

TR-4570:適用於 Apache Spark 的NetApp儲存解決方案:架構、用例和效能結果
 建議變更
建議變更
Rick Huang,Karthikeyan Nagalingam, NetApp
本文檔重點介紹 Apache Spark 架構、客戶用例以及與大數據分析和人工智慧 (AI) 相關的NetApp儲存產品組合。它還展示了使用業界標準 AI、機器學習 (ML) 和深度學習 (DL) 工具針對典型 Hadoop 系統進行的各種測試結果,以便您可以選擇合適的 Spark 解決方案。首先,您需要一個 Spark 架構、適當的元件和兩種部署模式(叢集和用戶端)。
該文件還提供了解決配置問題的客戶用例,並討論了與大數據分析以及 Spark 的 AI、ML 和 DL 相關的NetApp儲存產品組合的概述。然後,我們得到來自 Spark 特定用例和NetApp Spark 解決方案組合的測試結果。
客戶挑戰
本節重點在於零售、數位行銷、銀行、離散製造、流程製造、政府和專業服務等資料成長產業中客戶面臨的大數據分析和 AI/ML/DL 挑戰。
不可預測的表現
傳統的 Hadoop 部署通常使用商品硬體。為了提高效能,您必須調整網路、作業系統、Hadoop 叢集、生態系統元件(如 Spark)和硬體。即使您調整每一層,也很難達到所需的效能水平,因為 Hadoop 運行在並非為您的環境的高效能而設計的商用硬體上。
介質和節點故障
即使在正常條件下,商品硬體也容易故障。如果資料節點上的磁碟發生故障,則 Hadoop 主伺服器預設該節點不健康。然後,它透過網路將該節點上的特定資料從副本複製到健康節點。此過程會減慢任何 Hadoop 作業的網路封包速度。當不健康的節點恢復健康狀態時,叢集必須再次複製資料並刪除過度複製的資料。
Hadoop供應商鎖定
Hadoop 經銷商擁有自己的 Hadoop 發行版和版本控制,將客戶鎖定在這些發行版上。然而,許多客戶需要記憶體分析支持,而這種支援不會將客戶綁定到特定的 Hadoop 發行版。他們需要自由地改變分佈,同時仍保留他們的分析能力。
缺乏對多種語言的支持
客戶通常需要除了 MapReduce Java 程式之外的多種語言支援來執行他們的作業。 SQL 和腳本等選項為獲取答案提供了更大的靈活性,為組織和檢索資料提供了更多的選項,以及將資料移至分析框架的更快的方式。
使用難度
一段時間以來,人們一直抱怨 Hadoop 難以使用。儘管 Hadoop 的每個新版本都變得更簡單、更強大,但這種批評仍然存在。 Hadoop 要求您了解 Java 和 MapReduce 程式模式,這對資料庫管理員和具有傳統腳本技能的人員來說是一個挑戰。
複雜的框架和工具
企業AI團隊面臨多重挑戰。即使擁有專業的數據科學知識,不同部署生態系統和應用程式的工具和框架也可能無法簡單地從一個轉換到另一個。數據科學平台應該與基於 Spark 構建的相應大數據平台無縫集成,易於數據移動、可重複使用的模型、開箱即用的代碼以及支持原型設計、驗證、版本控制、共享、重用和快速將模型部署到生產的最佳實踐的工具。
為什麼選擇NetApp?
NetApp可以透過以下方式改善您的 Spark 體驗:
-
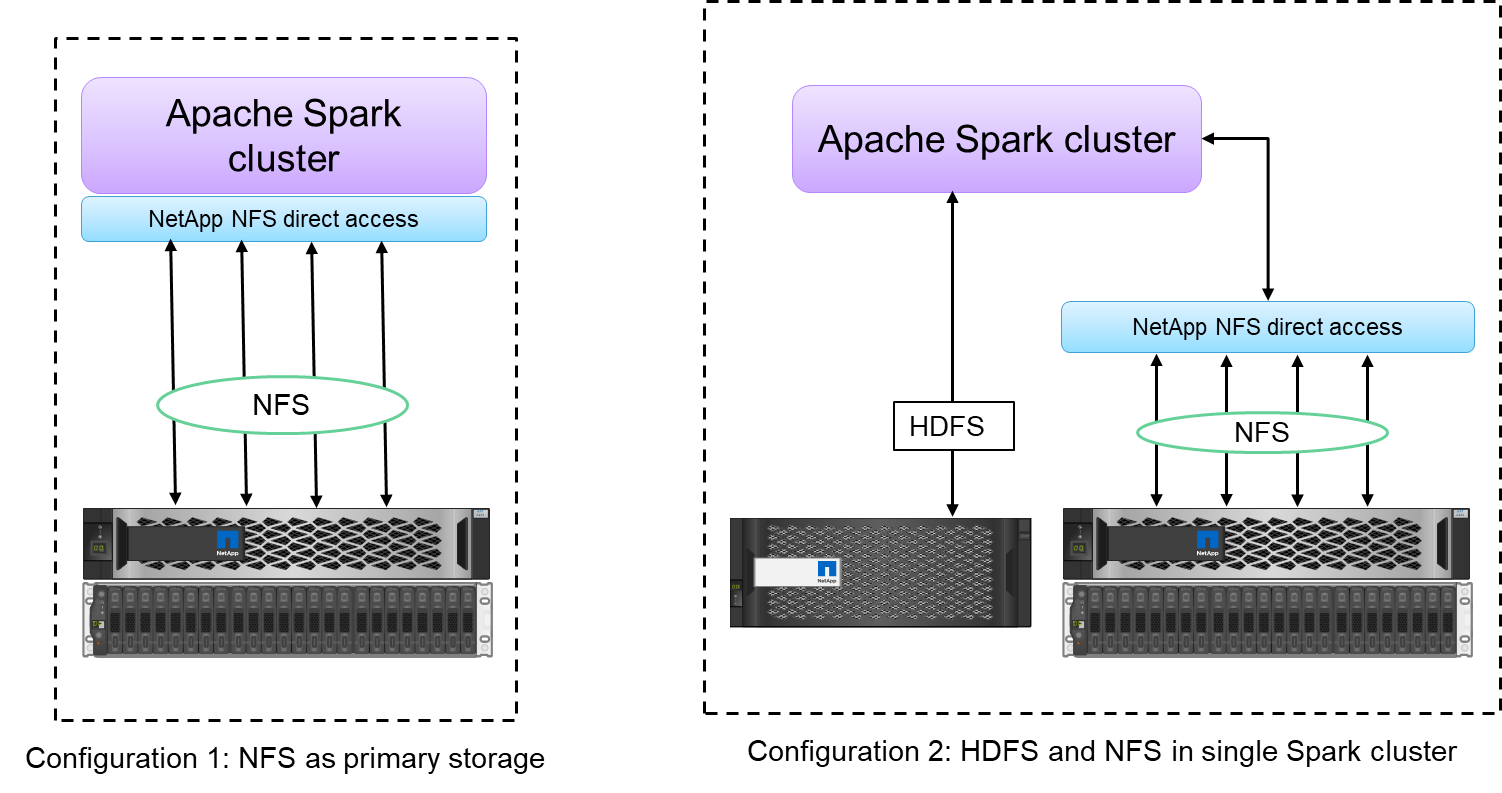
NetApp NFS 直接存取(如下圖所示)允許客戶在其現有或新的 NFSv3 或 NFSv4 資料上執行大數據分析作業,而無需移動或複製資料。它可以防止資料的多次複製,並且無需將資料與來源同步。
-
更有效率的儲存和更少的伺服器複製。例如, NetApp E 系列 Hadoop 解決方案需要兩個而不是三個資料副本,而FAS Hadoop 解決方案需要一個資料來源,但不需要資料複製或副本。 NetApp儲存解決方案還能減少伺服器之間的流量。
-
驅動器和節點故障期間更好的 Hadoop 作業和叢集行為。
-
更好的數據提取性能。
例如,在金融和醫療保健領域,資料從一個地方移動到另一個地方必須滿足法律義務,這不是一件容易的事。在這種情況下, NetApp NFS 直接存取會從原始位置分析財務和醫療保健資料。另一個主要優勢是,使用NetApp NFS 直接存取可以透過使用本機 Hadoop 指令簡化 Hadoop 資料的保護,並利用NetApp豐富的資料管理產品組合來實現資料保護工作流程。
NetApp NFS 直接存取為 Hadoop/Spark 叢集提供了兩種部署選項:
-
預設情況下,Hadoop 或 Spark 叢集使用 Hadoop 分散式檔案系統 (HDFS) 進行資料儲存和預設檔案系統。 NetApp NFS 直接存取可以用 NFS 儲存取代預設的 HDFS 作為預設檔案系統,從而實現對 NFS 資料的直接分析。
-
在另一個部署選項中, NetApp NFS 直接存取支援在單一 Hadoop 或 Spark 叢集中將 NFS 與 HDFS 一起配置為附加儲存。在這種情況下,客戶可以透過 NFS 匯出共享數據,並從同一集群存取數據以及 HDFS 數據。
使用NetApp NFS 直接存取的主要優勢包括:
-
從目前位置分析數據,從而避免將分析數據移動到 Hadoop 基礎架構(如 HDFS)這一耗時耗能的任務。
-
將副本數量從三個減少到一個。
-
使用戶能夠分離計算和存儲以獨立擴展它們。
-
利用ONTAP豐富的資料管理功能提供企業資料保護。
-
通過 Hortonworks 資料平台認證。
-
支援混合資料分析部署。
-
利用動態多執行緒功能減少備份時間。
看"TR-4657: NetApp混合雲資料解決方案 - 基於客戶使用案例的 Spark 和 Hadoop"用於備份 Hadoop 資料、從雲端到本地的備份和災難復原、對現有 Hadoop 資料進行 DevTest、資料保護和多雲連接以及加速分析工作負載。
以下部分介紹了對 Spark 客戶來說重要的儲存功能。
儲存分層
透過 Hadoop 儲存分層,您可以根據儲存策略儲存具有不同儲存類型的檔案。儲存類型包括 hot, cold , warm , all_ssd , one_ssd , 和 lazy_persist。
我們在NetApp AFF儲存控制器和具有不同儲存策略的 SSD 和 SAS 磁碟機的 E 系列儲存控制器上對 Hadoop 儲存分層進行了驗證。具有AFF-A800 的 Spark 叢集有四個運算工作節點,而有 E 系列的叢集有八個。這主要是為了比較固態硬碟 (SSD) 與硬碟 (HDD) 的效能。
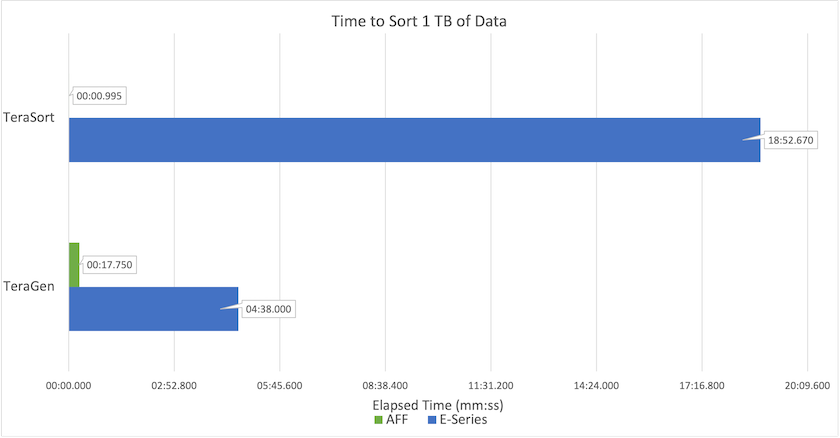
下圖顯示了NetApp針對 Hadoop SSD 的解決方案的效能。
-
基線 NL-SAS 配置使用八個運算節點和 96 個 NL-SAS 磁碟機。此配置在 4 分 38 秒內產生了 1TB 的資料。看 "TR-3969 NetApp E系列Hadoop解決方案"有關叢集和儲存配置的詳細資訊。
-
使用 TeraGen,SSD 配置產生 1TB 資料的速度比 NL-SAS 配置快 15.66 倍。此外,SSD 配置使用了一半數量的計算節點和一半數量的磁碟機(總共 24 個 SSd 磁碟機)。根據作業完成時間,它幾乎比 NL-SAS 配置快兩倍。
-
使用 TeraSort,SSD 配置對 1TB 資料的排序速度比 NL-SAS 配置快 1138.36 倍。此外,SSD 配置使用了一半數量的計算節點和一半數量的磁碟機(總共 24 個 SSd 磁碟機)。因此,每個驅動器的速度大約比 NL-SAS 配置快三倍。
-
重點是從旋轉磁碟過渡到全快閃記憶體可以提高效能。計算節點的數量不是瓶頸。借助 NetApp 的全快閃存儲,運行時性能可以很好地擴展。
-
使用 NFS,資料在功能上相當於被集中在一起,這可以根據您的工作負載減少計算節點的數量。 Apache Spark 叢集使用者在更改運算節點數量時不必手動重新平衡資料。
效能擴展 - 橫向擴展
當您需要從AFF解決方案中的 Hadoop 叢集取得更多運算能力時,您可以新增具有適當數量儲存控制器的資料節點。 NetApp建議從每個儲存控制器陣列 4 個資料節點開始,然後根據工作負載特性將每個儲存控制器的資料節點數量增加到 8 個。
AFF和FAS非常適合就地分析。根據運算需求,您可以新增節點管理器,且無中斷操作可讓您按需新增儲存控制器而無需停機。我們提供AFF和FAS的豐富功能,例如 NVME 媒體支援、保證效率、資料減少、QOS、預測分析、雲端分層、複製、雲端部署和安全性。為了幫助客戶滿足他們的需求, NetApp提供了檔案系統分析、配額和機上負載平衡等功能,無需額外的授權費用。 NetApp在並發作業數量、更低的延遲、更簡單的操作以及更高的每秒千兆位元組吞吐量方面比我們的競爭對手錶現更好。此外, NetApp Cloud Volumes ONTAP可在三大雲端供應商上運作。
效能擴展 - 擴大規模
當您需要額外的儲存容量時,擴充功能可讓您將磁碟機新增至AFF、 FAS和 E 系列系統。使用Cloud Volumes ONTAP,將儲存擴展到 PB 層級需要結合兩個因素:將不常用的資料從區塊儲存分層到物件存儲,以及堆疊Cloud Volumes ONTAP授權而無需額外的運算。
多種協定
NetApp系統支援大多數 Hadoop 部署協議,包括 SAS、iSCSI、FCP、InfiniBand 和 NFS。
營運和支援的解決方案
本文檔中所述的 Hadoop 解決方案由NetApp支援。這些解決方案也經過了主要 Hadoop 經銷商的認證。欲了解更多信息,請參閱 "Hortonworks"站點和 Cloudera "認證"和 "夥伴"站點。