

範例工作流程 - 使用 Kubeflow 和NetApp DataOps 工具包訓練影像辨識模型
 建議變更
建議變更
本節介紹使用 Kubeflow 和NetApp DataOps Toolkit 訓練和部署用於影像辨識的神經網路的步驟。這旨在作為範例來展示結合NetApp儲存的訓練作業。
先決條件
建立一個包含所需配置的 Dockerfile,用於 Kubeflow 管道內的訓練和測試步驟。以下是 Dockerfile 的範例 -
FROM pytorch/pytorch:latest
RUN pip install torchvision numpy scikit-learn matplotlib tensorboard
WORKDIR /app
COPY . /app
COPY train_mnist.py /app/train_mnist.py
CMD ["python", "train_mnist.py"]根據您的要求,安裝運行程式所需的所有必需程式庫和套件。在訓練機器學習模型之前,假設您已經有一個可執行的 Kubeflow 部署。
使用 PyTorch 和 Kubeflow Pipelines 在 MNIST 資料上訓練小型 NN
我們使用在 MNIST 資料上訓練的小型神經網路作為範例。 MNIST 資料集由 0-9 的手寫數位影像組成。影像尺寸為 28x28 像素。此資料集分為 60,000 張訓練影像和 10,000 張驗證影像。本實驗所採用的神經網路是一個2層前饋網路。訓練是使用 Kubeflow Pipelines 執行的。請參閱文檔 "這裡"了解更多。我們的 Kubeflow 管道包含了先決條件部分的 docker 映像。
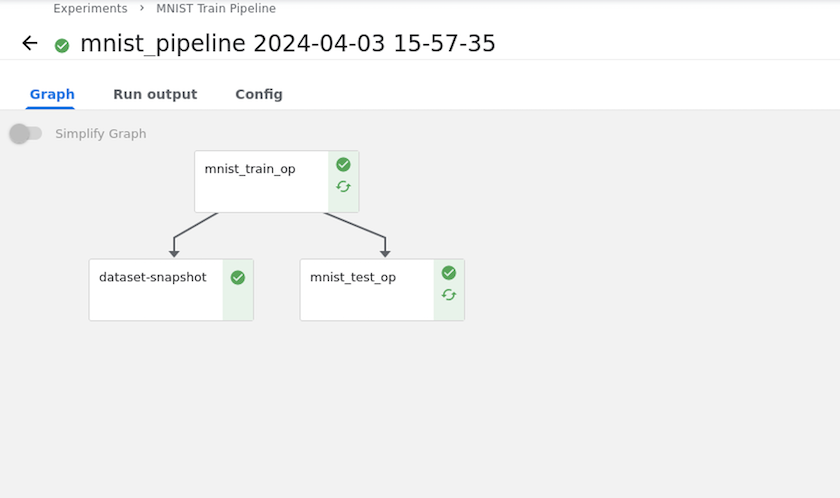
使用 Tensorboard 可視化結果
一旦模型訓練完成,我們就可以使用 Tensorboard 將結果視覺化。 "Tensorboard"作為 Kubeflow 儀表板上的功能提供。您可以為您的工作建立自訂張量板。以下的範例展示了訓練準確度與時期數以及訓練損失與時期數的關係圖。

使用 Katib 進行超參數實驗
"卡提布"是 Kubeflow 中的一個工具,可用來試驗模型超參數。要建立實驗,首先要定義所需的指標/目標。這通常是測試準確度。一旦定義了指標,選擇您想要使用的超參數(優化器/學習率/層數)。 Katib 使用使用者定義的值進行超參數掃描,以找到滿足所需指標的最佳參數組合。您可以在 UI 的每個部分中定義這些參數。或者,您可以定義一個具有必要規範的 YAML 檔案。以下是 Katib 實驗的說明 -
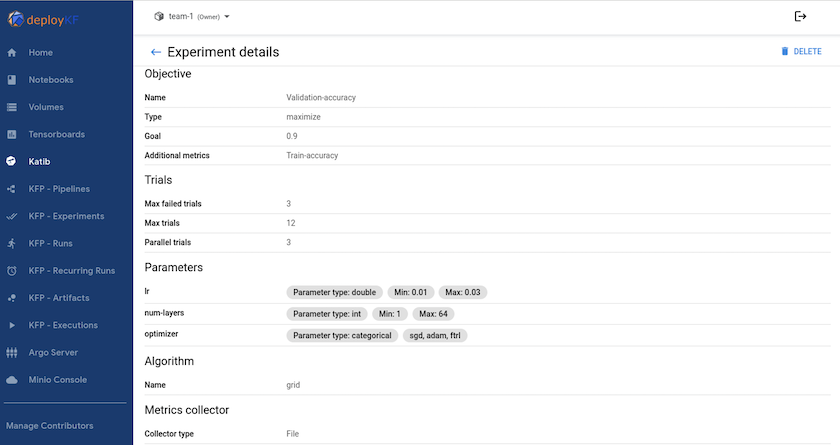
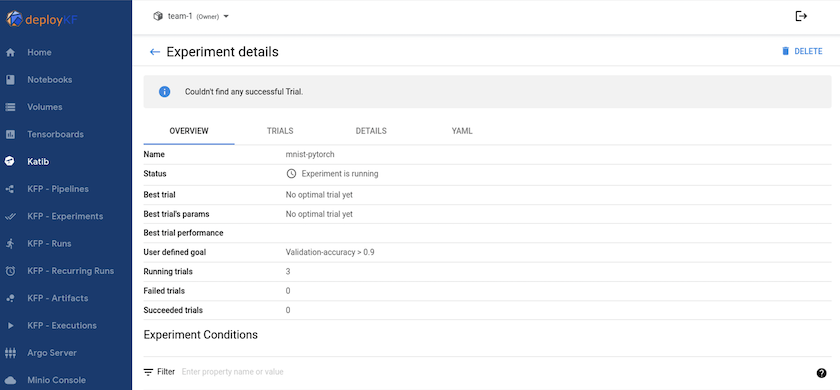
使用NetApp快照保存資料以實現可追溯性
在模型訓練期間,我們可能希望保存訓練資料集的快照以便於追溯。為此,我們可以向管道新增快照步驟,如下所示。要建立快照,我們可以使用 "適用於 Kubernetes 的NetApp DataOps 工具包"。
