

使用 CLI 手動進行四節點或八節點 MetroCluster 組態的 ONTAP 不中斷升級
 建議變更
建議變更
手動升級四個或八個節點的 MetroCluster 組態、包括準備更新、同時更新一或兩個 DR 群組中的每個 DR 配對、以及執行升級後的工作。
-
此工作適用於下列組態:
-
執行不含更新版本的4節點MetroCluster 的不含功能的FC或IP組態ONTAP
-
八節點MetroCluster 的不ONTAP 受限於任何版本的不受影響的不受限的FFC組態
-
-
如果您有雙節點MetroCluster 的不全功能組態、請勿使用此程序。
-
下列工作是指ONTAP 舊版和新版的《不一樣》。
-
升級時、舊版ONTAP 是舊版的版次、版本編號比新版ONTAP 的版次低。
-
降級時、舊版本ONTAP 是更新版本的版次、版本編號比ONTAP 新版的版次更高。
-
-
此工作使用下列高層級工作流程:
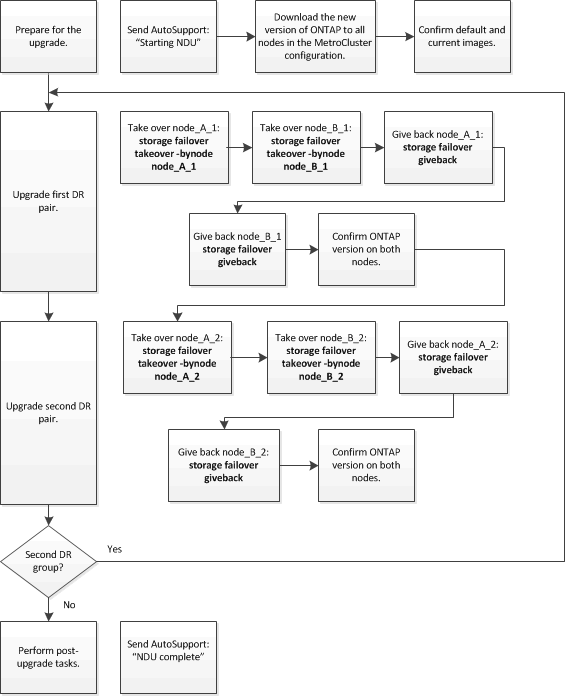
在八節點或四節點 MetroCluster 組態上更新 ONTAP 軟體時的差異
MetroCluster 軟體升級程序會因 MetroCluster 組態中有八個或四個節點而異。
一個由一或兩個DR群組所組成的支援組態。MetroCluster每個DR群組包含兩個HA配對、每MetroCluster 個VMware叢集各一個HA配對。八節點MetroCluster 的功能不全包含兩個DR群組:
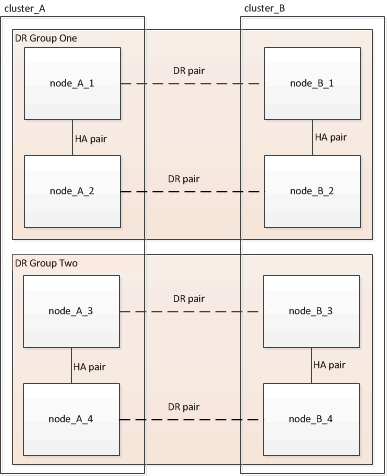
您一次升級一個 DR 群組。
-
升級 DR Group One :
-
升級 node_a_1 和 node_B_1 。
-
升級 node_a_2 和 node_B_2 。
-
-
升級 DR Group One :
-
升級 node_a_1 和 node_B_1 。
-
升級 node_a_2 和 node_B_2 。
-
-
升級 DR 群組二:
-
升級 node_a_3 和 node_B_3 。
-
升級 node_a_4 和 node_B_4 。
-
準備升級 MetroCluster DR 群組
在節點上升級 ONTAP 軟體之前、您必須先識別節點之間的 DR 關係、傳送一則 AutoSupport 訊息、告知您正在初始化升級、並確認每個節點上執行的 ONTAP 版本。
此工作必須在每個DR群組上重複執行。如果這個支援功能組態由八個節點組成、則有兩個DR群組。MetroCluster因此、此工作必須在每個DR群組上重複執行。
本工作所提供的範例使用下圖所示的名稱來識別叢集和節點:
-
識別組態中的 DR 配對:
metrocluster node show -fields dr-partnercluster_A::> metrocluster node show -fields dr-partner (metrocluster node show) dr-group-id cluster node dr-partner ----------- ------- -------- ---------- 1 cluster_A node_A_1 node_B_1 1 cluster_A node_A_2 node_B_2 1 cluster_B node_B_1 node_A_1 1 cluster_B node_B_2 node_A_2 4 entries were displayed. cluster_A::>
-
將權限等級從 admin 設定為進階、在提示繼續時輸入 * y* :
set -privilege advanced進階提示 (
*>)。 -
確認叢集 A 上的 ONTAP 版本:
system image showcluster_A::*> system image show Is Is Install Node Image Default Current Version Date -------- ------- ------- ------- ------- ------------------- node_A_1 image1 true true X.X.X MM/DD/YYYY TIME image2 false false Y.Y.Y MM/DD/YYYY TIME node_A_2 image1 true true X.X.X MM/DD/YYYY TIME image2 false false Y.Y.Y MM/DD/YYYY TIME 4 entries were displayed. cluster_A::> -
確認叢集 B 上的版本:
system image showcluster_B::*> system image show Is Is Install Node Image Default Current Version Date -------- ------- ------- ------- ------- ------------------- node_B_1 image1 true true X.X.X MM/DD/YYYY TIME image2 false false Y.Y.Y MM/DD/YYYY TIME node_B_2 image1 true true X.X.X MM/DD/YYYY TIME image2 false false Y.Y.Y MM/DD/YYYY TIME 4 entries were displayed. cluster_B::> -
觸發AutoSupport 功能不支援通知:
autosupport invoke -node * -type all -message "Starting_NDU"此 AutoSupport 通知包含升級前的系統狀態記錄。如果升級程序發生問題、它會儲存實用的疑難排解資訊。
如果您的叢集未設定為傳送AutoSupport 功能性訊息、則通知複本會儲存在本機。
-
針對第一組中的每個節點、將目標 ONTAP 軟體映像設為預設映像:
system image modify {-node nodename -iscurrent false} -isdefault true此命令會使用延伸查詢、將安裝為替代映像的目標軟體映像變更為節點的預設映像。
-
確認目標 ONTAP 軟體映像已設為叢集 A 上的預設映像:
system image show在下列範例中、image2是新ONTAP 的版本、並在第一組的每個節點上設為預設影像:
cluster_A::*> system image show Is Is Install Node Image Default Current Version Date -------- ------- ------- ------- ------- ------------------- node_A_1 image1 false true X.X.X MM/DD/YYYY TIME image2 true false Y.Y.Y MM/DD/YYYY TIME node_A_2 image1 false true X.X.X MM/DD/YYYY TIME image2 true false Y.Y.Y MM/DD/YYYY TIME 2 entries were displayed.-
確認目標 ONTAP 軟體映像已設為叢集 B 上的預設映像:
system image show下列範例顯示、目標版本已設定為第一組中每個節點的預設映像:
cluster_B::*> system image show Is Is Install Node Image Default Current Version Date -------- ------- ------- ------- ------- ------------------- node_A_1 image1 false true X.X.X MM/DD/YYYY TIME image2 true false Y.Y.Y MM/YY/YYYY TIME node_A_2 image1 false true X.X.X MM/DD/YYYY TIME image2 true false Y.Y.Y MM/DD/YYYY TIME 2 entries were displayed. -
-
確定要升級的節點目前是否為每個節點提供兩次任何用戶端服務:
system node run -node target-node -command uptime正常運作時間命令會顯示節點自上次開機以來、針對NFS、CIFS、FC和iSCSI用戶端執行的作業總數。對於每個傳輸協定、您需要執行兩次命令、以判斷作業數是否增加。如果數量不斷增加、則節點目前正在為該傳輸協定的用戶端提供服務。如果不增加、則節點目前不會為該傳輸協定的用戶端提供服務。

您應該記下每個增加用戶端作業的傳輸協定、以便在節點升級之後、您可以確認用戶端流量已恢復。 此範例顯示具有NFS、CIFS、FC和iSCSI作業的節點。不過、節點目前僅提供NFS和iSCSI用戶端服務。
cluster_x::> system node run -node node0 -command uptime 2:58pm up 7 days, 19:16 800000260 NFS ops, 1017333 CIFS ops, 0 HTTP ops, 40395 FCP ops, 32810 iSCSI ops cluster_x::> system node run -node node0 -command uptime 2:58pm up 7 days, 19:17 800001573 NFS ops, 1017333 CIFS ops, 0 HTTP ops, 40395 FCP ops, 32815 iSCSI ops
更新MetroCluster 不只一個DR群組的第一個DR配對
您必須以正確順序執行節點的接管和恢復、才能使ONTAP 節點的新版本成為節點的目前版本。
所有節點都必須執行舊版ONTAP 的功能。
在此工作中、 node_a_1 和 node_B_1 會升級。
如果您已在第一個 DR 群組上升級 ONTAP 軟體、並正在八節點 MetroCluster 組態中升級第二個 DR 群組、則在此工作中、您將會更新 node_a_3 和 node_B_3 。
-
將所有資料生命從節點移轉至其他位置:
network interface migrate-all -node node_A_1network interface migrate-all -node node_B_1 -
如果啟用了 MetroCluster Tiebreaker 軟體,請將其停用。
-
針對 HA 配對中的每個節點、停用自動恢復:
storage failover modify -node target-node -auto-giveback false此命令必須針對HA配對中的每個節點重複執行。
-
確認已停用自動恢復:
storage failover show -fields auto-giveback此範例顯示兩個節點上的自動恢復功能均已停用:
cluster_x::> storage failover show -fields auto-giveback node auto-giveback -------- ------------- node_x_1 false node_x_2 false 2 entries were displayed.
-
確保每個控制器的 I/O 不超過約 50% 、而且每個控制器的 CPU 使用率不超過約 50% 。
-
啟動叢集A上目標節點的接管:
請勿指定-option Immediate參數、因為要重新啟動至新軟體映像的節點需要正常接管。
-
接管叢集 A ( node_a_1 )上的 DR 合作夥伴:
storage failover takeover -ofnode node_A_1節點會開機至「等待恢復」狀態。
如果啟用了「支援」、則會傳送一則消息「不支援」、指出節點已超出叢集仲裁。AutoSupport AutoSupport您可以忽略此通知並繼續升級。 -
確認接管成功:
storage failover show以下範例顯示接管作業成功。node_a_1處於「等待恢復」狀態、node_a_2則處於「接管」狀態。
cluster_A::> storage failover show Takeover Node Partner Possible State Description -------------- -------------- -------- ------------------------------------- node_A_1 node_A_2 - Waiting for giveback (HA mailboxes) node_A_2 node_A_1 false In takeover 2 entries were displayed. -
-
接管叢集B(node_B_1)上的DR合作夥伴:
請勿指定-option Immediate參數、因為要重新啟動至新軟體映像的節點需要正常接管。
-
接管 node_B_1 :
storage failover takeover -ofnode node_B_1節點會開機至「等待恢復」狀態。
如果啟用了「支援」、則會傳送一則消息「不支援」、指出節點已超出叢集仲裁。AutoSupport AutoSupport您可以忽略此通知並繼續升級。 -
確認接管成功:
storage failover show以下範例顯示接管作業成功。node_B_1處於「等待恢復」狀態、node_B_2則處於「接管」狀態。
cluster_B::> storage failover show Takeover Node Partner Possible State Description -------------- -------------- -------- ------------------------------------- node_B_1 node_B_2 - Waiting for giveback (HA mailboxes) node_B_2 node_B_1 false In takeover 2 entries were displayed. -
-
至少等待八分鐘、以確保發生下列情況:
-
用戶端多重路徑(若已部署)會穩定下來。
-
用戶端會從接管期間發生的I/O暫停中恢復。
還原時間是用戶端專屬的、視用戶端應用程式的特性而定、可能需要8分鐘以上的時間。
-
-
將集合體傳回目標節點:
將MetroCluster 靜態IP組態升級ONTAP 為EFlash 9.5或更新版本之後、集合體將會在重新同步並返回鏡射狀態之前、處於降級狀態一小段時間。
-
將集合物傳回叢集 A 上的 DR 合作夥伴:
storage failover giveback -ofnode node_A_1 -
將集合物傳回叢集 B 上的 DR 合作夥伴:
storage failover giveback -ofnode node_B_1恢復作業會先將根Aggregate傳回節點、然後在節點完成開機之後、傳回非根Aggregate。
-
-
在兩個叢集上發出下列命令、確認已傳回所有的集合體:
storage failover show-giveback如果「歸還狀態」欄位指出沒有要歸還的集合體、則會傳回所有集合體。如果恢復被否決、命令會顯示恢復進度、以及哪個子系統已對恢復執行了指令。
-
如果尚未傳回任何Aggregate、請執行下列動作:
-
請檢閱「否決因應措施」、以判斷您是否想要處理「『直接』條件、或是要撤銷「否決」。
-
如有必要、請解決錯誤訊息中所述的「『驗證』條件、確保所有已識別的作業都能正常終止。
-
重新輸入儲存容錯移轉恢復命令。
如果您決定覆寫「vito'」條件、請將-overre-etoes參數設為true。
-
-
至少等待八分鐘、以確保發生下列情況:
-
用戶端多重路徑(若已部署)會穩定下來。
-
用戶端會從還原期間發生的I/O暫停中恢復。
還原時間是用戶端專屬的、視用戶端應用程式的特性而定、可能需要8分鐘以上的時間。
-
-
將權限等級從 admin 設定為進階、在提示繼續時輸入 * y* :
set -privilege advanced進階提示 (
*>)。 -
確認叢集 A 上的版本:
system image show以下範例顯示系統映像 2(目標 ONTAP 映像)是 node_A_1 上的預設和目前版本:
cluster_A::*> system image show Is Is Install Node Image Default Current Version Date -------- ------- ------- ------- -------- ------------------- node_A_1 image1 false false X.X.X MM/DD/YYYY TIME image2 true true Y.Y.Y MM/DD/YYYY TIME node_A_2 image1 false true X.X.X MM/DD/YYYY TIME image2 true false Y.Y.Y MM/DD/YYYY TIME 4 entries were displayed. cluster_A::> -
確認叢集 B 上的版本:
system image show以下範例顯示系統映像 2(目標 ONTAP 映像)是 node_B_1 上的預設和目前版本:
cluster_B::*> system image show Is Is Install Node Image Default Current Version Date -------- ------- ------- ------- -------- ------------------- node_B_1 image1 false false X.X.X MM/DD/YYYY TIME image2 true true Y.Y.Y MM/DD/YYYY TIME node_B_2 image1 false true X.X.X MM/DD/YYYY TIME image2 true false Y.Y.Y MM/DD/YYYY TIME 4 entries were displayed. cluster_B::>
正在更新MetroCluster 不只是個DR群組的第二個DR配對
您必須以正確順序執行節點接管與恢復、才能使ONTAP 節點的新版本成為節點的目前版本。
您應該已經升級第一個DR配對(node_a_1和node_B_1)。
在此工作中、 node_a_2 和 node_B_2 會升級。
如果您已在第一個 DR 群組上升級 ONTAP 軟體、並正在八節點 MetroCluster 組態中更新第二個 DR 群組、則在此工作中、您將更新 node_a_4 和 node_B_4 。
-
將所有資料生命從節點移轉至其他位置:
network interface migrate-all -node node_A_2network interface migrate-all -node node_B_2 -
啟動叢集A上目標節點的接管:
請勿指定-option Immediate參數、因為要重新啟動至新軟體映像的節點需要正常接管。
-
接管叢集_A上的DR合作夥伴:
storage failover takeover -ofnode node_A_2 -option allow-version-mismatch
。 allow-version-mismatch從 ONTAP 9.0 升級至 ONTAP 9.1 或任何修補程式升級時、都不需要選項。節點會開機至「等待恢復」狀態。
如果啟用了「支援」、則會傳送一則消息「不支援」、指出節點已超出叢集仲裁。AutoSupport AutoSupport您可以忽略此通知並繼續升級。
-
確認接管成功:
storage failover show以下範例顯示接管作業成功。node_a_2處於「等待恢復」狀態、node_a_1處於「接管」狀態。
cluster_A::> storage failover show Takeover Node Partner Possible State Description -------------- -------------- -------- ------------------------------------- node_A_1 node_A_2 false In takeover node_A_2 node_A_1 - Waiting for giveback (HA mailboxes) 2 entries were displayed. -
-
在叢集B上啟動目標節點的接管:
請勿指定-option Immediate參數、因為要重新啟動至新軟體映像的節點需要正常接管。
-
接管叢集 B 上的 DR 合作夥伴( node_B_2 ):
如果您要從…升級 輸入此命令… 部分版本ONTAP ONTAP
storage failover takeover -ofnode node_B_2部分版本的升級版ONTAP Data ONTAP
storage failover takeover -ofnode node_B_2 -option allow-version-mismatch
。 allow-version-mismatch從 ONTAP 9.0 升級至 ONTAP 9.1 或任何修補程式升級時、都不需要選項。節點會開機至「等待恢復」狀態。
如果啟用 AutoSupport 、則會傳送 AutoSupport 訊息、指出節點已超出叢集仲裁。您可以安全地忽略此通知並繼續升級。 -
確認接管成功:
storage failover show以下範例顯示接管作業成功。node_B_2處於「等待恢復」狀態、node_B_1處於「接管中」狀態。
cluster_B::> storage failover show Takeover Node Partner Possible State Description -------------- -------------- -------- ------------------------------------- node_B_1 node_B_2 false In takeover node_B_2 node_B_1 - Waiting for giveback (HA mailboxes) 2 entries were displayed. -
-
至少等待八分鐘、以確保發生下列情況:
-
用戶端多重路徑(若已部署)會穩定下來。
-
用戶端會從接管期間發生的I/O暫停中恢復。
還原時間是用戶端專屬的、視用戶端應用程式的特性而定、可能需要8分鐘以上的時間。
-
-
將集合體傳回目標節點:
將MetroCluster 靜態IP組態升級ONTAP 為EFlash 9.5之後、集合體將會在重新同步並返回鏡射狀態之前、處於降級狀態一小段時間。
-
將集合物傳回叢集 A 上的 DR 合作夥伴:
storage failover giveback -ofnode node_A_2 -
將集合物傳回叢集 B 上的 DR 合作夥伴:
storage failover giveback -ofnode node_B_2恢復作業會先將根Aggregate傳回節點、然後在節點完成開機之後、傳回非根Aggregate。
-
-
在兩個叢集上發出下列命令、確認已傳回所有的集合體:
storage failover show-giveback如果「歸還狀態」欄位指出沒有要歸還的集合體、則會傳回所有集合體。如果恢復被否決、命令會顯示恢復進度、以及哪個子系統已對恢復執行了指令。
-
如果尚未傳回任何Aggregate、請執行下列動作:
-
請檢閱「否決因應措施」、以判斷您是否想要處理「『直接』條件、或是要撤銷「否決」。
-
如有必要、請解決錯誤訊息中所述的「『驗證』條件、確保所有已識別的作業都能正常終止。
-
重新輸入儲存容錯移轉恢復命令。
如果您決定覆寫「vito'」條件、請將-overre-etoes參數設為true。
-
-
至少等待八分鐘、以確保發生下列情況:
-
用戶端多重路徑(若已部署)會穩定下來。
-
用戶端會從還原期間發生的I/O暫停中恢復。
還原時間是用戶端專屬的、視用戶端應用程式的特性而定、可能需要8分鐘以上的時間。
-
-
將權限等級從 admin 設定為進階、在提示繼續時輸入 * y* :
set -privilege advanced進階提示 (
*>)。 -
確認叢集 A 上的版本:
system image show以下範例顯示系統映像 2 (目標 ONTAP 映像)是 node_A_2 上的預設和目前版本:
cluster_A::*> system image show Is Is Install Node Image Default Current Version Date -------- ------- ------- ------- ---------- ------------------- node_A_1 image1 false false X.X.X MM/DD/YYYY TIME image2 true true Y.Y.Y MM/DD/YYYY TIME node_A_2 image1 false false X.X.X MM/DD/YYYY TIME image2 true true Y.Y.Y MM/DD/YYYY TIME 4 entries were displayed. cluster_A::> -
確認叢集 B 上的版本:
system image show以下範例顯示系統映像 2(目標 ONTAP 映像)是 node_B_2 上的預設和目前版本:
cluster_B::*> system image show Is Is Install Node Image Default Current Version Date -------- ------- ------- ------- ---------- ------------------- node_B_1 image1 false false X.X.X MM/DD/YYYY TIME image2 true true Y.Y.Y MM/DD/YYYY TIME node_B_2 image1 false false X.X.X MM/DD/YYYY TIME image2 true true Y.Y.Y MM/DD/YYYY TIME 4 entries were displayed. cluster_B::> -
針對 HA 配對中的每個節點、啟用自動恢復:
storage failover modify -node target-node -auto-giveback true此命令必須針對HA配對中的每個節點重複執行。
-
確認已啟用自動恢復:
storage failover show -fields auto-giveback此範例顯示兩個節點均已啟用自動恢復功能:
cluster_x::> storage failover show -fields auto-giveback node auto-giveback -------- ------------- node_x_1 true node_x_2 true 2 entries were displayed.