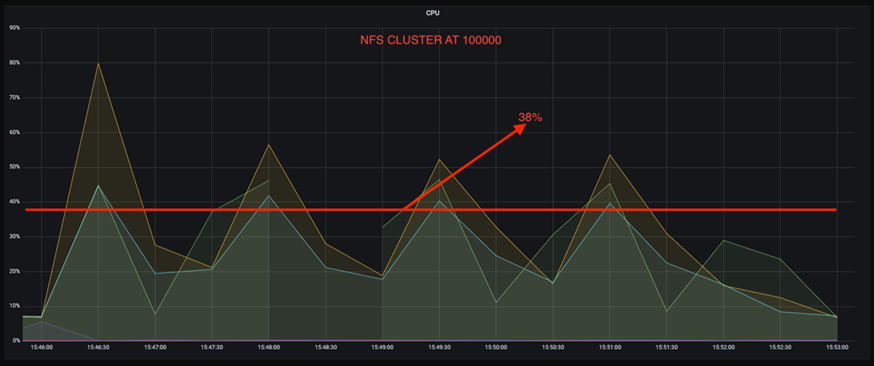
更快的经纪人恢复
我们发现,当 Kafka 代理使用共享NetApp NFS 存储时,恢复速度更快。当 Kafka 集群中某个 Broker 崩溃时,可以用具有相同 Broker ID 的健康 Broker 替代该 Broker。在执行此测试用例时,我们发现,对于基于 DAS 的 Kafka 集群,集群会在新添加的健康 Broker 上重建数据,这非常耗时。对于基于NetApp NFS 的 Kafka 集群,替换代理将继续从以前的日志目录读取数据,并且恢复速度更快。
建筑设置
下表展示了使用NAS的Kafka集群的环境配置。
| 平台组件 | 环境配置 |
|---|---|
卡夫卡 3.2.3 |
|
所有节点上的操作系统 |
RHEL8.7 或更高版本 |
NetApp Cloud Volumes ONTAP实例 |
单节点实例 – M5.2xLarge |
下图是基于NAS的Kafka集群架构图。
-
*计算。*一个三节点 Kafka 集群,带有一个三节点 zookeeper 集合,在专用服务器上运行。每个代理通过专用 LIF 拥有两个指向NetApp CVO 实例上的单个卷的 NFS 挂载点。
-
监控 Prometheus-Grafana 组合的两个节点。为了生成工作负载,我们使用一个单独的三节点集群,该集群可以为该 Kafka 集群生产和消费。
-
*贮存。*单节点NetApp Cloud Volumes ONTAP实例,实例上安装了六个 250GB GP2 AWS-EBS 卷。然后,这些卷通过专用 LIF 作为六个 NFS 卷公开给 Kafka 集群。
-
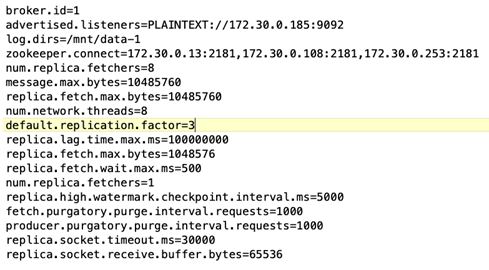
*经纪人配置。*此测试用例中一个可配置元素是 Kafka 代理。为 Kafka 代理选择了以下规格。这 `replica.lag.time.mx.ms`设置为较高的值,因为这决定了特定节点从 ISR 列表中取出的速度。当您在坏节点和健康节点之间切换时,您不希望该代理 ID 被排除在 ISR 列表中。
测试方法
-
创建了两个类似的集群:
-
基于 EC2 的汇合集群。
-
基于NetApp NFS 的汇合集群。
-
-
创建了一个备用 Kafka 节点,其配置与原始 Kafka 集群中的节点相同。
-
在每个集群上,都创建了一个示例主题,并且在每个代理上填充了大约 110GB 的数据。
-
基于 EC2 的集群。 Kafka 代理数据目录映射到
/mnt/data-2(下图中 cluster1 的 Broker-1[左侧终端])。 -
基于NetApp NFS 的集群。 Kafka 代理数据目录安装在 NFS 点上
/mnt/data(下图中 cluster2 的 Broker-1【右侧终端】)。
-
-
在每个集群中,Broker-1 被终止以触发失败的代理恢复过程。
-
代理终止后,代理 IP 地址被分配作为备用代理的辅助 IP。这是必要的,因为 Kafka 集群中的代理通过以下方式标识:
-
*IP 地址。*通过将发生故障的代理 IP 重新分配给备用代理来进行分配。
-
*经纪人ID*这是在备用代理中配置的
server.properties。
-
-
分配 IP 后,备用代理上启动了 Kafka 服务。
-
过了一会儿,拉取服务器日志来检查在集群中的替换节点上构建数据所花费的时间。
观察结果
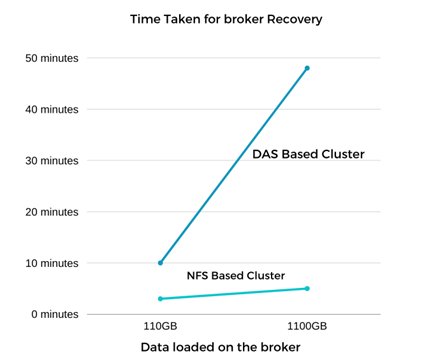
Kafka 代理的恢复速度几乎提高了 9 倍。与在 Kafka 集群中使用 DAS SSD 相比,使用NetApp NFS 共享存储时恢复故障代理节点所需的时间明显更快。对于 1TB 的主题数据,基于 DAS 的集群的恢复时间为 48 分钟,而基于NetApp-NFS 的 Kafka 集群的恢复时间则不到 5 分钟。
我们观察到基于 EC2 的集群花费 10 分钟在新代理节点上重建 110GB 数据,而基于 NFS 的集群在 3 分钟内完成恢复。我们还在日志中观察到,EC2 分区的消费者偏移量为 0,而在 NFS 集群上,消费者偏移量是从前一个代理获取的。
[2022-10-31 09:39:17,747] INFO [LogLoader partition=test-topic-51R3EWs-0000-55, dir=/mnt/kafka-data/broker2] Reloading from producer snapshot and rebuilding producer state from offset 583999 (kafka.log.UnifiedLog$) [2022-10-31 08:55:55,170] INFO [LogLoader partition=test-topic-qbVsEZg-0000-8, dir=/mnt/data-1] Loading producer state till offset 0 with message format version 2 (kafka.log.UnifiedLog$)
基于DAS的集群
-
备份节点于 08:55:53,730 启动。

-
数据重建过程于 09:05:24,860 结束。处理 110GB 的数据大约需要 10 分钟。

基于NFS的集群
-
备份节点于 09:39:17,213 启动。下面突出显示了起始日志条目。

-
数据重建过程于 09:42:29,115 结束。处理 110GB 的数据大约需要 3 分钟。

对包含约 1TB 数据的代理重复了测试,对于 DAS 大约需要 48 分钟,对于 NFS 大约需要 3 分钟。结果如下图所示。
存储效率
由于 Kafka 集群的存储层是通过NetApp ONTAP配置的,因此我们获得了ONTAP的所有存储效率功能。这是通过在Cloud Volumes ONTAP上配置 NFS 存储的 Kafka 集群上生成大量数据进行的测试。我们可以看到,由于ONTAP功能,空间显著减少。
建筑设置
下表展示了使用NAS的Kafka集群的环境配置。
| 平台组件 | 环境配置 |
|---|---|
卡夫卡 3.2.3 |
|
所有节点上的操作系统 |
RHEL8.7 或更高版本 |
NetApp Cloud Volumes ONTAP实例 |
单节点实例 – M5.2xLarge |
下图是基于NAS的Kafka集群架构图。
-
*计算。*我们使用了三节点 Kafka 集群,并在专用服务器上运行三节点 zookeeper 集合。每个代理通过专用 LIF 拥有两个指向NetApp CVO 实例上的单个卷的 NFS 挂载点。
-
*监控*我们使用两个节点来实现 Prometheus-Grafana 组合。为了生成工作负载,我们使用了一个单独的三节点集群,该集群可以为该 Kafka 集群生产和消费。
-
*贮存。*我们使用了单节点NetApp Cloud Volumes ONTAP实例,该实例上安装了六个 250GB GP2 AWS-EBS 卷。然后,这些卷通过专用 LIF 作为六个 NFS 卷公开给 Kafka 集群。
-
*配置。*该测试用例中的可配置元素是 Kafka 代理。
生产者端的压缩被关闭,从而使生产者能够产生高吞吐量。存储效率由计算层处理。
测试方法
-
已按照上述规格配置了 Kafka 集群。
-
在集群上,使用 OpenMessaging Benchmarking 工具产生了大约 350GB 的数据。
-
工作负载完成后,使用ONTAP系统管理器和 CLI 收集存储效率统计数据。
观察结果
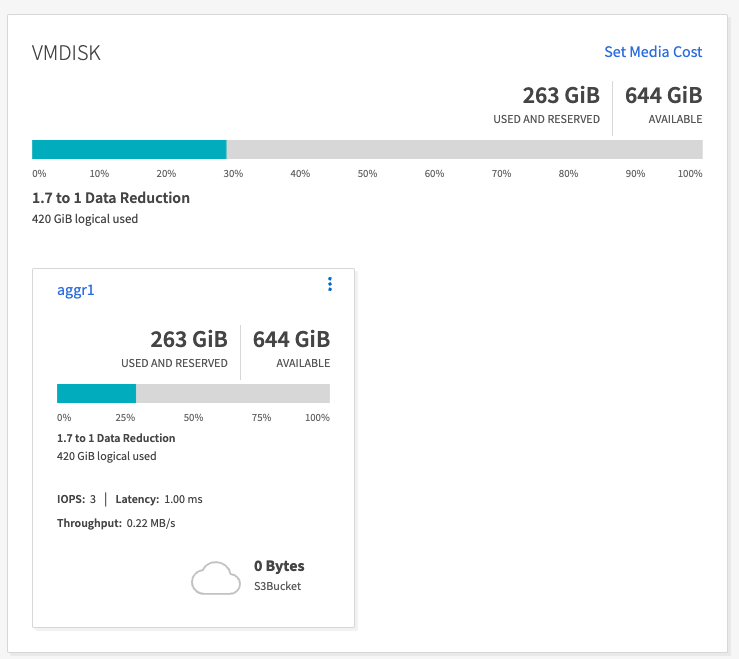
对于使用 OMB 工具生成的数据,我们发现空间节省了约 33%,存储效率比为 1.70:1。如下图所示,产生的数据所使用的逻辑空间为420.3GB,用于保存数据的物理空间为281.7GB。