

API für Data Infrastructure Insights
 Änderungen vorschlagen
Änderungen vorschlagen
Die Data Infrastructure Insights API ermöglicht NetApp Kunden und unabhängigen Softwareanbietern (ISVs) , Data Infrastructure Insights in andere Anwendungen wie CMDBs oder andere Ticketsysteme zu integrieren.
Data Infrastructure Insights"Feature-Set-Rolle" bestimmt, auf welche APIs Sie zugreifen können. Die Rollen „Benutzer“ und „Gast“ verfügen über weniger Berechtigungen als die Rolle „Administrator“. Wenn Sie beispielsweise in Monitor und Optimize die Administratorrolle haben, in Reporting jedoch die Benutzerrolle, können Sie alle API-Typen außer Data Warehouse verwalten.
Voraussetzungen für den API-Zugriff
-
Zum Gewähren des Zugriffs wird ein API-Zugriffstokenmodell verwendet.
-
Die API-Token-Verwaltung wird von Data Infrastructure Insights -Benutzern mit der Administratorrolle durchgeführt.
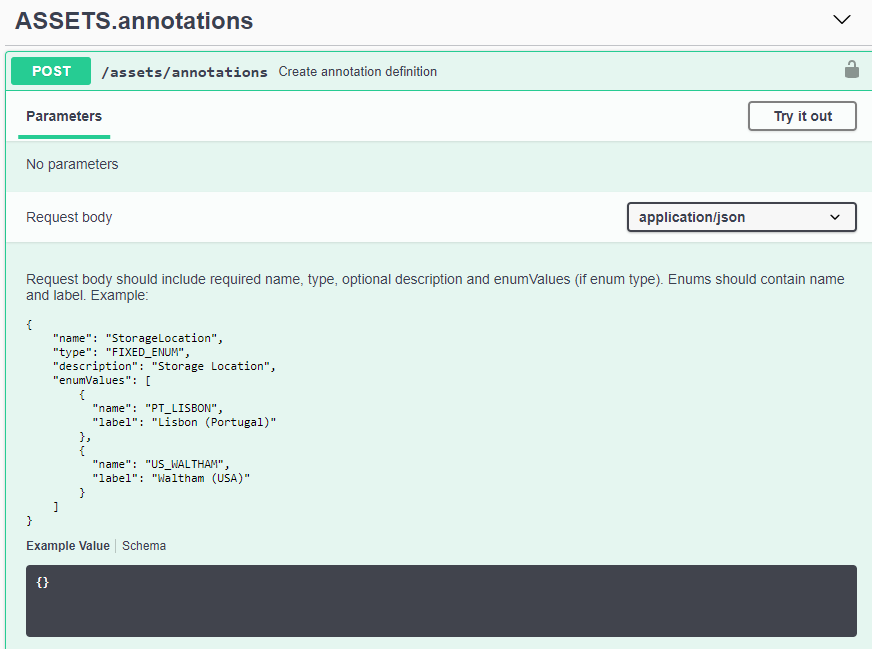
API-Dokumentation (Swagger)
Die neuesten API-Informationen finden Sie, indem Sie sich bei Data Infrastructure Insights anmelden und zu Admin > API-Zugriff navigieren. Klicken Sie auf den Link API-Dokumentation.

Die API-Dokumentation basiert auf Swagger und bietet eine kurze Beschreibung und Nutzungsinformationen zur API. Sie können sie in Ihrem Mandanten ausprobieren. Je nach Ihrer Benutzerrolle und/oder Data Infrastructure Insights -Edition können die für Sie verfügbaren API-Typen variieren.
API-Zugriffstoken
Bevor Sie die Data Infrastructure Insights API verwenden, müssen Sie ein oder mehrere API-Zugriffstoken erstellen. Zugriffstoken werden für bestimmte API-Typen verwendet und können Lese- und/oder Schreibberechtigungen erteilen. Sie können auch das Ablaufdatum für jedes Zugriffstoken festlegen. Alle APIs unter den angegebenen Typen sind für das Zugriffstoken gültig. Für jedes Token ist weder ein Benutzername noch ein Passwort erforderlich.
So erstellen Sie ein Zugriffstoken:
-
Klicken Sie auf Admin > API-Zugriff
-
Klicken Sie auf +API-Zugriffstoken
-
Geben Sie den Tokennamen ein
-
API-Typen auswählen
-
Geben Sie die für diesen API-Zugriff erteilten Berechtigungen an
-
Token-Ablauf festlegen
-

|
Ihr Token steht Ihnen während des Erstellungsprozesses nur zum Kopieren in die Zwischenablage und zum Speichern zur Verfügung. Token können nach ihrer Erstellung nicht abgerufen werden. Es wird daher dringend empfohlen, das Token zu kopieren und an einem sicheren Ort zu speichern. Sie werden aufgefordert, auf die Schaltfläche API-Zugriffstoken kopieren zu klicken, bevor Sie den Bildschirm zur Token-Erstellung schließen können. |
Sie können Token deaktivieren, aktivieren und widerrufen. Deaktivierte Token können aktiviert werden.
Token gewähren aus Kundensicht allgemeinen Zugriff auf APIs und verwalten den Zugriff auf APIs im Rahmen ihres eigenen Mandanten. Kundenadministratoren können diese Token ohne direkte Beteiligung des Back-End-Personals von Data Infrastructure Insights erteilen und widerrufen.
Die Anwendung erhält ein Zugriffstoken, nachdem ein Benutzer den Zugriff erfolgreich authentifiziert und autorisiert hat, und übergibt das Zugriffstoken dann als Anmeldeinformation, wenn sie die Ziel-API aufruft. Das übergebene Token informiert die API darüber, dass der Inhaber des Tokens autorisiert wurde, auf die API zuzugreifen und bestimmte Aktionen auszuführen, die durch den bei der Autorisierung gewährten Umfang festgelegt sind.
Der HTTP-Header, an den das Zugriffstoken übergeben wird, ist X-CloudInsights-ApiKey:.
Verwenden Sie beispielsweise Folgendes, um Speicherressourcen abzurufen:
curl https://<tenant_host_name>/rest/v1/assets/storages -H 'X-CloudInsights-ApiKey:<API_Access_Token>' Dabei ist _<API_Access_Token>_ das Token, das Sie während der Erstellung des API-Zugriffs gespeichert haben.
Auf den Swagger-Seiten finden Sie Beispiele speziell für die API, die Sie verwenden möchten.
API-Typ
Die Data Infrastructure Insights API ist kategoriebasiert und enthält derzeit die folgenden Typen:
-
Der Typ ASSETS enthält Asset-, Query- und Search-APIs. DII-Asset-Attribute und -Metriken werden manchmal als „odata“ bezeichnet. Die APIs hierfür sind typischerweise über /rest/v1/asset oder /rest/v1/query zugänglich. Siehe die API Swagger-Dokumentation für weitere Informationen.
-
Assets: Listen Sie Objekte der obersten Ebene auf und rufen Sie ein bestimmtes Objekt oder eine Objekthierarchie ab.
-
Abfrage: Rufen Sie Data Infrastructure Insights -Abfragen ab und verwalten Sie sie.
-
Importieren: Annotationen oder Anwendungen importieren und Objekten zuordnen
-
Suche: Suchen Sie ein bestimmtes Objekt, ohne die eindeutige ID oder den vollständigen Namen des Objekts zu kennen.
-
-
Der Typ DATA COLLECTION wird zum Abrufen und Verwalten von Datensammlern verwendet.
-
DATA INGESTION-Typ wird verwendet, um Ingestion-Daten und benutzerdefinierte Metriken abzurufen und zu verwalten, wie z. B. von Telegraf-Agenten. Diese werden manchmal als "Datalake"- oder "Lake"-Metriken bezeichnet. Die APIs dafür werden normalerweise über /rest/v1/lake aufgerufen. Siehe API Swagger-Dokumentation für weitere Informationen.
-
LOG INGESTION dient zum Abrufen und Verwalten von Protokolldaten
Im Laufe der Zeit werden möglicherweise weitere Typen und/oder APIs verfügbar. Die aktuellsten API-Informationen finden Sie im"API Swagger-Dokumentation" .
Beachten Sie, dass die API-Typen, auf die ein Benutzer Zugriff hat, auch von der "Benutzerrolle" abhängen, die er in jedem Data Infrastructure Insights Funktionssatz (Observability, Workload Security, Reporting) hat.
Bestandsdurchlauf
In diesem Abschnitt wird beschrieben, wie Sie eine Hierarchie von Data Infrastructure Insights -Objekten durchlaufen.
Objekte der obersten Ebene
Einzelne Objekte werden in Anfragen durch eine eindeutige URL (in JSON „self“ genannt) identifiziert und erfordern die Kenntnis des Objekttyps und der internen ID. Für einige der Objekte der obersten Ebene (Hosts, Speicher usw.) bietet die REST-API Zugriff auf die gesamte Sammlung.
Das allgemeine Format einer API-URL ist:
https://<tenant>/rest/v1/<type>/<object> Um beispielsweise alle Speicher von einem Mandanten namens _mysite.c01.cloudinsights.netapp.com_ abzurufen, lautet die Anforderungs-URL:
https://mysite.c01.cloudinsights.netapp.com/rest/v1/assets/storages
Untergeordnete Elemente und zugehörige Objekte
Objekte der obersten Ebene, wie z. B. Speicher, können zum Durchlaufen anderer untergeordneter und verwandter Objekte verwendet werden. Um beispielsweise alle Datenträger für einen bestimmten Speicher abzurufen, verketten Sie die Speicher-URL „self“ mit „/disks“, zum Beispiel:
https://<tenant>/rest/v1/assets/storages/4537/disks
Erweitert
Viele API-Befehle unterstützen den Parameter expand, der zusätzliche Details zum Objekt oder URLs für verwandte Objekte bereitstellt.
Der einzige gemeinsame Erweiterungsparameter ist expands. Die Antwort enthält eine Liste aller verfügbaren spezifischen Erweiterungen für das Objekt.
Wenn Sie beispielsweise Folgendes anfordern:
https://<tenant>/rest/v1/assets/storages/2782?expand=_expands Die API gibt alle verfügbaren Erweiterungen für das Objekt wie folgt zurück:
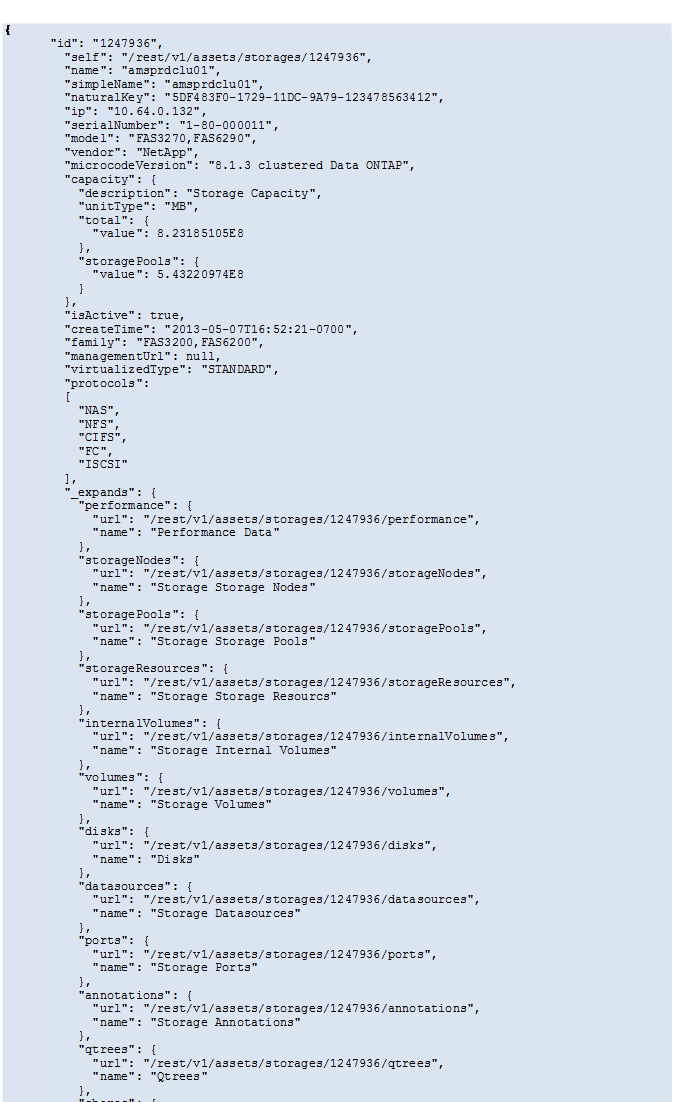
Jede Erweiterung enthält Daten, eine URL oder beides. Der Expand-Parameter unterstützt mehrere und verschachtelte Attribute, zum Beispiel:
https://<tenant>/rest/v1/assets/storages/2782?expand=performance,storageResources.storage Mit „Erweitern“ können Sie viele verwandte Daten in einer Antwort einbringen. NetApp empfiehlt, nicht zu viele Informationen auf einmal anzufordern, da dies zu Leistungseinbußen führen kann.
Um dies zu verhindern, können Anfragen für Sammlungen der obersten Ebene nicht erweitert werden. Sie können beispielsweise nicht für alle Speicherobjekte gleichzeitig erweiterte Daten anfordern. Clients müssen die Objektliste abrufen und dann bestimmte Objekte zum Erweitern auswählen.
Leistungsdaten
Leistungsdaten werden über viele Geräte hinweg als separate Stichproben erfasst. Jede Stunde (Standardeinstellung) aggregiert und fasst Data Infrastructure Insights Leistungsbeispiele zusammen.
Die API ermöglicht den Zugriff sowohl auf die Beispiele als auch auf die zusammengefassten Daten. Für ein Objekt mit Leistungsdaten ist eine Leistungszusammenfassung als expand=performance verfügbar. Zeitreihen zur Leistungshistorie sind über verschachtelte expand=performance.history verfügbar.
Beispiele für Leistungsdatenobjekte sind:
-
Speicherleistung
-
Speicherpoolleistung
-
PortPerformance
-
DiskPerformance
Eine Leistungsmetrik hat eine Beschreibung und einen Typ und enthält eine Sammlung von Leistungszusammenfassungen. Zum Beispiel Latenz, Verkehr und Rate.
Eine Leistungszusammenfassung enthält eine Beschreibung, eine Einheit, eine Beispielstartzeit, eine Beispielendzeit und eine Sammlung zusammengefasster Werte (aktuell, Min., Max., Durchschnitt usw.), die aus einem einzelnen Leistungsindikator über einen Zeitraum (1 Stunde, 24 Stunden, 3 Tage usw.) berechnet wurden.
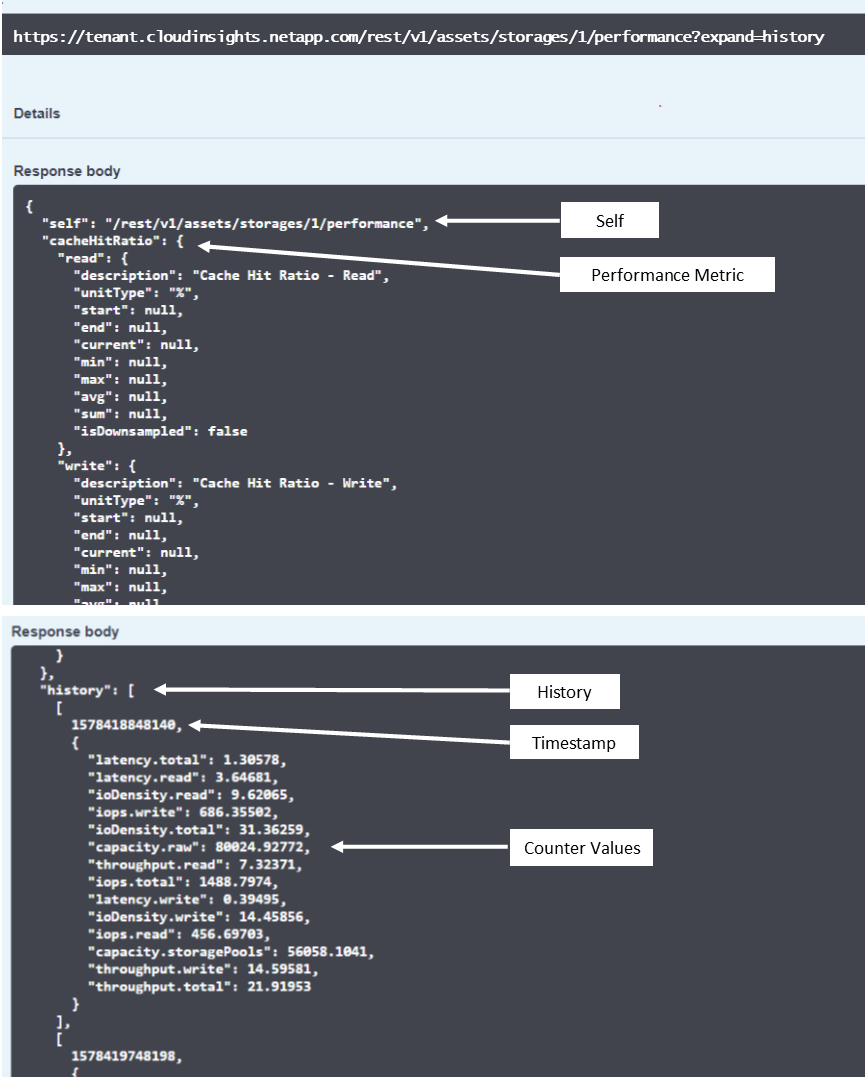
Das resultierende Leistungsdatenwörterbuch enthält die folgenden Schlüssel:
-
„self“ ist die eindeutige URL des Objekts
-
„History“ ist die Liste der Paare aus Zeitstempel und Zuordnung der Zählerwerte
-
Jeder andere Wörterbuchschlüssel („diskThroughput“ usw.) ist der Name einer Leistungsmetrik.
Jeder Leistungsdatenobjekttyp verfügt über einen einzigartigen Satz von Leistungsmetriken. Beispielsweise unterstützt das Leistungsobjekt „Virtuelle Maschine“ „diskThroughput“ als Leistungsmetrik. Jede unterstützte Leistungsmetrik gehört zu einer bestimmten „Leistungskategorie“, die im Metrikwörterbuch dargestellt wird. Data Infrastructure Insights unterstützt mehrere Leistungsmetriktypen, die weiter unten in diesem Dokument aufgeführt sind. Jedes Leistungsmetrikwörterbuch verfügt außerdem über das Feld „Beschreibung“, das eine für Menschen lesbare Beschreibung dieser Leistungsmetrik und eine Reihe von Leistungszusammenfassungszählereinträgen enthält.
Der Leistungszusammenfassungszähler ist die Zusammenfassung der Leistungszähler. Es werden typische aggregierte Werte wie Min., Max. und Durchschnitt für einen Zähler sowie der zuletzt beobachtete Wert, der Zeitbereich für zusammengefasste Daten, der Einheitentyp für den Zähler und Schwellenwerte für Daten angezeigt. Nur Schwellenwerte sind optional; die restlichen Attribute sind obligatorisch.
Für die folgenden Zählertypen sind Leistungszusammenfassungen verfügbar:
-
Lesen – Zusammenfassung für Lesevorgänge
-
Schreiben – Zusammenfassung für Schreibvorgänge
-
Gesamt – Zusammenfassung aller Vorgänge. Es kann höher sein als die einfache Summe aus Lesen und Schreiben und es können auch andere Operationen enthalten sein.
-
Gesamtmaximum – Zusammenfassung aller Vorgänge. Dies ist der maximale Gesamtwert im angegebenen Zeitraum.
Objektleistungsmetriken
Die API kann detaillierte Metriken für Objekte auf Ihrem Mandanten zurückgeben, zum Beispiel:
-
Speicherleistungsmetriken wie IOPS (Anzahl der Eingabe-/Ausgabeanforderungen pro Sekunde), Latenz oder Durchsatz.
-
Switch-Leistungsmetriken, wie etwa Verkehrsauslastung, BB Credit Zero-Daten oder Portfehler.
Siehe die"API Swagger-Dokumentation" für Informationen zu Metriken für jeden Objekttyp.
Leistungsverlaufsdaten
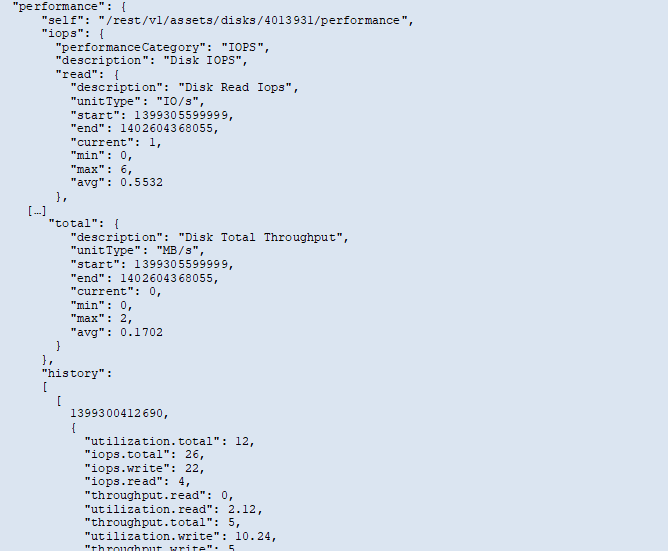
Verlaufsdaten werden in Leistungsdaten als Liste von Zeitstempel- und Zählerkartenpaaren dargestellt.
Die Benennung der Verlaufszähler basiert auf dem Namen des Leistungsmetrikobjekts. Beispielsweise unterstützt das Leistungsobjekt der virtuellen Maschine „diskThroughput“, sodass die Verlaufskarte Schlüssel mit den Namen „diskThroughput.read“, „diskThroughput.write“ und „diskThroughput.total“ enthält.
|
|
Der Zeitstempel liegt im UNIX-Zeitformat vor. |
Nachfolgend sehen Sie ein Beispiel für die Leistungsdaten einer Festplatte im JSON-Format:
Objekte mit Kapazitätsattributen
Objekte mit Kapazitätsattributen verwenden grundlegende Datentypen und das CapacityItem zur Darstellung.
KapazitätArtikel
CapacityItem ist eine einzelne logische Kapazitätseinheit. Es verfügt über „Wert“ und „hoher Schwellenwert“ in Einheiten, die durch sein übergeordnetes Objekt definiert sind. Es unterstützt auch eine optionale Aufschlüsselungskarte, die erklärt, wie der Kapazitätswert aufgebaut ist. Beispielsweise wäre die Gesamtkapazität eines 100-TB-Speicherpools ein CapacityItem mit dem Wert 100. Die Aufschlüsselung kann ergeben, dass 60 TB für „Daten“ und 40 TB für „Schnappschüsse“ vorgesehen sind.
Hinweis: „highThreshold“ stellt systemdefinierte Schwellenwerte für die entsprechenden Metriken dar, die ein Client verwenden kann, um Warnungen oder visuelle Hinweise auf Werte zu generieren, die außerhalb der akzeptablen konfigurierten Bereiche liegen.
Im Folgenden wird die Kapazität für StoragePools mit mehreren Kapazitätszählern angezeigt:

Verwenden der Suche zum Nachschlagen von Objekten
Die Such-API ist ein einfacher Einstiegspunkt in das System. Der einzige Eingabeparameter für die API ist eine Zeichenfolge in freier Form und das resultierende JSON enthält eine kategorisierte Ergebnisliste. Typen sind verschiedene Asset-Typen aus dem Inventar, wie Speicher, Hosts, Datenspeicher usw. Jeder Typ würde eine Liste von Objekten des Typs enthalten, die den Suchkriterien entsprechen.
Data Infrastructure Insights ist eine erweiterbare (weit offene) Lösung, die Integrationen mit Orchestrierungs-, Geschäftsverwaltungs-, Änderungskontroll- und Ticketsystemen von Drittanbietern sowie benutzerdefinierte CMDB-Integrationen ermöglicht.
Die RESTful-API von Cloud Insight ist ein primärer Integrationspunkt, der eine einfache und effektive Datenübertragung ermöglicht und Benutzern einen nahtlosen Zugriff auf ihre Daten ermöglicht.
Deaktivieren oder Widerrufen eines API-Tokens
Um ein API-Token vorübergehend zu deaktivieren, klicken Sie auf der API-Token-Listenseite auf das Menü mit den drei Punkten für die API und wählen Sie Deaktivieren. Sie können das Token jederzeit wieder aktivieren, indem Sie im selben Menü „Aktivieren“ auswählen.
Um ein API-Token dauerhaft zu entfernen, wählen Sie im Menü „Widerrufen“ aus. Sie können ein widerrufenes Token nicht erneut aktivieren. Sie müssen ein neues Token erstellen.

Rotieren abgelaufener API-Zugriffstoken
API-Zugriffstoken haben ein Ablaufdatum. Wenn ein API-Zugriffstoken abläuft, müssen Benutzer ein neues Token (vom Typ Data Ingestion mit Lese-/Schreibberechtigungen) generieren und Telegraf neu konfigurieren, um das neu generierte Token anstelle des abgelaufenen Tokens zu verwenden. Die folgenden Schritte beschreiben die Vorgehensweise im Detail.
Kubernetes
Beachten Sie, dass diese Befehle den Standardnamespace „netapp-monitoring“ verwenden. Wenn Sie Ihren eigenen Namespace festgelegt haben, ersetzen Sie diesen Namespace in diesen und allen nachfolgenden Befehlen und Dateien.
Hinweis: Wenn Sie den neuesten NetApp Kubernetes Monitoring Operator installiert haben und ein erneuerbares API-Zugriffstoken verwenden, werden ablaufende Token automatisch durch neue/aktualisierte API-Zugriffstoken ersetzt. Es ist nicht erforderlich, die unten aufgeführten manuellen Schritte auszuführen.
-
Erstellen Sie ein neues API-Token.
-
Befolgen Sie die Schritte für"Manuelles Upgrade" und wählen Sie das neue API-Token aus.
Hinweis: Kunden, die ihren NetApp Kubernetes Monitoring Operator mit einem Konfigurationsverwaltungstool wie Kustomize verwalten, können dieselben Schritte ausführen, um einen aktualisierten Satz von YAMLs zu generieren und herunterzuladen, um ihn in ihr Repository zu übertragen.
RHEL/CentOS und Debian/Ubuntu
-
Bearbeiten Sie die Telegraf-Konfigurationsdateien und ersetzen Sie alle Instanzen des alten API-Tokens durch das neue API-Token.
sudo sed -i.bkup ‘s/<OLD_API_TOKEN>/<NEW_API_TOKEN>/g’ /etc/telegraf/telegraf.d/*.conf * Starten Sie Telegraf neu.
sudo systemctl restart telegraf
Windows
-
Ersetzen Sie für jede Telegraf-Konfigurationsdatei in C:\Programme\telegraf\telegraf.d alle Instanzen des alten API-Tokens durch das neue API-Token.
cp <plugin>.conf <plugin>.conf.bkup (Get-Content <plugin>.conf).Replace(‘<OLD_API_TOKEN>’, ‘<NEW_API_TOKEN>’) | Set-Content <plugin>.conf
-
Starten Sie Telegraf neu.
Stop-Service telegraf Start-Service telegraf