TR-4912: NetApp Confluent Kafka 分層儲存最佳實務指南
 建議變更
建議變更
Karthikeyan Nagalingam、Joseph Kandatilparambil、 NetApp Rankesh Kumar、Confluence
Apache Kafka 是一個社群分散式事件流平台,每天都能夠處理數兆個事件。 Kafka 最初被認為是一個訊息佇列,基於分散式提交日誌的抽象化。自 2011 年由 LinkedIn 創建並開源以來,Kafka 已經從一個訊息佇列發展成為一個成熟的事件流平台。 Confluent 透過 Confluent 平台提供 Apache Kafka 的分發。 Confluent 平台為 Kafka 提供了額外的社群和商業功能,旨在增強大規模生產中營運商和開發人員的串流體驗。
本文檔透過提供以下內容描述了在 NetApp 物件儲存產品上使用 Confluent 分層儲存的最佳實踐指南:
-
使用NetApp物件儲存進行匯合驗證 – NetApp StorageGRID
-
分層儲存效能測試
-
NetApp儲存系統上 Confluent 的最佳實務指南
為什麼選擇 Confluent 分層儲存?
Confluent 已成為許多應用程式的預設即時串流平台,尤其是對於大數據、分析和串流媒體工作負載。分層儲存使用戶能夠在 Confluent 平台中將運算與儲存分開。它使儲存資料更具成本效益,使您能夠儲存幾乎無限量的資料並按需擴大(或縮小)工作負載,並使資料和租戶重新平衡等管理任務更加容易。 S3 相容儲存系統可以利用所有這些功能,將所有事件集中在一個地方,實現資料民主化,因此無需複雜的資料工程。有關為什麼應該為 Kafka 使用分層存儲的更多信息,請查看"本文由 Confluent 撰寫"。
NetApp instaclustr 從 3.8.1 版本開始也支援 Kafka 分層儲存。請點擊此處查看更多詳情 "使用 Kafka 分層儲存的 Instaclust"
為什麼選擇NetApp StorageGRID進行分層儲存?
StorageGRID是NetApp推出的業界領先的物件儲存平台。 StorageGRID是一種軟體定義的基於物件的儲存解決方案,支援業界標準物件 API,包括 Amazon Simple Storage Service (S3) API。 StorageGRID大規模儲存和管理非結構化數據,以提供安全、持久的物件儲存。內容被放置在正確的位置、正確的時間和正確的儲存層,從而優化工作流程並降低全球分佈的富媒體的成本。
StorageGRID最大的差異在於其資訊生命週期管理 (ILM) 策略引擎,它支援策略驅動的資料生命週期管理。策略引擎可以使用元資料來管理資料在其整個生命週期內的儲存方式,以便最初優化效能,並隨著資料老化自動優化成本和耐用性。
啟用 Confluent 分層存儲
分層儲存的基本概念是將資料儲存任務與資料處理任務分開。透過這種分離,資料儲存層和資料處理層可以更輕鬆地獨立擴展。
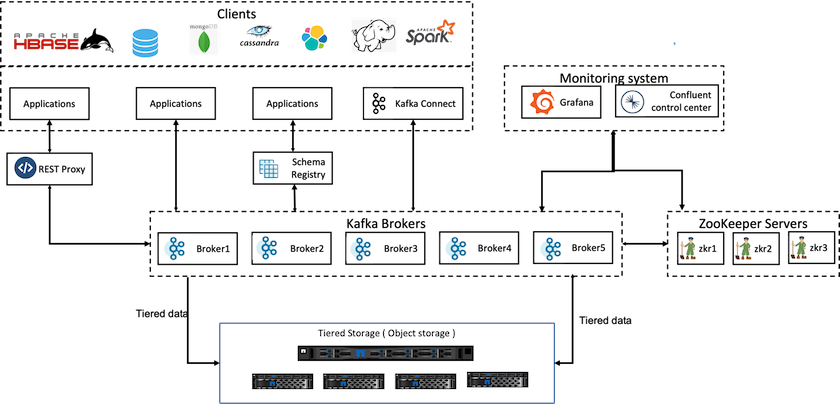
Confluent 的分層儲存解決方案必須處理兩個因素。首先,它必須解決或避免常見的物件儲存一致性和可用性屬性,例如 LIST 操作中的不一致和偶爾的物件不可用。其次,它必須正確處理分層儲存與 Kafka 的複製和容錯模型之間的交互,包括殭屍領導者繼續分層偏移範圍的可能性。 NetApp物件儲存提供一致的物件可用性和 HA 模型,使分層儲存可用於層偏移範圍。 NetApp物件儲存提供一致的物件可用性和 HA 模型,使分層儲存可用於層偏移範圍。
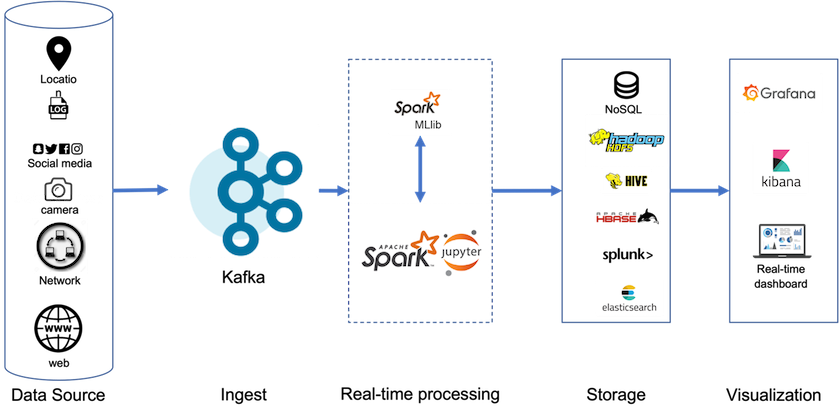
透過分層存儲,您可以使用高效能平台在串流資料尾部附近進行低延遲讀寫,還可以使用更便宜、可擴展的物件儲存(如NetApp StorageGRID )進行高吞吐量歷史讀取。我們也為具有 netapp 儲存控制器的 Spark 提供了技術解決方案,詳細資訊請見此處。下圖顯示了 Kafka 如何融入即時分析管道。
下圖描述了NetApp StorageGRID如何作為 Confluent Kafka 的物件儲存層。