

技术概述
 建议更改
建议更改
本节重点介绍NetApp的 OpenSource MLOps 技术概述。
人工智能
人工智能是一门计算机科学学科,其中计算机经过训练可以模仿人类思维的认知功能。人工智能开发人员训练计算机以类似于人类甚至优于人类的方式学习和解决问题。深度学习和机器学习是人工智能的子领域。越来越多的组织采用 AI、ML 和 DL 来支持其关键业务需求。以下是一些示例:
-
分析大量数据以发掘以前未知的商业见解
-
使用自然语言处理直接与客户互动
-
自动化各种业务流程和功能
现代人工智能训练和推理工作负载需要大规模并行计算能力。因此,GPU 越来越多地被用于执行 AI 操作,因为 GPU 的并行处理能力远远优于通用 CPU。
容器
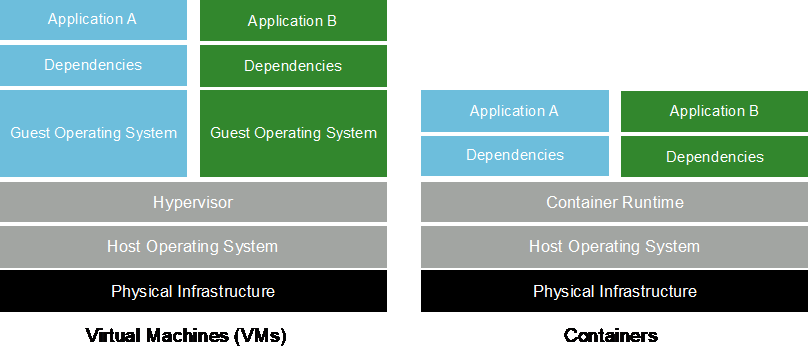
容器是在共享主机操作系统内核上运行的隔离的用户空间实例。容器的采用正在迅速增加。容器提供许多与虚拟机 (VM) 相同的应用程序沙盒优势。然而,由于虚拟机所依赖的虚拟机管理程序和客户操作系统层已被消除,因此容器变得更加轻量级。下图描述了虚拟机与容器的可视化。
容器还允许直接将应用程序依赖项、运行时间等与应用程序高效地打包在一起。最常用的容器打包格式是Docker容器。以 Docker 容器格式容器化的应用程序可以在任何可以运行 Docker 容器的机器上执行。即使应用程序的依赖项不存在于机器上,情况也是如此,因为所有依赖项都打包在容器本身中。欲了解更多信息,请访问 "Docker 网站"。
Kubernetes
Kubernetes 是一个开源的、分布式的容器编排平台,最初由 Google 设计,现在由云原生计算基金会 (CNCF) 维护。 Kubernetes 支持容器化应用程序的部署、管理和扩展功能的自动化。近年来,Kubernetes 已经成为主流的容器编排平台。欲了解更多信息,请访问 "Kubernetes 网站"。
NetApp Trident
"Trident"支持在所有流行的NetApp存储平台上(公共云或内部)使用和管理存储资源,包括ONTAP (AFF、 FAS、Select、Cloud、 Amazon FSx ONTAP)、 Azure NetApp Files服务和Google Cloud NetApp Volumes。 Trident是一个符合容器存储接口 (CSI) 的动态存储编排器,可与 Kubernetes 原生集成。
NetApp DataOps 工具包
这"NetApp DataOps 工具包"是一个基于 Python 的工具,可简化由高性能、横向扩展NetApp存储支持的开发/培训工作区和推理服务器的管理。主要功能包括:
-
快速配置由高性能、横向扩展NetApp存储支持的全新高容量工作区。
-
近乎即时地克隆高容量工作区,以实现实验或快速迭代。
-
近乎即时地保存高容量工作区的快照,以用于备份和/或可追溯性/基准测试。
-
近乎即时地提供、克隆和快照大容量、高性能数据卷。
Apache Airflow
Apache Airflow 是一个开源工作流管理平台,支持以编程方式编写、调度和监控复杂的企业工作流。它通常用于自动化 ETL 和数据管道工作流程,但并不局限于这些类型的工作流程。 Airflow 项目由 Airbnb 发起,但后来在业界变得非常流行,现在由 Apache 软件基金会赞助。 Airflow 是用 Python 编写的,Airflow 工作流是通过 Python 脚本创建的,并且 Airflow 是在“配置即代码”的原则下设计的。许多企业 Airflow 用户现在在 Kubernetes 上运行 Airflow。
有向无环图(DAG)
在 Airflow 中,工作流被称为有向无环图 (DAG)。 DAG 由按顺序、并行或两者结合执行的任务组成,具体取决于 DAG 定义。 Airflow 调度程序在一组工作器上执行各个任务,遵守 DAG 定义中指定的任务级依赖关系。 DAG 是通过 Python 脚本定义和创建的。
Jupyter 笔记本
Jupyter Notebooks 是类似 wiki 的文档,包含实时代码和描述性文本。 Jupyter Notebooks 在 AI 和 ML 社区中被广泛用作记录、存储和共享 AI 和 ML 项目的一种方式。有关 Jupyter Notebooks 的更多信息,请访问 "Jupyter 网站"。
Jupyter Notebook 服务器
Jupyter Notebook 服务器是一个开源 Web 应用程序,允许用户创建 Jupyter Notebook。
JupyterHub
JupyterHub 是一个多用户应用程序,允许个人用户配置和访问他们自己的 Jupyter Notebook 服务器。有关 JupyterHub 的更多信息,请访问 "JupyterHub 网站"。
机器学习流
MLflow 是一个流行的开源 AI 生命周期管理平台。 MLflow 的主要功能包括 AI/ML 实验跟踪和 AI/ML 模型库。有关 MLflow 的更多信息,请访问 "MLflow 网站"。
Kubeflow
Kubeflow 是 Kubernetes 的开源 AI 和 ML 工具包,最初由 Google 开发。 Kubeflow 项目使 Kubernetes 上 AI 和 ML 工作流的部署变得简单、可移植且可扩展。 Kubeflow 抽象了 Kubernetes 的复杂性,使数据科学家能够专注于他们最了解的领域——数据科学。请参见下图以了解可视化效果。对于喜欢一体化 MLOps 平台的组织来说,Kubeflow 是一个不错的开源选择。欲了解更多信息,请访问 "Kubeflow 网站"。
Kubeflow 管道
Kubeflow Pipelines 是 Kubeflow 的关键组件。 Kubeflow Pipelines 是一个用于定义和部署可移植、可扩展的 AI 和 ML 工作流的平台和标准。有关详细信息,请参阅 "Kubeflow 官方文档"。
Kubeflow 笔记本
Kubeflow 简化了 Kubernetes 上 Jupyter Notebook 服务器的配置和部署。有关 Kubeflow 上下文中的 Jupyter Notebooks 的更多信息,请参阅 "Kubeflow 官方文档"。
卡提布
Katib 是一个用于自动化机器学习 (AutoML) 的 Kubernetes 原生项目。 Katib 支持超参数调整、早期停止和神经架构搜索 (NAS)。 Katib 是一个与机器学习 (ML) 框架无关的项目。它可以调整用户选择的任何语言编写的应用程序的超参数,并且原生支持许多 ML 框架,例如 TensorFlow、MXNet、PyTorch、XGBoost 等。 Katib 支持许多不同的 AutoML 算法,例如贝叶斯优化、Parzen 估计器树、随机搜索、协方差矩阵自适应进化策略、超频、高效神经架构搜索、可微分架构搜索等等。有关 Kubeflow 上下文中的 Jupyter Notebooks 的更多信息,请参阅 "Kubeflow 官方文档"。
NetApp ONTAP
ONTAP 9 是NetApp最新一代存储管理软件,它支持企业实现基础架构现代化并过渡到云就绪数据中心。 ONTAP利用业界领先的数据管理功能,只需一套工具即可管理和保护数据,无论数据位于何处。您还可以将数据自由移动到任何需要的地方:边缘、核心或云端。 ONTAP 9 包含众多功能,可简化数据管理、加速和保护关键数据,并支持跨混合云架构的下一代基础架构功能。
简化数据管理
数据管理对于企业 IT 运营和数据科学家至关重要,以便将适当的资源用于 AI 应用程序和训练 AI/ML 数据集。以下有关NetApp技术的附加信息超出了本次验证的范围,但可能与您的部署相关。
ONTAP数据管理软件包括以下功能,可简化操作并降低总运营成本:
-
内联数据压缩和扩展重复数据删除。数据压缩减少了存储块内部浪费的空间,重复数据删除显著增加了有效容量。这适用于本地存储的数据和分层到云的数据。
-
最小、最大和自适应服务质量 (AQoS)。细粒度的服务质量 (QoS) 控制有助于维持高度共享环境中关键应用程序的性能水平。
-
NetApp FabricPool。提供冷数据自动分层到公共和私有云存储选项,包括 Amazon Web Services (AWS)、Azure 和NetApp StorageGRID存储解决方案。有关FabricPool的更多信息,请参阅 "TR-4598: FabricPool最佳实践"。
加速并保护数据
ONTAP提供卓越级别的性能和数据保护,并通过以下方式扩展这些功能:
-
性能和更低的延迟。 ONTAP以尽可能低的延迟提供尽可能高的吞吐量。
-
数据保护。ONTAP提供内置数据保护功能,并在所有平台上提供通用管理。
-
NetApp卷加密 (NVE)。 ONTAP提供原生卷级加密,同时支持板载和外部密钥管理。
-
多租户和多因素身份验证。 ONTAP支持以最高级别的安全性共享基础设施资源。
面向未来的基础设施
ONTAP具有以下功能,可帮助满足苛刻且不断变化的业务需求:
-
无缝扩展和无中断运行。 ONTAP支持无中断地向现有控制器和横向扩展集群添加容量。客户可以升级到最新技术,而无需昂贵的数据迁移或中断。
-
云连接。 ONTAP是与云连接最紧密的存储管理软件,在所有公共云中提供软件定义存储和云原生实例的选项。
-
与新兴应用程序的集成。 ONTAP使用支持现有企业应用的相同基础架构,为下一代平台和应用(如自动驾驶汽车、智能城市和工业 4.0)提供企业级数据服务。
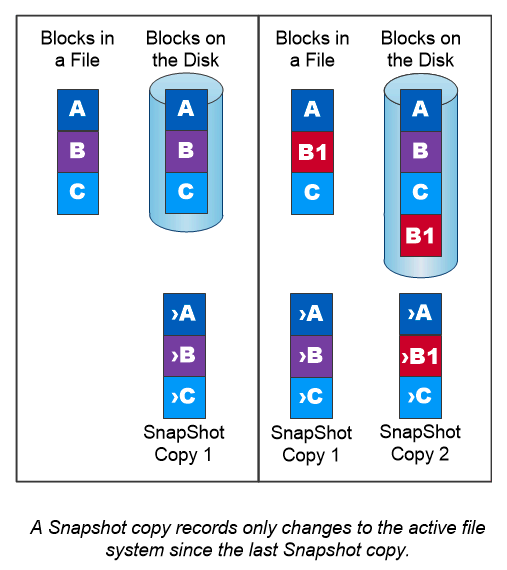
NetApp Snapshot 副本
NetApp Snapshot 副本是卷的只读、时间点映像。该图像占用的存储空间极小,并且产生的性能开销可以忽略不计,因为它仅记录自上次 Snapshot 副本创建以来对文件的更改,如下图所示。
Snapshot 副本的效率归功于核心ONTAP存储虚拟化技术,即任意位置写入文件布局 (WAFL)。与数据库一样, WAFL使用元数据指向磁盘上的实际数据块。但是,与数据库不同, WAFL不会覆盖现有块。它将更新的数据写入新块并更改元数据。这是因为ONTAP在创建 Snapshot 副本时引用元数据,而不是复制数据块,所以 Snapshot 副本非常高效。这样做可以消除其他系统在定位要复制的块时产生的寻道时间,以及复制本身的成本。
您可以使用 Snapshot 副本来恢复单个文件或 LUN,或者还原卷的全部内容。 ONTAP将 Snapshot 副本中的指针信息与磁盘上的数据进行比较,以重建丢失或损坏的对象,而无需停机或造成显著的性能成本。
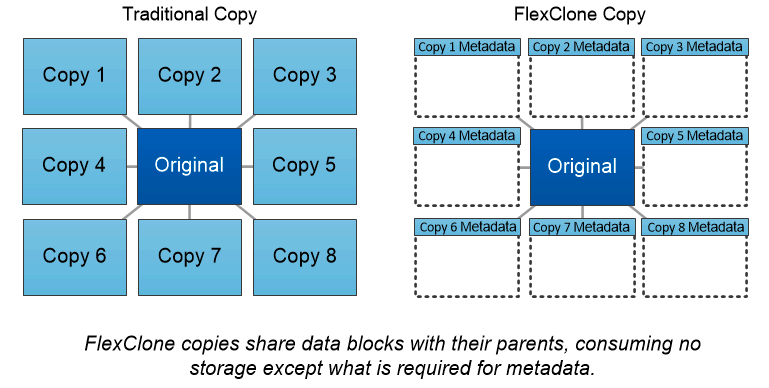
NetApp FlexClone 技术
NetApp FlexClone技术参考 Snapshot 元数据来创建卷的可写时间点副本。副本与其父级共享数据块,除了元数据所需的存储空间外,不消耗任何存储空间,直到将更改写入副本为止,如下图所示。传统的复制可能需要几分钟甚至几小时才能创建,而FlexClone软件可以让您几乎立即复制最大的数据集。这使得它非常适合需要相同数据集的多个副本(例如,开发工作区)或数据集的临时副本(针对生产数据集测试应用程序)的情况。
NetApp SnapMirror数据复制技术
NetApp SnapMirror软件是一种跨数据结构的经济高效、易于使用的统一复制解决方案。它通过 LAN 或 WAN 高速复制数据。它为所有类型的应用程序(包括虚拟和传统环境中的关键业务应用程序)提供高数据可用性和快速数据复制。当您将数据复制到一个或多个NetApp存储系统并不断更新辅助数据时,您的数据将保持最新状态并可随时使用。不需要外部复制服务器。下图是利用SnapMirror技术的架构示例。
SnapMirror软件通过网络仅发送更改的块来利用NetApp ONTAP存储效率。 SnapMirror软件还使用内置网络压缩来加速数据传输并将网络带宽利用率降低高达 70%。借助SnapMirror技术,您可以利用一个精简复制数据流来创建一个存储库,该存储库同时维护活动镜像和之前的时间点副本,从而将网络流量减少高达 50%。
NetApp BlueXP复制和同步
"BlueXP复制和同步"是NetApp 的一项快速、安全的数据同步服务。无论您需要在本地 NFS 或 SMB 文件共享、 NetApp StorageGRID、 NetApp ONTAP S3、 Google Cloud NetApp Volumes、 Azure NetApp Files、AWS S3、AWS EFS、Azure Blob、Google Cloud Storage 还是 IBM Cloud Object Storage 之间传输文件, BlueXP Copy and Sync 都能快速安全地将文件移动到您需要的位置。
数据传输完成后,可在源端和目标端完全使用。 BlueXP Copy and Sync 可以在触发更新时按需同步数据,或者根据预定义的时间表连续同步数据。无论如何, BlueXP Copy and Sync 仅移动增量,因此在数据复制上花费的时间和金钱被最小化。
BlueXP Copy and Sync 是一种软件即服务 (SaaS) 工具,其设置和使用极其简单。 BlueXP Copy 和 Sync 触发的数据传输由数据代理执行。 BlueXP Copy 和 Sync 数据代理可以部署在 AWS、Azure、Google Cloud Platform 或本地。
NetApp XCP
"NetApp XCP"是一款基于客户端的软件,用于任意到NetApp和NetApp到NetApp 的数据迁移和文件系统洞察。 XCP 旨在通过利用所有可用的系统资源来处理大容量数据集和高性能迁移,从而实现扩展并实现最大性能。 XCP 可帮助您全面了解文件系统,并提供生成报告的选项。
NetApp ONTAP FlexGroup卷
训练数据集可能包含数十亿个文件。文件可以包括文本、音频、视频和其他形式的非结构化数据,这些数据必须存储和处理才能并行读取。存储系统必须存储大量小文件,并且必须并行读取这些文件以实现顺序和随机 I/O。
FlexGroup卷是一个由多个组成成员卷组成的单一命名空间,如下图所示。从存储管理员的角度来看, FlexGroup卷的管理和行为类似于NetApp FlexVol volume。 FlexGroup卷中的文件被分配给各个成员卷,并且不会跨卷或节点进行条带化。它们支持以下功能:
-
FlexGroup卷为高元数据工作负载提供了数 PB 的容量和可预测的低延迟。
-
它们支持同一命名空间中最多 4000 亿个文件。
-
它们支持跨 CPU、节点、聚合体和组成FlexVol卷的 NAS 工作负载的并行操作。
