

Daten von lokalen ONTAP Clustern auf Amazon S3 in NetApp Cloud Tiering verschieben
 Änderungen vorschlagen
Änderungen vorschlagen
Geben Sie Speicherplatz auf Ihren lokalen ONTAP Clustern frei, indem Sie inaktive Daten in NetApp Cloud Tiering auf Amazon S3 auslagern.
Schnellstart
Mit den folgenden Schritten können Sie schnell loslegen. Details zu den einzelnen Schritten finden Sie in den folgenden Abschnitten dieses Themas.
 Identifizieren Sie die Konfigurationsmethode, die Sie verwenden werden
Identifizieren Sie die Konfigurationsmethode, die Sie verwenden werdenWählen Sie, ob Sie Ihren lokalen ONTAP -Cluster direkt über das öffentliche Internet mit AWS S3 verbinden oder ob Sie ein VPN oder AWS Direct Connect verwenden und den Datenverkehr über eine private VPC-Endpunktschnittstelle zu AWS S3 leiten.
 Bereiten Sie Ihren Konsolenagenten vor
Bereiten Sie Ihren Konsolenagenten vorWenn Sie den Konsolenagenten bereits in Ihrem AWS VPC oder vor Ort bereitgestellt haben, sind Sie startklar. Wenn nicht, müssen Sie den Agenten erstellen, um ONTAP -Daten in den AWS S3-Speicher zu verschieben. Sie müssen auch die Netzwerkeinstellungen für den Agenten anpassen, damit er eine Verbindung zu AWS S3 herstellen kann.
 Vorbereiten Ihres lokalen ONTAP Clusters
Vorbereiten Ihres lokalen ONTAP ClustersErmitteln Sie Ihren ONTAP Cluster in der NetApp Console, überprüfen Sie, ob der Cluster die Mindestanforderungen erfüllt, und passen Sie die Netzwerkeinstellungen an, damit der Cluster eine Verbindung zu AWS S3 herstellen kann.
 Bereiten Sie Amazon S3 als Ihr Tiering-Ziel vor
Bereiten Sie Amazon S3 als Ihr Tiering-Ziel vorRichten Sie Berechtigungen für den Agenten ein, um den S3-Bucket zu erstellen und zu verwalten. Sie müssen außerdem Berechtigungen für den lokalen ONTAP Cluster einrichten, damit dieser Daten aus dem S3-Bucket lesen und schreiben kann.
 Aktivieren Sie Cloud Tiering auf dem System
Aktivieren Sie Cloud Tiering auf dem SystemWählen Sie ein lokales System aus, wählen Sie Aktivieren für den Cloud-Tiering-Dienst und folgen Sie den Anweisungen, um die Daten auf Amazon S3 zu verschieben.
 Einrichten der Lizenzierung
Einrichten der LizenzierungNach Ablauf Ihrer kostenlosen Testversion bezahlen Sie für Cloud Tiering über ein Pay-as-you-go-Abonnement, eine ONTAP Cloud Tiering BYOL-Lizenz oder eine Kombination aus beidem:
-
Um sich über den AWS Marketplace anzumelden, "zum Marketplace-Angebot" , wählen Sie Abonnieren und folgen Sie dann den Anweisungen.
-
Um mit einer Cloud Tiering BYOL-Lizenz zu bezahlen, kontaktieren Sie uns, und dann"Fügen Sie es der NetApp Console hinzu" .
Netzpläne für Anschlussmöglichkeiten
Es gibt zwei Verbindungsmethoden, die Sie beim Konfigurieren des Tierings von lokalen ONTAP -Systemen zu AWS S3 verwenden können.
-
Öffentliche Verbindung – Verbinden Sie das ONTAP -System über einen öffentlichen S3-Endpunkt direkt mit AWS S3.
-
Private Verbindung – Verwenden Sie ein VPN oder AWS Direct Connect und leiten Sie den Datenverkehr über eine VPC-Endpunktschnittstelle, die eine private IP-Adresse verwendet.
Das folgende Diagramm zeigt die Methode öffentliche Verbindung und die Verbindungen, die Sie zwischen den Komponenten vorbereiten müssen. Sie können den Konsolenagenten verwenden, den Sie vor Ort installiert haben, oder einen Agenten, den Sie im AWS VPC bereitgestellt haben.
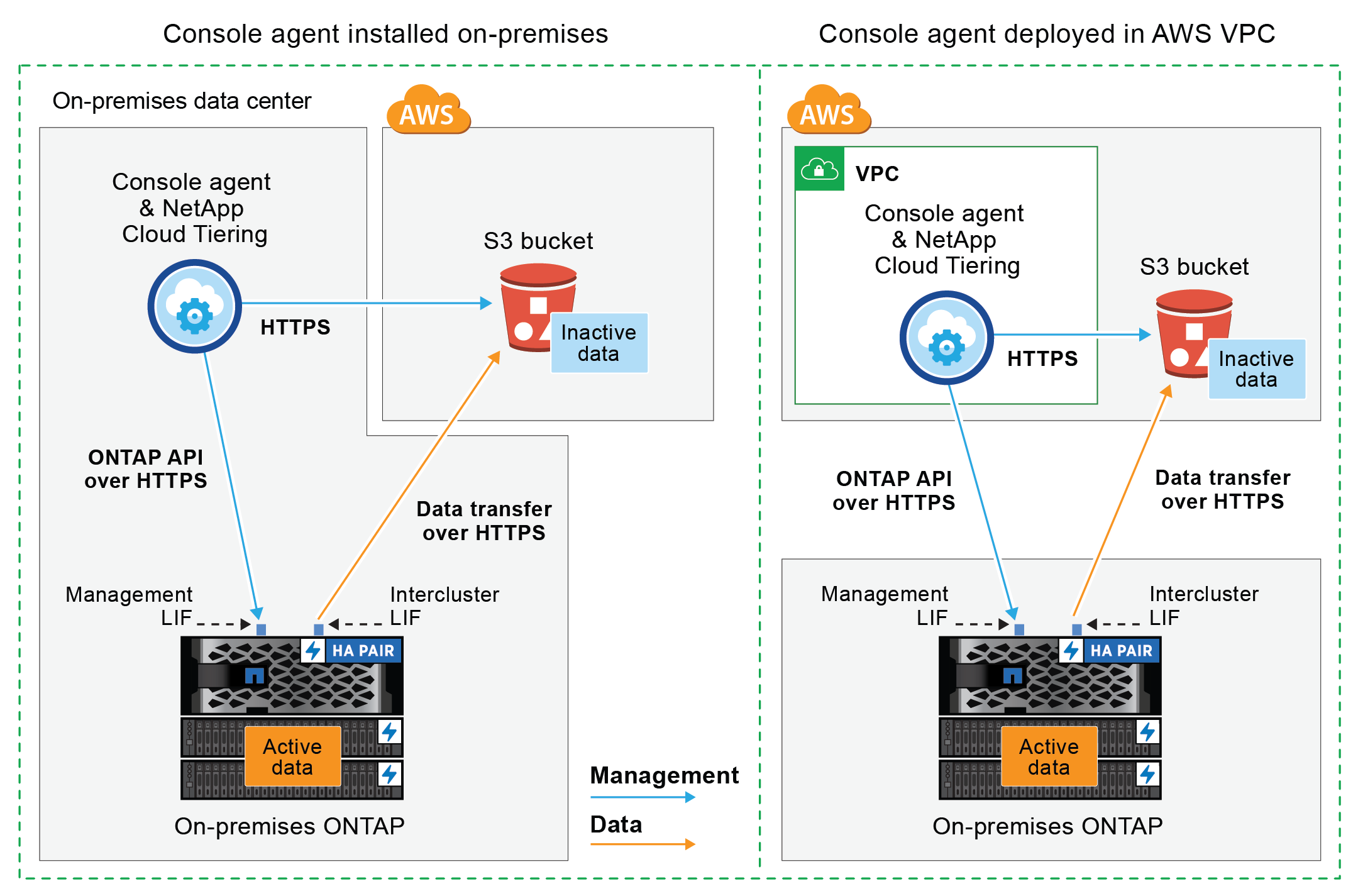
Das folgende Diagramm zeigt die Methode private Verbindung und die Verbindungen, die Sie zwischen den Komponenten vorbereiten müssen. Sie können den Konsolenagenten verwenden, den Sie vor Ort installiert haben, oder einen Agenten, den Sie im AWS VPC bereitgestellt haben.
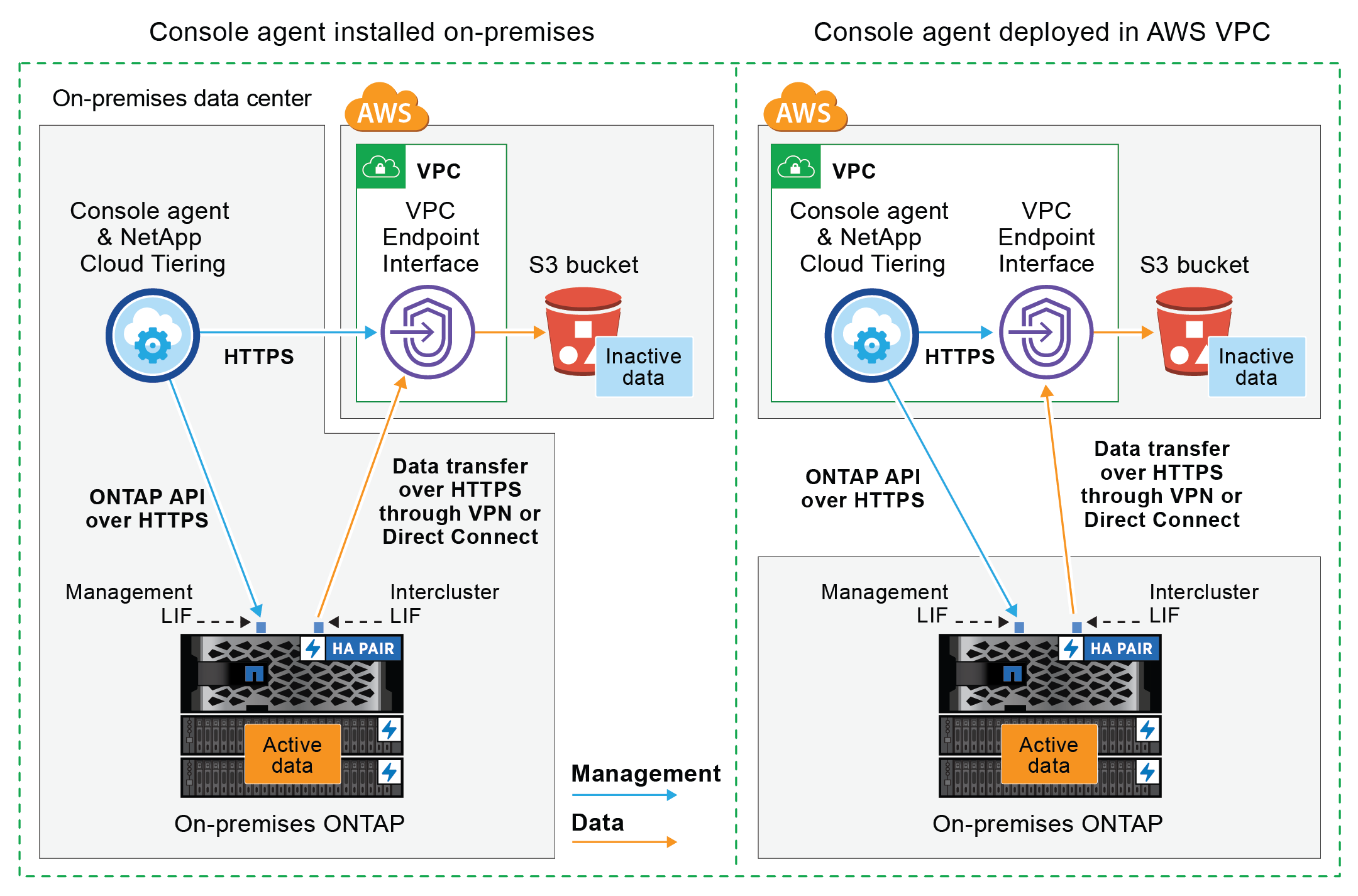

|
Die Kommunikation zwischen einem Agenten und S3 dient nur der Einrichtung des Objektspeichers. |
Vorbereiten Ihres Konsolenagenten
Der Agent aktiviert Tiering-Funktionen über die NetApp Console. Zum Tiering Ihrer inaktiven ONTAP Daten ist ein Agent erforderlich.
Agenten erstellen oder wechseln
Wenn Sie bereits einen Agenten in Ihrem AWS VPC oder vor Ort bereitgestellt haben, sind Sie startklar. Wenn nicht, müssen Sie an einem dieser Standorte einen Agenten erstellen, um ONTAP -Daten in den AWS S3-Speicher zu verschieben. Sie können keinen Agenten verwenden, der bei einem anderen Cloud-Anbieter bereitgestellt wird.
Netzwerkanforderungen für Agenten
-
Stellen Sie sicher, dass das Netzwerk, in dem der Agent installiert ist, die folgenden Verbindungen ermöglicht:
-
Eine HTTPS-Verbindung über Port 443 zum Cloud Tiering-Dienst und zu Ihrem S3-Objektspeicher("siehe Liste der Endpunkte" )
-
Eine HTTPS-Verbindung über Port 443 zu Ihrem ONTAP Cluster-Management-LIF
-
-
"Stellen Sie sicher, dass der Agent über die Berechtigung zur Verwaltung des S3-Buckets verfügt"
-
Wenn Sie über eine Direct Connect- oder VPN-Verbindung von Ihrem ONTAP Cluster zum VPC verfügen und die Kommunikation zwischen dem Agenten und S3 in Ihrem internen AWS-Netzwerk bleiben soll (eine private Verbindung), müssen Sie eine VPC-Endpunktschnittstelle zu S3 aktivieren.Erfahren Sie, wie Sie eine VPC-Endpunktschnittstelle einrichten.
Bereiten Sie Ihren ONTAP Cluster vor
Ihre ONTAP -Cluster müssen beim Tiering von Daten auf Amazon S3 die folgenden Anforderungen erfüllen.
ONTAP Anforderungen
- Unterstützte ONTAP -Plattformen
-
-
Bei Verwendung von ONTAP 9.8 und höher: Sie können Daten von AFF -Systemen oder FAS Systemen mit reinen SSD- oder reinen HDD-Aggregaten stufen.
-
Bei Verwendung von ONTAP 9.7 und früher: Sie können Daten von AFF -Systemen oder FAS Systemen mit reinen SSD-Aggregaten stufen.
-
- Unterstützte ONTAP-Versionen
-
-
ONTAP 9.2 oder höher
-
ONTAP 9.7 oder höher ist erforderlich, wenn Sie eine AWS PrivateLink-Verbindung zum Objektspeicher verwenden möchten
-
- Unterstützte Volumes und Aggregate
-
Die Gesamtzahl der Volumes, die Cloud Tiering in Tiering einteilen kann, ist möglicherweise geringer als die Anzahl der Volumes auf Ihrem ONTAP System. Das liegt daran, dass Volumes aus einigen Aggregaten nicht gestaffelt werden können. Weitere Informationen finden Sie in der ONTAP -Dokumentation. "Funktionen oder Features, die von FabricPool nicht unterstützt werden" .
|
|
Cloud Tiering unterstützt FlexGroup -Volumes ab ONTAP 9.5. Die Einrichtung funktioniert genauso wie bei jedem anderen Volume. |
Cluster-Netzwerkanforderungen
-
Der Cluster erfordert eine eingehende HTTPS-Verbindung vom Konsolenagenten zum Clusterverwaltungs-LIF.
Eine Verbindung zwischen Cluster und Cloud Tiering ist nicht erforderlich.
-
Auf jedem ONTAP Knoten, der die Volumes hostet, die Sie in ein Tiering einteilen möchten, ist ein Intercluster-LIF erforderlich. Diese Cluster-übergreifenden LIFs müssen auf den Objektspeicher zugreifen können.
Der Cluster initiiert eine ausgehende HTTPS-Verbindung über Port 443 von den Intercluster-LIFs zum Amazon S3-Speicher für Tiering-Vorgänge. ONTAP liest und schreibt Daten in den und aus dem Objektspeicher – der Objektspeicher wird nie initiiert, er antwortet nur.
-
Die Intercluster-LIFs müssen mit dem IPspace verknüpft sein, den ONTAP für die Verbindung mit dem Objektspeicher verwenden soll. "Erfahren Sie mehr über IPspaces" .
Wenn Sie Cloud Tiering einrichten, werden Sie nach dem zu verwendenden IPspace gefragt. Sie sollten den IPspace auswählen, mit dem diese LIFs verknüpft sind. Dies kann der „Standard“-IP-Bereich oder ein benutzerdefinierter IP-Bereich sein, den Sie erstellt haben.
Wenn Sie einen anderen IP-Bereich als „Standard“ verwenden, müssen Sie möglicherweise eine statische Route erstellen, um Zugriff auf den Objektspeicher zu erhalten.
Alle Intercluster-LIFs innerhalb des IPspace müssen Zugriff auf den Objektspeicher haben. Wenn Sie dies für den aktuellen IPspace nicht konfigurieren können, müssen Sie einen dedizierten IPspace erstellen, in dem alle LIFs zwischen Clustern Zugriff auf den Objektspeicher haben.
-
Wenn Sie für die S3-Verbindung einen privaten VPC-Schnittstellenendpunkt in AWS verwenden, müssen Sie das S3-Endpunktzertifikat in den ONTAP Cluster laden, damit HTTPS/443 verwendet werden kann.Erfahren Sie, wie Sie eine VPC-Endpunktschnittstelle einrichten und das S3-Zertifikat laden.
Entdecken Sie Ihren ONTAP Cluster in der NetApp Console
Sie müssen Ihren lokalen ONTAP Cluster in der NetApp Console ermitteln, bevor Sie mit der Tiering-Verteilung kalter Daten in den Objektspeicher beginnen können. Sie müssen die IP-Adresse der Clusterverwaltung und das Kennwort für das Administratorbenutzerkonto kennen, um den Cluster hinzuzufügen.
Vorbereiten Ihrer AWS-Umgebung
Wenn Sie die Datenschichtung für einen neuen Cluster einrichten, werden Sie gefragt, ob der Dienst einen S3-Bucket erstellen soll oder ob Sie einen vorhandenen S3-Bucket im AWS-Konto auswählen möchten, in dem der Agent eingerichtet ist. Das AWS-Konto muss über Berechtigungen und einen Zugriffsschlüssel verfügen, den Sie in Cloud Tiering eingeben können. Der ONTAP Cluster verwendet den Zugriffsschlüssel, um Daten in und aus S3 zu schichten.
Standardmäßig erstellt Cloud Tiering den Bucket für Sie. Wenn Sie Ihren eigenen Bucket verwenden möchten, können Sie einen erstellen, bevor Sie den Tiering-Aktivierungsassistenten starten, und diesen Bucket dann im Assistenten auswählen. "Erfahren Sie, wie Sie S3-Buckets über die NetApp Console erstellen." . Der Bucket darf ausschließlich zum Speichern inaktiver Daten aus Ihren Volumes verwendet werden – er kann nicht für andere Zwecke verwendet werden. Der S3-Bucket muss sich in einem"Region, die Cloud Tiering unterstützt" .
|
|
Wenn Sie Cloud Tiering so konfigurieren möchten, dass eine kostengünstigere Speicherklasse verwendet wird, in die Ihre mehrstufigen Daten nach einer bestimmten Anzahl von Tagen verschoben werden, dürfen Sie beim Einrichten des Buckets in Ihrem AWS-Konto keine Lebenszyklusregeln auswählen. Cloud Tiering verwaltet die Lebenszyklusübergänge. |
S3-Berechtigungen einrichten
Sie müssen zwei Berechtigungssätze konfigurieren:
-
Berechtigungen für den Agenten, damit er den S3-Bucket erstellen und verwalten kann.
-
Berechtigungen für den lokalen ONTAP Cluster, damit dieser Daten aus dem S3-Bucket lesen und schreiben kann.
-
Berechtigungen für Konsolenagenten:
-
Bestätigen Sie, dass "diese S3-Berechtigungen" sind Teil der IAM-Rolle, die dem Agenten Berechtigungen erteilt. Sie sollten standardmäßig enthalten sein, als Sie den Agenten zum ersten Mal bereitgestellt haben. Wenn nicht, müssen Sie alle fehlenden Berechtigungen hinzufügen. Siehe die "AWS-Dokumentation: Bearbeiten von IAM-Richtlinien" Anweisungen hierzu finden Sie unter.
-
Der von Cloud Tiering erstellte Standard-Bucket hat das Präfix „Fabric-Pool“. Wenn Sie für Ihren Bucket ein anderes Präfix verwenden möchten, müssen Sie die Berechtigungen mit dem gewünschten Namen anpassen. In den S3-Berechtigungen sehen Sie eine Zeile
"Resource": ["arn:aws:s3:::fabric-pool*"]. Sie müssen „Fabric-Pool“ in das Präfix ändern, das Sie verwenden möchten. Wenn Sie beispielsweise "tiering-1" als Präfix für Ihre Buckets verwenden möchten, ändern Sie diese Zeile in"Resource": ["arn:aws:s3:::tiering-1*"].Wenn Sie für Buckets, die Sie für zusätzliche Cluster in derselben NetApp Console -Organisation verwenden, ein anderes Präfix verwenden möchten, können Sie eine weitere Zeile mit dem Präfix für andere Buckets hinzufügen. Beispiel:
"Resource": ["arn:aws:s3:::tiering-1*"]
"Resource": ["arn:aws:s3:::tiering-2*"]
Wenn Sie Ihren eigenen Bucket erstellen und kein Standardpräfix verwenden, sollten Sie diese Zeile ändern in
"Resource": ["arn:aws:s3:::*"]damit jeder Eimer erkannt wird. Allerdings werden dadurch möglicherweise alle Ihre Buckets freigegeben, anstatt nur die, die Sie für die Speicherung inaktiver Daten aus Ihren Volumes vorgesehen haben. -
-
Clusterberechtigungen:
-
Wenn Sie den Dienst aktivieren, werden Sie vom Tiering-Assistenten aufgefordert, einen Zugriffsschlüssel und einen geheimen Schlüssel einzugeben. Diese Anmeldeinformationen werden an den ONTAP Cluster weitergegeben, damit ONTAP Daten in den S3-Bucket einstufen kann. Dazu müssen Sie einen IAM-Benutzer mit den folgenden Berechtigungen erstellen:
"s3:ListAllMyBuckets", "s3:ListBucket", "s3:GetBucketLocation", "s3:GetObject", "s3:PutObject", "s3:DeleteObject"
-
-
Erstellen oder suchen Sie den Zugriffsschlüssel.
Cloud Tiering gibt den Zugriffsschlüssel an den ONTAP Cluster weiter. Die Anmeldeinformationen werden nicht im Cloud Tiering-Dienst gespeichert.
Konfigurieren Sie Ihr System für eine private Verbindung mithilfe einer VPC-Endpunktschnittstelle
Wenn Sie eine öffentliche Standard-Internetverbindung verwenden möchten, werden alle Berechtigungen vom Agenten festgelegt, und Sie müssen nichts weiter tun. Diese Art der Verbindung wird imerstes Diagramm oben .
Wenn Sie eine sicherere Verbindung über das Internet von Ihrem lokalen Rechenzentrum zum VPC wünschen, können Sie im Tiering-Aktivierungsassistenten eine AWS PrivateLink-Verbindung auswählen. Dies ist erforderlich, wenn Sie ein VPN oder AWS Direct Connect verwenden möchten, um Ihr lokales System über eine VPC-Endpunktschnittstelle zu verbinden, die eine private IP-Adresse verwendet. Diese Art der Verbindung wird in derzweites Diagramm oben .
-
Erstellen Sie mithilfe der Amazon VPC-Konsole oder der Befehlszeile eine Schnittstellenendpunktkonfiguration. "Details zur Verwendung von AWS PrivateLink für Amazon S3 anzeigen" .
-
Ändern Sie die Sicherheitsgruppenkonfiguration, die dem Agenten zugeordnet ist. Sie müssen die Richtlinie von "Vollzugriff" auf "Benutzerdefiniert" ändern undFügen Sie die erforderlichen S3-Agent-Berechtigungen hinzu wie bereits gezeigt.
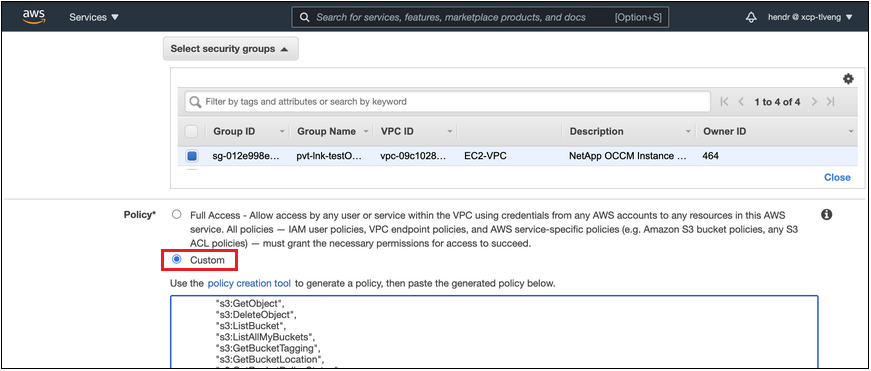
Wenn Sie Port 80 (HTTP) für die Kommunikation mit dem privaten Endpunkt verwenden, sind Sie fertig. Sie können Cloud Tiering jetzt auf dem Cluster aktivieren.
Wenn Sie Port 443 (HTTPS) für die Kommunikation mit dem privaten Endpunkt verwenden, müssen Sie das Zertifikat vom VPC S3-Endpunkt kopieren und es Ihrem ONTAP Cluster hinzufügen, wie in den nächsten 4 Schritten gezeigt.
-
Rufen Sie den DNS-Namen des Endpunkts von der AWS-Konsole ab.
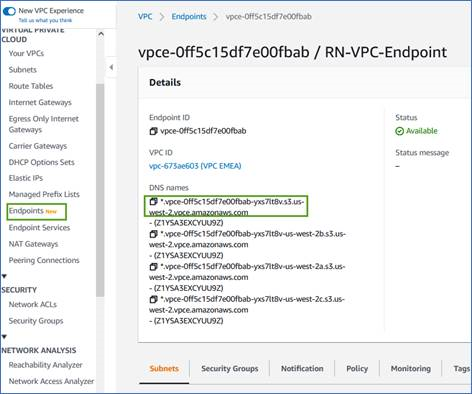
-
Besorgen Sie sich das Zertifikat vom VPC S3-Endpunkt. Sie tun dies, indem Sie "Anmelden bei der VM, die den Agenten hostet" und führen Sie den folgenden Befehl aus. Wenn Sie den DNS-Namen des Endpunkts eingeben, fügen Sie am Anfang „bucket“ hinzu und ersetzen Sie das „*“:
[ec2-user@ip-10-160-4-68 ~]$ openssl s_client -connect bucket.vpce-0ff5c15df7e00fbab-yxs7lt8v.s3.us-west-2.vpce.amazonaws.com:443 -showcerts -
Kopieren Sie aus der Ausgabe dieses Befehls die Daten für das S3-Zertifikat (alle Daten zwischen und einschließlich der Tags BEGIN / END CERTIFICATE):
Certificate chain 0 s:/CN=s3.us-west-2.amazonaws.com` i:/C=US/O=Amazon/OU=Server CA 1B/CN=Amazon -----BEGIN CERTIFICATE----- MIIM6zCCC9OgAwIBAgIQA7MGJ4FaDBR8uL0KR3oltTANBgkqhkiG9w0BAQsFADBG … … GqvbOz/oO2NWLLFCqI+xmkLcMiPrZy+/6Af+HH2mLCM4EsI2b+IpBmPkriWnnxo= -----END CERTIFICATE----- -
Melden Sie sich bei der CLI des ONTAP Clusters an und wenden Sie das kopierte Zertifikat mit dem folgenden Befehl an (ersetzen Sie den Namen Ihrer eigenen Speicher-VM):
cluster1::> security certificate install -vserver <svm_name> -type server-ca Please enter Certificate: Press <Enter> when done
Inaktive Daten von Ihrem ersten Cluster auf Amazon S3 übertragen
Nachdem Sie Ihre AWS-Umgebung vorbereitet haben, beginnen Sie mit der Tiering-Verteilung inaktiver Daten aus Ihrem ersten Cluster.
-
Ein AWS-Zugriffsschlüssel für einen IAM-Benutzer, der über die erforderlichen S3-Berechtigungen verfügt.
-
Wählen Sie das lokale ONTAP -System aus.
-
Klicken Sie im rechten Bereich auf Aktivieren für Cloud Tiering.
Wenn das Amazon S3-Tiering-Ziel als System auf der Seite „Systeme“ vorhanden ist, können Sie den Cluster auf das System ziehen, um den Setup-Assistenten zu starten.
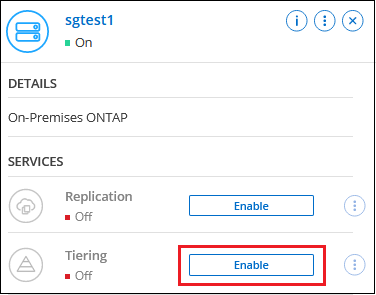
-
Name des Objektspeichers definieren: Geben Sie einen Namen für diesen Objektspeicher ein. Es muss sich von allen anderen Objektspeichern unterscheiden, die Sie möglicherweise mit Aggregaten auf diesem Cluster verwenden.
-
Anbieter auswählen: Wählen Sie Amazon Web Services und dann Weiter.
-
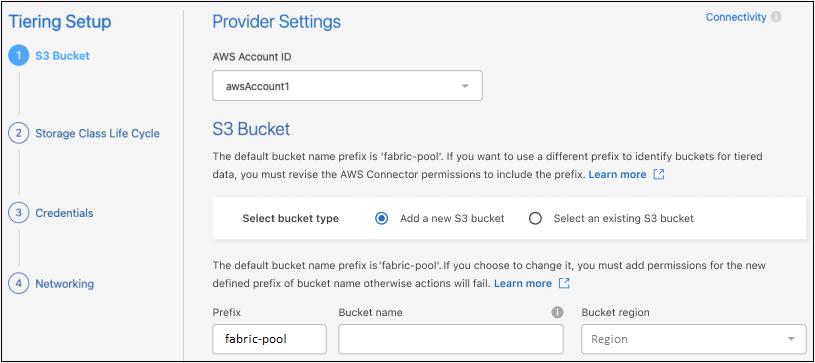
Füllen Sie die Abschnitte auf der Seite Tiering-Setup aus:
-
S3-Bucket: Fügen Sie einen neuen S3-Bucket hinzu oder wählen Sie einen vorhandenen S3-Bucket aus, wählen Sie die Bucket-Region aus und wählen Sie Weiter.
Wenn Sie einen lokalen Agenten verwenden, müssen Sie die AWS-Konto-ID eingeben, die Zugriff auf den vorhandenen S3-Bucket oder den neu zu erstellenden S3-Bucket bietet.
Das Präfix fabric-pool wird standardmäßig verwendet, da die IAM-Richtlinie für den Agenten es der Instanz ermöglicht, S3-Aktionen für Buckets auszuführen, die genau mit diesem Präfix benannt sind. Sie könnten den S3-Bucket beispielsweise fabric-pool-AFF1 nennen, wobei AFF1 der Name des Clusters ist. Sie können auch das Präfix für die Buckets definieren, die für das Tiering verwendet werden. SehenEinrichten von S3-Berechtigungen um sicherzustellen, dass Sie über AWS-Berechtigungen verfügen, die alle benutzerdefinierten Präfixe erkennen, die Sie verwenden möchten.
-
Speicherklasse: Cloud Tiering verwaltet die Lebenszyklusübergänge Ihrer mehrstufigen Daten. Die Daten beginnen in der Klasse Standard, Sie können jedoch eine Regel erstellen, um nach einer bestimmten Anzahl von Tagen eine andere Speicherklasse auf die Daten anzuwenden.
Wählen Sie die S3-Speicherklasse aus, in die Sie die mehrstufigen Daten übertragen möchten, und die Anzahl der Tage, bevor die Daten dieser Klasse zugewiesen werden, und wählen Sie Weiter. Der folgende Screenshot zeigt beispielsweise, dass abgestufte Daten nach 45 Tagen im Objektspeicher von der Klasse Standard der Klasse Standard-IA zugewiesen werden.
Wenn Sie Daten in dieser Speicherklasse behalten wählen, verbleiben die Daten in der Standard-Speicherklasse und es werden keine Regeln angewendet. "Siehe unterstützte Speicherklassen" .
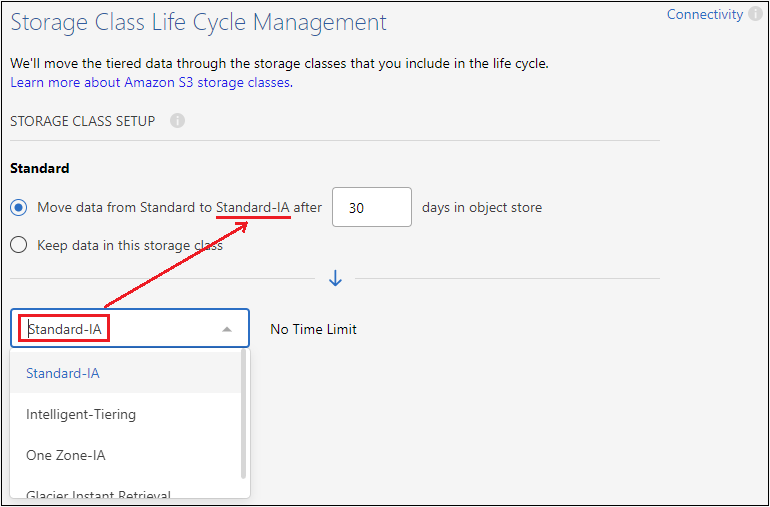
Beachten Sie, dass die Lebenszyklusregel auf alle Objekte im ausgewählten Bucket angewendet wird.
-
Anmeldeinformationen: Geben Sie die Zugriffsschlüssel-ID und den geheimen Schlüssel für einen IAM-Benutzer ein, der über die erforderlichen S3-Berechtigungen verfügt, und wählen Sie Weiter.
Der IAM-Benutzer muss sich im selben AWS-Konto befinden wie der Bucket, den Sie auf der Seite S3 Bucket ausgewählt oder erstellt haben.
-
Netzwerk: Geben Sie die Netzwerkdetails ein und wählen Sie Weiter.
Wählen Sie den IP-Bereich im ONTAP Cluster aus, in dem sich die Volumes befinden, für die Sie ein Tiering durchführen möchten. Die Intercluster-LIFs für diesen IPspace müssen über ausgehenden Internetzugang verfügen, damit sie eine Verbindung zum Objektspeicher Ihres Cloud-Anbieters herstellen können.
Wählen Sie optional aus, ob Sie einen zuvor konfigurierten AWS PrivateLink verwenden möchten. Siehe die Einrichtungsinformationen oben. Es wird ein Dialogfeld angezeigt, das Sie durch die Endpunktkonfiguration führt.
Sie können auch die zum Hochladen inaktiver Daten in den Objektspeicher verfügbare Netzwerkbandbreite festlegen, indem Sie die „Maximale Übertragungsrate“ definieren. Wählen Sie das Optionsfeld Begrenzt und geben Sie die maximal nutzbare Bandbreite ein, oder wählen Sie Unbegrenzt, um anzugeben, dass keine Begrenzung besteht.
-
-
Wählen Sie auf der Seite „Tier Volumes“ die Volumes aus, für die Sie Tiering konfigurieren möchten, und starten Sie die Seite „Tiering Policy“:
-
Um alle Bände auszuwählen, aktivieren Sie das Kontrollkästchen in der Titelzeile (
 ) und wählen Sie Volumes konfigurieren.
) und wählen Sie Volumes konfigurieren. -
Um mehrere Volumes auszuwählen, aktivieren Sie das Kontrollkästchen für jedes Volume (
 ) und wählen Sie Volumes konfigurieren.
) und wählen Sie Volumes konfigurieren. -
Um ein einzelnes Volume auszuwählen, wählen Sie die Zeile (oder
 Symbol) für die Lautstärke.
Symbol) für die Lautstärke.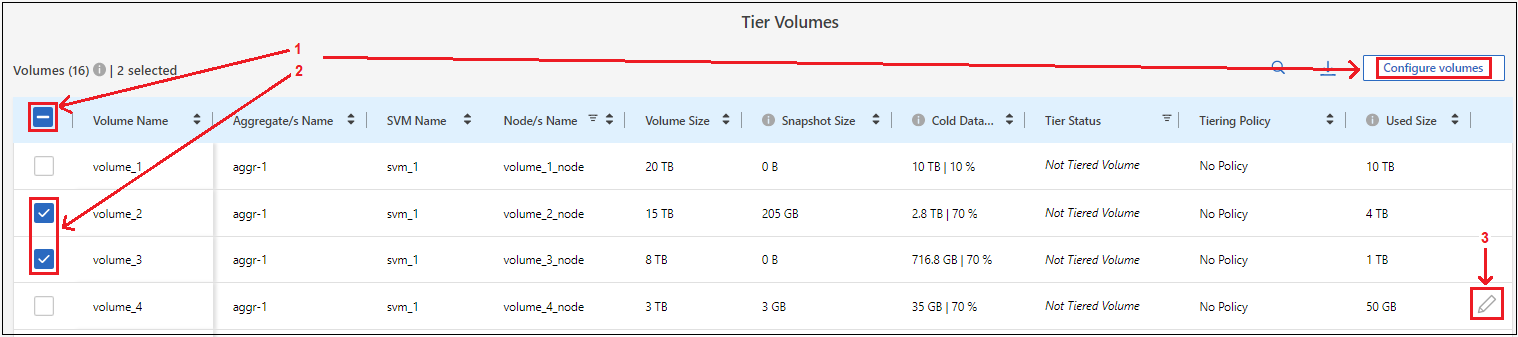
-
-
Wählen Sie im Dialogfeld „Tiering-Richtlinie“ eine Tiering-Richtlinie aus, passen Sie optional die Kühltage für die ausgewählten Volumes an und wählen Sie „Übernehmen“ aus.
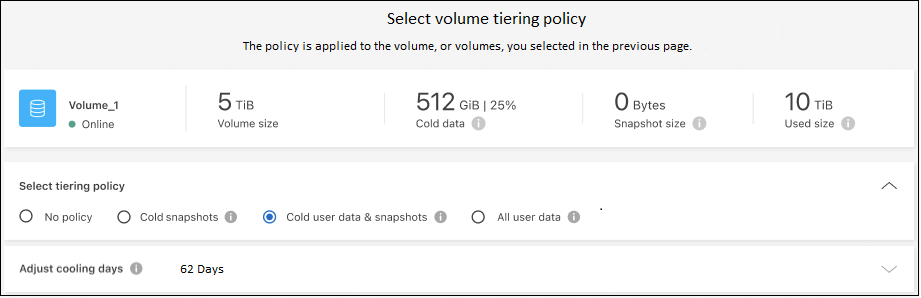
Sie haben die Datenschichtung von Volumes im Cluster zum S3-Objektspeicher erfolgreich eingerichtet.
Sie können Informationen zu den aktiven und inaktiven Daten auf dem Cluster überprüfen. "Erfahren Sie mehr über die Verwaltung Ihrer Tiering-Einstellungen" .
Sie können auch zusätzlichen Objektspeicher erstellen, wenn Sie Daten aus bestimmten Aggregaten eines Clusters auf verschiedene Objektspeicher verteilen möchten. Oder wenn Sie FabricPool Mirroring verwenden möchten, bei dem Ihre mehrstufigen Daten in einen zusätzlichen Objektspeicher repliziert werden. "Weitere Informationen zur Verwaltung von Objektspeichern" .