

使用 F5 DNS 实现StorageGRID 的全局负载均衡
 建议更改
建议更改
作者:史蒂夫·戈尔曼 (F5)
本技术报告提供了详细的说明,指导如何配置NetApp StorageGRID与 F5 DNS 服务,以实现全局负载均衡,从而在网格分布于多个站点和/或 HA 组时,提供更好的数据可用性、更高的数据一致性并优化 S3 事务路由。
简介
F5 BIG-IP DNS 解决方案以前称为 BIG-IP GTM(全球流量管理器),非正式名称为 GSLB(全球服务器负载均衡),它允许跨多个主动-主动 HA 组和主动-主动多站点StorageGRID解决方案实现无缝访问。
F5 BIG-IP 多站点StorageGRID配置
无论要支持多少个StorageGRID站点,至少需要两个 BIG-IP 设备(物理或虚拟)启用并设置 BIG-IP DNS 模块。DNS 设备越多,企业获得的冗余程度就越高。
BIG-IP DNS - 初始设置入门指南
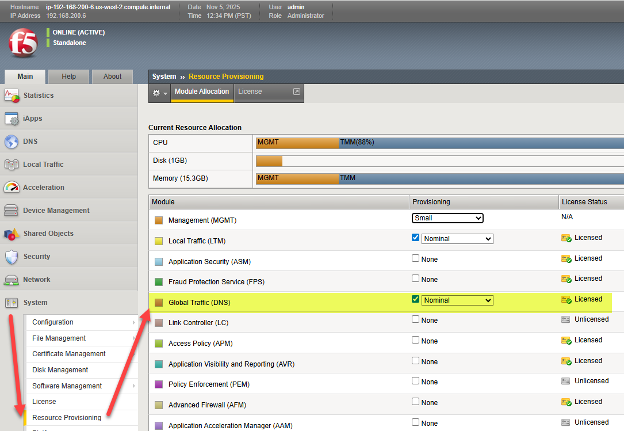
BIG-IP 设备完成至少初始配置后,使用 Web 浏览器登录到 TMUI(BIG-IP GUI)界面,然后选择“系统”→“资源配置”。如前所述,请确保“全球流量(DNS)”模块已勾选并显示已获得许可。请注意,如图所示,“本地流量 (LTM)”通常可以配置在同一设备上。
配置 DNS 协议基础元素
StorageGRID站点的全局流量管理的第一步是选择 DNS 选项卡,几乎所有全局流量控制都将在此配置,然后选择设置→ GLSB。启用这两个同步选项,并选择一个将在参与的 BIG-IP 设备之间共享的 DNS 组名称。

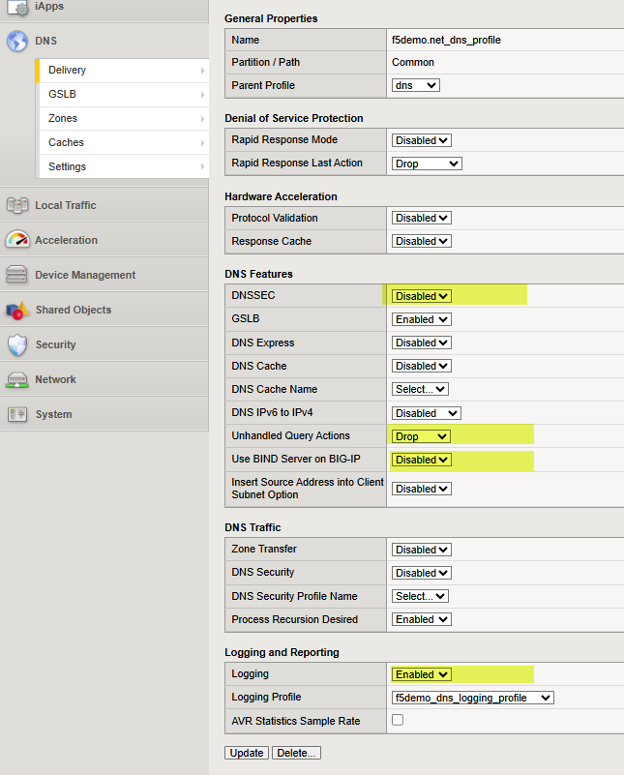
接下来,导航至 DNS > 交付 > 配置文件 > DNS:创建并创建一个配置文件,该配置文件将控制您希望启用或禁用的 DNS 功能。如果您对生成特定 DNS 日志感兴趣,请参阅前面的 DNS 课堂指南链接。以下是一个可用的 DNS 配置文件示例,请注意四个高亮部分,它们代表重要的设置值。为了便于理解,每种可能的设置都在以下 F5 知识库 (KB) 文章中进行了解释。 "此处"。
此时,我们可以通过创建的“配置文件”来调整 UDP 和 TCP 协议的特性,这两个协议都可以承载涉及 BIG-IP 的 DNS 流量。只需为 UDP 和 TCP 创建一个新的配置文件即可。假设 DNS 流量将跨越 WAN 链路,一个好的做法是直接继承在 WAN 环境中性能良好的 UDP 和 TCP 特性。要添加每个协议,只需单击每个协议旁边的“+”图标,并将父配置文件设置为以下内容:
UDP → 使用“父”配置文件“udp_gtm_dns”
TCP → 使用“父”配置文件“f5-tcp-wan”

现在,我们只需要为涉及 BIG-IP DNS 的 UDP 和 TCP 流量分配一个 IP 地址即可。对于熟悉 BIG-IP LTM 的人来说,这本质上是创建 DNS 虚拟服务器,而虚拟服务器需要“监听器”IP 地址。如图所示,按照箭头指示创建 DNS/UDP 和 DNS/TCP 的监听器/虚拟服务器。

以下是来自实时 BIG-IP DNS 的一个示例,其中我们可以看到 TCP 虚拟服务器监听器设置,并可以看到它是如何将许多先前的步骤联系起来的。这包括引用 DNS 配置文件和协议 (TCP) 配置文件,以及配置 DNS 要使用的有效 IP 地址。与使用 BIG-IP 创建的所有对象一样,使用有意义的名称有助于识别对象是什么,例如示例名称中的 dns/siteb/TCP53。

至此,启用 DNS 模块的 BIG-IP 设备的初步设置步骤(通常是“一次性”设置步骤)就完成了。目前,我们已准备好过渡到使用我们的设备建立全球流量管理解决方案的具体细节,这当然将与StorageGRID站点的特性相关联。
分四步完成数据中心站点搭建和BIG-IP间通信建立
第一步:创建数据中心
每个将容纳由 BIG-IP LTM 进行本地负载均衡的节点集群的站点都应该输入到 BIG-IP DNS 中。这只需要在一个 BIG-IP DNS 上完成,因为我们正在创建一个 DNS 同步组来支持流量管理,因此该配置将在组的 DNS 成员之间共享。
通过 TMUI GUI,选择 DNS > GSLB > 数据中心 > 数据中心列表,并为每个StorageGRID站点创建一个条目。如果使用与图 1 一致的网络设置,DNS 设备位于其他非StorageGRID站点,除了存储站点之外,还要为这些站点添加数据中心。在本例中,站点 a 和 b 分别创建在俄亥俄州和俄勒冈州,BIG-IP 是双 DNS 和 LTM 设备。

第二步:创建服务器(解决方案中所有 BIG-IP 设备列表)
现在我们已准备好将各个StorageGRID站点集群连接到 BIG-IP DNS 设置。回想一下,每个站点的 BIG-IP 设备将通过配置虚拟服务器来实际进行 S3 流量的负载均衡,这些虚拟服务器将“前端”可达 IP 地址/端口绑定到一组后端存储节点设备的“池”,使用“后端”IP 地址/端口。
例如,如果池中的所有存储节点因管理原因(例如站点停用)或因实时健康检查失败而意外离线,则流量将通过更改 DNS 查询响应定向到其他站点。
要将 StorageGrid 站点(特别是本地虚拟服务器)与每个设备上的 BIG-IP DNS 配置关联起来,只需设置一次即可。接下来,所有 BIG-IP DNS 设备都将进行同步设置。
简单来说,我们将创建一个列表,称为服务器列表,其中包含我们所有的 BIG-IP 设备,无论它们是否获得了 DNS、LTM 或 DNS 和 LTM 的许可。列表完成后,该主列表将与所有 BIG-IP DNS 设备同步。
在一台已获得 BIG-IP DNS 许可的设备上,选择 DNS > GSLB > 服务器 > 服务器列表,然后选择添加按钮 (+)。
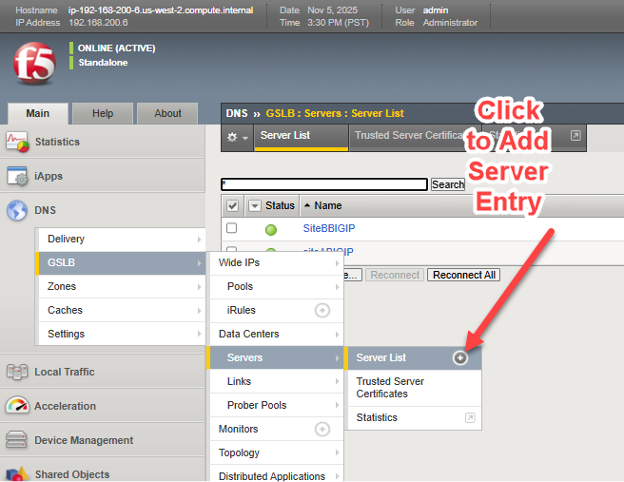
添加每个 BIG-IP 时,四个关键要素包括:* 从产品下拉菜单中选择 BIG-IP,虽然也可以使用其他负载均衡器,但通常缺乏在每个站点后端节点健康状况恶化时的实时可见性和响应能力。* 添加 BIG-IP DNS 设备的 IP 地址。通常情况下,首次添加 BIG-IP DNS 设备时,地址将是当前可通过 GUI 访问的设备,以后添加的设备将是解决方案中的其他设备。* 选择健康监视器,当添加的负载均衡器是 BIG-IP 设备时,始终使用“BIG-IP”,以便考虑后端StorageGRID节点的健康状况。* 如果设备是双 DNS/LTM 设备,则可以选择请求虚拟服务器自动发现。

在某些情况下,例如瞬态网络问题或网络位置之间的防火墙 ACL 规则,在此阶段添加远程设备时,虚拟服务器发现可能不会显示已配置 LTM 的远程设备的条目。在这种情况下,添加新设备(“服务器”)后,可以按照以下指示手动添加虚拟服务器。如果添加的是仅用于 DNS 的 BIG-IP 设备,则不会发现或向该设备添加任何虚拟服务器。

我们需要在所有站点为解决方案中的每个设备添加这些服务器条目,包括 BIG-IP DNS 设备、BIG-IP LTM 设备以及任何同时承担 DNS 和 LTM 双重角色的设备。
第三步:在所有BIG-IP设备之间建立信任
在以下示例中,添加了四台设备作为服务器,它们分布在两个站点。请注意,每个站点都有专用的 BIG-IP DNS 和 BIG-IP LTM。但是,除了当前登录的设备之外,所有其他设备的“状态”列中都显示蓝色图标。这意味着尚未与其他 BIG-IP 设备建立信任关系。

要添加信任,请使用 SSH 连接到刚刚通过 GUI 输入配置详细信息的 BIG-IP,并使用“root”帐户访问 BIG-IP 命令行界面。在提示符下发出以下单个命令:bigip_add
“bigip_add”命令从目标BIGIP设备拉取管理证书,用于在集群中的GSLB服务器之间建立加密的“iQuery”通道。默认情况下,iQuery使用TCP端口4353运行,它是一种心跳机制,使BOG-IP DNS成员保持同步状态。它在加密通道中使用了 xml 和 gzip。当不带任何选项运行“bigip_add”时,该命令将使用当前用户名连接到端点,对 GSLB 服务器列表中的所有 BIGIP 设备运行。为了快速检查是否成功,只需返回 BIG-IP GUI 并确认所有服务器的证书现在都列在显示的下拉菜单中即可。

第四步:将所有 BIG-IP DNS 设备同步到 DNS 组
最后一步将允许仅使用单个设备的 TMUI GUI 即可完全配置所有 BIG-IP DNS 设备。例如,如果有两个StorageGRID站点,这意味着现在需要使用 SSH 访问另一个站点的 BIG-IP DNS 的命令行。以 root 用户身份连接后,并确保防火墙策略/ACL 允许两个 BIG-IP DNS 设备通过 TCP 端口 22 (SSH)、443 (HTTPS) 和 4354 (F5 iQuery 协议) 进行通信,然后在提示符下执行以下命令:gtm_add <之前完成所有 GUI 步骤的第一个站点 BIG-IP DNS 的 IP 地址>
此时,所有进一步的 DNS 配置工作都可以在已添加到该组的任何 BIG-IP DNS 设备上执行。对于仅支持 LTM 的设备成员,无需应用上述命令 gtm_add。只有支持 DNS 的设备才需要此命令才能加入同步 DNS 组。
建立数据中心站点和建立BIG-IP间通信
至此,创建底层、健康的 BIG-IP DNS 设备组的所有步骤均已完成。现在我们可以继续创建指向我们在每个StorageGRID数据中心公开的分布式 Web/S3 服务的名称、FQDN。
这些名称被称为“广域 IP 地址”,简称 WIP,它们是具有 DNS A 资源记录的普通 DNS FQDN。然而,它们并不像传统的 A 资源记录那样指向服务器,而是在内部指向 BIG-IP 虚拟服务器池。每个池都可以单独由一个或多个虚拟服务器组成。请求 IP 地址进行名称解析的 S3 客户端将收到策略选择的最佳StorageGRID站点上的 S3 虚拟服务器的地址。
广域IP、IP池和虚拟服务器简述
举一个简单的虚构例子,名称 storage.quantumvault.com 的 WIP 可能会将 BIG-IP DNS 解决方案与两个潜在的虚拟服务器池连接起来。第一个池子可能由北美的 4 个地点组成;第二个池子可能由欧洲的 3 个地点组成。
选定的池子可能是通过一系列政策决定得出的,也许可以使用 5:1 的简单比例,将大部分流量导向北美StorageGRID站点。更有可能的是,基于拓扑结构的选择,例如,将所有来自欧洲的 S3 流量定向到欧洲站点,而将世界其余的 S3 流量定向到北美数据中心。
一旦 BIG-IP DNS 确定了池,假设选择了北美池,则返回用于解析 storage.quantumvault.com 的实际 DNS A 资源记录可以是 BIG-IP LTM 在北美 4 个站点中支持的 4 个虚拟服务器中的任何一个。同样,具体选择取决于策略,存在简单的“静态”方法,例如轮询;而更高级的“动态”选择,例如使用性能探针来测量每个站点从本地 DNS 解析器的延迟,则被保留并用作站点选择的标准。
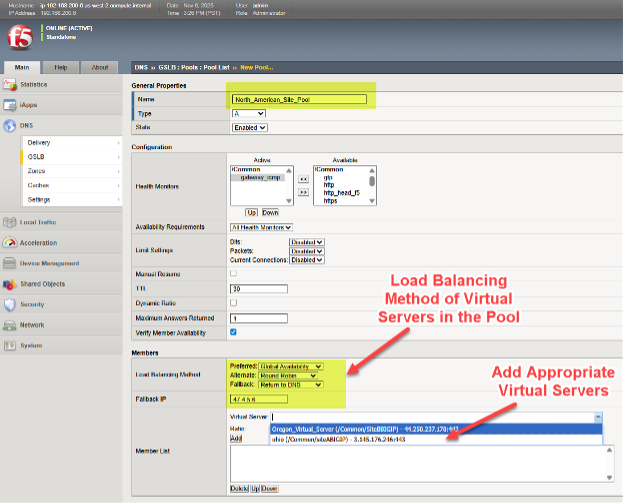
要在 BIG-IP DNS 上设置虚拟服务器池,请按照菜单路径 DNS > GSLB > Pools > Pool List > Add (+) 进行操作。在这个例子中,我们可以看到各种北美虚拟服务器被添加到池中,并且选择此池时,首选的负载均衡方法是分层选择的。
我们将 WIP(广域 IP),即我们的服务名称(将通过 DNS 解析),按照 DNS > GSLB > 广域 IP > 广域 IP 列表 > 创建 (+) 的步骤添加到部署中。在下面的示例中,我们提供了一个支持 S3 的存储服务的示例 WIP。

调整 DNS 以支持全球流量管理
目前,我们所有的底层 BIG-IP 设备都已准备好执行 GSLB(全局服务器负载均衡)。我们只需要调整并分配用于 S3 流量的名称,即可利用该解决方案。一般做法是将企业现有 DNS 域的一部分委托给 BIG-IP DNS 控制。也就是说,要“划分”出一部分名称空间,即一个子域,并将该子域的控制权委托给 BIG-IP DNS 设备。从技术上讲,这是通过确保 BIG-IP DNS 设备在企业 DNS 中具有 A DNS 资源记录 (RR),然后将这些名称/地址设置为委派域的名称服务器 (NS) DNS 资源记录来实现的。
如今企业维护 DNS 的方式有很多种,其中一种方法是完全托管的解决方案。例如,通过 Windows Server 2025 运行和管理 DNS 就是这种情况。企业还可以采用另一种方法,即利用 AWS Route53 或 Squarespace 等云 DNS 提供商。
以下示例纯属虚构,仅供参考。我们有StorageGRID支持通过 S3 协议对对象进行读取和写入,现有域由 AWS Route53 管理,现有示例域为 f5demo.net。
我们希望将子域名 engineering.f5demo.net 分配给 BIG-IP DNS 设备,以实现全球流量管理。为此,我们为 engineering.f5demo.net 创建一个新的 NS(名称服务器)资源记录,并将其指向 BIG-IP DNS 设备名称列表。在我们的示例中,我们有两个 BIG-IP DNS 设备,因此我们为它们创建了两条 A 资源记录。
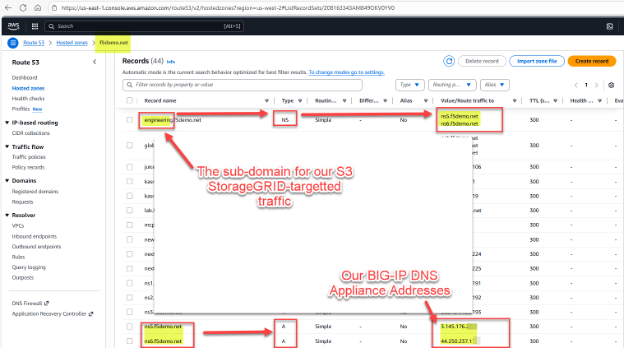
现在,我们以 BIG-IP DNS 为例,设置一个广域 IP (WIP)。由于 DNS 使用组同步,我们只需要使用一台设备的 GUI 进行调整。在 BIG-IP DNS GUI 中,转到 DNS > GSLB > 广域 IP > 广域 IP 列表 (+)。回想一下,在传统的 DNS FQDN 设置中,需要输入一个或多个 IPv4 地址,而在我们的例子中,我们只需指向一个或多个StorageGRID虚拟服务器池。

在我们的示例中,我们在俄亥俄州和俄勒冈州站点都设有通用的 Web HTTPS 服务器。通过简单的“轮询”方法,我们应该能够看到全局 DNS 响应对 www.wip.engineering.f5demo.net 的 A 资源记录映射的查询,其中包含两个虚拟服务器 IP。
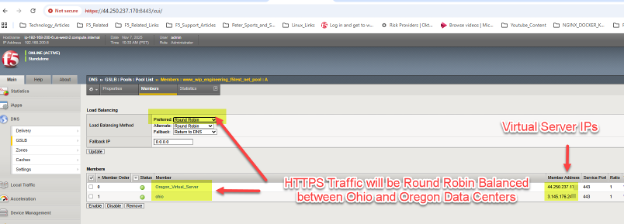
可以使用网页浏览器进行简单的测试,或者,对于使用StorageGRID 的S3,可以使用 S3Browser 等图形工具进行测试。由于我们在池内选择了轮询调度,因此每次 DNS 查询都会将池中的下一个数据中心站点用作后续流量的目标。
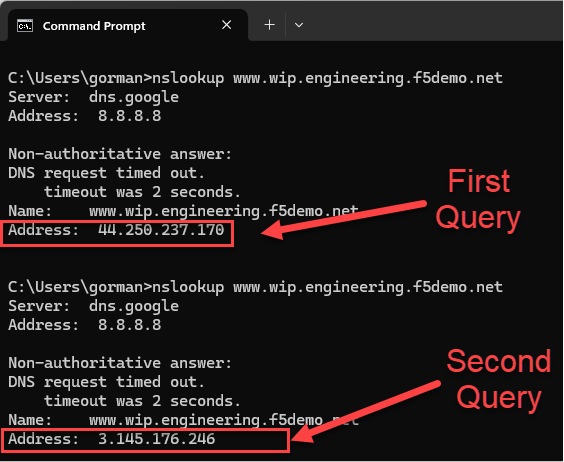
在我们的示例设置中,我们可以使用 dig 或 nslookup 快速生成一系列两个 DNS 查询,以确保 BIG-IP DNS 确实在进行轮询负载均衡,从而使两个站点都能随着时间的推移接收流量。
建议探索更高级的技术
众多可行方法之一,是使用“全局可用性”模式,而不是上面给出的简单“轮询”示例。通过全局可用性,可以将流量定向到池的顺序,或者单个池中的虚拟服务器。这样一来,所有 S3 流量默认都可以定向到例如纽约市的站点。
如果健康检查表明此站点的StorageGRID节点可用性存在问题,则流量届时可能会被定向到圣路易斯。如果圣路易斯出现健康问题,法兰克福的站点可以转而开始接收 S3 读取或写入交易。因此,全球可用性是提高 S3 StorageGRID整体解决方案弹性的一种方法。另一种方法是混合搭配负载均衡方法,采用分层方法。

在这个例子中,“动态”选项是已配置池中站点的首选负载均衡方式。在所示的示例中,持续测量方法采用主动探测本地 DNS 解析器性能的方法,这是站点选择的催化剂。如果这种方法不可行,则可以根据分配给每个站点的比例来选择各个站点。按比例计算,规模更大、带宽更高的StorageGRID站点可以接收比规模较小的站点更多的 S3 事务。最后,作为一种灾难恢复方案,如果池中的所有站点都出现故障,则指定的备用 IP 将用作最后的备选站点。BIG-IP DNS 中比较有趣的负载均衡方法之一是“拓扑”,它观察 DNS 查询的传入源(即 S3 用户的本地 DNS 解析器),并利用互联网拓扑信息从池中选择看似“最近”的站点。
最后,如果站点遍布全球,则值得考虑使用 F5 BIG-IP DNS 手册中详细讨论的动态“探测”技术。通过探测,可以监控频繁的 DNS 查询来源,例如,流量通常使用同一本地 DNS 解析器的企业对企业合作伙伴。可以从全球每个站点的 BIG-IP LTM 启动 BIG-IP DNS 探测,以大致确定哪个潜在站点可能为 S3 交易提供最低延迟。因此,来自亚洲的流量可能由亚洲的StorageGRID站点提供比位于北美或欧洲的站点更好的服务。