

第 2 部分 - 利用 AWS Amazon FSx for NetApp ONTAP (FSx ONTAP) 作為 SageMaker 模型訓練的資料來源
 建議變更
建議變更
本文是關於使用Amazon FSx for NetApp ONTAP (FSx ONTAP) 在 SageMaker 中訓練 PyTorch 模型的教程,具體針對輪胎品質分類項目。
介紹
本教學提供了一個電腦視覺分類專案的實際範例,提供了在 SageMaker 環境中利用 FSx ONTAP作為資料來源建立 ML 模型的實務經驗。該專案專注於使用深度學習框架 PyTorch 根據輪胎影像對輪胎品質進行分類。它強調使用 FSx ONTAP作為 Amazon SageMaker 中的資料來源來開發機器學習模型。
什麼是 FSx ONTAP
Amazon FSx ONTAP確實是 AWS 提供的完全託管的儲存解決方案。它利用 NetApp 的ONTAP檔案系統提供可靠且高效能的儲存。透過支援 NFS、SMB 和 iSCSI 等協議,它允許從不同的計算實例和容器進行無縫存取。該服務旨在提供卓越的效能,確保快速且有效率的資料操作。它還具有高可用性和耐用性,確保您的資料保持可存取和保護。此外, Amazon FSx ONTAP的儲存容量是可擴充的,您可以根據需要輕鬆調整。
先決條件
網路環境
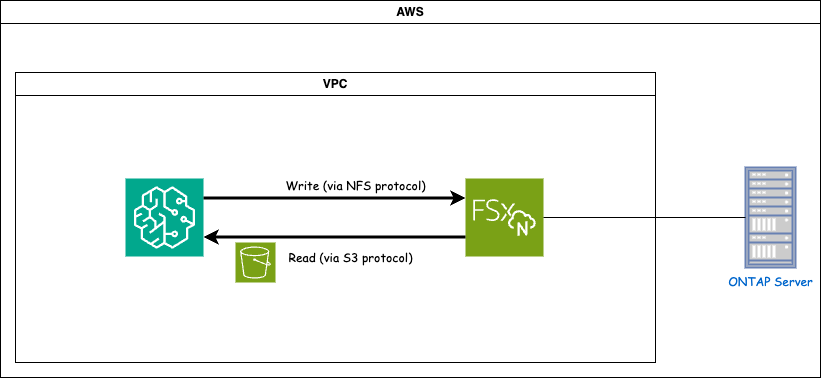
FSx ONTAP (Amazon FSx ONTAP)是一項 AWS 儲存服務。它包括在NetApp ONTAP系統上運行的檔案系統和連接到它的 AWS 管理的系統虛擬機器 (SVM)。在提供的圖中,AWS 管理的NetApp ONTAP伺服器位於 VPC 外部。 SVM作為SageMaker和NetApp ONTAP系統之間的中介,接收來自SageMaker的操作請求並轉送到底層儲存。若要存取 FSx ONTAP,SageMaker 必須放置在與 FSx ONTAP部署相同的 VPC 內。此配置可確保 SageMaker 和 FSx ONTAP之間的通訊和資料存取。
資料存取
在現實場景中,資料科學家通常利用 FSx ONTAP中儲存的現有資料來建立他們的機器學習模型。但是,出於演示目的,由於 FSx ONTAP檔案系統在建立後最初是空的,因此需要手動上傳訓練資料。這可以透過將 FSx ONTAP作為磁碟區安裝到 SageMaker 來實現。檔案系統成功掛載後,您可以將資料集上傳到掛載位置,以便在 SageMaker 環境中訓練模型。這種方法可讓您利用 FSx ONTAP的儲存容量和功能,同時與 SageMaker 進行模型開發和訓練。
資料讀取過程涉及將 FSx ONTAP配置為私有 S3 儲存桶。詳細配置說明請參考"第 1 部分 - 將Amazon FSx for NetApp ONTAP (FSx ONTAP) 作為私有 S3 儲存桶整合到 AWS SageMaker"
整合概述
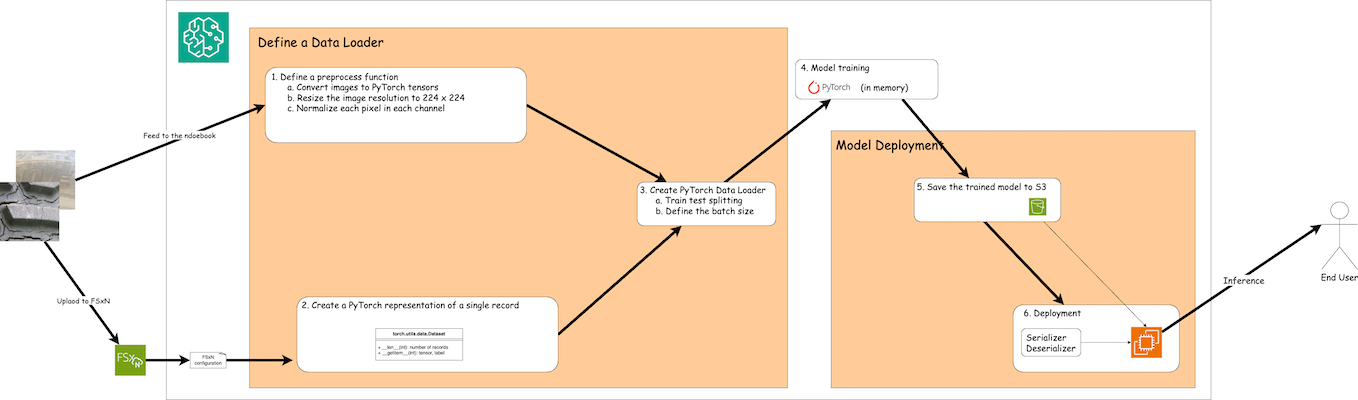
使用 FSx ONTAP中的訓練資料在 SageMaker 中建立深度學習模型的工作流程可以概括為三個主要步驟:資料載入器定義、模型訓練和部署。從高層次來看,這些步驟構成了 MLOps 管道的基礎。然而,為了全面實施,每個步驟都涉及幾個詳細的子步驟。這些子步驟涵蓋資料預處理、資料集拆分、模型配置、超參數調整、模型評估和模型部署等各種任務。這些步驟確保在 SageMaker 環境中使用來自 FSx ONTAP的訓練資料建構和部署深度學習模型的流程全面有效。
逐步集成
資料Loader
為了使用資料訓練 PyTorch 深度學習網絡,創建了一個資料載入器以方便資料的輸入。資料載入器不僅定義批次大小,還確定讀取和預處理批次中每個記錄的過程。透過配置資料載入器,我們可以批次處理數據,從而實現深度學習網路的訓練。
資料載入器由3部分組成。
預處理函數
from torchvision import transforms
preprocess = transforms.Compose([
transforms.ToTensor(),
transforms.Resize((224,224)),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
])上面的程式碼片段示範了使用 torchvision.transforms 模組定義影像預處理轉換。在本教程中,建立預處理物件來套用一系列轉換。首先,ToTensor() 轉換將影像轉換為張量表示。隨後,Resize224,224 轉換將影像調整為固定大小 224x224 像素。最後,Normalize() 轉換透過減去平均值並除以每個通道的標準差來對張量值進行歸一化。用於標準化的平均值和標準差值通常用於預訓練的神經網路模型。總的來說,這段程式碼透過將圖像資料轉換為張量、調整其大小以及規範化像素值來準備進一步處理或輸入到預先訓練的模型中。
PyTorch 資料集類
import torch
from io import BytesIO
from PIL import Image
class FSxNImageDataset(torch.utils.data.Dataset):
def __init__(self, bucket, prefix='', preprocess=None):
self.image_keys = [
s3_obj.key
for s3_obj in list(bucket.objects.filter(Prefix=prefix).all())
]
self.preprocess = preprocess
def __len__(self):
return len(self.image_keys)
def __getitem__(self, index):
key = self.image_keys[index]
response = bucket.Object(key)
label = 1 if key[13:].startswith('defective') else 0
image_bytes = response.get()['Body'].read()
image = Image.open(BytesIO(image_bytes))
if image.mode == 'L':
image = image.convert('RGB')
if self.preprocess is not None:
image = self.preprocess(image)
return image, label此類別提供取得資料集中記錄總數的功能,並定義讀取每筆記錄資料的方法。在 getitem 函數中,程式碼利用 boto3 S3 bucket 物件從 FSx ONTAP檢索二進位資料。從 FSx ONTAP存取資料的程式碼樣式類似於從 Amazon S3 讀取資料。後續講解深入探討私有 S3 物件 bucket 的創建過程。
FSx ONTAP作為私有 S3 儲存庫
seed = 77 # Random seed
bucket_name = '<Your ONTAP bucket name>' # The bucket name in ONTAP
aws_access_key_id = '<Your ONTAP bucket key id>' # Please get this credential from ONTAP
aws_secret_access_key = '<Your ONTAP bucket access key>' # Please get this credential from ONTAP
fsx_endpoint_ip = '<Your FSx ONTAP IP address>' # Please get this IP address from FSXNimport boto3
# Get session info
region_name = boto3.session.Session().region_name
# Initialize Fsxn S3 bucket object
# --- Start integrating SageMaker with FSXN ---
# This is the only code change we need to incorporate SageMaker with FSXN
s3_client: boto3.client = boto3.resource(
's3',
region_name=region_name,
aws_access_key_id=aws_access_key_id,
aws_secret_access_key=aws_secret_access_key,
use_ssl=False,
endpoint_url=f'http://{fsx_endpoint_ip}',
config=boto3.session.Config(
signature_version='s3v4',
s3={'addressing_style': 'path'}
)
)
# s3_client = boto3.resource('s3')
bucket = s3_client.Bucket(bucket_name)
# --- End integrating SageMaker with FSXN ---為了從 SageMaker 中的 FSx ONTAP讀取數據,需要建立一個使用 S3 協定指向 FSx ONTAP儲存的處理程序。這使得 FSx ONTAP可以被視為私人 S3 儲存桶。處理程序配置包括指定 FSx ONTAP SVM 的 IP 位址、儲存桶名稱和必要的憑證。有關取得這些配置項目的詳細說明,請參閱以下文件:"第 1 部分 - 將Amazon FSx for NetApp ONTAP (FSx ONTAP) 作為私有 S3 儲存桶整合到 AWS SageMaker" 。
在上面的例子中,bucket 物件用於實例化 PyTorch 資料集物件。數據集對象將在後續章節中進一步解釋。
PyTorch 資料Loader
from torch.utils.data import DataLoader
torch.manual_seed(seed)
# 1. Hyperparameters
batch_size = 64
# 2. Preparing for the dataset
dataset = FSxNImageDataset(bucket, 'dataset/tyre', preprocess=preprocess)
train, test = torch.utils.data.random_split(dataset, [1500, 356])
data_loader = DataLoader(dataset, batch_size=batch_size, shuffle=True)在提供的範例中,指定批次大小為 64,表示每個批次將包含 64 筆記錄。透過結合 PyTorch Dataset 類別、預處理函數和訓練批次大小,我們獲得了用於訓練的資料載入器。此資料載入器有助於在訓練階段分批迭代資料集的過程。
模型訓練
from torch import nn
class TyreQualityClassifier(nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(
nn.Conv2d(3,32,(3,3)),
nn.ReLU(),
nn.Conv2d(32,32,(3,3)),
nn.ReLU(),
nn.Conv2d(32,64,(3,3)),
nn.ReLU(),
nn.Flatten(),
nn.Linear(64*(224-6)*(224-6),2)
)
def forward(self, x):
return self.model(x)import datetime
num_epochs = 2
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = TyreQualityClassifier()
fn_loss = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
model.to(device)
for epoch in range(num_epochs):
for idx, (X, y) in enumerate(data_loader):
X = X.to(device)
y = y.to(device)
y_hat = model(X)
loss = fn_loss(y_hat, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
current_time = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
print(f"Current Time: {current_time} - Epoch [{epoch+1}/{num_epochs}]- Batch [{idx + 1}] - Loss: {loss}", end='\r')此程式碼實現了標準的 PyTorch 訓練流程。它定義了一個名為*TyreQualityClassifier*的神經網路模型,使用卷積層和線性層對輪胎品質進行分類。訓練循環迭代資料批次,計算損失,並使用反向傳播和最佳化更新模型的參數。此外,它還列印當前時間、紀元、批次和損失以供監控目的。
模型部署
部署
import io
import os
import tarfile
import sagemaker
# 1. Save the PyTorch model to memory
buffer_model = io.BytesIO()
traced_model = torch.jit.script(model)
torch.jit.save(traced_model, buffer_model)
# 2. Upload to AWS S3
sagemaker_session = sagemaker.Session()
bucket_name_default = sagemaker_session.default_bucket()
model_name = f'tyre_quality_classifier.pth'
# 2.1. Zip PyTorch model into tar.gz file
buffer_zip = io.BytesIO()
with tarfile.open(fileobj=buffer_zip, mode="w:gz") as tar:
# Add PyTorch pt file
file_name = os.path.basename(model_name)
file_name_with_extension = os.path.split(file_name)[-1]
tarinfo = tarfile.TarInfo(file_name_with_extension)
tarinfo.size = len(buffer_model.getbuffer())
buffer_model.seek(0)
tar.addfile(tarinfo, buffer_model)
# 2.2. Upload the tar.gz file to S3 bucket
buffer_zip.seek(0)
boto3.resource('s3') \
.Bucket(bucket_name_default) \
.Object(f'pytorch/{model_name}.tar.gz') \
.put(Body=buffer_zip.getvalue())程式碼將 PyTorch 模型儲存到 Amazon S3,因為 SageMaker 要求將模型儲存在 S3 中以便部署。透過將模型上傳到 Amazon S3,SageMaker 就可以存取它,從而允許對已部署的模型進行部署和推理。
import time
from sagemaker.pytorch import PyTorchModel
from sagemaker.predictor import Predictor
from sagemaker.serializers import IdentitySerializer
from sagemaker.deserializers import JSONDeserializer
class TyreQualitySerializer(IdentitySerializer):
CONTENT_TYPE = 'application/x-torch'
def serialize(self, data):
transformed_image = preprocess(data)
tensor_image = torch.Tensor(transformed_image)
serialized_data = io.BytesIO()
torch.save(tensor_image, serialized_data)
serialized_data.seek(0)
serialized_data = serialized_data.read()
return serialized_data
class TyreQualityPredictor(Predictor):
def __init__(self, endpoint_name, sagemaker_session):
super().__init__(
endpoint_name,
sagemaker_session=sagemaker_session,
serializer=TyreQualitySerializer(),
deserializer=JSONDeserializer(),
)
sagemaker_model = PyTorchModel(
model_data=f's3://{bucket_name_default}/pytorch/{model_name}.tar.gz',
role=sagemaker.get_execution_role(),
framework_version='2.0.1',
py_version='py310',
predictor_cls=TyreQualityPredictor,
entry_point='inference.py',
source_dir='code',
)
timestamp = int(time.time())
pytorch_endpoint_name = '{}-{}-{}'.format('tyre-quality-classifier', 'pt', timestamp)
sagemaker_predictor = sagemaker_model.deploy(
initial_instance_count=1,
instance_type='ml.p3.2xlarge',
endpoint_name=pytorch_endpoint_name
)此程式碼有助於在 SageMaker 上部署 PyTorch 模型。它定義了一個自訂序列化器 TyreQualitySerializer,它將輸入資料預處理並序列化為 PyTorch 張量。 TyreQualityPredictor 類別是自訂預測器,它利用定義的序列化器和 JSONDeserializer。程式碼還創建了一個 PyTorchModel 物件來指定模型的 S3 位置、IAM 角色、框架版本和推理的入口點。程式碼產生時間戳並根據模型和時間戳記建立端點名稱。最後,使用 deploy 方法部署模型,指定實例數量、實例類型和產生的端點名稱。這使得 PyTorch 模型可以在 SageMaker 上部署並進行推理。
推理
image_object = list(bucket.objects.filter('dataset/tyre'))[0].get()
image_bytes = image_object['Body'].read()
with Image.open(with Image.open(BytesIO(image_bytes)) as image:
predicted_classes = sagemaker_predictor.predict(image)
print(predicted_classes)這是使用已部署端點進行推理的範例。