Erfahren Sie mehr über Cloud Volumes ONTAP HA-Paare in AWS
 Änderungen vorschlagen
Änderungen vorschlagen
Eine Cloud Volumes ONTAP Hochverfügbarkeitskonfiguration (HA) bietet unterbrechungsfreien Betrieb und Fehlertoleranz. In AWS werden Daten synchron zwischen den beiden Knoten gespiegelt.
HA-Komponenten
In AWS umfassen Cloud Volumes ONTAP HA-Konfigurationen die folgenden Komponenten:
-
Zwei Cloud Volumes ONTAP Knoten, deren Daten synchron untereinander gespiegelt werden.
-
Eine Mediatorinstanz, die einen Kommunikationskanal zwischen den Knoten bereitstellt, um bei der Übernahme und Rückgabe von Speicher zu helfen.
Vermittler
Hier sind einige wichtige Details zur Mediator-Instanz in AWS:
- Instanztyp
-
t3-Mikro
- Festplatten
-
Zwei st1-Festplatten mit 8 GiB und 4 GiB
- Betriebssystem
-
Debian 11

Für Cloud Volumes ONTAP 9.10.0 und früher wurde Debian 10 auf dem Mediator installiert. - Verbesserungen
-
Wenn Sie Cloud Volumes ONTAP aktualisieren, aktualisiert die NetApp Console bei Bedarf auch die Mediatorinstanz.
- Zugriff auf die Instanz
-
Wenn Sie ein Cloud Volumes ONTAP HA-Paar über die Konsole erstellen, werden Sie aufgefordert, ein Schlüsselpaar für die Mediatorinstanz anzugeben. Sie können dieses Schlüsselpaar für den SSH-Zugriff verwenden, indem Sie
adminBenutzer. - Drittanbieter-Agenten
-
Agenten oder VM-Erweiterungen von Drittanbietern werden auf der Mediatorinstanz nicht unterstützt.
Speicherübernahme und -rückgabe
Wenn ein Knoten ausfällt, kann der andere Knoten Daten für seinen Partner bereitstellen, um einen kontinuierlichen Datendienst bereitzustellen. Clients können auf dieselben Daten des Partnerknotens zugreifen, da die Daten synchron zum Partner gespiegelt wurden.
Nach dem Neustart des Knotens muss der Partner die Daten erneut synchronisieren, bevor er den Speicher zurückgeben kann. Die zum erneuten Synchronisieren der Daten benötigte Zeit hängt davon ab, wie viele Daten geändert wurden, während der Knoten ausgefallen war.
Die Speicherübernahme, Neusynchronisierung und Rückgabe erfolgen standardmäßig automatisch. Es ist keine Benutzeraktion erforderlich.
RPO und RTO
Eine HA-Konfiguration gewährleistet die Hochverfügbarkeit Ihrer Daten wie folgt:
-
Das Recovery Point Objective (RPO) beträgt 0 Sekunden. Ihre Daten sind transaktionskonsistent und es kommt zu keinem Datenverlust.
-
Die Wiederherstellungszeit (RTO) beträgt 120 Sekunden. Im Falle eines Ausfalls sollten die Daten in 120 Sekunden oder weniger verfügbar sein.
HA-Bereitstellungsmodelle
Sie können die Hochverfügbarkeit Ihrer Daten sicherstellen, indem Sie eine HA-Konfiguration über mehrere Verfügbarkeitszonen (AZs) oder in einer einzelnen Verfügbarkeitszone (AZ) bereitstellen. Sie sollten sich die Einzelheiten zu jeder Konfiguration genauer ansehen, um die Konfiguration auszuwählen, die Ihren Anforderungen am besten entspricht.
Mehrere Verfügbarkeitszonen
Durch die Bereitstellung einer HA-Konfiguration in mehreren Verfügbarkeitszonen (AZs) wird eine hohe Verfügbarkeit Ihrer Daten gewährleistet, wenn bei einer AZ oder einer Instanz, auf der ein Cloud Volumes ONTAP Knoten ausgeführt wird, ein Fehler auftritt. Sie sollten verstehen, welche Auswirkungen NAS-IP-Adressen auf den Datenzugriff und das Speicher-Failover haben.
NFS- und CIFS-Datenzugriff
Wenn eine HA-Konfiguration über mehrere Verfügbarkeitszonen verteilt ist, ermöglichen Floating IP-Adressen den NAS-Clientzugriff. Die Floating-IP-Adressen, die für alle VPCs in der Region außerhalb der CIDR-Blöcke liegen müssen, können bei Fehlern zwischen Knoten migrieren. Sie sind für Clients außerhalb der VPC nicht nativ zugänglich, es sei denn, Sie"Einrichten eines AWS Transit Gateways" .
Wenn Sie kein Transit-Gateway einrichten können, stehen private IP-Adressen für NAS-Clients außerhalb der VPC zur Verfügung. Diese IP-Adressen sind jedoch statisch und können nicht zwischen Knoten umgeschaltet werden.
Sie sollten die Anforderungen für Floating-IP-Adressen und Routentabellen überprüfen, bevor Sie eine HA-Konfiguration über mehrere Verfügbarkeitszonen hinweg bereitstellen. Sie müssen die Floating-IP-Adressen angeben, wenn Sie die Konfiguration bereitstellen. Die privaten IP-Adressen werden automatisch erstellt.
Weitere Informationen finden Sie unter "AWS-Netzwerkanforderungen für Cloud Volumes ONTAP HA in mehreren AZs" .
iSCSI-Datenzugriff
Die VPC-übergreifende Datenkommunikation stellt kein Problem dar, da iSCSI keine Floating-IP-Adressen verwendet.
Übernahme und Rückgabe für iSCSI
Für iSCSI verwendet Cloud Volumes ONTAP Multipath I/O (MPIO) und Asymmetric Logical Unit Access (ALUA), um das Pfad-Failover zwischen den aktiv optimierten und nicht optimierten Pfaden zu verwalten.
|
|
Informationen darüber, welche spezifischen Hostkonfigurationen ALUA unterstützen, finden Sie im "NetApp Interoperabilitätsmatrix-Tool" und die "Leitfaden für SAN-Hosts und Cloud-Clients" für Ihr Host-Betriebssystem. |
Übernahme und Rückgabe für NAS
Wenn in einer NAS-Konfiguration mit Floating-IPs eine Übernahme erfolgt, wird die Floating-IP-Adresse des Knotens, die Clients für den Datenzugriff verwenden, auf den anderen Knoten verschoben. Das folgende Bild zeigt die Speicherübernahme in einer NAS-Konfiguration mit Floating-IPs. Wenn Knoten 2 ausfällt, wird die Floating-IP-Adresse für Knoten 2 auf Knoten 1 verschoben.
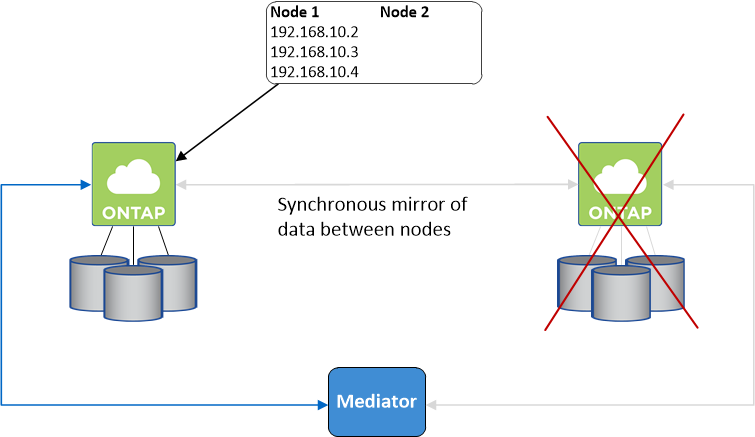
Für den externen VPC-Zugriff verwendete NAS-Daten-IPs können bei Fehlern nicht zwischen Knoten migriert werden. Wenn ein Knoten offline geht, müssen Sie Volumes manuell erneut an Clients außerhalb der VPC anbinden, indem Sie die IP-Adresse auf dem anderen Knoten verwenden.
Nachdem der ausgefallene Knoten wieder online ist, mounten Sie die Clients erneut mit der ursprünglichen IP-Adresse auf den Volumes. Dieser Schritt ist erforderlich, um die Übertragung unnötiger Daten zwischen zwei HA-Knoten zu vermeiden, die erhebliche Auswirkungen auf Leistung und Stabilität haben können.
Sie können die richtige IP-Adresse in der Konsole ermitteln, indem Sie das Volume auswählen und auf Mount Command klicken.
Einzelne Verfügbarkeitszone
Durch die Bereitstellung einer HA-Konfiguration in einer einzelnen Verfügbarkeitszone (AZ) können Sie eine hohe Verfügbarkeit Ihrer Daten sicherstellen, wenn eine Instanz ausfällt, auf der ein Cloud Volumes ONTAP Knoten ausgeführt wird. Auf alle Daten kann nativ von außerhalb der VPC zugegriffen werden.
|
|
Die Konsole erstellt eine "AWS-Dokumentation: AWS Spread Placement Group" und startet die beiden HA-Knoten in dieser Platzierungsgruppe. Die Platzierungsgruppe verringert das Risiko gleichzeitiger Ausfälle, indem sie die Instanzen auf unterschiedliche zugrunde liegende Hardware verteilt. Diese Funktion verbessert die Redundanz aus der Perspektive der Datenverarbeitung und nicht aus der Perspektive eines Festplattenausfalls. |
Datenzugriff
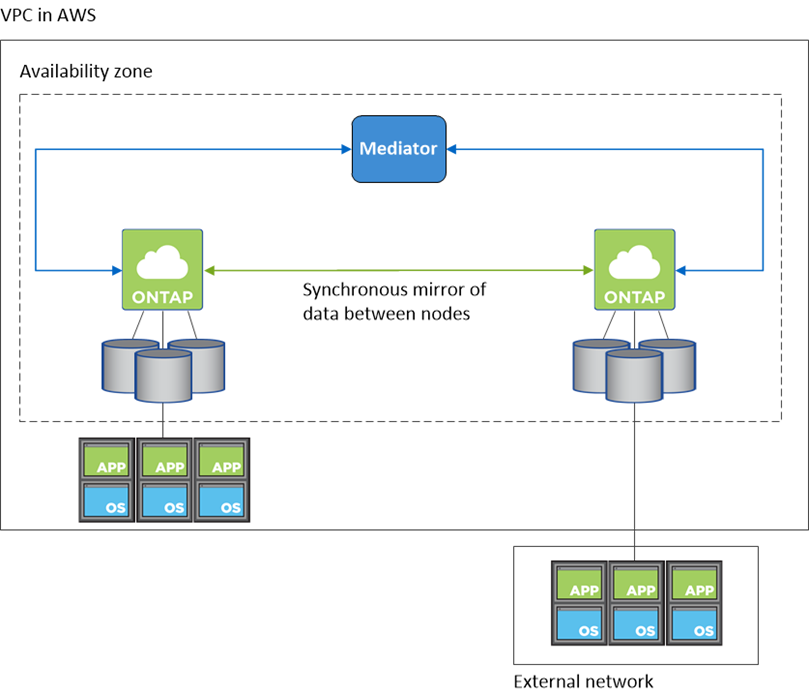
Da sich diese Konfiguration in einer einzelnen AZ befindet, sind keine Floating-IP-Adressen erforderlich. Sie können dieselbe IP-Adresse für den Datenzugriff innerhalb und außerhalb der VPC verwenden.
Das folgende Bild zeigt eine HA-Konfiguration in einer einzelnen AZ. Auf die Daten kann innerhalb und außerhalb der VPC zugegriffen werden.
Übernahme und Rückgabe
Für iSCSI verwendet Cloud Volumes ONTAP Multipath I/O (MPIO) und Asymmetric Logical Unit Access (ALUA), um das Pfad-Failover zwischen den aktiv optimierten und nicht optimierten Pfaden zu verwalten.
|
|
Informationen darüber, welche spezifischen Hostkonfigurationen ALUA unterstützen, finden Sie im "NetApp Interoperabilitätsmatrix-Tool" und die "Leitfaden für SAN-Hosts und Cloud-Clients" für Ihr Host-Betriebssystem. |
Bei NAS-Konfigurationen können die Daten-IP-Adressen bei Fehlern zwischen HA-Knoten migrieren. Dadurch wird der Clientzugriff auf den Speicher sichergestellt.
Lokale AWS-Zonen
Bei AWS Local Zones handelt es sich um eine Infrastrukturbereitstellung, bei der Speicher, Rechenleistung, Datenbanken und andere ausgewählte AWS-Dienste in der Nähe von Großstädten und Industriegebieten angesiedelt sind. Mit AWS Local Zones können Sie AWS-Dienste näher zu sich holen, was die Latenz für Ihre Workloads verbessert und Datenbanken lokal verwaltet. Auf Cloud Volumes ONTAP,
Sie können eine einzelne AZ oder mehrere AZ-Konfigurationen in AWS Local Zones bereitstellen.
|
|
AWS Local Zones werden unterstützt, wenn die Konsole im Standard- und privaten Modus verwendet wird. Derzeit werden AWS Local Zones im eingeschränkten Modus nicht unterstützt. |
Beispielkonfigurationen für AWS Local Zone
Cloud Volumes ONTAP in AWS unterstützt nur den Hochverfügbarkeitsmodus (HA) in einer einzelnen Verfügbarkeitszone. Bereitstellungen mit einem einzelnen Knoten werden nicht unterstützt.
Cloud Volumes ONTAP unterstützt kein Daten-Tiering, Cloud-Tiering und nicht qualifizierte Instanzen in AWS Local Zones.
Nachfolgend sind Beispielkonfigurationen aufgeführt:
-
Einzelne Verfügbarkeitszone: Beide Clusterknoten und der Mediator befinden sich in derselben lokalen Zone.
-
Mehrere Verfügbarkeitszonen In Konfigurationen mit mehreren Verfügbarkeitszonen gibt es drei Instanzen, zwei Knoten und einen Mediator. Eine der drei Instanzen muss sich in einer separaten Zone befinden. Sie können wählen, wie Sie dies einrichten.
Hier sind drei Beispielkonfigurationen:
-
Jeder Clusterknoten befindet sich in einer anderen lokalen Zone und der Mediator in einer öffentlichen Verfügbarkeitszone.
-
Ein Clusterknoten in einer lokalen Zone, der Mediator in einer lokalen Zone und der zweite Clusterknoten befindet sich in einer Verfügbarkeitszone.
-
Jeder Clusterknoten und der Mediator befinden sich in separaten lokalen Zonen.
-
Unterstützte Datenträger- und Instanztypen
Der einzige unterstützte Datenträgertyp ist GP2. Die folgenden EC2-Instance-Typfamilien mit den Größen xlarge bis 4xlarge werden derzeit unterstützt:
-
M5
-
C5
-
C5d
-
R5
-
R5d
|
|
Cloud Volumes ONTAP unterstützt ausschließlich diese Konfigurationen. Die Auswahl nicht unterstützter Datenträgertypen oder nicht qualifizierter Instanzen in der AWS Local Zone-Konfiguration kann zu einem Bereitstellungsfehler führen. Data Tiering zu Amazon Simple Storage Service (Amazon S3) wird nicht unterstützt, wenn sich Ihr Cloud Volumes ONTAP System in einer AWS Local Zone befindet, da der Zugriff auf die Amazon S3-Buckets außerhalb der Local Zone mit einer höheren Latenz verbunden ist und die Aktivitäten von Cloud Volumes ONTAP beeinträchtigt. |
Funktionsweise der Speicherung in einem HA-Paar
Anders als bei einem ONTAP Cluster wird der Speicher in einem Cloud Volumes ONTAP HA-Paar nicht zwischen den Knoten geteilt. Stattdessen werden die Daten synchron zwischen den Knoten gespiegelt, sodass die Daten im Fehlerfall verfügbar sind.
Speicherzuweisung
Wenn Sie ein neues Volume erstellen und zusätzliche Datenträger benötigt werden, weist die Konsole beiden Knoten die gleiche Anzahl an Datenträgern zu, erstellt ein gespiegeltes Aggregat und erstellt dann das neue Volume. Wenn beispielsweise zwei Festplatten für das Volume erforderlich sind, weist die Konsole zwei Festplatten pro Knoten zu, sodass insgesamt vier Festplatten vorhanden sind.
Speicherkonfigurationen
Sie können ein HA-Paar als Aktiv-Aktiv-Konfiguration verwenden, bei der beide Knoten Daten an Clients bereitstellen, oder als Aktiv-Passiv-Konfiguration, bei der der passive Knoten nur dann auf Datenanforderungen antwortet, wenn er den Speicher für den aktiven Knoten übernommen hat.
|
|
Sie können eine Aktiv-Aktiv-Konfiguration nur einrichten, wenn Sie die Konsole in der Speichersystemansicht verwenden. |
Leistungserwartungen
Eine Cloud Volumes ONTAP HA-Konfiguration repliziert Daten synchron zwischen Knoten, was Netzwerkbandbreite verbraucht. Im Vergleich zu einer Cloud Volumes ONTAP -Konfiguration mit einem einzelnen Knoten können Sie daher die folgende Leistung erwarten:
-
Bei HA-Konfigurationen, die Daten von nur einem Knoten bereitstellen, ist die Leseleistung mit der Leseleistung einer Einzelknotenkonfiguration vergleichbar, während die Schreibleistung geringer ist.
-
Bei HA-Konfigurationen, die Daten von beiden Knoten bereitstellen, ist die Leseleistung höher als die Leseleistung einer Einzelknotenkonfiguration und die Schreibleistung ist gleich oder höher.
Weitere Informationen zur Leistung von Cloud Volumes ONTAP finden Sie unter"Performance" .
Clientzugriff auf Speicher
Clients sollten auf NFS- und CIFS-Volumes zugreifen, indem sie die Daten-IP-Adresse des Knotens verwenden, auf dem sich das Volume befindet. Wenn NAS-Clients über die IP-Adresse des Partnerknotens auf ein Volume zugreifen, wird der Datenverkehr zwischen beiden Knoten geleitet, was die Leistung verringert.

|
Wenn Sie ein Volume zwischen Knoten in einem HA-Paar verschieben, sollten Sie das Volume unter Verwendung der IP-Adresse des anderen Knotens erneut mounten. Andernfalls kann es zu Leistungseinbußen kommen. Wenn Clients NFSv4-Verweise oder Ordnerumleitungen für CIFS unterstützen, können Sie diese Funktionen auf den Cloud Volumes ONTAP Systemen aktivieren, um eine erneute Bereitstellung des Volumes zu vermeiden. Einzelheiten finden Sie in der ONTAP -Dokumentation. |
Sie können die richtige IP-Adresse ganz einfach über die Option „Mount Command“ im Bereich „Volumes verwalten“ ermitteln.