功能驗證 - 愚蠢的重命名修復
 建議變更
建議變更
對於功能驗證,我們表明,使用 NFSv3 掛載儲存的 Kafka 叢集無法執行分區重新分配等 Kafka 操作,而使用修復程式掛載在 NFSv4 上的另一個叢集可以執行相同的操作而不會出現任何中斷。
驗證設定
該設定在 AWS 上運行。下表顯示了用於驗證的不同平台組件和環境配置。
| 平台組件 | 環境配置 |
|---|---|
Confluent 平台版本 7.2.1 |
|
所有節點上的作業系統 |
RHEL8.7或更高版本 |
NetApp Cloud Volumes ONTAP實例 |
單一節點實例 – M5.2xLarge |
下圖顯示了該解決方案的架構配置。
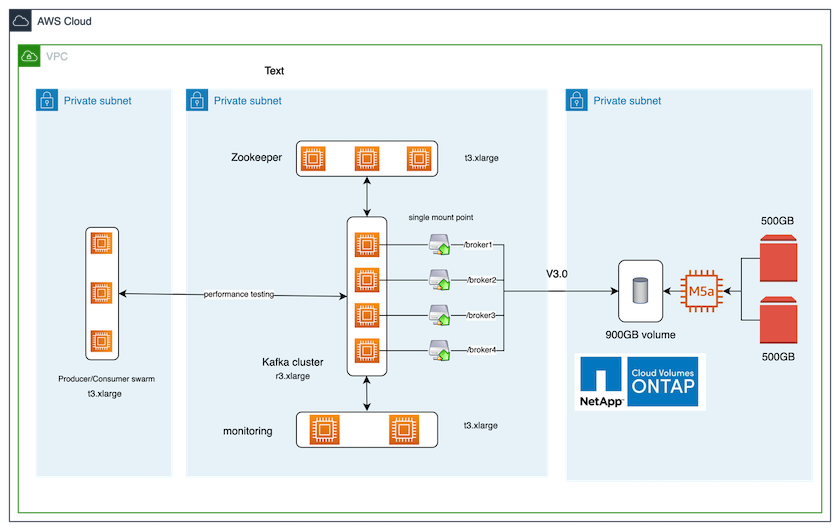
建築流程
-
*計算。 *我們使用了四節點 Kafka 集群,並在專用伺服器上運行三節點 zookeeper 集合。
-
*監控*我們使用兩個節點來實現 Prometheus-Grafana 組合。
-
*工作量*為了產生工作負載,我們使用了一個單獨的三節點集群,該集群可以從該 Kafka 集群中生產和消費。
-
*貯存。 *我們使用了單節點NetApp Cloud Volumes ONTAP實例,該實例連接了兩個 500GB GP2 AWS-EBS 磁碟區。然後,這些磁碟區透過 LIF 作為單一 NFSv4.1 磁碟區公開給 Kafka 叢集。
所有伺服器都選擇了 Kafka 的預設屬性。對動物園管理員群也做了同樣的事情。
測試方法
-
更新 `-is-preserve-unlink-enabled true`到kafka卷,如下:
aws-shantanclastrecall-aws::*> volume create -vserver kafka_svm -volume kafka_fg_vol01 -aggregate kafka_aggr -size 3500GB -state online -policy kafka_policy -security-style unix -unix-permissions 0777 -junction-path /kafka_fg_vol01 -type RW -is-preserve-unlink-enabled true [Job 32] Job succeeded: Successful
-
創建了兩個類似的 Kafka 集群,但有以下區別:
-
*集群 1.*執行生產就緒ONTAP版本 9.12.1 的後端 NFS v4.1 伺服器由NetApp CVO 執行個體所託管。代理程式上安裝了 RHEL 8.7/RHEL 9.1。
-
*集群 2.*後端 NFS 伺服器是手動建立的通用 Linux NFSv3 伺服器。
-
-
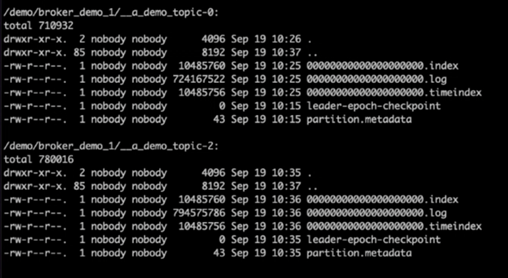
在兩個 Kafka 叢集上都建立了一個示範主題。
集群 1:

集群 2:

-
資料被載入到這兩個叢集新建立的主題。這是使用預設 Kafka 包中的生產者效能測試工具包完成的:
./kafka-producer-perf-test.sh --topic __a_demo_topic --throughput -1 --num-records 3000000 --record-size 1024 --producer-props acks=all bootstrap.servers=172.30.0.160:9092,172.30.0.172:9092,172.30.0.188:9092,172.30.0.123:9092
-
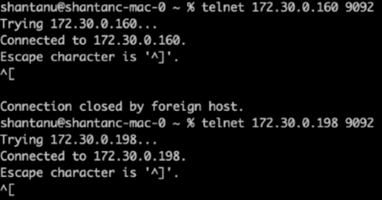
使用 telnet 對每個叢集的 broker-1 執行健康檢查:
-
遠端登入
172.30.0.160 9092 -
遠端登入
172.30.0.198 9092下圖顯示了兩個集群上的代理的成功健康檢查:
-
-
為了觸發導致使用 NFSv3 儲存磁碟區的 Kafka 叢集崩潰的故障條件,我們在兩個叢集上啟動了分區重新分配程序。分區重新分配是使用
kafka-reassign-partitions.sh。具體過程如下:-
為了重新指派 Kafka 叢集中某個主題的分區,我們產生了建議的重新指派組態 JSON(對兩個叢集都執行了此操作)。
kafka-reassign-partitions --bootstrap-server=172.30.0.160:9092,172.30.0.172:9092,172.30.0.188:9092,172.30.0.123:9092 --broker-list "1,2,3,4" --topics-to-move-json-file /tmp/topics.json --generate
-
產生的重新分配 JSON 隨後保存在
/tmp/reassignment- file.json。 -
實際的分區重新分配過程由以下命令觸發:
kafka-reassign-partitions --bootstrap-server=172.30.0.198:9092,172.30.0.163:9092,172.30.0.221:9092,172.30.0.204:9092 --reassignment-json-file /tmp/reassignment-file.json –execute
-
-
重新分配完成後幾分鐘,對代理進行的另一次健康檢查顯示,使用 NFSv3 存儲卷的集群遇到了一個愚蠢的重命名問題並崩潰了,而使用已修復的NetApp ONTAP NFSv4.1 存儲卷的集群 1 繼續運行而沒有任何中斷。
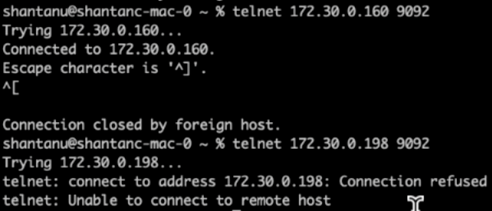
-
Cluster1-Broker-1 處於活動狀態。
-
Cluster2-broker-1 已死亡。
-
-
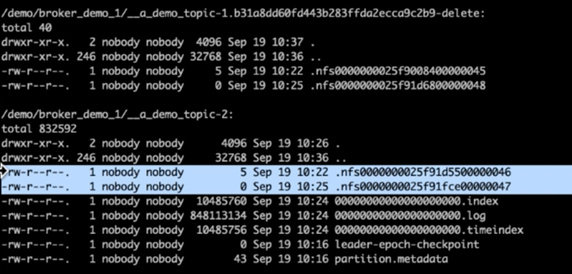
檢查 Kafka 日誌目錄後,很明顯,使用已修復的NetApp ONTAP NFSv4.1 儲存磁碟區的叢集 1 具有乾淨的分割區分配,而使用通用 NFSv3 儲存的叢集 2 由於愚蠢的重命名問題而沒有,從而導致崩潰。下圖顯示了叢集 2 的分區重新平衡,這導致了 NFSv3 儲存上出現了一個愚蠢的重命名問題。
下圖顯示了使用NetApp NFSv4.1 儲存對叢集 1 進行乾淨的分區重新平衡。