本繁體中文版使用機器翻譯,譯文僅供參考,若與英文版本牴觸,應以英文版本為準。
用例 2:從雲端到本地的備份和災難恢復
貢獻者

 建議變更
建議變更
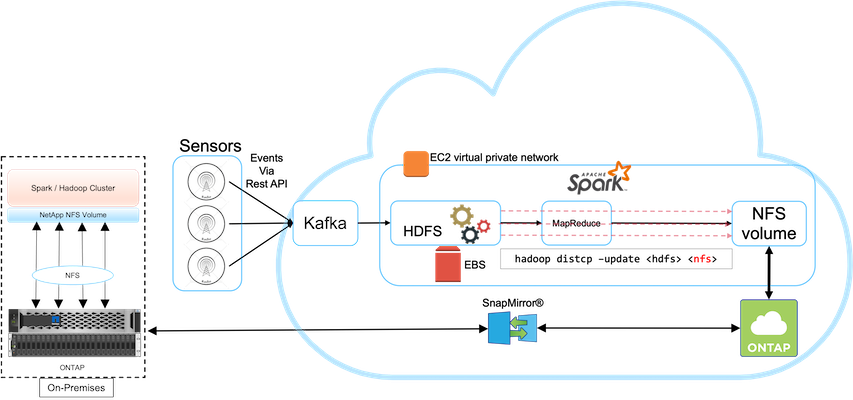
此用例基於一個廣播客戶,該客戶需要將基於雲端的分析資料備份到其內部資料中心,如下圖所示。
設想
在這種情況下,物聯網感測器資料被引入雲端中,並使用 AWS 內的開源 Apache Spark 叢集進行分析。要求是將處理後的資料從雲端備份到本地端。
要求和挑戰
此用例的主要要求和挑戰包括:
-
啟用資料保護不會對雲端中的生產 Spark/Hadoop 叢集造成任何效能影響。
-
需要以高效、安全的方式將雲端感測器資料移動並保護到本地。
-
在不同條件下靈活地將資料從雲端傳輸到本地,例如按需、即時以及低叢集負載時間期間。
解決方案
客戶使用 AWS Elastic Block Store (EBS) 作為其 Spark 叢集 HDFS 存儲,以透過 Kafka 接收和提取來自遠端感測器的資料。因此,HDFS 儲存可作為備份資料的來源。
為了滿足這些要求, NetApp ONTAP Cloud 部署在 AWS 中,並建立了一個 NFS 共用作為 Spark/Hadoop 叢集的備份目標。
建立 NFS 共用後,將資料從 HDFS EBS 儲存複製到ONTAP NFS 共用。當資料駐留在ONTAP Cloud 中的 NFS 時,可以根據需要使用SnapMirror技術以安全且有效率的方式將資料從雲端鏡像到本機儲存中。
此圖顯示了從雲端到本地解決方案的備份和災難復原。