

Hadoop S3A 調校
 建議變更
建議變更
_ 作者: Angela Cheng _
Hadoop S3A 連接器可促進 Hadoop 應用程式與 S3 物件儲存之間的順暢互動。調整 Hadoop S3A Connector 是在使用 S3 物件儲存設備時最佳化效能的關鍵。在我們開始調整詳細資料之前、讓我們先基本瞭解 Hadoop 及其元件。
什麼是 Hadoop ?
-
Hadoop * 是功能強大的開放原始碼架構、專為處理大規模資料處理與儲存而設計。它可跨電腦叢集進行分散式儲存和平行處理。
Hadoop 的三個核心元件為:
-
* Hadoop HDFS ( Hadoop 分散式檔案系統) * :此功能可處理儲存、將資料分成區塊、並在節點之間散佈。
-
* Hadoop MapReduce * :負責處理資料、將工作分割成較小的區塊、並平行執行。
-
* 哈大諾布(又是另一個資源協商者): * "有效管理資源並排程工作"
Hadoop HDFS 和 S3A 接頭
HDFS 是 Hadoop 生態系統的重要元件、在高效率的巨量資料處理中扮演重要角色。HDFS 提供可靠的儲存與管理功能。它可確保平行處理和最佳化的資料儲存、進而加快資料存取和分析速度。
在巨量資料處理中、 HDFS 在為大型資料集提供容錯儲存方面表現優異。它透過資料複寫來達成此目標。它可以在資料倉儲環境中儲存及管理大量的結構化和非結構化資料。此外、它還能與領先業界的巨量資料處理架構(例如 Apache Spark 、 Hive 、 Pig 和 Fllink )無縫整合、實現可擴充且有效率的資料處理。它與 Unix ( Linux )作業系統相容、是偏好使用 Linux 環境進行巨量資料處理的組織的理想選擇。
隨著資料量隨著時間成長、將新機器新增至 Hadoop 叢集、並使用其本身的運算和儲存設備的方法變得效率不彰。線性擴充會在有效使用資源和管理基礎架構方面帶來挑戰。
為了因應這些挑戰、 Hadoop S3A 連接器提供高效能 I/O 、可與 S3 物件儲存設備相較。運用S3A實作Hadoop工作流程、有助於將物件儲存設備當作資料儲存庫、並可將運算與儲存設備分開、進而獨立擴充運算與儲存設備。分離運算和儲存設備也能讓您將適當的資源量用於運算工作、並根據資料集的大小提供容量。因此、您可以降低Hadoop工作流程的整體TCO。
Hadoop S3A 接頭調校
S3 的行為與 HDFS 不同、有些為了保留檔案系統外觀的嘗試則不佳。為了最有效地使用 S3 資源、必須仔細調整 / 測試 / 實驗。
本文中的 Hadoop 選項是以 Hadoop 3.3.5 為基礎、請參閱 "Hadoop 3.3.5 core-site.xml" 適用於所有可用選項。
附註:在每個 Hadoop 版本中、某些 Hadoop FS.s3a 設定的預設值會有所不同。請務必查看您目前 Hadoop 版本的預設值。如果這些設定未在 Hadoop 核心網站 .xml 中指定、則會使用預設值。您可以使用 Spark 或 Hive 組態選項、在執行階段覆寫值。
您一定要來這裏 "Apache Hadoop 頁面" 以瞭解每個 FS.s3a 選項。如有可能、請在非正式作業 Hadoop 叢集中測試它們、以找出最佳值。
您應該閱讀 "使用 S3A 連接器時發揮最大效能" 以取得其他調整建議。
讓我們來探討一些重要考量:
-
1。資料壓縮 *
請勿啟用 StorageGRID 壓縮。大部分的巨量資料系統使用位元組範圍 GET 、而非擷取整個物件。使用位元組範圍取得壓縮物件會大幅降低取得效能。
2.S3A 交付人 *
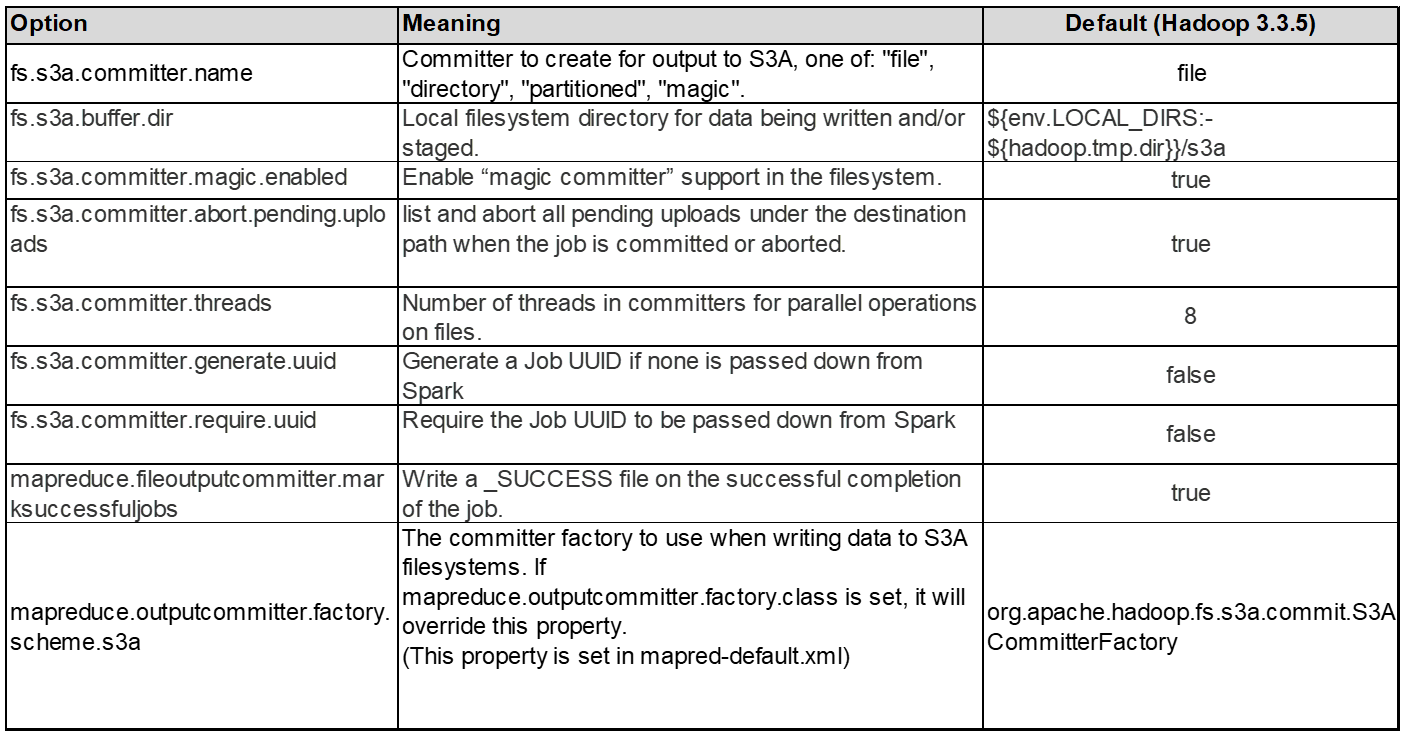
一般而言、建議使用 magic s3a committer 。請參閱此 "一般 S3A 交付選項頁面" 更深入瞭解魔術棒及其相關的 s3a 設定。
Magic Committer :
Magic Committer 特別仰賴 S3Guard 在 S3 物件存放區上提供一致的目錄清單。
有了一致的 S3 (現在就是這樣)、萬智牌委員會就能安全地與任何 S3 儲存桶搭配使用。
選擇與實驗:
視您的使用案例而定、您可以在 Staging Committer (依賴叢集 HDFS 檔案系統)和 Magic Committer 之間進行選擇。
請嘗試兩者、以判斷哪一種最適合您的工作負載和需求。
總結來說、 S3A Commiters 提供解決方案、以因應對 S3 的一致、高效能及可靠輸出承諾這項基本挑戰。其內部設計可確保資料傳輸效率、同時維持資料完整性。
-
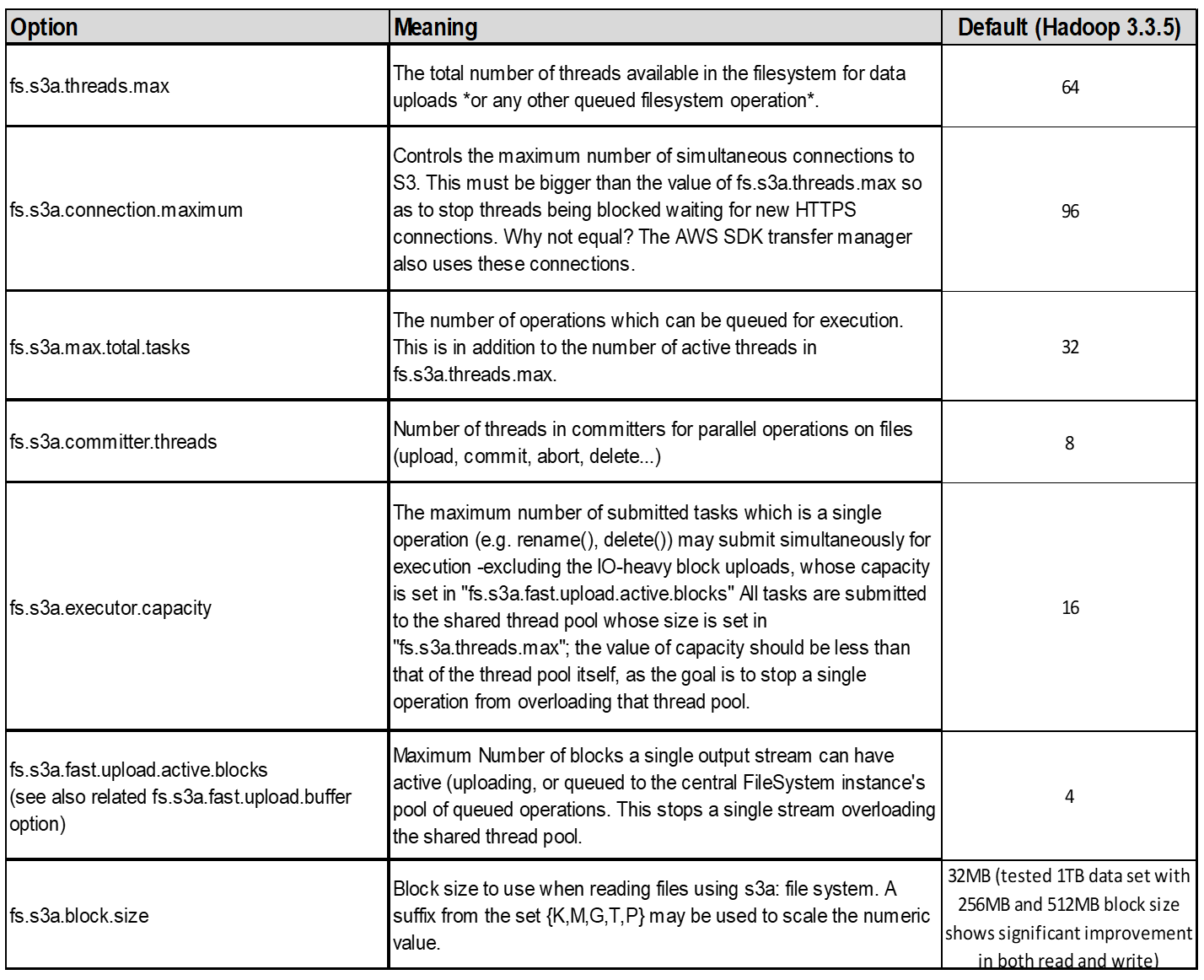
3.執行緒、連線集區大小和區塊大小 *
-
每個與單一貯體互動的 S3A 用戶端都有其專屬的開放式 HTTP 1.1 連線集區和執行緒、可用於上傳及複製作業。
-
將資料上傳至 S3 時、資料會分成區塊。預設區塊大小為 32 MB 。您可以設定 FS.s3a.block.size 屬性來自訂此值。
-
較大的區塊大小可降低上傳期間管理多個零件的成本、進而改善大型資料上傳的效能。大型資料集的建議值為 256 MB 或更高。
*4.多部分上傳 *
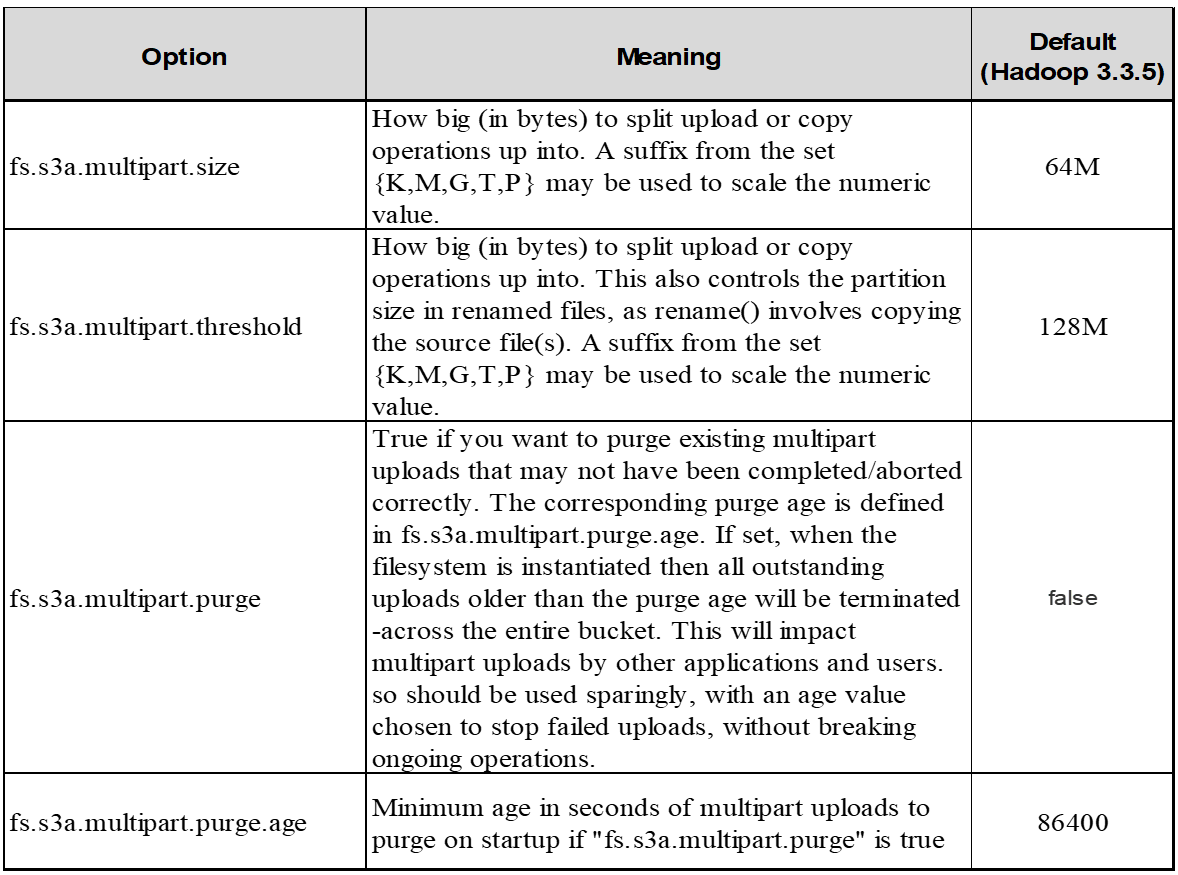
s3a commiters * Always * 使用 MPU (多部分上傳)將資料上傳至 S3 儲存庫。這是為了允許:工作失敗、工作的投機性執行、以及工作在提交前中止。以下是與多部分上傳相關的一些重要規格:
-
最大物件大小: 5 TiB ( TB )。
-
每次上傳的最大零件數: 10 、 000 。
-
零件編號:範圍從 1 到 10 、 000 (含)。
-
零件大小:介於 5 MIB 和 5 GiB 之間。值得注意的是、您的多部分上傳最後一部分沒有最小大小限制。
將較小的零件大小用於 S3 多個部分上傳、既有優點也有缺點。
-
優點 * :
-
從網路快速恢復問題:當您上傳較小的零件時、因為網路錯誤而重新啟動失敗上傳的影響會降至最低。如果零件失敗、您只需要重新上傳該特定零件、而不需要重新上傳整個物件。
-
更佳的平行化:可以同時上傳更多零件、同時利用多執行緒或並行連線。這種平行化可提升效能、尤其是處理大型檔案時。
-
缺點 * :
-
網路負荷:較小的零件尺寸代表需要上傳更多零件、每個零件都需要自己的 HTTP 要求。更多 HTTP 要求會增加啟動和完成個別要求的成本。管理大量的小型零件可能會影響效能。
-
複雜度:管理訂單、追蹤零件、以及確保成功上傳可能會很麻煩。如果需要中止上傳、則需要追蹤和清除所有已上傳的零件。
若為 Hadoop 、建議使用 256 MB 或以上的零件大小、以使用 FS.s3a.multite.size 。請務必將 FS.s3a.mutlipart.threshold 值設為 2 x FS.s3a.multipe.size 值。例如、 fs.s3a.multipe.size = 256M 、 fs.s3a.mutlipart.threshold 應為 512M 。
大型資料集使用較大的零件大小。請務必根據您的特定使用案例和網路條件、選擇零件尺寸來平衡這些因素。
多部分上傳是 "三步驟程序":
-
上傳即會啟動、 StorageGRID 會傳回上傳 ID 。
-
物件零件會使用 upload-id.
-
上傳所有物件零件後、會傳送完整的多個部分上傳要求與 upload-id.StorageGRID 會從上傳的零件建構物件、用戶端可以存取物件。
如果未成功傳送完整的多部分上傳要求、則零件會留在 StorageGRID 中、不會建立任何物件。當工作中斷、失敗或中止時、就會發生這種情況。零件會保留在網格中、直到多個零件上傳完成或中止、或 StorageGRID 在上傳開始後 15 天內清除這些零件。如果在某個儲存庫中有許多(數十萬到數百萬)進行中的多部分上傳、當 Hadoop 傳送「 list-multify-upload 」(此要求不依上傳 ID 篩選)時、要求可能需要很長時間才能完成或最終逾時。您可以考慮將 FS.s3a.mutlipart.purge 設為 true 、並設定適當的 FS.s3a.multipe.pure.age 值(例如 5 至 7 天、請勿使用 86400 的預設值、即 1 天)。或請 NetApp 支援人員調查情況。
*5.緩衝區將資料寫入記憶體 *
若要提升效能、您可以在將資料上傳至 S3 之前、先緩衝寫入記憶體中的資料。這樣可以減少小寫入次數、並提高效率。

請記住、 S3 和 HDFS 的運作方式各不相同。為了最有效地使用 S3 資源、必須仔細調整 / 測試 / 實驗。