測試結果
 建議變更
建議變更
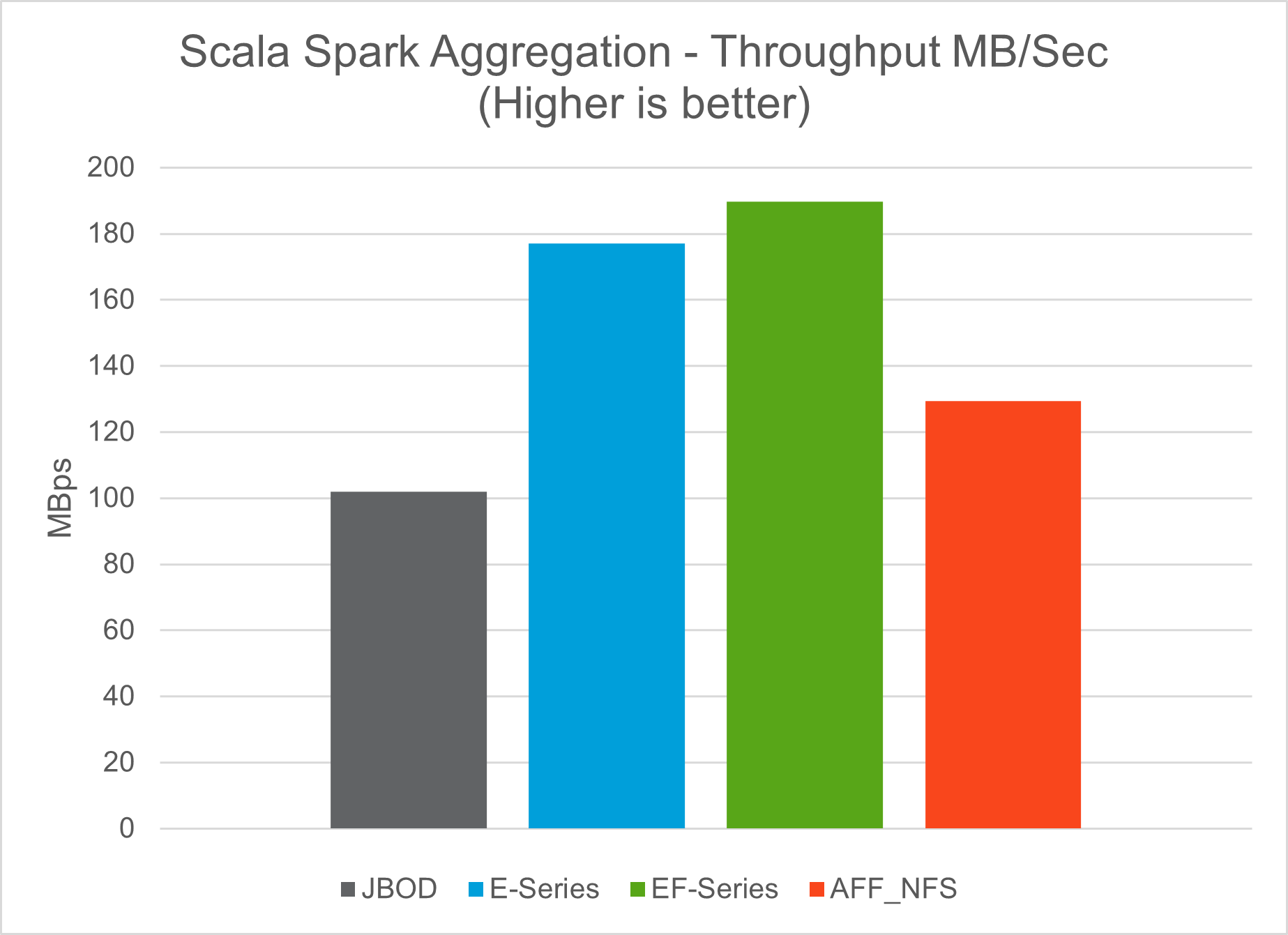
我們使用 TeraGen 基準測試工具中的 TeraSort 和 TeraValidate 腳本來測量 E5760、E5724 和AFF-A800 配置的 Spark 效能驗證。此外,還測試了三個主要用例:Spark NLP 管道和 TensorFlow 分散式訓練、Horovod 分散式訓練以及使用 Keras 進行 DeepFM CTR 預測的多工深度學習。
對於 E 系列和StorageGRID驗證,我們使用了 Hadoop 複製因子 2。對於AFF驗證,我們只使用一個資料來源。
下表列出了 Spark 效能驗證的硬體配置。
| 類型 | Hadoop 工作節點 | 驅動器類型 | 每個節點的驅動器 | 儲存控制器 |
|---|---|---|---|---|
SG6060 |
4 |
SAS |
12 |
單一高可用性 (HA) 對 |
E5760 |
4 |
SAS |
60 |
單一 HA 對 |
E5724 |
4 |
SAS |
24 |
單一 HA 對 |
AFF800 |
4 |
固態硬碟 |
6 |
單一 HA 對 |
下表列出了軟體要求。
| 軟體 | 版本 |
|---|---|
紅帽企業版 |
7.9 |
OpenJDK 運作環境 |
1.8.0 |
OpenJDK 64 位元伺服器虛擬機 |
25.302 |
Git |
2.24.1 |
GCC/G++ |
11.2.1 |
火花 |
3.2.1 |
PySpark |
3.1.2 |
SparkNLP |
3.4.2 |
TensorFlow |
2.9.0 |
喀拉拉 |
2.9.0 |
霍羅沃德 |
0.24.3 |
金融情緒分析
我們發表了"TR-4910:利用NetApp AI 進行客戶溝通情緒分析",其中使用 "NetApp DataOps 工具包"、 AFF儲存和NVIDIA DGX 系統。此管道利用 DataOps Toolkit 執行批量音訊訊號處理、自動語音辨識 (ASR)、遷移學習和情緒分析, "NVIDIA Riva SDK" ,以及 "道框架"。將情緒分析用例擴展到金融服務業,我們建立了 SparkNLP 工作流程,為各種 NLP 任務(例如命名實體識別)加載了三個 BERT 模型,並獲得了納斯達克十大公司季度收益電話會議的句子級情緒。
以下腳本 `sentiment_analysis_spark. py`使用 FinBERT 模型處理 HDFS 中的轉錄本,並產生正面、中性和負面情緒計數,如下表所示:
-bash-4.2$ time ~/anaconda3/bin/spark-submit --packages com.johnsnowlabs.nlp:spark-nlp_2.12:3.4.3 --master yarn --executor-memory 5g --executor-cores 1 --num-executors 160 --conf spark.driver.extraJavaOptions="-Xss10m -XX:MaxPermSize=1024M" --conf spark.executor.extraJavaOptions="-Xss10m -XX:MaxPermSize=512M" /sparkusecase/tr-4570-nlp/sentiment_analysis_spark.py hdfs:///data1/Transcripts/ > ./sentiment_analysis_hdfs.log 2>&1 real13m14.300s user557m11.319s sys4m47.676s
下表列出了 2016 年至 2020 年納斯達克十大公司的收益電話會議句子級情緒分析。
| 情緒計數和百分比 | 全部 10 家公司 | 蘋果 | AMD | 亞馬遜 | 思科 | 國際貿易中心 | 微軟 | NVDA | |
|---|---|---|---|---|---|---|---|---|---|
正計數 |
7447 |
1567 |
743 |
290 |
682 |
826 |
824 |
904 |
417 |
中立計數 |
64067 |
6856 |
7596 |
5086 |
6650 |
5914 |
6099 |
5715 |
6189 |
負數 |
1787 |
253 |
213 |
84 |
189 |
97 |
282 |
202 |
89 |
未分類的計數 |
196 |
0 |
0 |
76 |
0 |
0 |
0 |
1 |
0 |
(總數) |
73497 |
8676 |
8552 |
5536 |
7521 |
6837 |
7205 |
6822 |
6695 |
從百分比來看,執行長和財務長所說的大多數句子都是事實,因此帶有中立的情緒。在收益電話會議期間,分析師提出的問題可能會傳達正面或負面的情緒。值得進一步定量研究負面或正面情緒如何影響交易當天或隔天的股票價格。
下表列出了納斯達克十大公司的句子級情感分析,以百分比表示。
| 情緒百分比 | 全部 10 家公司 | 蘋果 | AMD | 亞馬遜 | 思科 | 國際貿易中心 | 微軟 | NVDA | |
|---|---|---|---|---|---|---|---|---|---|
積極的 |
10.13% |
18.06% |
8.69% |
5.24% |
9.07% |
12.08% |
11.44% |
13.25% |
6.23% |
中性的 |
87.17% |
79.02% |
88.82% |
91.87% |
88.42% |
86.50% |
84.65% |
83.77% |
92.44% |
消極的 |
2.43% |
2.92% |
2.49% |
1.52% |
2.51% |
1.42% |
3.91% |
2.96% |
1.33% |
未分類 |
0.27% |
0% |
0% |
1.37% |
0% |
0% |
0% |
0.01% |
0% |
在工作流程運行時方面,我們看到了顯著的 4.78 倍改進 `local`模式到 HDFS 中的分散式環境,並透過利用 NFS 進一步提高 0.14%。
-bash-4.2$ time ~/anaconda3/bin/spark-submit --packages com.johnsnowlabs.nlp:spark-nlp_2.12:3.4.3 --master yarn --executor-memory 5g --executor-cores 1 --num-executors 160 --conf spark.driver.extraJavaOptions="-Xss10m -XX:MaxPermSize=1024M" --conf spark.executor.extraJavaOptions="-Xss10m -XX:MaxPermSize=512M" /sparkusecase/tr-4570-nlp/sentiment_analysis_spark.py file:///sparkdemo/sparknlp/Transcripts/ > ./sentiment_analysis_nfs.log 2>&1 real13m13.149s user537m50.148s sys4m46.173s
如下圖所示,資料和模型並行提高了資料處理和分散式 TensorFlow 模型推理的速度。 NFS 中的資料位置產生了稍微更好的運行時間,因為工作流程瓶頸是預訓練模型的下載。如果我們增加成績單資料集的大小,NFS 的優勢就更加明顯。
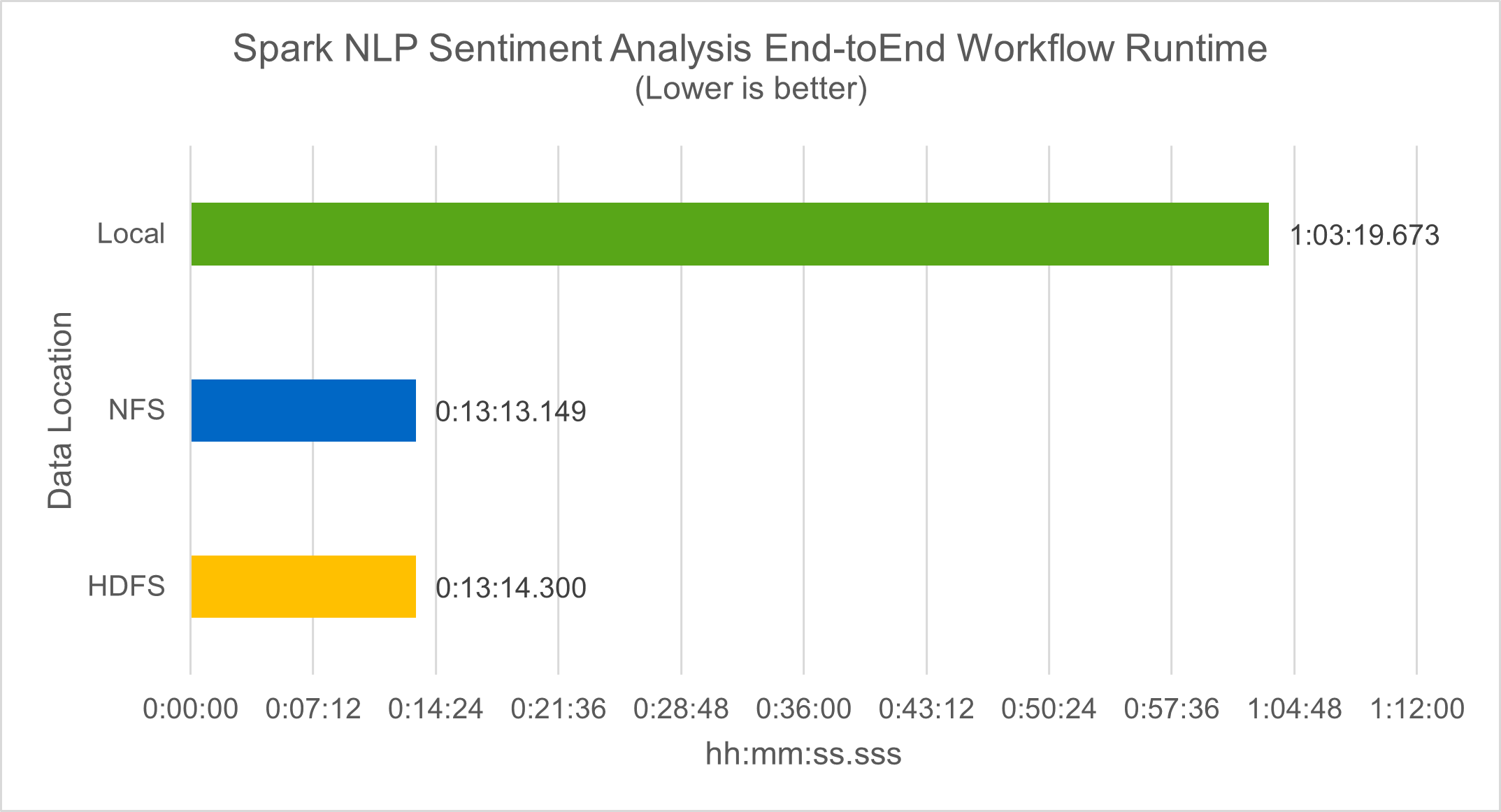
Horovod 表現的分散式訓練
以下命令使用單一 master`具有 160 個執行器的節點,每個執行器都有一個核心。執行器記憶體限制為 5GB,以避免記憶體不足錯誤。請參閱"針對每個主要用例的 Python 腳本"有關數據處理、模型訓練和模型準確率計算的更多詳細信息,請參閱 `keras_spark_horovod_rossmann_estimator.py。
(base) [root@n138 horovod]# time spark-submit --master local --executor-memory 5g --executor-cores 1 --num-executors 160 /sparkusecase/horovod/keras_spark_horovod_rossmann_estimator.py --epochs 10 --data-dir file:///sparkusecase/horovod --local-submission-csv /tmp/submission_0.csv --local-checkpoint-file /tmp/checkpoint/ > /tmp/keras_spark_horovod_rossmann_estimator_local. log 2>&1
經過 10 個訓練週期後,最終的運行時間如下:
real43m34.608s user12m22.057s sys2m30.127s
處理輸入資料、訓練 DNN 模型、計算準確度以及產生 TensorFlow 檢查點和預測結果的 CSV 檔案花費了超過 43 分鐘。我們將訓練週期數限制為 10,在實踐中通常設定為 100,以確保令人滿意的模型準確率。訓練時間通常與訓練次數呈線性關係。
接下來,我們使用叢集中可用的四個工作節點,並在 `yarn`HDFS 中的資料模式:
(base) [root@n138 horovod]# time spark-submit --master yarn --executor-memory 5g --executor-cores 1 --num-executors 160 /sparkusecase/horovod/keras_spark_horovod_rossmann_estimator.py --epochs 10 --data-dir hdfs:///user/hdfs/tr-4570/experiments/horovod --local-submission-csv /tmp/submission_1.csv --local-checkpoint-file /tmp/checkpoint/ > /tmp/keras_spark_horovod_rossmann_estimator_yarn.log 2>&1
最終的運轉時間改進如下:
real8m13.728s user7m48.421s sys1m26.063s
借助 Horovod 模型和 Spark 中的資料並行性,我們看到運行速度提高了 5.29 倍 yarn`相對 `local`具有十個訓練階段的模式。下圖中圖例顯示了這一點 `HDFS`和 `Local。如果可用的話,可以使用 GPU 進一步加速底層 TensorFlow DNN 模型訓練。我們計劃進行此項測試並在未來的技術報告中發布結果。
我們的下一個測試比較了 NFS 和 HDFS 中的輸入資料的運行時間。 AFF A800上的 NFS 磁碟區已安裝在 `/sparkdemo/horovod`分佈於 Spark 叢集的五個節點(一個主節點,四個工作節點)上。我們運行了與先前的測試類似的命令, `--data- dir`參數現在指向 NFS 掛載:
(base) [root@n138 horovod]# time spark-submit --master yarn --executor-memory 5g --executor-cores 1 --num-executors 160 /sparkusecase/horovod/keras_spark_horovod_rossmann_estimator.py --epochs 10 --data-dir file:///sparkdemo/horovod --local-submission-csv /tmp/submission_2.csv --local-checkpoint-file /tmp/checkpoint/ > /tmp/keras_spark_horovod_rossmann_estimator_nfs.log 2>&1
使用 NFS 的運行結果如下:
real 5m46.229s user 5m35.693s sys 1m5.615s
速度又提高了 1.43 倍,如下圖所示。因此,透過將NetApp全快閃儲存連接到其集群,客戶可以享受 Horovod Spark 工作流程的快速資料傳輸和分發優勢,與在單一節點上運行相比,可實現 7.55 倍的加速。
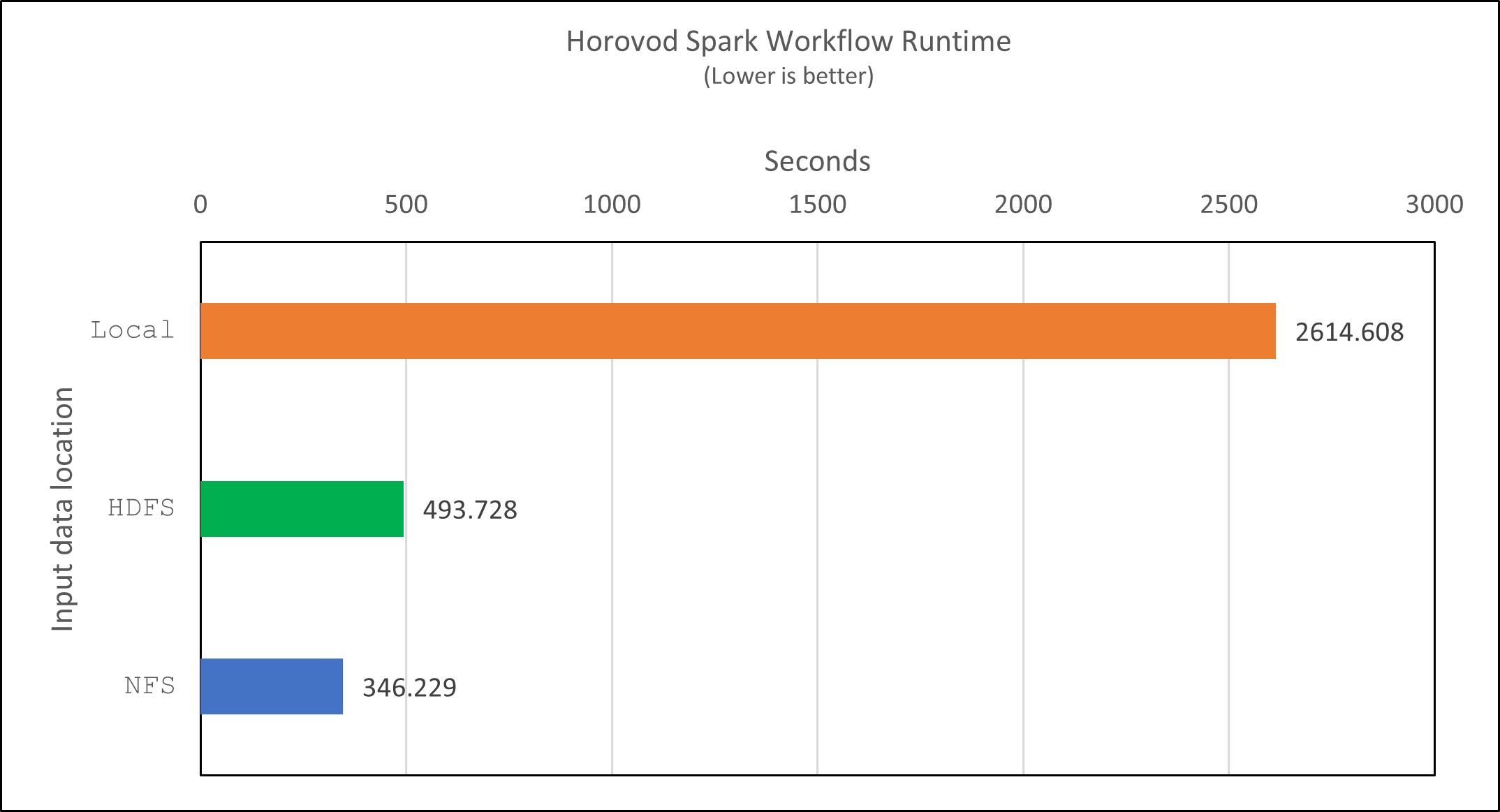
CTR預測表現的深度學習模型
對於旨在最大化點擊率的推薦系統,必須學習使用者行為背後複雜的特徵交互,這些特徵交互可以透過數學方式從低階到高階計算。對於良好的深度學習模型來說,低階和高階特徵交叉應該同等重要,而不應偏向其中任何一方。深度分解機(DeepFM)是一種基於分解機的神經網絡,它將用於推薦的分解機和用於特徵學習的深度學習結合在新的神經網路架構中。
雖然傳統的分解機將成對的特徵交叉建模為特徵之間潛在向量的內積,並且理論上可以捕獲高階信息,但在實踐中,機器學習從業者通常只使用二階特徵交叉,因為計算和存儲複雜度很高。深度神經網路變體,例如Google的 "廣度與深度模型"另一方面,透過結合線性寬模型和深度模型,在混合網路結構中學習複雜的特徵交互作用。
這個 Wide & Deep 模型有兩個輸入,一個用於底層的廣度模型,另一個用於深度模型,後者仍然需要專家的特徵工程,因此該技術不太適用於其他領域。與廣度和深度模型不同,DeepFM 可以使用原始特徵進行有效訓練,而無需任何特徵工程,因為它的廣度部分和深度部分共享相同的輸入和嵌入向量。
我們首先處理了 Criteo train.txt (11GB)檔案轉換為名為 `ctr_train.csv`儲存在 NFS 掛載中 `/sparkdemo/tr-4570-data`使用 `run_classification_criteo_spark.py`來自部分"每個主要用例的 Python 腳本。"在此腳本中,函數 `process_input_file`執行幾個字串方法來刪除製表符並插入 ','`作為分隔符號和 '\n'`作為換行符。請注意,您只需處理原始 `train.txt`一次,這樣程式碼區塊就顯示為註解。
為了對不同的 DL 模型進行以下測試,我們使用 ctr_train.csv`作為輸入檔。在後續的測試運行中,輸入的 CSV 檔案被讀入 Spark DataFrame,其模式包含以下字段 'label',整數密集特徵 ['I1', 'I2', 'I3', …, 'I13']`和稀疏特徵 `['C1', 'C2', 'C3', …, 'C26']。下列 `spark-submit`指令接受輸入 CSV,以 20% 的比例訓練 DeepFM 模型進行交叉驗證,並在十個訓練週期後選出最佳模型來計算測試集上的預測準確率:
(base) [root@n138 ~]# time spark-submit --master yarn --executor-memory 5g --executor-cores 1 --num-executors 160 /sparkusecase/DeepCTR/examples/run_classification_criteo_spark.py --data-dir file:///sparkdemo/tr-4570-data > /tmp/run_classification_criteo_spark_local.log 2>&1
請注意,由於數據文件 `ctr_train.csv`超過 11GB,則必須設定足夠的 `spark.driver.maxResultSize`大於資料集大小以避免錯誤。
spark = SparkSession.builder \
.master("yarn") \
.appName("deep_ctr_classification") \
.config("spark.jars.packages", "io.github.ravwojdyla:spark-schema-utils_2.12:0.1.0") \
.config("spark.executor.cores", "1") \
.config('spark.executor.memory', '5gb') \
.config('spark.executor.memoryOverhead', '1500') \
.config('spark.driver.memoryOverhead', '1500') \
.config("spark.sql.shuffle.partitions", "480") \
.config("spark.sql.execution.arrow.enabled", "true") \
.config("spark.driver.maxResultSize", "50gb") \
.getOrCreate()
在上述 `SparkSession.builder`配置我們還啟用了 "阿帕契箭",將 Spark DataFrame 轉換為 Pandas DataFrame, `df.toPandas()`方法。
22/06/17 15:56:21 INFO scheduler.DAGScheduler: Job 2 finished: toPandas at /sparkusecase/DeepCTR/examples/run_classification_criteo_spark.py:96, took 627.126487 s Obtained Spark DF and transformed to Pandas DF using Arrow.
隨機分割後,訓練資料集中有超過 3,600 萬行,測試集中有 900 萬個樣本:
Training dataset size = 36672493 Testing dataset size = 9168124
由於本技術報告專注於不使用任何 GPU 的 CPU 測試,因此必須使用適當的編譯器標誌來建立 TensorFlow。此步驟避免呼叫任何 GPU 加速函式庫,並充分利用 TensorFlow 的高階向量擴充 (AVX) 和 AVX2 指令。這些特徵是為線性代數計算而設計的,例如向量加法、前饋中的矩陣乘法或反向傳播 DNN 訓練。 AVX2 提供的融合乘加 (FMA) 指令使用 256 位元浮點 (FP) 暫存器,非常適合整數程式碼和資料類型,可實現高達 2 倍的加速。對於 FP 程式碼和資料類型,AVX2 比 AVX 實現了 8% 的加速。
2022-06-18 07:19:20.101478: I tensorflow/core/platform/cpu_feature_guard.cc:151] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 FMA To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
若要從原始碼建置 TensorFlow, NetApp建議使用 "巴澤爾"。對於我們的環境,我們在 shell 提示字元下執行以下命令來安裝 dnf, dnf-plugins ,以及 Bazel。
yum install dnf dnf install 'dnf-command(copr)' dnf copr enable vbatts/bazel dnf install bazel5
您必須啟用 GCC 5 或更新版本才能在建置過程中使用 C++17 功能,該功能由 RHEL 透過軟體集合庫 (SCL) 提供。以下命令安裝 `devtoolset`以及 RHEL 7.9 叢集上的 GCC 11.2.1:
subscription-manager repos --enable rhel-server-rhscl-7-rpms yum install devtoolset-11-toolchain yum install devtoolset-11-gcc-c++ yum update scl enable devtoolset-11 bash . /opt/rh/devtoolset-11/enable
請注意,最後兩個命令啟用 devtoolset-11,使用 /opt/rh/devtoolset-11/root/usr/bin/gcc(GCC 11.2.1)。此外,請確保您的 `git`版本高於 1.8.3(隨 RHEL 7.9 提供)。參考這個 "文章"用於更新 `git`至 2.24.1。
我們假設您已經克隆了最新的 TensorFlow 主倉庫。然後創建一個 `workspace`目錄與 `WORKSPACE`檔案使用 AVX、AVX2 和 FMA 從原始程式碼建置 TensorFlow。運行 `configure`檔案並指定正確的 Python 二進位位置。 "CUDA"由於我們沒有使用 GPU,因此在我們的測試中被停用。一個 `.bazelrc`文件根據您的設定產生。此外,我們編輯了文件並設置 `build --define=no_hdfs_support=false`啟用 HDFS 支援。參考 `.bazelrc`在本節中"針對每個主要用例的 Python 腳本,"以獲得完整的設定和標誌清單。
./configure bazel build -c opt --copt=-mavx --copt=-mavx2 --copt=-mfma --copt=-mfpmath=both -k //tensorflow/tools/pip_package:build_pip_package
使用正確的標誌建立 TensorFlow 後,執行以下腳本來處理 Criteo Display Ads 資料集,訓練 DeepFM 模型,並根據預測分數計算接收者操作特徵曲線下面積 (ROC AUC)。
(base) [root@n138 examples]# ~/anaconda3/bin/spark-submit --master yarn --executor-memory 15g --executor-cores 1 --num-executors 160 /sparkusecase/DeepCTR/examples/run_classification_criteo_spark.py --data-dir file:///sparkdemo/tr-4570-data > . /run_classification_criteo_spark_nfs.log 2>&1
經過十次訓練後,我們獲得了測試資料集上的 AUC 分數:
Epoch 1/10 125/125 - 7s - loss: 0.4976 - binary_crossentropy: 0.4974 - val_loss: 0.4629 - val_binary_crossentropy: 0.4624 Epoch 2/10 125/125 - 1s - loss: 0.3281 - binary_crossentropy: 0.3271 - val_loss: 0.5146 - val_binary_crossentropy: 0.5130 Epoch 3/10 125/125 - 1s - loss: 0.1948 - binary_crossentropy: 0.1928 - val_loss: 0.6166 - val_binary_crossentropy: 0.6144 Epoch 4/10 125/125 - 1s - loss: 0.1408 - binary_crossentropy: 0.1383 - val_loss: 0.7261 - val_binary_crossentropy: 0.7235 Epoch 5/10 125/125 - 1s - loss: 0.1129 - binary_crossentropy: 0.1102 - val_loss: 0.7961 - val_binary_crossentropy: 0.7934 Epoch 6/10 125/125 - 1s - loss: 0.0949 - binary_crossentropy: 0.0921 - val_loss: 0.9502 - val_binary_crossentropy: 0.9474 Epoch 7/10 125/125 - 1s - loss: 0.0778 - binary_crossentropy: 0.0750 - val_loss: 1.1329 - val_binary_crossentropy: 1.1301 Epoch 8/10 125/125 - 1s - loss: 0.0651 - binary_crossentropy: 0.0622 - val_loss: 1.3794 - val_binary_crossentropy: 1.3766 Epoch 9/10 125/125 - 1s - loss: 0.0555 - binary_crossentropy: 0.0527 - val_loss: 1.6115 - val_binary_crossentropy: 1.6087 Epoch 10/10 125/125 - 1s - loss: 0.0470 - binary_crossentropy: 0.0442 - val_loss: 1.6768 - val_binary_crossentropy: 1.6740 test AUC 0.6337
以與先前的用例類似的方式,我們將 Spark 工作流程運行時與位於不同位置的資料進行了比較。下圖顯示了 Spark 工作流程運行時深度學習 CTR 預測的比較。