本繁體中文版使用機器翻譯,譯文僅供參考,若與英文版本牴觸,應以英文版本為準。
用例 3:在現有 Hadoop 資料上啟用 DevTest
貢獻者

 建議變更
建議變更
在這種用例中,客戶的要求是基於現有的 Hadoop 集群快速有效地建立新的 Hadoop/Spark 集群,該集群包含大量用於同一資料中心和遠端位置的開發測試和報告目的的分析資料。
設想
在這種情況下,從本地以及災難復原位置的大型 Hadoop 資料湖實作建置多個 Spark/Hadoop 叢集。
要求和挑戰
此用例的主要要求和挑戰包括:
-
為 DevTest、QA 或任何其他需要存取相同生產資料的目的建立多個 Hadoop 叢集。這裡的挑戰是以非常節省空間的方式瞬間多次克隆一個非常大的 Hadoop 叢集。
-
將 Hadoop 資料同步到 DevTest 和報告團隊以提高營運效率。
-
在生產和新叢集中使用相同的憑證分發 Hadoop 資料。
-
使用調度策略有效率地建立QA集群,而不影響生產集群。
解決方案
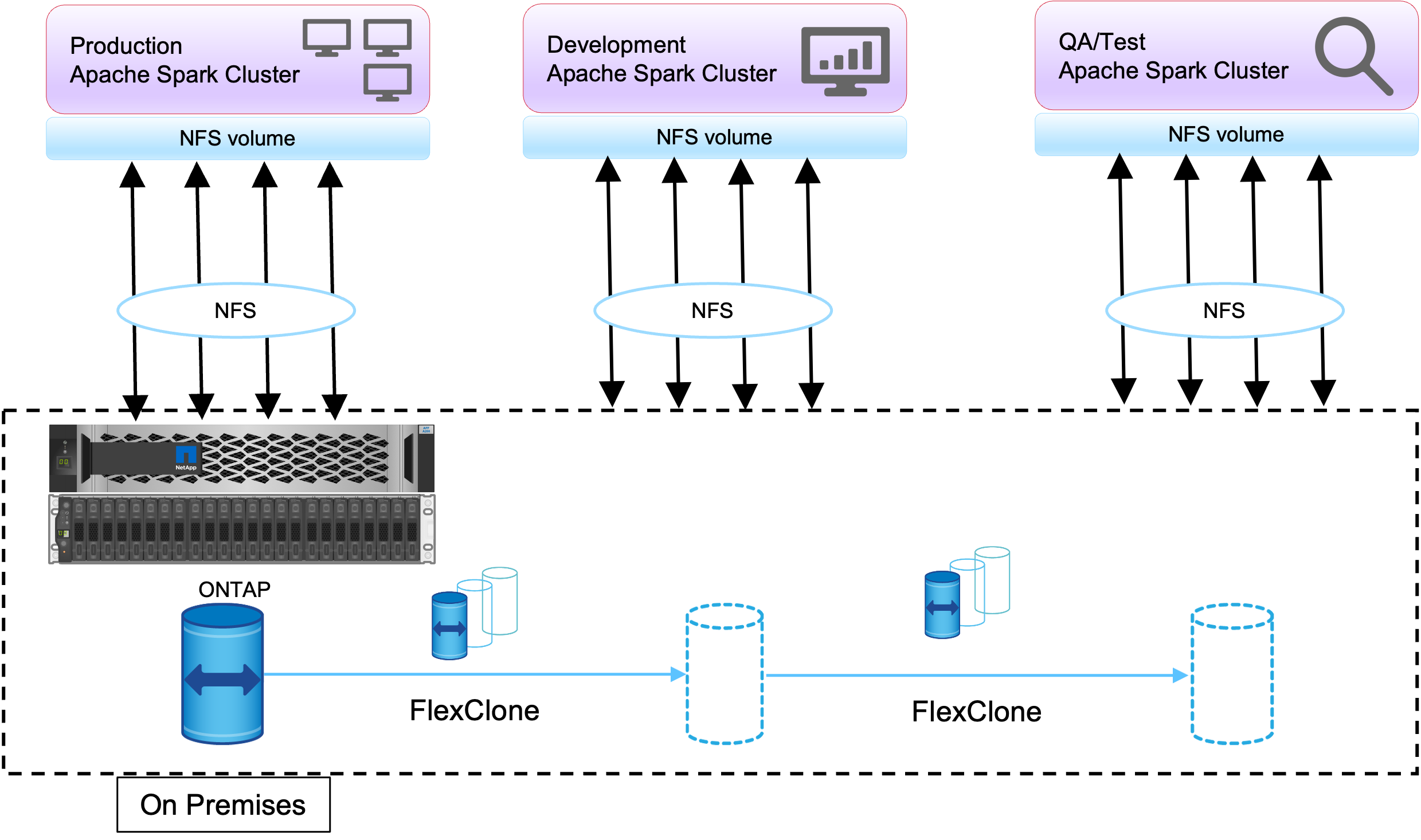
FlexClone技術用於滿足剛才所述的要求。 FlexClone技術是 Snapshot 副本的讀/寫副本。它從父 Snapshot 副本數據中讀取數據,並且僅為新/修改的區塊消耗額外的空間。它速度快並且節省空間。
首先,使用NetApp一致性群組建立現有叢集的 Snapshot 副本。
NetApp系統管理員或儲存管理提示中的快照副本。一致性群組Snapshot副本是應用程式一致性群組Snapshot副本, FlexClone磁碟區是基於一致性群組Snapshot副本建立的。值得一提的是, FlexClone磁碟區繼承了父磁碟區的 NFS 導出策略。建立 Snapshot 副本後,必須安裝一個新的 Hadoop 叢集以用於 DevTest 和報告目的,如下圖所示。來自新 Hadoop 叢集的克隆 NFS 磁碟區存取 NFS 資料。
此圖顯示了 DevTest 的 Hadoop 叢集。