

矢量数据库
 建议更改
建议更改
本节介绍NetApp AI 解决方案中向量数据库的定义和使用。
矢量数据库
矢量数据库是一种特殊类型的数据库,旨在使用机器学习模型的嵌入来处理、索引和搜索非结构化数据。它不以传统的表格格式组织数据,而是将数据排列为高维向量,也称为向量嵌入。这种独特的结构使得数据库能够更高效、更准确地处理复杂、多维的数据。
矢量数据库的关键功能之一是使用生成式人工智能进行分析。这包括相似性搜索,其中数据库识别类似于给定输入的数据点,以及异常检测,其中它可以发现与常态有显著偏差的数据点。
此外,矢量数据库非常适合处理时间数据或带时间戳的数据。这种类型的数据提供了有关“发生了什么”以及何时发生的信息,按顺序以及与给定 IT 系统中所有其他事件的关系。这种处理和分析时间数据的能力使得矢量数据库对于需要了解随时间推移的事件的应用程序特别有用。
矢量数据库对于ML和AI的优势:
-
高维搜索:向量数据库擅长管理和检索高维数据,这些数据通常在 AI 和 ML 应用程序中生成。
-
可扩展性:它们可以有效扩展以处理大量数据,支持 AI 和 ML 项目的增长和扩展。
-
灵活性:矢量数据库具有高度的灵活性,可以适应多种数据类型和结构。
-
性能:它们提供高性能数据管理和检索,这对于 AI 和 ML 操作的速度和效率至关重要。
-
可定制的索引:矢量数据库提供可定制的索引选项,从而能够根据特定需求优化数据组织和检索。
矢量数据库和用例。
本节提供各种矢量数据库及其用例详细信息。
Faiss和ScaNN
它们是向量搜索领域中的重要工具库。这些库提供的功能有助于管理和搜索矢量数据,使其成为数据管理这一专业领域的宝贵资源。
Elasticsearch
它是一种广泛使用的搜索和分析引擎,最近加入了矢量搜索功能。此新功能增强了其功能,使其能够更有效地处理和搜索矢量数据。
松果
它是一个具有一组独特功能的强大矢量数据库。它的索引功能同时支持密集和稀疏向量,从而增强了其灵活性和适应性。它的主要优势之一在于能够将传统搜索方法与基于人工智能的密集矢量搜索相结合,从而创造出一种兼具两全其美的混合搜索方法。
Pinecone 主要基于云,专为机器学习应用而设计,可与各种平台良好集成,包括 GCP、AWS、Open AI、GPT-3、GPT-3.5、GPT-4、Catgut Plus、Elasticsearch、Haystack 等。值得注意的是,Pinecone 是一个闭源平台,可作为软件即服务 (SaaS) 产品使用。
鉴于其先进的功能,Pinecone 特别适合网络安全行业,其高维搜索和混合搜索功能可以有效地利用来检测和应对威胁。
色度
它是一个矢量数据库,具有包含四个主要功能的核心 API,其中一个功能包括内存文档矢量存储。它还利用 Face Transformers 库来矢量化文档,增强其功能和多功能性。 Chroma 的设计可在云端和本地运行,可根据用户需求提供灵活性。特别是在音频相关应用方面表现出色,使其成为基于音频的搜索引擎、音乐推荐系统和其他音频相关用例的绝佳选择。
威维特
它是一个多功能矢量数据库,允许用户使用其内置模块或自定义模块矢量化其内容,根据特定需求提供灵活性。它提供完全托管和自托管解决方案,满足各种部署偏好。
Weaviate 的主要功能之一是它能够同时存储矢量和对象,从而增强其数据处理能力。它广泛应用于一系列应用,包括 ERP 系统中的语义搜索和数据分类。在电子商务领域,它为搜索和推荐引擎提供支持。 Weaviate 还用于图像搜索、异常检测、自动数据协调和网络安全威胁分析,展示了其在多个领域的多功能性。
Redis
Redis 是一种高性能矢量数据库,以其快速的内存存储而闻名,可为读写操作提供低延迟。这使其成为需要快速数据访问的推荐系统、搜索引擎和数据分析应用程序的绝佳选择。
Redis 支持向量的各种数据结构,包括列表、集合和有序集。它还提供矢量运算,例如计算矢量之间的距离或查找交集和并集。这些功能对于相似性搜索、聚类和基于内容的推荐系统特别有用。
在可扩展性和可用性方面,Redis 擅长处理高吞吐量工作负载并提供数据复制。它还可以与其他数据类型很好地集成,包括传统的关系数据库(RDBMS)。 Redis 包含一个用于实时更新的发布/订阅(Pub/Sub)功能,这有利于管理实时向量。此外,Redis 轻量级且易于使用,使其成为管理矢量数据的用户友好型解决方案。
Milvus
它是一个多功能的矢量数据库,提供类似文档存储的 API,非常类似于 MongoDB。它因支持多种数据类型而脱颖而出,成为数据科学和机器学习领域的热门选择。
Milvus 的独特功能之一是其多矢量化功能,它允许用户在运行时指定用于搜索的矢量类型。此外,它利用 Knowwhere(一个位于 Faiss 等其他库之上的库)来管理查询和向量搜索算法之间的通信。
由于与 PyTorch 和 TensorFlow 兼容,Milvus 还提供与机器学习工作流程的无缝集成。这使其成为一系列应用的绝佳工具,包括电子商务、图像和视频分析、对象识别、图像相似性搜索和基于内容的图像检索。在自然语言处理领域,Milvus 用于文档聚类、语义搜索和问答系统。
对于这个解决方案,我们选择了 milvus 进行解决方案验证。为了提高性能,我们同时使用了 milvus 和 postgres(pgvecto.rs)。
为什么我们选择 milvus 作为这个解决方案?
-
开源:Milvus 是一个开源矢量数据库,鼓励社区驱动的开发和改进。
-
AI 集成:它利用嵌入相似性搜索和 AI 应用程序来增强矢量数据库功能。
-
大容量处理:Milvus 有能力存储、索引和管理由深度神经网络 (DNN) 和机器学习 (ML) 模型生成的超过十亿个嵌入向量。
-
用户友好:易于使用,设置只需不到一分钟。 Milvus 还为不同的编程语言提供 SDK。
-
速度:它提供极快的检索速度,比一些替代方案快 10 倍。
-
可扩展性和可用性:Milvus 具有高度可扩展性,可以根据需要进行扩展和缩小。
-
功能丰富:它支持不同的数据类型、属性过滤、用户定义函数 (UDF) 支持、可配置的一致性级别和旅行时间,使其成为各种应用的多功能工具。
Milvus 架构概述
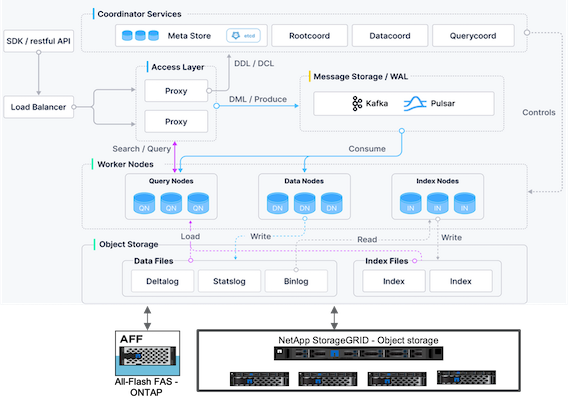
本节提供 Milvus 架构中使用的更高级别的组件和服务。 * 访问层——由一组无状态代理组成,作为系统的前端层和用户的端点。 * 协调器服务——它将任务分配给工作节点并充当系统的大脑。它有三种协调器类型:根协调器、数据协调器和查询协调器。 * 工作节点:它遵循协调服务的指令并执行用户触发的DML / DDL命令。它有三种类型的工作节点,例如查询节点,数据节点和索引节点。 * 存储:负责数据持久化。它包括元存储、日志代理和对象存储。 NetApp存储(例如ONTAP和StorageGRID)为 Milvus 提供对象存储和基于文件的存储,用于客户数据和矢量数据库数据。