

So nutzt Unified Manager die Workload-Latenz, um Leistungsprobleme zu identifizieren
 Änderungen vorschlagen
Änderungen vorschlagen
Die Workload-Latenz (Antwortzeit) ist die Zeit, die ein Volume in einem Cluster benötigt, um auf E/A-Anfragen von Clientanwendungen zu antworten. Unified Manager nutzt die Latenz, um Leistungsereignisse zu erkennen und Sie darauf aufmerksam zu machen.
Eine hohe Latenz bedeutet, dass Anfragen von Anwendungen an ein Volume in einem Cluster länger als üblich dauern. Die Ursache für die hohe Latenz könnte im Cluster selbst liegen, da es zu Konflikten bei einer oder mehreren Clusterkomponenten kommt. Eine hohe Latenz kann auch durch Probleme außerhalb des Clusters verursacht werden, beispielsweise Netzwerkengpässe, Probleme mit dem Client, der die Anwendungen hostet, oder Probleme mit den Anwendungen selbst.

|
Unified Manager überwacht nur die Workload-Aktivität im Cluster. Es überwacht weder die Anwendungen, die Clients noch die Pfade zwischen den Anwendungen und dem Cluster. |
Vorgänge im Cluster, wie etwa das Erstellen von Sicherungen oder Ausführen einer Deduplizierung, die den Bedarf an Clusterkomponenten erhöhen, die von anderen Workloads gemeinsam genutzt werden, können ebenfalls zu einer hohen Latenz beitragen. Wenn die tatsächliche Latenz den dynamischen Leistungsschwellenwert des erwarteten Bereichs (Latenzprognose) überschreitet, analysiert Unified Manager das Ereignis, um festzustellen, ob es sich um ein Leistungsereignis handelt, das Sie möglicherweise beheben müssen. Die Latenz wird in Millisekunden pro Vorgang (ms/op) gemessen.
Im Diagramm „Gesamtlatenz“ auf der Seite „Arbeitslastanalyse“ können Sie eine Analyse der Latenzstatistiken anzeigen, um zu sehen, wie die Aktivität einzelner Prozesse, z. B. Lese- und Schreibanforderungen, im Vergleich zur Gesamtlatenzstatistik abschneidet. Mithilfe des Vergleichs können Sie feststellen, welche Vorgänge die höchste Aktivität aufweisen oder ob bei bestimmten Vorgängen eine anormale Aktivität auftritt, die sich auf die Latenz eines Datenträgers auswirkt. Beim Analysieren von Leistungsereignissen können Sie anhand der Latenzstatistiken feststellen, ob ein Ereignis durch ein Problem im Cluster verursacht wurde. Sie können auch die spezifischen Workload-Aktivitäten oder Clusterkomponenten identifizieren, die an dem Ereignis beteiligt sind.
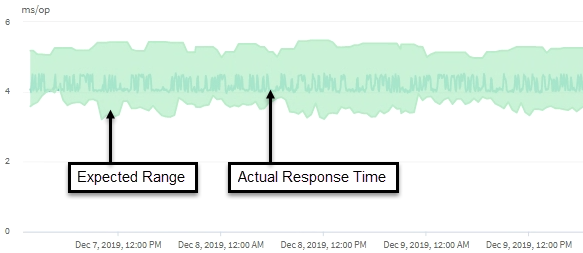
Dieses Beispiel zeigt das Latenzdiagramm. Die tatsächliche Reaktionszeit (Latenz) ist eine blaue Linie und die Latenzprognose (erwarteter Bereich) ist grün.
|
|
Wenn Unified Manager keine Daten erfassen konnte, können Lücken in der blauen Linie vorhanden sein. Dies kann auftreten, weil der Cluster oder das Volume nicht erreichbar war, Unified Manager während dieser Zeit ausgeschaltet war oder die Erfassung länger als die 5-Minuten-Erfassungsdauer dauerte. |