

效能
 建議變更
建議變更
NetApp AFX 的設計以效能和擴充性為核心,專門針對需要高讀寫處理量的工作負載,並可提供簡單、線性的擴充。
每個節點的效能
每個 NetApp AFX 儲存節點都提供特定的讀取和寫入吞吐量。隨著節點加入叢集中,效能會線性成長,如本文件「節點效能的線性擴展」部分所述。
目前,節點類型為 "AFX 1K",讀寫吞吐量大致如下所示。隨著 NetApp AFX 可用硬體的更新,這些限制可能會改變。注意:如下面的「基準測試結果」部分所示,使用多個客戶端讀取和寫入多個檔案時達到了最高效能。
每節點效能預估
| 節點類型 | 讀取效能上限 | 最大寫入效能 |
|---|---|---|
AFX 1K |
約 35GB/s |
約 10GB/s |

|
如需最新的效能預估,請洽詢您的 NetApp 銷售團隊。 |
每個磁碟櫃效能
每個儲存架包含高效能儲存架模組,配備 16 個 100GB 乙太網路連接埠,利用 RoCEv2 通訊實現與叢集中運算節點的高頻寬儲存互動。與任何實體資源一樣,這些儲存架的效能也有其極限——尤其因為 NetApp AFX 可以呈現多個指向同一組磁碟的節點。下表顯示了單一儲存架對 TLC 和 QLC 磁碟機的估計最大讀取和寫入效能。有關 TLC 和 QLC 差異的更多資訊,請參閱 "TLC 與 QLC"。
每個磁碟櫃的效能預估
| 機櫃模組類型 | 讀取效能上限 | 最大寫入效能 |
|---|---|---|
NSM 140 |
140GB/s(TLC 和 QLC) |
70GB/s TLC 35GB/s QLC |
|
|
如需最新的效能預估,請洽詢您的 NetApp 銷售團隊。 |
效能密度
在分散式 ONTAP 架構中,將儲存節點與磁碟櫃分離,可讓更多節點將流量推送到較少的磁碟櫃,這有助於減少資料中心的整體佔用空間,只需使用所需的容量即可獲得最大效能。
「效能密度」的概念使儲存管理員能夠最大限度地利用現有硬體,而無需過度配置儲存環境。
例如,在統一的 ONTAP 叢集中,由於每個節點都有自己的一組磁碟,因此效能僅限於該節點擁有的磁碟;由於只有一個節點可以存取一組磁碟,因此它不一定能充分利用可用磁碟並達到其最大效能。
統一 ONTAP – 效能劃分方式
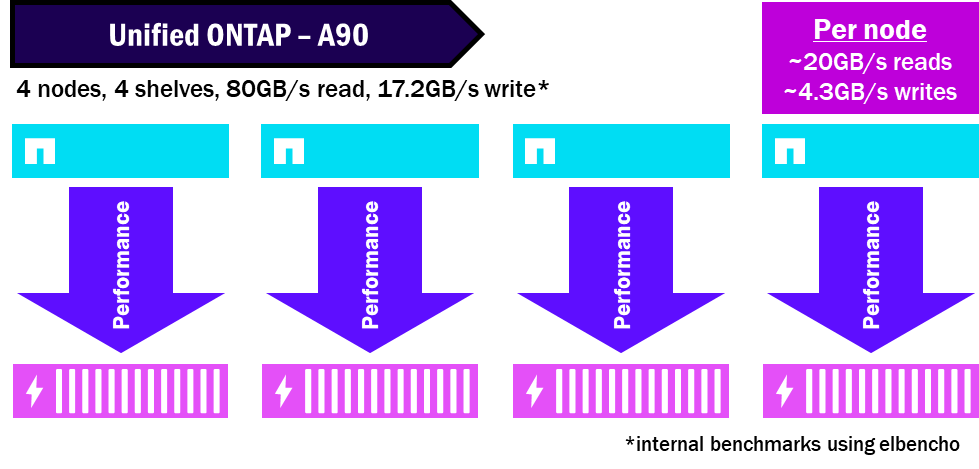
NetApp AFX 將所有磁碟匯集到單一儲存可用區域中,因此所有節點都可以運用所有磁碟。而且由於磁碟和節點是分離的,因此您不需要那麼多機櫃就能獲得相同的效能。這樣可以壓縮效能並最大化機櫃的最大效能潛力。
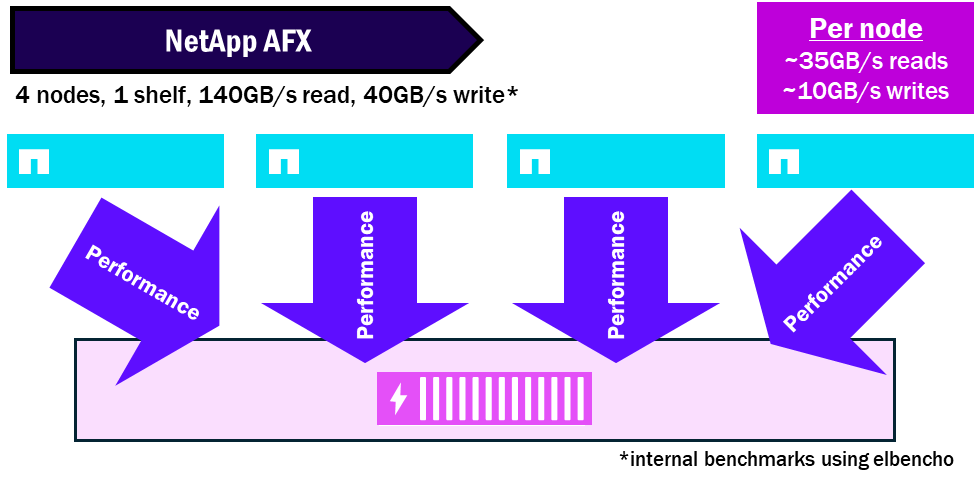
NetApp AFX – 效能密度
節點與機櫃比率
Unified ONTAP 節點每個節點至少需要一組磁碟,且單一節點可以連接多個磁碟櫃。因此,單一節點可能會出現效能瓶頸,可能無法充分利用其自身的磁碟。
NetApp AFX 將所有磁碟櫃提供給所有節點。每個磁碟櫃包含具有 16 x 100GB RoCE 功能介面的模組,以增加每個磁碟櫃允許的總效能量。因此,您可以使用多個節點飽和單一磁碟櫃,這些節點將對同一組磁碟進行讀取和寫入。
截至 ONTAP 9.19.1,節點:機櫃飽和度比率約為 4:1。
基準測試結果
以下部分介紹使用具有下列組態參數的 NetApp AFX 叢集進行基準測試的結果。
-
4 個節點、4 個資料介面
-
2 個磁碟櫃(7.6TB 磁碟機)
-
ONTAP 9.19.1
-
NFSv4.2(pNFS、工作階段主幹連線)
-
FlexGroup Volume
-
"ElBencho" 基準測試
-
寫入:elbencho --hosts=x.x.x.[y-z] -d -w -b 1M -t 80 --iodepth 1 --direct -s 600g /fio_vol1/
-
讀取:elbencho --hosts=x.x.x.[y-z] -r -b 256k -t 80 --lat --iodepth 2 --direct -s 600g --infloop /fio_vol1/
-
4 台 Cisco C240 M8 伺服器、2 個連接埠 * 200GbE CX-7 卡、80 個執行緒
-
NFS 掛載選項:rw,vers=4.2,rsize=1048576,wsize=1048576,trunkdiscovery,proto=tcp
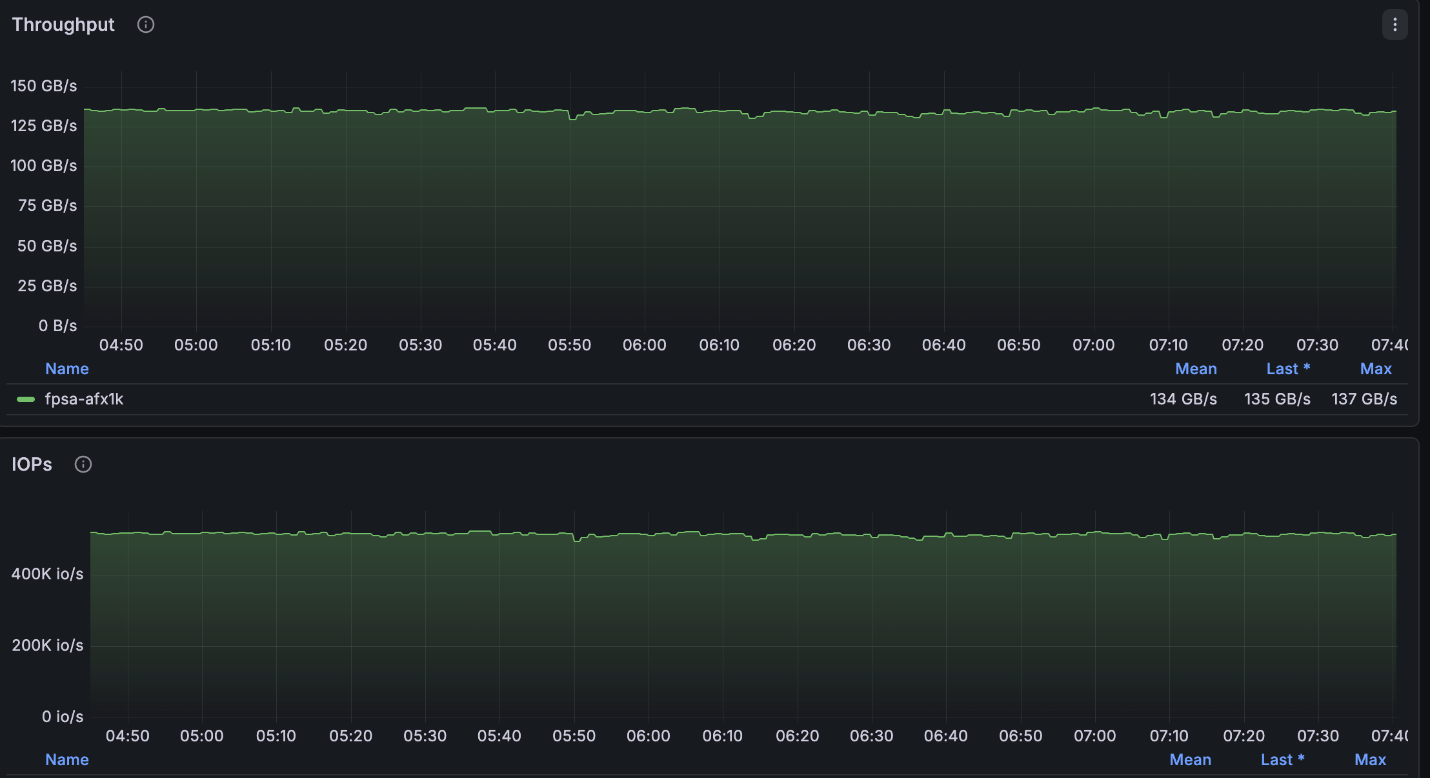
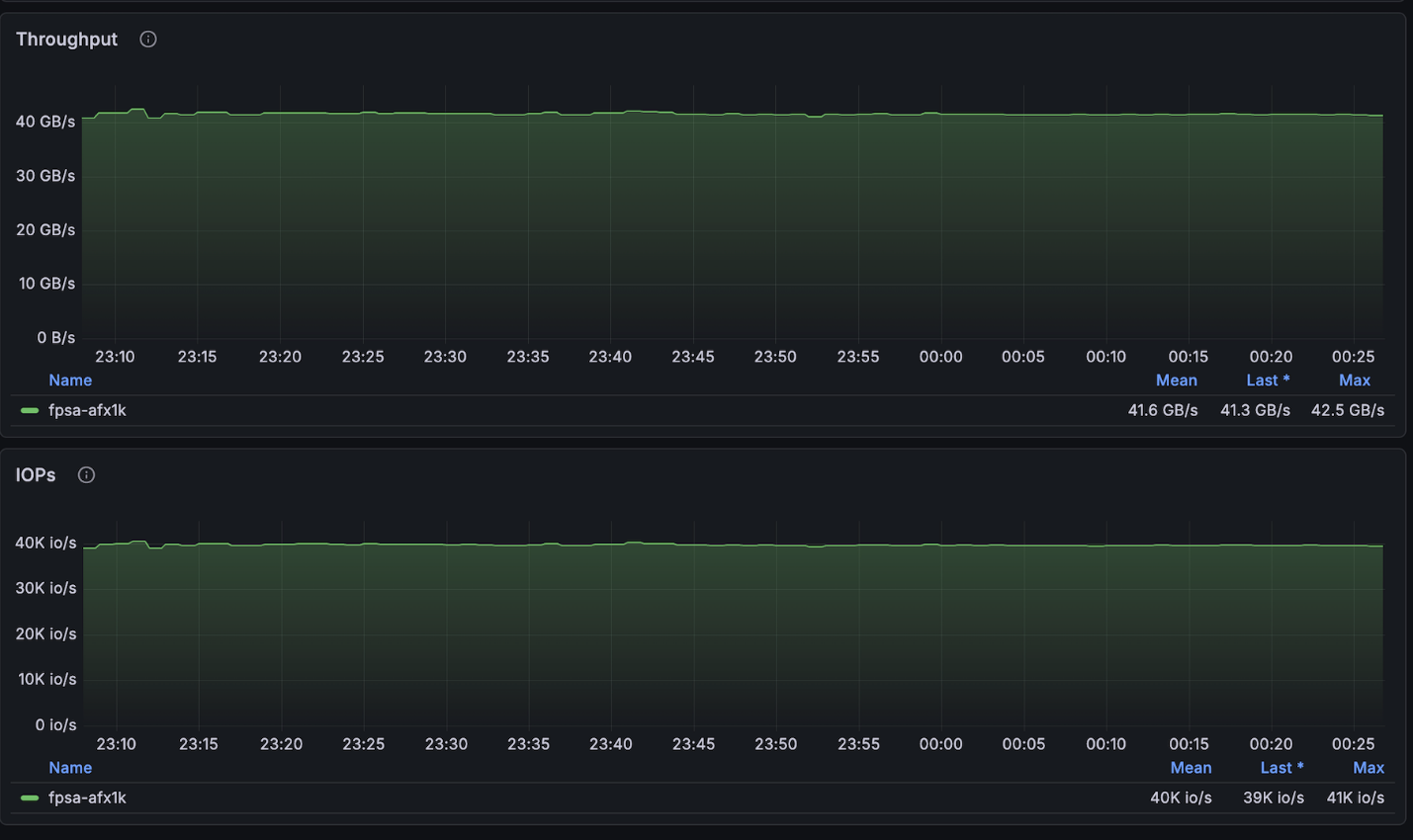
上述組態達到了 4 節點叢集可用的最大讀取速度(~134GB/s),並且正好達到每個節點允許的最大寫入速度(40GB/s)。
NetApp AFX – ElBencho 讀取效能,4 個節點
NetApp AFX – ElBencho 寫入效能,4 個節點
積極的預先讀取
在媒體串流工作負載中,一部 4K 電影通常會分割成數萬個檔案,每個檔案的大小通常在 50 MB 到 250 MB 之間。每個檔案代表一個影格,應用程式會在單一要求中讀取整個影格。為了維持流暢、不間斷且無可見緩衝的串流,這些影格讀取必須完成且不能中斷。
ONTAP 提供磁碟區層級選項(`-aggressive-readahead-mode`來最佳化這些工作負載。從 ONTAP 9.19.1 開始,AFX 上引入了新的 `cross_file_sequential_read`模式,可加速具有可預測 I/O 模式的類似檔案類型工作負載(例如媒體轉譯和串流)。
cross_file_sequential_read 會根據檔案名稱預測下一個要讀取的檔案,並在用戶端發出讀取呼叫之前開始對這些檔案進行預先讀取。預測邏輯假設目錄中的所有檔案都遵循命名模式,其數字後綴單調遞增(例如 file1、file2、file3)。目錄中的所有檔案都必須遵循此模式,使用十進位或十六進位編號。檔案名稱長度最多為 255 個字元。此邏輯與副檔名無關,僅根據目前檔案名稱在目前目錄中產生下一組檔案名稱。如果先前使用十進位編號產生的檔案名稱在目錄中不存在,則會使用十六進位編號重新產生名稱。如果產生的檔案名稱都不存在,則不會對該組發出預先擷取。預先擷取會在發出下一個用戶端讀取時恢復。
啟用這些選項後,"frametest" 效能基準測試能夠以每秒 30 幀的速度讀取 30,000 個 4K 幀,同時支援 30 個用戶端(NFSv3 和 SMB3)和 34 個用戶端(NFSv4.1),沒有丟幀。
雖然跨檔案循序讀取主要針對媒體工作負載而設計,但其他具有可預測存取模式和檔案名稱的讀取密集型工作負載(例如 AI 訓練和推理)也可以從中受益。
考量事項與注意事項
-
共享緩衝區快取 – 主動預讀使用與節點上其他磁碟區相同的緩衝區快取。啟用此功能可能會影響該節點上其他磁碟區的讀取效能。
-
底層儲存效能 – 如果檔案讀取速度不夠快(例如,在基於 HDD 的 FAS 系統上),則快取資料可能會在用戶端讀取之前被清除,從而抵消預讀的優勢。
-
存取模式要求 – 如果工作負載的讀取模式不是循序的,或者目錄中的檔案名稱不是按遞增循序順序命名的,則 cross_file_sequential_read 積極預先讀取模式不會帶來有意義的效益。
NFSv4.x 效能增強功能
幾十年來,NFS 版本 3 一直是 NFS 應用程式的黃金標準——早在 1995 年首次正式發佈時就已如此。它兼具效能和恢復能力,因此有充分的理由讓人們難以考慮升級到更新的 NFS 版本。
然而、NFSv3 並非沒有限制。協定的無狀態特性雖然有利於效能、並可將儲存容錯移轉的中斷降至最低、但對於資料一致性和鎖定管理而言並不理想。NFS 伺服器並不會真正追蹤鎖定狀態、因此如果發生故障、NFS 伺服器可能會或可能不會釋放鎖定、而 NFS 用戶端可能不知道檔案是否已鎖定。
Security for NFSv3 is also a bit lacking. The protocol requires multiple open firewall ports to function properly and numeric IDs are sent in plaintext over the wire. Furthermore, NFS does not have robust ACL support, and does not include native file and folder auditing. As a result of these limitations, NFSv4 was created in 2003 via link:https://datatracker.ietf.org/doc/html/rfc3530[RFC-3530^] (obsoleted in 2015 by link:https://datatracker.ietf.org/doc/html/rfc7530[RFC-7530^]). 雖然 NFSv4.x 已經存在了 20 多年,但由於一些原因,它仍然沒有被廣泛採用。
-
身分識別管理的複雜性:許多環境沒有名稱服務基礎架構來正確利用 NFSv4.x 中的名稱字串和 Kerberos 安全性需求。
-
新版 NFS 用戶端的需求:隨著 NFSv4 發佈時間的推移,如今的 NFS 環境對新版 NFS 用戶端的需求已不再那麼迫切。幾乎所有目前使用的作業系統都包含完全支援 NFSv4 的 NFS 用戶端,但仍有一些舊系統可能缺少必要的 NFSv4.x 套件。事實上,某些應用程式仍然需要使用較舊的 NFS 版本。
-
「如果沒壞,就別修」的心態:企業 IT 組織在採用新技術方面出了名的保守——即使是那些已經存在 20 多年的技術。如果目前的 NFS 版本運作良好,為什麼要改變呢?
-
效能問題:在過去 20 年的大部分時間裡,有狀態協定(例如 NFSv4.x)的效能一直落後於無狀態協定 NFSv3。過去,效能上的影響往往超過了 NFSv4.x 帶來的優勢。
使用 AFX 在 ONTAP 9.18.1 中對 NFSv4.x 進行改進
ONTAP 的一些架構變更為 NFS 提供了急需的效能提升,並顯著提高了 NFSv4.x 的整體效能。
以下是其中一些變更的高階摘要。
順序讀取效能提升:NFSv4.1 比 NFSv3 提升 30%
ONTAP 9.18.1 引進了對 NFSv4.1 多路徑 I/O 的支援。MPIO 不再處理來自 WAFL 檔案系統的讀取操作,而是將讀取操作轉移到網路域,以多路徑安全的方式提供服務。這種方法減少了上下文切換,提高了順序讀取流量的整體並行性,並透過繞過 WAFL 降低了緩衝區管理的開銷。
FlexGroup Volume 隨機讀取增強:NFSv4.1 與 NFSv3 的差異在 7% 以內
FlexGroup Volume 是將多個底層組成 Volume 整合為一個統一命名空間的 Volume 。在 AFX 中、FlexGroup Volume 預設啟用進階容量平衡、這表示大於 10GB 的檔案會以多部分檔案的形式寫入多個組成 Volume 。由於這些檔案部分位於遠端位置、 NFSv4.x 的隨機讀取效能通常略有下降(比 NFSv3 低約 18% )。ONTAP 9.18.1 引入了對 NFSv4.x 多部分讀取的快取 IO 支援、以解決此問題。附註:此變更不適用於 FlexVol Volume 。
循序寫入:比先前版本提升 10%
改進了 HA 故障轉移功能的 NVLOG 資料複製方式,提高了 NetApp AFX 系統的整體順序寫入效能。
中繼資料作業:在 EDA 基準測試中,效能在 NFSv3 的 15% 範圍內
NFSv4.1 傳統上會將所有 OPEN 和 CLOSE 操作串行化,叢集節點會逐一處理這些操作,然後才能將其從網路傳送到 WAFL。ONTAP 9.18.1 引入了並發開啟 / 關閉(COC)機制,它透過改變競爭條件的解決方式來消除網路串列化,從而解決了先前版本中出現的 OPEN/CLOSE 瓶頸問題。
所有這些變更,以及 AFX 帶來的架構變更,都使得 ONTAP 9.18.1 中 NFSv4.1 的整體效能得以提升。
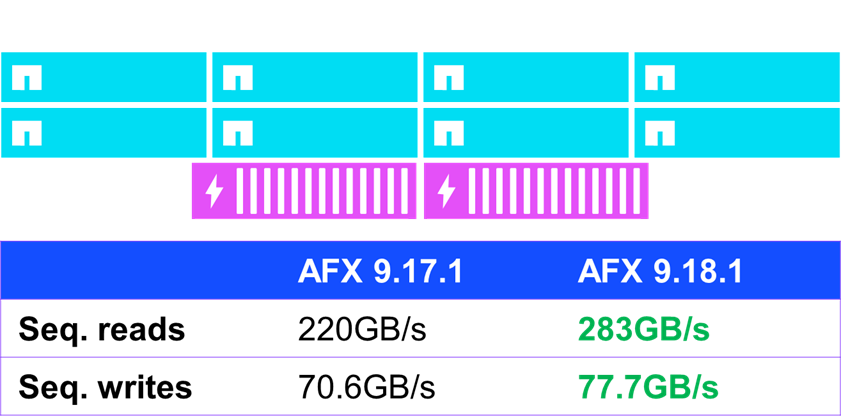
連續 IO 結果
效能提升較為顯著的領域之一是順序 IO(即可預測且依序執行的 IO 操作)。在使用 fio 進行的標準效能測試中,執行 ONTAP 9.18.1 的 AFX 的順序讀取效能提升了近 30%,順序寫入效能提升了 10%。
NetApp AFX – NFSv4.1 順序 IO 效能(ONTAP 9.18.1)
中繼資料密集型工作負載結果
更令人印象深刻的是,NFSv4.x 在效能瓶頸之一——元資料方面也取得了顯著改進。這些是隨機 IO,通常在 4K 範圍內,用於管理檔案擁有者和屬性、建立和列出檔案等等。由於 NFSv4.x 的狀態性,這類操作往往會消耗更多 CPU 資源並增加延遲,從而降低整體效能。
隨著 AFX ONTAP 9.18.1 的變更,NFSv4.x 在這些類型工作負載下的效能已大幅改善,並已縮小與 NFSv3 效能的差距(在 15% 以內)。
我們的效能工程團隊對標準 AI 影像、EDA 和軟體建置基準的效能進行了比較,發現與先前的 ONTAP 版本相比有了巨大的提升。
NetApp AFX – ONTAP 9.18.1 中的 NFSv4.1 元資料 IO 效能
