

Teil 2 – Nutzung von AWS Amazon FSx for NetApp ONTAP (FSx ONTAP) als Datenquelle für das Modelltraining in SageMaker
 Änderungen vorschlagen
Änderungen vorschlagen
Dieser Artikel ist ein Tutorial zur Verwendung von Amazon FSx for NetApp ONTAP (FSx ONTAP) zum Trainieren von PyTorch-Modellen in SageMaker, insbesondere für ein Projekt zur Klassifizierung der Reifenqualität.
Einführung
Dieses Tutorial bietet ein praktisches Beispiel für ein Computer Vision-Klassifizierungsprojekt und vermittelt praktische Erfahrung beim Erstellen von ML-Modellen, die FSx ONTAP als Datenquelle innerhalb der SageMaker-Umgebung verwenden. Das Projekt konzentriert sich auf die Verwendung von PyTorch, einem Deep-Learning-Framework, um die Reifenqualität anhand von Reifenbildern zu klassifizieren. Der Schwerpunkt liegt auf der Entwicklung von Modellen für maschinelles Lernen unter Verwendung von FSx ONTAP als Datenquelle in Amazon SageMaker.
Was ist FSx ONTAP
Amazon FSx ONTAP ist tatsächlich eine vollständig verwaltete Speicherlösung, die von AWS angeboten wird. Es nutzt das ONTAP Dateisystem von NetApp, um zuverlässigen und leistungsstarken Speicher bereitzustellen. Mit Unterstützung für Protokolle wie NFS, SMB und iSCSI ermöglicht es nahtlosen Zugriff von verschiedenen Compute-Instanzen und Containern. Der Dienst ist auf außergewöhnliche Leistung ausgelegt und gewährleistet schnelle und effiziente Datenvorgänge. Darüber hinaus bietet es eine hohe Verfügbarkeit und Haltbarkeit und stellt sicher, dass Ihre Daten zugänglich und geschützt bleiben. Darüber hinaus ist die Speicherkapazität von Amazon FSx ONTAP skalierbar, sodass Sie sie problemlos an Ihre Bedürfnisse anpassen können.
Voraussetzung
Netzwerkumgebung
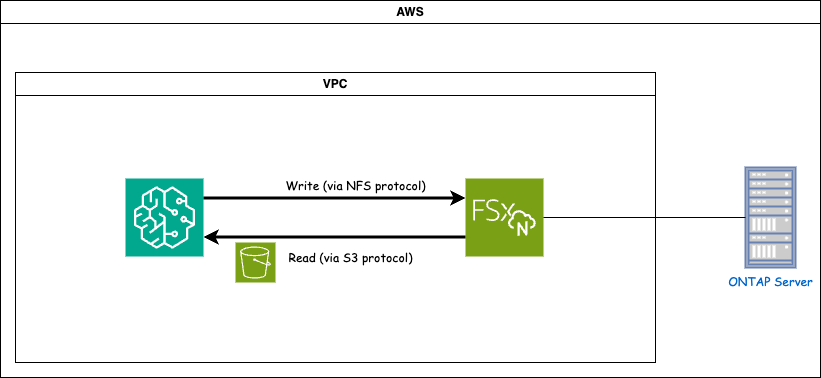
FSx ONTAP (Amazon FSx ONTAP) ist ein AWS-Speicherdienst. Es umfasst ein Dateisystem, das auf dem NetApp ONTAP -System ausgeführt wird, und eine von AWS verwaltete System-Virtual-Machine (SVM), die eine Verbindung damit herstellt. Im bereitgestellten Diagramm befindet sich der von AWS verwaltete NetApp ONTAP -Server außerhalb des VPC. Der SVM dient als Vermittler zwischen SageMaker und dem NetApp ONTAP -System, empfängt Betriebsanforderungen von SageMaker und leitet sie an den zugrunde liegenden Speicher weiter. Um auf FSx ONTAP zuzugreifen, muss SageMaker im selben VPC wie die FSx ONTAP Bereitstellung platziert werden. Diese Konfiguration gewährleistet die Kommunikation und den Datenzugriff zwischen SageMaker und FSx ONTAP.
Datenzugriff
In realen Szenarien verwenden Datenwissenschaftler normalerweise die vorhandenen, in FSx ONTAP gespeicherten Daten, um ihre Modelle für maschinelles Lernen zu erstellen. Da das FSx ONTAP Dateisystem nach der Erstellung jedoch zunächst leer ist, ist es zu Demonstrationszwecken erforderlich, die Trainingsdaten manuell hochzuladen. Dies kann erreicht werden, indem FSx ONTAP als Volume in SageMaker eingebunden wird. Sobald das Dateisystem erfolgreich gemountet ist, können Sie Ihren Datensatz an den gemounteten Speicherort hochladen und ihn so für das Training Ihrer Modelle innerhalb der SageMaker-Umgebung zugänglich machen. Mit diesem Ansatz können Sie die Speicherkapazität und Funktionen von FSx ONTAP nutzen, während Sie mit SageMaker zur Modellentwicklung und -schulung arbeiten.
Der Datenlesevorgang umfasst die Konfiguration von FSx ONTAP als privater S3-Bucket. Um die detaillierten Konfigurationsanweisungen zu erfahren, lesen Sie bitte"Teil 1 – Integration von Amazon FSx for NetApp ONTAP (FSx ONTAP) als privater S3-Bucket in AWS SageMaker"
Integrationsübersicht
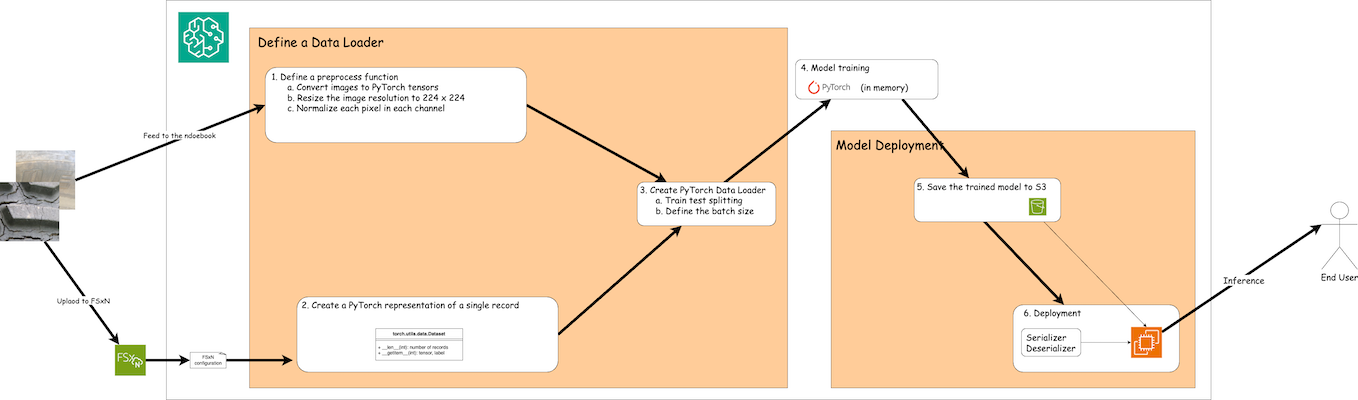
Der Workflow zur Verwendung von Trainingsdaten in FSx ONTAP zum Erstellen eines Deep-Learning-Modells in SageMaker lässt sich in drei Hauptschritte zusammenfassen: Definition des Datenladers, Modelltraining und Bereitstellung. Auf hoher Ebene bilden diese Schritte die Grundlage einer MLOps-Pipeline. Für eine umfassende Umsetzung sind jedoch zu jedem Schritt mehrere detaillierte Unterschritte erforderlich. Diese Unterschritte umfassen verschiedene Aufgaben wie Datenvorverarbeitung, Datensatzaufteilung, Modellkonfiguration, Hyperparameter-Tuning, Modellbewertung und Modellbereitstellung. Diese Schritte gewährleisten einen gründlichen und effektiven Prozess zum Erstellen und Bereitstellen von Deep-Learning-Modellen mithilfe von Trainingsdaten von FSx ONTAP innerhalb der SageMaker-Umgebung.
Schrittweise Integration
Loader
Um ein PyTorch-Deep-Learning-Netzwerk mit Daten zu trainieren, wird ein Datenlader erstellt, der die Dateneingabe erleichtert. Der Datenlader definiert nicht nur die Batchgröße, sondern bestimmt auch das Verfahren zum Lesen und Vorverarbeiten jedes Datensatzes innerhalb des Batches. Durch die Konfiguration des Datenladers können wir die Verarbeitung der Daten in Stapeln durchführen und so das Training des Deep-Learning-Netzwerks ermöglichen.
Der Datenlader besteht aus 3 Teilen.
Vorverarbeitungsfunktion
from torchvision import transforms
preprocess = transforms.Compose([
transforms.ToTensor(),
transforms.Resize((224,224)),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
])Der obige Codeausschnitt demonstriert die Definition von Bildvorverarbeitungstransformationen mithilfe des Moduls torchvision.transforms. In diesem Tutorial wird das Vorverarbeitungsobjekt erstellt, um eine Reihe von Transformationen anzuwenden. Zunächst wandelt die ToTensor()-Transformation das Bild in eine Tensordarstellung um. Anschließend wird die Bildgröße durch die Transformation Resize224,224 auf eine feste Größe von 224 x 224 Pixeln geändert. Schließlich normalisiert die Normalize()-Transformation die Tensorwerte, indem sie den Mittelwert subtrahiert und durch die Standardabweichung entlang jedes Kanals dividiert. Die zur Normalisierung verwendeten Mittelwert- und Standardabweichungswerte werden üblicherweise in vortrainierten neuronalen Netzwerkmodellen verwendet. Insgesamt bereitet dieser Code die Bilddaten für die weitere Verarbeitung oder Eingabe in ein vortrainiertes Modell vor, indem er sie in einen Tensor umwandelt, ihre Größe ändert und die Pixelwerte normalisiert.
Die PyTorch-Dataset-Klasse
import torch
from io import BytesIO
from PIL import Image
class FSxNImageDataset(torch.utils.data.Dataset):
def __init__(self, bucket, prefix='', preprocess=None):
self.image_keys = [
s3_obj.key
for s3_obj in list(bucket.objects.filter(Prefix=prefix).all())
]
self.preprocess = preprocess
def __len__(self):
return len(self.image_keys)
def __getitem__(self, index):
key = self.image_keys[index]
response = bucket.Object(key)
label = 1 if key[13:].startswith('defective') else 0
image_bytes = response.get()['Body'].read()
image = Image.open(BytesIO(image_bytes))
if image.mode == 'L':
image = image.convert('RGB')
if self.preprocess is not None:
image = self.preprocess(image)
return image, labelDiese Klasse bietet Funktionen zum Abrufen der Gesamtzahl der Datensätze im Datensatz und definiert die Methode zum Lesen der Daten für jeden Datensatz. Innerhalb der Funktion getitem verwendet der Code das S3-Bucket-Objekt boto3, um die Binärdaten von FSx ONTAP abzurufen. Der Codestil für den Zugriff auf Daten von FSx ONTAP ähnelt dem Lesen von Daten von Amazon S3. Die folgende Erklärung befasst sich eingehend mit dem Erstellungsprozess des privaten S3-Objekts Bucket.
FSx ONTAP als privates S3-Repository
seed = 77 # Random seed
bucket_name = '<Your ONTAP bucket name>' # The bucket name in ONTAP
aws_access_key_id = '<Your ONTAP bucket key id>' # Please get this credential from ONTAP
aws_secret_access_key = '<Your ONTAP bucket access key>' # Please get this credential from ONTAP
fsx_endpoint_ip = '<Your FSx ONTAP IP address>' # Please get this IP address from FSXNimport boto3
# Get session info
region_name = boto3.session.Session().region_name
# Initialize Fsxn S3 bucket object
# --- Start integrating SageMaker with FSXN ---
# This is the only code change we need to incorporate SageMaker with FSXN
s3_client: boto3.client = boto3.resource(
's3',
region_name=region_name,
aws_access_key_id=aws_access_key_id,
aws_secret_access_key=aws_secret_access_key,
use_ssl=False,
endpoint_url=f'http://{fsx_endpoint_ip}',
config=boto3.session.Config(
signature_version='s3v4',
s3={'addressing_style': 'path'}
)
)
# s3_client = boto3.resource('s3')
bucket = s3_client.Bucket(bucket_name)
# --- End integrating SageMaker with FSXN ---Um Daten von FSx ONTAP in SageMaker zu lesen, wird ein Handler erstellt, der mithilfe des S3-Protokolls auf den FSx ONTAP -Speicher verweist. Dadurch kann FSx ONTAP als privater S3-Bucket behandelt werden. Die Handler-Konfiguration umfasst die Angabe der IP-Adresse des FSx ONTAP SVM, des Bucket-Namens und der erforderlichen Anmeldeinformationen. Eine umfassende Erklärung zum Erhalt dieser Konfigurationselemente finden Sie im Dokument unter"Teil 1 – Integration von Amazon FSx for NetApp ONTAP (FSx ONTAP) als privater S3-Bucket in AWS SageMaker" .
Im oben genannten Beispiel wird das Bucket-Objekt verwendet, um das PyTorch-Dataset-Objekt zu instanziieren. Das Dataset-Objekt wird im folgenden Abschnitt näher erläutert.
Der PyTorch Data Loader
from torch.utils.data import DataLoader
torch.manual_seed(seed)
# 1. Hyperparameters
batch_size = 64
# 2. Preparing for the dataset
dataset = FSxNImageDataset(bucket, 'dataset/tyre', preprocess=preprocess)
train, test = torch.utils.data.random_split(dataset, [1500, 356])
data_loader = DataLoader(dataset, batch_size=batch_size, shuffle=True)Im bereitgestellten Beispiel wird eine Batchgröße von 64 angegeben, was bedeutet, dass jeder Batch 64 Datensätze enthält. Durch die Kombination der PyTorch-Klasse Dataset, der Vorverarbeitungsfunktion und der Trainings-Batchgröße erhalten wir den Datenlader für das Training. Dieser Datenlader erleichtert den Prozess der stapelweisen Iteration durch den Datensatz während der Trainingsphase.
Modelltraining
from torch import nn
class TyreQualityClassifier(nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(
nn.Conv2d(3,32,(3,3)),
nn.ReLU(),
nn.Conv2d(32,32,(3,3)),
nn.ReLU(),
nn.Conv2d(32,64,(3,3)),
nn.ReLU(),
nn.Flatten(),
nn.Linear(64*(224-6)*(224-6),2)
)
def forward(self, x):
return self.model(x)import datetime
num_epochs = 2
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = TyreQualityClassifier()
fn_loss = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
model.to(device)
for epoch in range(num_epochs):
for idx, (X, y) in enumerate(data_loader):
X = X.to(device)
y = y.to(device)
y_hat = model(X)
loss = fn_loss(y_hat, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
current_time = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
print(f"Current Time: {current_time} - Epoch [{epoch+1}/{num_epochs}]- Batch [{idx + 1}] - Loss: {loss}", end='\r')Dieser Code implementiert einen standardmäßigen PyTorch-Trainingsprozess. Es definiert ein neuronales Netzwerkmodell namens TyreQualityClassifier, das Faltungsschichten und eine lineare Schicht zur Klassifizierung der Reifenqualität verwendet. Die Trainingsschleife iteriert über Datenstapel, berechnet den Verlust und aktualisiert die Parameter des Modells mithilfe von Backpropagation und Optimierung. Darüber hinaus werden zu Überwachungszwecken die aktuelle Zeit, Epoche, Charge und der Verlust gedruckt.
Modellbereitstellung
Einsatz
import io
import os
import tarfile
import sagemaker
# 1. Save the PyTorch model to memory
buffer_model = io.BytesIO()
traced_model = torch.jit.script(model)
torch.jit.save(traced_model, buffer_model)
# 2. Upload to AWS S3
sagemaker_session = sagemaker.Session()
bucket_name_default = sagemaker_session.default_bucket()
model_name = f'tyre_quality_classifier.pth'
# 2.1. Zip PyTorch model into tar.gz file
buffer_zip = io.BytesIO()
with tarfile.open(fileobj=buffer_zip, mode="w:gz") as tar:
# Add PyTorch pt file
file_name = os.path.basename(model_name)
file_name_with_extension = os.path.split(file_name)[-1]
tarinfo = tarfile.TarInfo(file_name_with_extension)
tarinfo.size = len(buffer_model.getbuffer())
buffer_model.seek(0)
tar.addfile(tarinfo, buffer_model)
# 2.2. Upload the tar.gz file to S3 bucket
buffer_zip.seek(0)
boto3.resource('s3') \
.Bucket(bucket_name_default) \
.Object(f'pytorch/{model_name}.tar.gz') \
.put(Body=buffer_zip.getvalue())Der Code speichert das PyTorch-Modell in Amazon S3, da SageMaker für die Bereitstellung die Speicherung des Modells in S3 erfordert. Durch das Hochladen des Modells auf Amazon S3 wird es für SageMaker zugänglich, was die Bereitstellung und Inferenz des bereitgestellten Modells ermöglicht.
import time
from sagemaker.pytorch import PyTorchModel
from sagemaker.predictor import Predictor
from sagemaker.serializers import IdentitySerializer
from sagemaker.deserializers import JSONDeserializer
class TyreQualitySerializer(IdentitySerializer):
CONTENT_TYPE = 'application/x-torch'
def serialize(self, data):
transformed_image = preprocess(data)
tensor_image = torch.Tensor(transformed_image)
serialized_data = io.BytesIO()
torch.save(tensor_image, serialized_data)
serialized_data.seek(0)
serialized_data = serialized_data.read()
return serialized_data
class TyreQualityPredictor(Predictor):
def __init__(self, endpoint_name, sagemaker_session):
super().__init__(
endpoint_name,
sagemaker_session=sagemaker_session,
serializer=TyreQualitySerializer(),
deserializer=JSONDeserializer(),
)
sagemaker_model = PyTorchModel(
model_data=f's3://{bucket_name_default}/pytorch/{model_name}.tar.gz',
role=sagemaker.get_execution_role(),
framework_version='2.0.1',
py_version='py310',
predictor_cls=TyreQualityPredictor,
entry_point='inference.py',
source_dir='code',
)
timestamp = int(time.time())
pytorch_endpoint_name = '{}-{}-{}'.format('tyre-quality-classifier', 'pt', timestamp)
sagemaker_predictor = sagemaker_model.deploy(
initial_instance_count=1,
instance_type='ml.p3.2xlarge',
endpoint_name=pytorch_endpoint_name
)Dieser Code erleichtert die Bereitstellung eines PyTorch-Modells auf SageMaker. Es definiert einen benutzerdefinierten Serialisierer, TyreQualitySerializer, der Eingabedaten als PyTorch-Tensor vorverarbeitet und serialisiert. Die Klasse TyreQualityPredictor ist ein benutzerdefinierter Prädiktor, der den definierten Serialisierer und einen JSONDeserializer verwendet. Der Code erstellt außerdem ein PyTorchModel-Objekt, um den S3-Speicherort, die IAM-Rolle, die Framework-Version und den Einstiegspunkt für die Inferenz des Modells anzugeben. Der Code generiert einen Zeitstempel und erstellt einen Endpunktnamen basierend auf dem Modell und dem Zeitstempel. Schließlich wird das Modell mithilfe der Bereitstellungsmethode bereitgestellt, wobei die Anzahl der Instanzen, der Instanztyp und der generierte Endpunktname angegeben werden. Dadurch kann das PyTorch-Modell bereitgestellt und für Inferenzen auf SageMaker zugänglich gemacht werden.
Schlussfolgerung
image_object = list(bucket.objects.filter('dataset/tyre'))[0].get()
image_bytes = image_object['Body'].read()
with Image.open(with Image.open(BytesIO(image_bytes)) as image:
predicted_classes = sagemaker_predictor.predict(image)
print(predicted_classes)Dies ist ein Beispiel für die Verwendung des bereitgestellten Endpunkts zur Durchführung der Inferenz.