

更换 I/O 模块— AFF A700 和 FAS9000
 建议更改
建议更改
要更换 I/O 模块,您必须执行一系列特定的任务。
-
您可以将此操作步骤与系统支持的所有 ONTAP 版本结合使用
-
系统中的所有其他组件必须正常运行;否则,您必须联系技术支持。
第 1 步:关闭受损控制器
根据存储系统硬件配置的不同,您可以使用不同的过程关闭或接管受损的控制器。
接管并停止受损的控制器,以便健康控制器继续从受损的控制器的存储中提供数据。为此,您需要在 AutoSupport 中禁止自动创建案例,禁用自动回馈,并将受损的控制器带到 LOADER 提示符处。LOADER 提示符是安全停止状态,您可以从中更换 FRU。
-
如果您使用的是SAN系统,则必须已检查受损控制器SCSI刀片的事件消息
cluster kernel-service show。 `cluster kernel-service show`命令(在priv高级模式下)可显示该节点的节点名称"仲裁状态"、该节点的可用性状态以及该节点的运行状态。每个 SCSI 刀片式服务器进程应与集群中的其他节点保持仲裁关系。在继续更换之前,必须先解决所有问题。
-
If you have a cluster with more than two nodes, it must be in quorum.如果集群未达到仲裁或运行状况良好的控制器在资格和运行状况方面显示false、则必须在关闭受损控制器之前更正问题描述 ;请参见 "将节点与集群同步"。
-
如果启用了AutoSupport 、则通过调用AutoSupport 消息禁止自动创建案例:
system node autosupport invoke -node * -type all -message MAINT=<number of hours down>h这可以防止在计划的维护时段内打开自动支持案例。最大抑制持续时间为 72 小时。如果维护提前完成,您可以通过调用带有
MAINT=END的 AutoSupport 消息来重新启用案例创建。有关详细信息,请参见 "如何在计划维护窗口期间禁止自动创建案例"。以下AutoSupport 消息禁止自动创建案例两小时:
cluster1:> system node autosupport invoke -node * -type all -message MAINT=2h -
禁用自动交还:
-
从健康控制器的控制台输入以下命令:
storage failover modify -node impaired_node_name -auto-giveback false -
进入 `y`当您看到提示“您是否要禁用自动回馈?”时
-
-
将受损控制器显示为 LOADER 提示符:
如果受损控制器显示 … 那么 … LOADER 提示符
转至下一步。
正在等待交还
按 Ctrl-C ,然后在出现提示时回答
y。系统提示符或密码提示符
从运行正常的控制器接管或暂停受损控制器:
storage failover takeover -ofnode impaired_node_name -halt true-halt true参数将进入Loader提示符。
要关闭受损控制器,您必须确定控制器的状态,并在必要时切换控制器,以便运行正常的控制器继续从受损控制器存储提供数据。
-
您必须在此操作步骤 末尾保持电源处于打开状态,以便为运行正常的控制器供电。
-
检查 MetroCluster 状态以确定受损控制器是否已自动切换到运行正常的控制器:
MetroCluster show -
根据是否发生了自动切换,按照下表继续操作:
如果控制器受损 … 那么 … 已自动切换
继续执行下一步。
未自动切换
从运行正常的控制器执行计划内切换操作:
MetroCluster switchover未自动切换,您尝试使用
MetroCluster switchover命令进行切换,并且切换已被否决查看否决消息,如果可能,请解决问题描述并重试。如果无法解决问题描述问题,请联系技术支持。
-
在运行正常的集群中运行
MetroCluster heal -phase aggregates命令,以重新同步数据聚合。controller_A_1::> metrocluster heal -phase aggregates [Job 130] Job succeeded: Heal Aggregates is successful.
如果修复被否决,您可以使用 ` override-vetoes` 参数重新发出
MetroCluster heal命令。如果使用此可选参数,则系统将覆盖任何阻止修复操作的软否决。 -
使用 MetroCluster operation show 命令验证操作是否已完成。
controller_A_1::> metrocluster operation show Operation: heal-aggregates State: successful Start Time: 7/25/2016 18:45:55 End Time: 7/25/2016 18:45:56 Errors: - -
使用
storage aggregate show命令检查聚合的状态。controller_A_1::> storage aggregate show Aggregate Size Available Used% State #Vols Nodes RAID Status --------- -------- --------- ----- ------- ------ ---------------- ------------ ... aggr_b2 227.1GB 227.1GB 0% online 0 mcc1-a2 raid_dp, mirrored, normal...
-
使用
MetroCluster heal -phase root-aggregates命令修复根聚合。mcc1A::> metrocluster heal -phase root-aggregates [Job 137] Job succeeded: Heal Root Aggregates is successful
如果修复被否决,您可以使用 -override-vetoes 参数重新发出
MetroCluster heal命令。如果使用此可选参数,则系统将覆盖任何阻止修复操作的软否决。 -
在目标集群上使用
MetroCluster operation show命令验证修复操作是否已完成:mcc1A::> metrocluster operation show Operation: heal-root-aggregates State: successful Start Time: 7/29/2016 20:54:41 End Time: 7/29/2016 20:54:42 Errors: - -
在受损控制器模块上,断开电源。
第 2 步:更换 I/O 模块
要更换 I/O 模块,请在机箱中找到该模块,然后按照特定步骤顺序进行操作。
-
如果您尚未接地,请正确接地。
-
拔下与目标 I/O 模块关联的所有布线。
请确保为这些缆线贴上标签,以便您知道这些缆线来自何处。
-
从机箱中卸下目标 I/O 模块:
-
按下带字母和编号的凸轮按钮。
凸轮按钮离开机箱。
-
向下旋转凸轮闩锁,直到其处于水平位置。
I/O 模块从机箱中分离,并从 I/O 插槽中移出大约 1/2 英寸。
-
拉动 I/O 模块侧面的拉片,将 I/O 模块从机箱中卸下。
确保跟踪 I/O 模块所在的插槽。
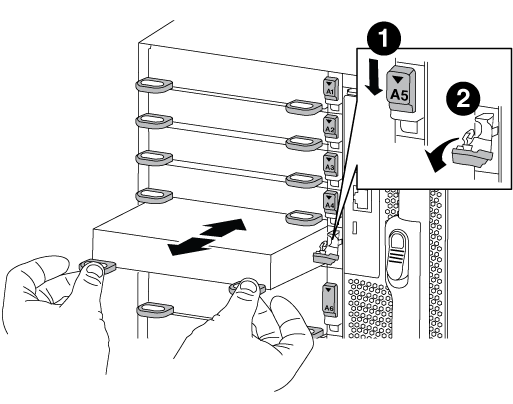

I/O 凸轮闩锁有字母和编号

I/O 凸轮闩锁完全解锁
-
-
将 I/O 模块放在一旁。
-
将替代 I/O 模块安装到机箱中,方法是将 I/O 模块轻轻滑入插槽,直到带字母和编号的 I/O 凸轮闩锁开始与 I/O 凸轮销啮合,然后将 I/O 凸轮闩锁一直向上推,将模块锁定到位。
-
根据需要重新对 I/O 模块进行布线。
第 3 步:更换 I/O 模块后重新启动控制器
更换 I/O 模块后,必须重新启动控制器模块。

|
如果新I/O模块与故障模块型号不同、则必须先重新启动BMC。 |
-
如果替代模块与旧模块的型号不同、请重新启动BMC:
-
在LOADER提示符处、更改为高级权限模式:
priv set advanced -
重新启动BMC:
sp reboot
-
-
从LOADER提示符处、重新启动节点:
bye
此操作将重新初始化PCIe卡和其他组件、并重新启动节点。 -
如果您的系统配置为在 40 GbE NIC 或板载端口上支持 10 GbE 集群互连和数据连接,请在维护模式下使用
nicadmin convert命令将这些端口转换为 10 GbE 连接。
请务必在完成转换后退出维护模式。 -
使节点恢复正常运行:
storage failover giveback -ofnode impaired_node_name -
如果已禁用自动交还,请重新启用它:
storage failover modify -node local -auto-giveback true
如果您的系统采用双节点MetroCluster 配置、则必须按照下一步中所述切回聚合。
第 4 步:切回双节点 MetroCluster 配置中的聚合
此任务仅限适用场景双节点 MetroCluster 配置。
-
验证所有节点是否处于
enabled状态:MetroCluster node showcluster_B::> metrocluster node show DR Configuration DR Group Cluster Node State Mirroring Mode ----- ------- -------------- -------------- --------- -------------------- 1 cluster_A controller_A_1 configured enabled heal roots completed cluster_B controller_B_1 configured enabled waiting for switchback recovery 2 entries were displayed. -
验证所有 SVM 上的重新同步是否已完成:
MetroCluster SVM show -
验证修复操作正在执行的任何自动 LIF 迁移是否已成功完成:
MetroCluster check lif show -
在运行正常的集群中的任何节点上使用
MetroCluster switchback命令执行切回。 -
验证切回操作是否已完成:
MetroCluster show当集群处于
waiting for-switchback状态时,切回操作仍在运行:cluster_B::> metrocluster show Cluster Configuration State Mode -------------------- ------------------- --------- Local: cluster_B configured switchover Remote: cluster_A configured waiting-for-switchback
当集群处于
normal状态时,切回操作完成。:cluster_B::> metrocluster show Cluster Configuration State Mode -------------------- ------------------- --------- Local: cluster_B configured normal Remote: cluster_A configured normal
如果切回需要很长时间才能完成,您可以使用
MetroCluster config-replication resync-status show命令检查正在进行的基线的状态。 -
重新建立任何 SnapMirror 或 SnapVault 配置。
第 5 步:将故障部件退回 NetApp
按照套件随附的 RMA 说明将故障部件退回 NetApp 。 "部件退回和更换"有关详细信息、请参见页面。