

解決方案技術
 建議變更
建議變更
Apache Spark 是一種流行的程式框架,用於編寫可直接與 Hadoop 分散式檔案系統 (HDFS) 協同工作的 Hadoop 應用程式。 Spark 已準備好投入生產,支援串流資料處理,並且比 MapReduce 更快。 Spark 具有可配置的記憶體資料緩存,可實現高效迭代,並且 Spark shell 具有互動性,可用於學習和探索資料。使用 Spark,您可以用 Python、Scala 或 Java 建立應用程式。 Spark 應用程式由一個或多個具有一個或多個任務的作業組成。
每個 Spark 應用程式都有一個 Spark 驅動程式。在 YARN-Client 模式下,驅動程式在客戶端本地運行。在 YARN-Cluster 模式下,驅動程式在應用程式主機上的叢集中運作。在叢集模式下,即使客戶端斷開連接,應用程式仍繼續運作。
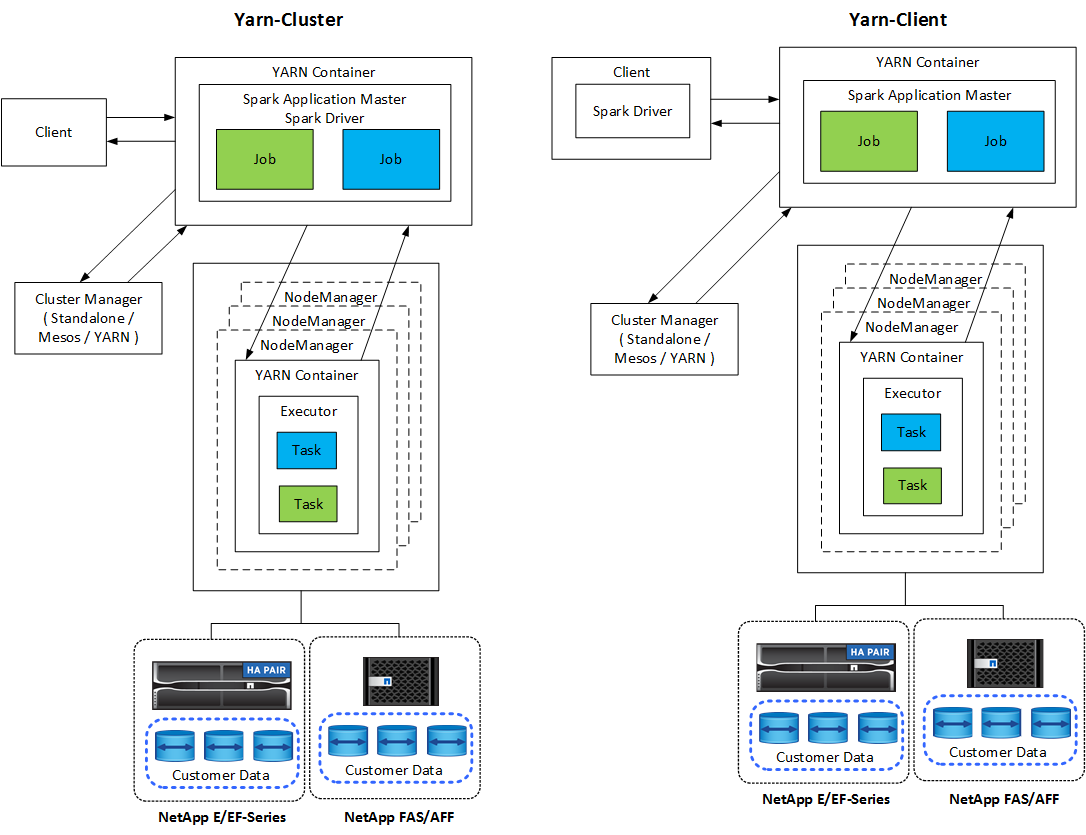
有三個集群管理器:
-
*獨立。 *此管理器是 Spark 的一部分,可以輕鬆設定叢集。
-
Apache Mesos。這是一個通用叢集管理器,也運行 MapReduce 和其他應用程式。
-
Hadoop YARN。這是 Hadoop 3 中的資源管理器。
彈性分散式資料集(RDD)是 Spark 的主要元件。 RDD 從叢集記憶體中儲存的資料重新建立遺失和缺少的數據,並儲存來自檔案或以程式設計方式建立的初始資料。 RDD 是從檔案、記憶體中的資料或另一個 RDD 建立的。 Spark 程式設計執行兩種操作:轉換和操作。轉換基於現有 RDD 建立新的 RDD。操作從 RDD 傳回一個值。
轉換和操作也適用於 Spark 資料集和 DataFrames。資料集是分散式資料集合,它兼具 RDD 的優勢(強型別、使用 lambda 函數)和 Spark SQL 優化執行引擎的優勢。可以從 JVM 物件建立資料集,然後使用功能轉換(map、flatMap、filter 等)進行操作。 DataFrame 是按命名列組織起來的資料集。它在概念上等同於關聯式資料庫中的表或 R/Python 中的資料框。 DataFrames 可以從多種來源構建,例如結構化資料檔案、Hive/HBase 中的表、本地或雲端的外部資料庫或現有的 RDD。
Spark 應用程式包括一個或多個 Spark 作業。作業在執行器中運行任務,執行器在 YARN 容器中運行。每個執行器都在單一容器中運行,並且執行器在應用程式的整個生命週期中都存在。應用程式啟動後,執行器就固定了,YARN 不會調整已指派的容器的大小。執行器可以對記憶體資料同時運行任務。