

更換 DIMM - AFF A700
 建議變更
建議變更
當儲存系統遇到錯誤時、您必須更換控制器中的 DIMM 、例如根據健全狀況監視器警示或不可修正的 ECC 錯誤(可修正的錯誤修正碼)過多、通常是由於單一 DIMM 故障而導致、導致儲存系統無法開機 ONTAP 。
系統中的所有其他元件都必須正常運作;否則、您必須聯絡技術支援部門。
您必須使用從供應商處收到的替換FRU元件來更換故障元件。
步驟1:關閉受損的控制器
根據儲存系統硬體組態的不同、您可以使用不同的程序來關閉或接管受損的控制器。
接管並停止故障控制器,以便正常控制器繼續從故障控制器的儲存提供資料。為此,您需要在 AutoSupport 中停用自動建立案例功能、停用自動復原功能,並將故障控制器置於 LOADER 提示字元。LOADER 提示字元是安全的停止狀態,您可以從中更換 FRU。
-
如果您有 SAN 系統,則必須檢查故障控制器 SCSI 刀鋒的事件訊息
cluster kernel-service show。 `cluster kernel-service show`命令(從 priv 進階模式)會顯示節點名稱、"仲裁狀態"該節點的可用度狀態、以及該節點的作業狀態。每個SCSI刀鋒處理序都應與叢集中的其他節點處於仲裁狀態。任何問題都必須先解決、才能繼續進行更換。
-
如果叢集有兩個以上的節點、則叢集必須處於仲裁狀態。如果叢集未達到法定人數、或健全的控制器顯示為「假」、表示符合資格和健全狀況、則您必須在關閉受損的控制器之前修正問題;請參閱 "將節點與叢集同步"。
-
如果啟用了「支援」功能、請叫用下列消息來禁止自動建立個案AutoSupport AutoSupport :
system node autosupport invoke -node * -type all -message MAINT=<number of hours down>h這樣可以防止在您規劃的維護視窗期間自動建立支援案例。最長抑制時間為 72 小時。如果您的維護提前完成,您可以透過呼叫包含 `MAINT=END`的 AutoSupport 訊息來重新啟用案例建立功能。如需詳細資訊,請參閱 "如何在排程維護期間抑制自動建立案例"。
下列AutoSupport 資訊不顯示自動建立案例兩小時:
cluster1:> system node autosupport invoke -node * -type all -message MAINT=2h -
停用自動交還:
-
從健康控制器的控制台輸入以下命令:
storage failover modify -node impaired_node_name -auto-giveback false -
進入 `y`當您看到提示「您是否要停用自動回饋?」時
-
-
將受損的控制器移至載入器提示:
如果受損的控制器正在顯示… 然後… 載入程式提示
前往下一步。
正在等待恢復…
按Ctrl-C、然後在出現提示時回應「y」。
系統提示或密碼提示
從健全的控制器接管或停止受損的控制器:
storage failover takeover -ofnode impaired_node_name -halt true--halt true_ 參數會帶您進入 Loader 提示字元。
若要關閉受損的控制器、您必須判斷控制器的狀態、並在必要時切換控制器、使健全的控制器繼續從受損的控制器儲存設備提供資料。
-
您必須在本程序結束時保持電源供應器開啟、才能為健全的控制器提供電力。
-
檢查MetroCluster 「不正常」狀態、判斷受損的控制器是否已自動切換至「正常」控制器MetroCluster :「不正常」
-
視是否發生自動切換而定、請根據下表繼續進行:
如果控制器受損… 然後… 已自動切換
繼續下一步。
尚未自動切換
從健全的控制器執行計畫性的切換作業MetroCluster :「『交換切換’」
尚未自動切換、您嘗試使用MetroCluster 「還原切換」命令進行切換、切換遭到否決
請檢閱否決訊息、如有可能、請解決此問題、然後再試一次。如果您無法解決問題、請聯絡技術支援部門。
-
從MetroCluster 存續的叢集執行「f恢復 階段Aggregate」命令、以重新同步資料集合體。
controller_A_1::> metrocluster heal -phase aggregates [Job 130] Job succeeded: Heal Aggregates is successful.
如果治療被否決、您可以選擇MetroCluster 使用「-overre-etoes」參數重新發出「還原」命令。如果您使用此選用參數、系統將會置換任何軟質否決、以防止修復作業。
-
使用MetroCluster flexoperationshow命令確認作業已完成。
controller_A_1::> metrocluster operation show Operation: heal-aggregates State: successful Start Time: 7/25/2016 18:45:55 End Time: 7/25/2016 18:45:56 Errors: - -
使用「shorage Aggregate show」命令來檢查集合體的狀態。
controller_A_1::> storage aggregate show Aggregate Size Available Used% State #Vols Nodes RAID Status --------- -------- --------- ----- ------- ------ ---------------- ------------ ... aggr_b2 227.1GB 227.1GB 0% online 0 mcc1-a2 raid_dp, mirrored, normal...
-
使用「MetroCluster f恢復 階段根集合體」命令來修復根集合體。
mcc1A::> metrocluster heal -phase root-aggregates [Job 137] Job succeeded: Heal Root Aggregates is successful
如果修復被否決、您可以選擇使用MetroCluster -overrover-etoes參數重新發出「還原」命令。如果您使用此選用參數、系統將會置換任何軟質否決、以防止修復作業。
-
在MetroCluster 目的地叢集上使用「停止作業show」命令、確認修復作業已完成:
mcc1A::> metrocluster operation show Operation: heal-root-aggregates State: successful Start Time: 7/29/2016 20:54:41 End Time: 7/29/2016 20:54:42 Errors: - -
在受損的控制器模組上、拔下電源供應器。
步驟2:移除控制器模組
若要存取控制器內部的元件、您必須先從系統中移除控制器模組、然後移除控制器模組上的護蓋。
-
如果您尚未接地、請正確接地。
-
從受損的控制器模組拔下纜線、並追蹤纜線的連接位置。
-
將CAM把手上的橘色按鈕向下推、直到解鎖為止。
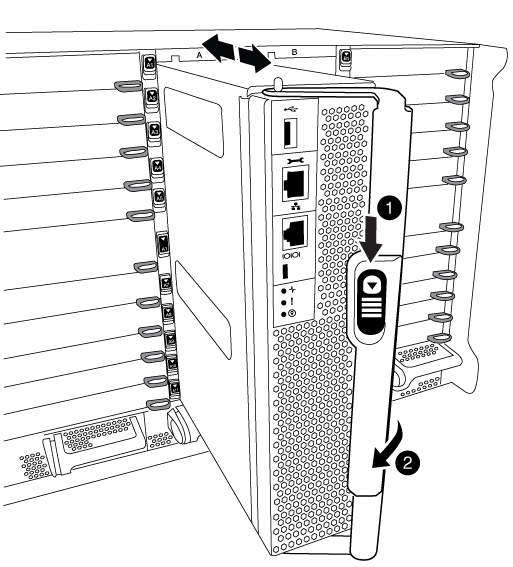

CAM握把釋放鈕

CAM握把
-
旋轉CAM握把、使其完全脫離機箱的控制器模組、然後將控制器模組滑出機箱。
將控制器模組滑出機箱時、請確定您支援控制器模組的底部。
-
將控制器模組蓋面朝上放置在穩固的平面上、按下機箱蓋上的藍色按鈕、將機箱蓋滑到控制器模組的背面、然後向上轉動機箱蓋、將其從控制器模組中取出。
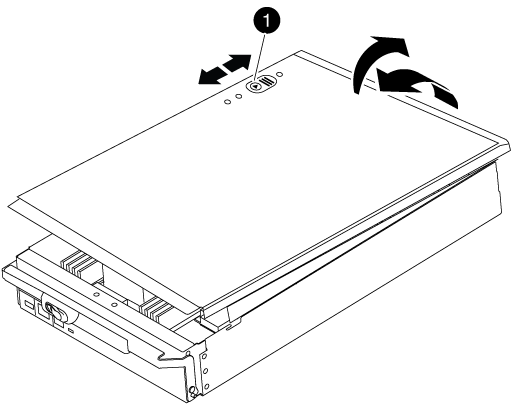
控制器模組護蓋鎖定按鈕
步驟3:更換DIMM
若要更換DIMM、請在控制器內找到DIMM、然後依照特定的步驟順序進行。
-
如果您尚未接地、請正確接地。
-
找到控制器模組上的DIMM。
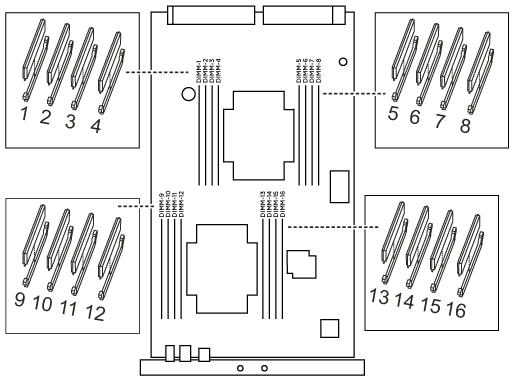
-
緩慢地將DIMM兩側的兩個DIMM彈出彈片分開、然後將DIMM從插槽中滑出、藉此將DIMM從插槽中退出。

小心拿住DIMM的邊緣、避免對DIMM電路板上的元件施加壓力。 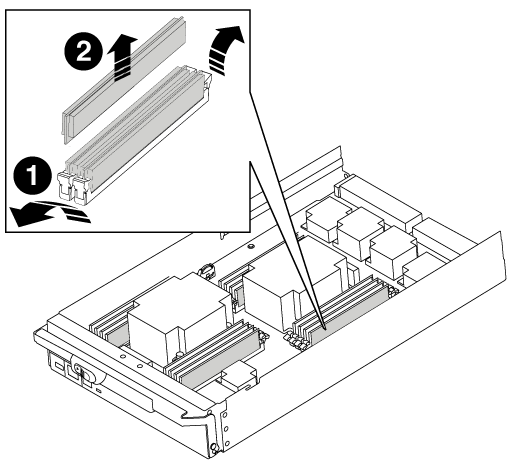
DIMM推出式彈片
DIMM
-
從防靜電包裝袋中取出備用DIMM、拿住DIMM的邊角、然後將其對準插槽。
DIMM插針之間的槽口應與插槽中的卡舌對齊。
-
確定連接器上的DIMM彈出彈片處於開啟位置、然後將DIMM正面插入插槽。
DIMM可緊密插入插槽、但應該很容易就能裝入。如果沒有、請重新將DIMM與插槽對齊、然後重新插入。
目視檢查DIMM、確認其對齊並完全插入插槽。 -
在DIMM頂端邊緣小心地推入、但穩固地推入、直到彈出彈出彈片卡入DIMM兩端的槽口。
-
合上控制器模組護蓋。
步驟4:安裝控制器
將元件安裝到控制器模組之後、您必須將控制器模組裝回系統機箱、然後啟動作業系統。
對於同一機箱中有兩個控制器模組的HA配對、安裝控制器模組的順序特別重要、因為當您將控制器模組完全裝入機箱時、它會嘗試重新開機。
-
如果您尚未接地、請正確接地。
-
如果您尚未更換控制器模組的護蓋、請將其裝回。
-
將控制器模組的一端與機箱的開口對齊、然後將控制器模組輕推至系統的一半。
在指示之前、請勿將控制器模組完全插入機箱。 -
僅連接管理連接埠和主控台連接埠、以便存取系統以執行下列各節中的工作。
您將在本程序稍後將其餘纜線連接至控制器模組。 -
完成控制器模組的重新安裝:
-
如果您尚未重新安裝纜線管理裝置、請重新安裝。
-
將控制器模組穩固地推入機箱、直到它與中間板完全接入。
控制器模組完全就位時、鎖定鎖條會上升。
將控制器模組滑入機箱時、請勿過度施力、以免損壞連接器。
控制器模組一旦完全插入機箱、就會開始開機。
-
向上轉動鎖定栓、將其傾斜、使其從鎖定銷中取出、然後將其放低至鎖定位置。
-
步驟5:在雙節點MetroCluster 的不二組態中切換回集合體
此工作僅適用於雙節點MetroCluster 的不完整組態。
-
驗證所有節點是否都處於「啟用」狀態:MetroCluster 「顯示節點」
cluster_B::> metrocluster node show DR Configuration DR Group Cluster Node State Mirroring Mode ----- ------- -------------- -------------- --------- -------------------- 1 cluster_A controller_A_1 configured enabled heal roots completed cluster_B controller_B_1 configured enabled waiting for switchback recovery 2 entries were displayed. -
確認所有SVM上的重新同步已完成:MetroCluster 「Svserver show」
-
驗證修復作業所執行的任何自動LIF移轉是否已成功完成:「MetroCluster 還原檢查LIF show」
-
從存續叢集中的任何節點使用「MetroCluster 還原」命令執行切換。
-
確認切換作業已完成:MetroCluster 「不顯示」
當叢集處於「等待切換」狀態時、切換回復作業仍在執行中:
cluster_B::> metrocluster show Cluster Configuration State Mode -------------------- ------------------- --------- Local: cluster_B configured switchover Remote: cluster_A configured waiting-for-switchback
當叢集處於「正常」狀態時、即可完成切換作業:
cluster_B::> metrocluster show Cluster Configuration State Mode -------------------- ------------------- --------- Local: cluster_B configured normal Remote: cluster_A configured normal
如果切換需要很長時間才能完成、您可以使用「MetroCluster show config-repl複 寫res同步 狀態show」命令來檢查進行中的基準狀態。
-
重新建立任何SnapMirror或SnapVault 不完整的組態。
步驟6:將故障零件歸還給NetApp
如套件隨附的RMA指示所述、將故障零件退回NetApp。如 "零件退貨與更換"需詳細資訊、請參閱頁面。