

Analyse eines dynamischen Performance-Ereignisses auf einem Cluster in einer MetroCluster Konfiguration
 Änderungen vorschlagen
Änderungen vorschlagen
Sie können Unified Manager verwenden, um das Cluster in einer MetroCluster-Konfiguration zu analysieren, bei der ein Performance-Ereignis erkannt wurde. Sie können den Cluster-Namen, die Ereigniserkennungszeit und die damit verbundenen Workloads bully und victim identifizieren.
Was Sie brauchen
-
Sie müssen über die Rolle „Operator“, „Application Administrator“ oder „Storage Administrator“ verfügen.
-
Für eine MetroCluster-Konfiguration müssen neue, anerkannte oder veraltete Performance-Ereignisse vorliegen.
-
Beide Cluster in der MetroCluster-Konfiguration müssen von derselben Instanz von Unified Manager überwacht werden.
-
Rufen Sie die Seite Ereignisdetails auf, um Informationen über das Ereignis anzuzeigen.
-
Die Ereignisbeschreibung enthält Namen der betroffenen Workloads sowie die Anzahl der betroffenen Workloads.
In diesem Beispiel ist das Symbol für MetroCluster-Ressourcen rot dargestellt, was bedeutet, dass die MetroCluster-Ressourcen über Konflikte verfügen. Sie positionieren den Cursor über das Symbol, um eine Beschreibung des Symbols anzuzeigen.

-
Notieren Sie sich den Cluster-Namen und die Ereignis-Erkennungszeit, mit der Sie Performance-Ereignisse im Partner-Cluster analysieren können.
-
Überprüfen Sie in den Diagrammen die „_victim_Workloads“, um zu bestätigen, dass ihre Antwortzeiten höher sind als der Performance-Schwellenwert.
In diesem Beispiel wird der Workload des Opfers im Hover-Text angezeigt. Die Latenzdiagramme werden auf hoher Ebene angezeigt, ein konsistentes Latenzmuster für die betroffenen Opfer-Workloads. Obwohl die anormale Latenz der betroffenen Workloads das Ereignis ausgelöst hat, kann ein konsistentes Latenzmuster darauf hindeuten, dass die Workloads innerhalb des erwarteten Bereichs liegen. Durch einen Spitzen bei den I/O wurde die Latenz erhöht und das Ereignis ausgelöst.
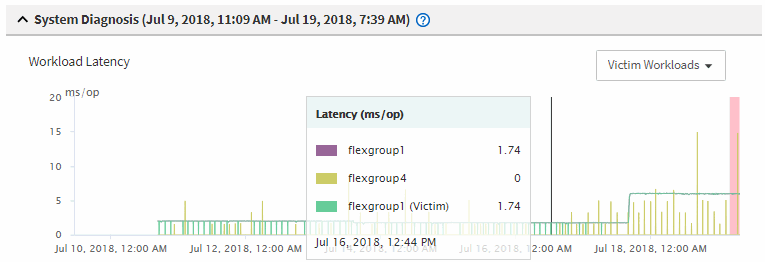
Falls Sie vor Kurzem eine Applikation auf einem Client installiert haben, der auf diese Volume-Workloads zugreift und die Applikation eine hohe Anzahl an I/O-Vorgängen sendet, kann die Verzögerungen bereits vorwegnehmen. Wenn die Latenz für die Workloads innerhalb des erwarteten Bereichs zurückkehrt, ändert sich der Ereignisstatus zu veraltet und bleibt mehr als 30 Minuten in diesem Status, können Sie das Ereignis wahrscheinlich ignorieren. Wenn das Ereignis andauernde und im neuen Status verbleibt, können Sie es weiter untersuchen, um festzustellen, ob andere Probleme das Ereignis verursacht haben.
-
Wählen Sie im Workload-Durchsatzdiagramm die Option problematische Workloads aus, um die problematische Workloads anzuzeigen.
Die Anwesenheit von problematischer Workloads zeigt an, dass ein Ereignis möglicherweise durch eine oder mehrere Workloads auf dem lokalen Cluster verursacht wurde, bei denen die MetroCluster-Ressourcen überlastet sind. Die problematische Workloads weisen eine hohe Abweichung beim Schreibdurchsatz (MB/s) auf.
Dieses Diagramm zeigt auf hoher Ebene das Muster für den Schreibdurchsatz (MB/s) für die Workloads an. Sie können das MB/s-Muster für Schreibvorgänge überprüfen, um einen anormalen Durchsatz zu identifizieren, der darauf hindeutet, dass ein Workload die MetroCluster-Ressourcen überausgelastet ist.
Wenn an diesem Ereignis keine problematische Workloads beteiligt sind, wurde dieses Ereignis möglicherweise durch ein Systemzustandsproblem mit der Verbindung zwischen den Clustern oder durch ein Performance-Problem auf dem Partner-Cluster verursacht. Sie können Unified Manager verwenden, um den Systemzustand beider Cluster in einer MetroCluster Konfiguration zu überprüfen. Außerdem können Sie mit Unified Manager Performance-Ereignisse im Partner-Cluster überprüfen und analysieren.