

关闭和启动MetroCluster IP配置中的单个站点
 建议更改
建议更改
如果您需要在MetroCluster IP配置中执行站点维护或重新定位单个站点、则必须了解如何关闭和启动该站点。
如果需要重新定位和重新配置站点(例如、如果需要从四节点集群扩展为八节点集群)、则无法同时完成这些任务。此操作步骤仅介绍在不更改站点配置的情况下执行站点维护或重新定位站点所需的步骤。
下图显示了 MetroCluster 配置。cluster_B已关闭以进行维护。
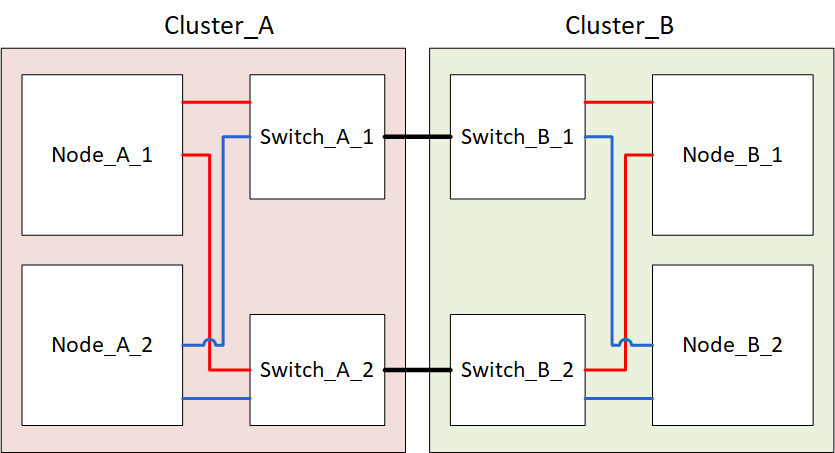
关闭MetroCluster站点
必须先关闭站点和所有设备,然后才能开始站点维护或重新定位。
以下步骤中的所有命令都是从仍保持通电的站点发出的。
-
开始之前,请检查站点上的任何非镜像聚合是否已脱机。
-
在 ONTAP 中验证 MetroCluster 配置的运行情况:
-
检查系统是否为多路径:
node run -node node-name sysconfig -a -
检查两个集群上是否存在任何运行状况警报:
s系统运行状况警报显示 -
确认 MetroCluster 配置以及操作模式是否正常:
MetroCluster show -
执行 MetroCluster check : + MetroCluster check run`
-
显示 MetroCluster 检查的结果:
MetroCluster check show`
-
检查交换机上是否存在任何运行状况警报(如果存在):
s存储开关显示 -
运行 Config Advisor 。
-
运行 Config Advisor 后,查看该工具的输出并按照输出中的建议解决发现的任何问题。
-
-
从要保持正常运行的站点实施切换:
MetroCluster switchovercluster_A::*> metrocluster switchover
此操作可能需要几分钟才能完成。
-
监控并验证切换的完成情况:
MetroCluster 操作显示cluster_A::*> metrocluster operation show Operation: Switchover Start time: 10/4/2012 19:04:13 State: in-progress End time: - Errors: cluster_A::*> metrocluster operation show Operation: Switchover Start time: 10/4/2012 19:04:13 State: successful End time: 10/4/2012 19:04:22 Errors: - -
如果您的 MetroCluster IP 配置运行的是 ONTAP 9.6 或更高版本,请等待灾难站点丛联机并自动完成修复操作。
在运行ONTAP 9.5或更早版本的MetroCluster IP配置中、灾难站点节点不会自动启动到ONTAP、丛会保持脱机状态。
-
将属于未镜像聚合的所有卷和LUN脱机移动。
-
使卷脱机。
cluster_A::* volume offline <volume name>
-
将LUN置于脱机状态。
cluster_A::* lun offline lun_path <lun_path>
-
-
将未镜像聚合移至脱机状态:
s将聚合存储到脱机状态cluster_A*::> storage aggregate offline -aggregate <aggregate-name>
-
根据您的配置和 ONTAP 版本,确定位于灾难站点( Cluster_B )的受影响丛并将其脱机。
您应将以下丛移至脱机状态:
-
位于灾难站点磁盘上的非镜像丛。
如果不将灾难站点上的非镜像丛脱机、则在灾难站点稍后关闭时可能会发生中断。
-
位于灾难站点上的磁盘上的镜像丛,用于聚合镜像。脱机后,丛将无法访问。
-
确定受影响的丛。
正常运行的站点上的节点所拥有的丛由 Pool1 磁盘组成。灾难站点上的节点所拥有的丛由 Pool0 磁盘组成。
Cluster_A::> storage aggregate plex show -fields aggregate,status,is-online,Plex,pool aggregate plex status is-online pool ------------ ----- ------------- --------- ---- Node_B_1_aggr0 plex0 normal,active true 0 Node_B_1_aggr0 plex1 normal,active true 1 Node_B_2_aggr0 plex0 normal,active true 0 Node_B_2_aggr0 plex5 normal,active true 1 Node_B_1_aggr1 plex0 normal,active true 0 Node_B_1_aggr1 plex3 normal,active true 1 Node_B_2_aggr1 plex0 normal,active true 0 Node_B_2_aggr1 plex1 normal,active true 1 Node_A_1_aggr0 plex0 normal,active true 0 Node_A_1_aggr0 plex4 normal,active true 1 Node_A_1_aggr1 plex0 normal,active true 0 Node_A_1_aggr1 plex1 normal,active true 1 Node_A_2_aggr0 plex0 normal,active true 0 Node_A_2_aggr0 plex4 normal,active true 1 Node_A_2_aggr1 plex0 normal,active true 0 Node_A_2_aggr1 plex1 normal,active true 1 14 entries were displayed. Cluster_A::>
受影响的丛是集群 A 的远程丛下表显示了磁盘是位于集群 A 的本地磁盘还是远程磁盘:
节点
池中的磁盘
磁盘是否应设置为脱机?
要脱机的丛示例
节点 _A_1 和节点 _A_2
池 0 中的磁盘
否磁盘是集群 A 的本地磁盘
-
池 1 中的磁盘
是的。磁盘对集群 A 来说是远程的
node_A_1_aggr0/plex4.
node_A_1_aggr1/plex1
node_A_2_aggr0/plex4.
node_A_2_aggr1/plex1
节点 _B_1 和节点 _B_2
池 0 中的磁盘
是的。磁盘对集群 A 来说是远程的
node_B_1_aggr1/plex0
node_B_1_aggr0/plex0
node_B_2_aggr0/plex0
node_B_2_aggr1/plex0
池 1 中的磁盘
-
使受影响的丛脱机:
s存储聚合丛脱机
storage aggregate plex offline -aggregate Node_B_1_aggr0 -plex plex0
+

对包含集群A远程磁盘的所有丛执行此步骤 -
-
根据交换机类型使ISL交换机端口持久脱机。
-
在每个节点上运行以下命令、以暂停节点:
node halt -inhibit-takeover true -skip-lif-migration true -node <node-name> -
关闭灾难站点上的设备。
您必须按所示顺序关闭以下设备:
-
存储控制器—存储控制器当前应位于
LOADER提示时、您必须将其完全关闭。 -
MetroCluster IP 交换机
-
存储架
-
重新定位 MetroCluster 的已关闭站点
关闭站点后,您可以开始维护工作。无论 MetroCluster 组件是在同一数据中心内重新定位还是重新定位到不同数据中心,操作步骤都是相同的。
-
硬件的布线方式应与上一站点相同。
-
如果交换机间链路( ISL )的速度,长度或数量发生变化,则需要重新配置它们。
-
验证是否已仔细记录所有组件的布线、以便可以在新位置正确重新连接。
-
物理重新定位所有硬件、存储控制器、IP 交换机和存储架。
-
配置 ISL 端口并验证站点间连接。
-
打开IP交换机的电源。
请勿 * 打开 * 任何其他设备的电源。
-
-
使用交换机上的工具(如果有)验证站点间连接。
只有在链路配置正确且稳定时、才应继续。 -
如果发现链路处于稳定状态,请再次禁用这些链路。
启动 MetroCluster 配置并恢复正常运行
完成维护或移动站点后,您必须启动站点并重新建立 MetroCluster 配置。
以下步骤中的所有命令都是从您启动的站点发出的。
-
打开交换机的电源。
您应首先打开交换机的电源。如果站点已重新定位,则它们可能已在上一步中启动。
-
如果需要或在重新定位过程中未完成此操作,请重新配置交换机间链路( ISL )。
-
如果隔离已完成,请启用 ISL 。
-
验证 ISL 。
-
-
打开存储控制器的电源、然后等待直至看到
LOADER提示符。控制器不能完全启动。如果启用了自动启动、请按
Ctrl+C停止控制器自动启动。
在启动控制器之前、请勿打开磁盘架电源。这样可以防止控制器意外启动到ONTAP。 -
打开磁盘架电源、留出足够的时间让其完全启动。
-
验证存储在维护模式下是否可见。
-
启动进入维护模式:
boot_ontap maint -
验证此存储是否可从正常运行的站点中看到。
-
验证本地和远程存储在维护模式下是否从节点可见:
disk show -v
-
-
暂停节点:
halt -
重新建立 MetroCluster 配置。
按照中的说明进行操作 "验证您的系统是否已做好切回准备" 根据 MetroCluster 配置执行修复和切回操作。