

审计消息流和保留
 建议更改
建议更改
所有StorageGRID服务在正常系统运行期间都会生成审计消息。您应该了解这些审计消息如何通过StorageGRID系统传输到 `audit.log`文件。
审计消息流
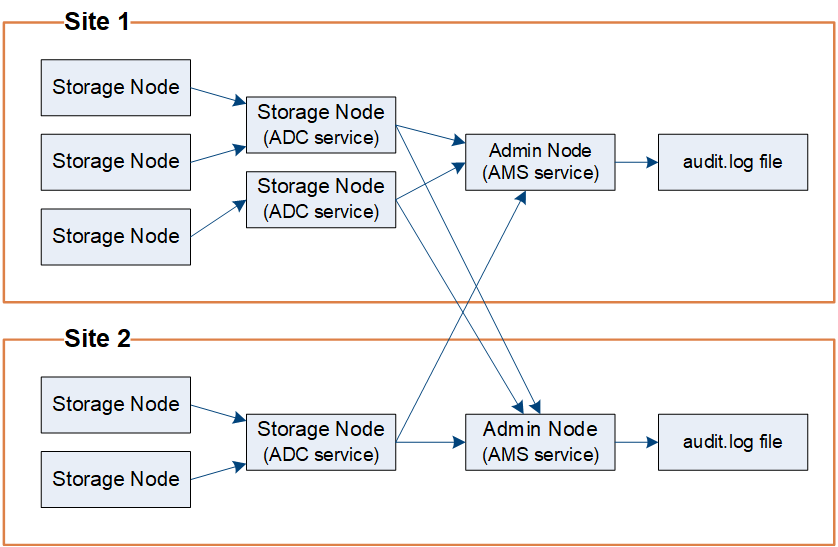
审计消息由管理节点和具有管理域控制器 (ADC) 服务的存储节点处理。
如审计消息流程图所示,每个StorageGRID节点将其审计消息发送到数据中心站点的其中一个 ADC 服务。每个站点安装的前三个存储节点都会自动启用 ADC 服务。
反过来,每个 ADC 服务充当中继,并将其审计消息集合发送到StorageGRID系统中的每个管理节点,这为每个管理节点提供了系统活动的完整记录。
每个管理节点都将审计消息存储在文本日志文件中;活动日志文件名为 audit.log。
审计消息保留
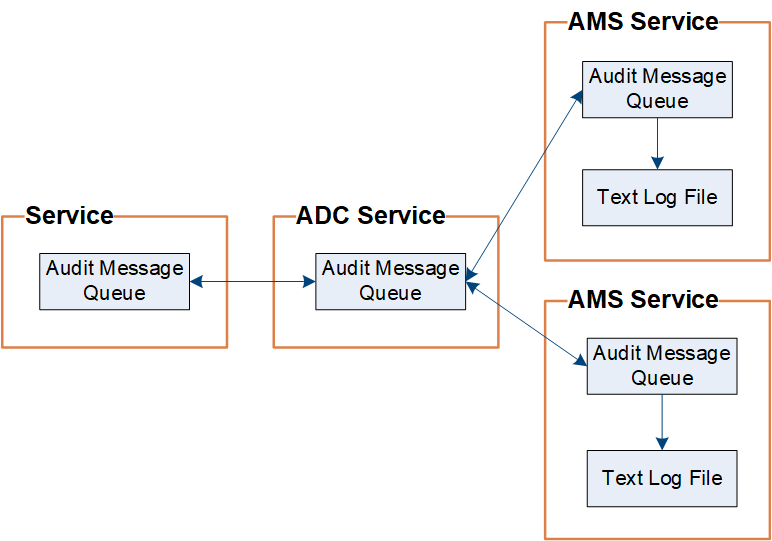
StorageGRID使用复制和删除过程来确保在将审计消息写入审计日志之前不会丢失任何审计消息。
当节点生成或中继审计消息时,该消息将存储在网格节点系统磁盘上的审计消息队列中。消息的副本始终保存在审计消息队列中,直到该消息被写入管理节点的审计日志文件为止 `/var/local/log`目录。这有助于防止审计消息在传输过程中丢失。
由于网络连接问题或审计容量不足,审计消息队列可能会暂时增加。随着队列的增加,它们会消耗每个节点的更多可用空间 `/var/local/`目录。如果问题仍然存在,并且节点的审计消息目录变得太满,则各个节点将优先处理其积压消息,并暂时无法接收新消息。
具体来说,您可能会看到以下行为:
-
如果 `/var/local/log`管理节点使用的目录已满,则管理节点将被标记为无法接收新的审计消息,直到目录不再满为止。S3 客户端请求不受影响。当审计存储库无法访问时,会触发 XAMS(无法访问的审计存储库)警报。
-
如果 `/var/local/`如果具有 ADC 服务的存储节点使用的目录已满 92%,则该节点将被标记为不可用于审核消息,直到目录仅满 87% 为止。S3 客户端对其他节点的请求不受影响。当审计中继无法访问时,会触发 NRLY(可用审计中继)警报。

如果没有可用的存储节点提供 ADC 服务,存储节点会将审计消息本地存储在 `/var/local/log/localaudit.log`文件。 -
如果
/var/local/`当存储节点使用的目录已满 85% 时,该节点将开始拒绝 S3 客户端请求 `503 Service Unavailable。
以下类型的问题可能会导致审核消息队列变得非常大:
-
具有 ADC 服务的管理节点或存储节点中断。如果系统的一个节点发生故障,其余节点可能会积压。
-
持续的活动率超出了系统的审计能力。
-
这 `/var/local/`由于与审计消息无关的原因,ADC 存储节点上的空间已满。发生这种情况时,节点将停止接受新的审计消息并优先处理其当前积压,这可能会导致其他节点积压。
大型审计队列警报和审计消息队列 (AMQS) 警报
为了帮助您监控审计消息队列随时间的大小,当存储节点队列或管理节点队列中的消息数量达到特定阈值时,将触发*大型审计队列*警报和旧式 AMQS 警报。
如果触发了“大型审计队列”警报或旧式 AMQS 警报,请首先检查系统负载——如果最近有大量交易,则警报和警报应该会随着时间的推移而解决,并且可以忽略。
如果警报或警告持续存在且严重程度增加,请查看队列大小图表。如果该数字在数小时或数天内稳步增加,则审计负载可能已经超出了系统的审计容量。通过将客户端写入和客户端读取的审计级别更改为错误或关闭,降低客户端操作率或减少记录的审计消息数量。看"配置审计消息和日志目标" 。
重复消息
如果发生网络或节点故障, StorageGRID系统会采取保守的方法。因此,审计日志中可能存在重复的消息。