

TR-4570: NetApp -Speicherlösungen für Apache Spark: Architektur, Anwendungsfälle und Leistungsergebnisse
 Änderungen vorschlagen
Änderungen vorschlagen
Rick Huang, Karthikeyan Nagalingam, NetApp
Der Schwerpunkt dieses Dokuments liegt auf der Apache Spark-Architektur, Anwendungsfällen von Kunden und dem NetApp -Speicherportfolio im Zusammenhang mit Big Data-Analysen und künstlicher Intelligenz (KI). Darüber hinaus werden verschiedene Testergebnisse präsentiert, bei denen branchenübliche KI-, Machine-Learning- (ML) und Deep-Learning- (DL) Tools mit einem typischen Hadoop-System verglichen wurden, sodass Sie die geeignete Spark-Lösung auswählen können. Zu Beginn benötigen Sie eine Spark-Architektur, entsprechende Komponenten und zwei Bereitstellungsmodi (Cluster und Client).
Dieses Dokument enthält außerdem Anwendungsfälle von Kunden zur Lösung von Konfigurationsproblemen und bietet einen Überblick über das NetApp -Speicherportfolio, das für Big Data-Analysen sowie KI, ML und DL mit Spark relevant ist. Abschließend präsentieren wir Testergebnisse aus Spark-spezifischen Anwendungsfällen und dem NetApp Spark-Lösungsportfolio.
Kundenherausforderungen
Dieser Abschnitt konzentriert sich auf die Herausforderungen für Kunden im Zusammenhang mit Big Data Analytics und KI/ML/DL in Datenwachstumsbranchen wie Einzelhandel, digitales Marketing, Bankwesen, diskrete Fertigung, Prozessfertigung, Behörden und professionelle Dienstleistungen.
Unvorhersehbare Leistung
Bei herkömmlichen Hadoop-Bereitstellungen wird normalerweise Standardhardware verwendet. Um die Leistung zu verbessern, müssen Sie das Netzwerk, das Betriebssystem, den Hadoop-Cluster, Ökosystemkomponenten wie Spark und die Hardware optimieren. Selbst wenn Sie jede Ebene optimieren, kann es schwierig sein, das gewünschte Leistungsniveau zu erreichen, da Hadoop auf Standardhardware ausgeführt wird, die nicht für hohe Leistung in Ihrer Umgebung ausgelegt ist.
Medien- und Knotenfehler
Selbst unter normalen Bedingungen ist Standardhardware anfällig für Ausfälle. Wenn eine Festplatte auf einem Datenknoten ausfällt, betrachtet der Hadoop-Master diesen Knoten standardmäßig als fehlerhaft. Anschließend werden bestimmte Daten von diesem Knoten über das Netzwerk von Replikaten auf einen fehlerfreien Knoten kopiert. Dieser Prozess verlangsamt die Netzwerkpakete für alle Hadoop-Jobs. Der Cluster muss die Daten dann erneut zurückkopieren und die überreplizierten Daten entfernen, wenn der fehlerhafte Knoten wieder in einen fehlerfreien Zustand zurückkehrt.
Hadoop-Anbieterbindung
Hadoop-Distributoren verfügen über ihre eigene Hadoop-Distribution mit eigener Versionierung, wodurch der Kunde an diese Distributionen gebunden ist. Viele Kunden benötigen jedoch Unterstützung für In-Memory-Analysen, die den Kunden nicht an bestimmte Hadoop-Distributionen bindet. Sie müssen die Freiheit haben, die Verteilung zu ändern und trotzdem ihre Analysen mitzunehmen.
Fehlende Unterstützung für mehr als eine Sprache
Kunden benötigen zur Ausführung ihrer Aufgaben häufig zusätzlich zu MapReduce-Java-Programmen Unterstützung für mehrere Sprachen. Optionen wie SQL und Skripte bieten mehr Flexibilität beim Erhalten von Antworten, mehr Optionen zum Organisieren und Abrufen von Daten und schnellere Möglichkeiten zum Verschieben von Daten in ein Analyseframework.
Schwierigkeit der Verwendung
Seit einiger Zeit beschweren sich Leute, dass Hadoop schwierig zu verwenden sei. Obwohl Hadoop mit jeder neuen Version einfacher und leistungsfähiger geworden ist, hält sich diese Kritik hartnäckig. Hadoop erfordert, dass Sie die Programmiermuster von Java und MapReduce verstehen, was für Datenbankadministratoren und Personen mit herkömmlichen Skriptkenntnissen eine Herausforderung darstellt.
Komplizierte Frameworks und Tools
KI-Teams in Unternehmen stehen vor zahlreichen Herausforderungen. Selbst mit Expertenwissen im Bereich Data Science lassen sich Tools und Frameworks für unterschiedliche Bereitstellungsökosysteme und Anwendungen möglicherweise nicht einfach von einem zum anderen übertragen. Eine Data-Science-Plattform sollte sich nahtlos in entsprechende Big-Data-Plattformen integrieren lassen, die auf Spark basieren, und dabei einfache Datenbewegungen, wiederverwendbare Modelle, sofort einsatzbereiten Code und Tools bieten, die Best Practices für das Prototyping, Validieren, Versionieren, Teilen, Wiederverwenden und schnelle Bereitstellen von Modellen in der Produktion unterstützen.
Warum NetApp?
NetApp kann Ihr Spark-Erlebnis auf folgende Weise verbessern:
-
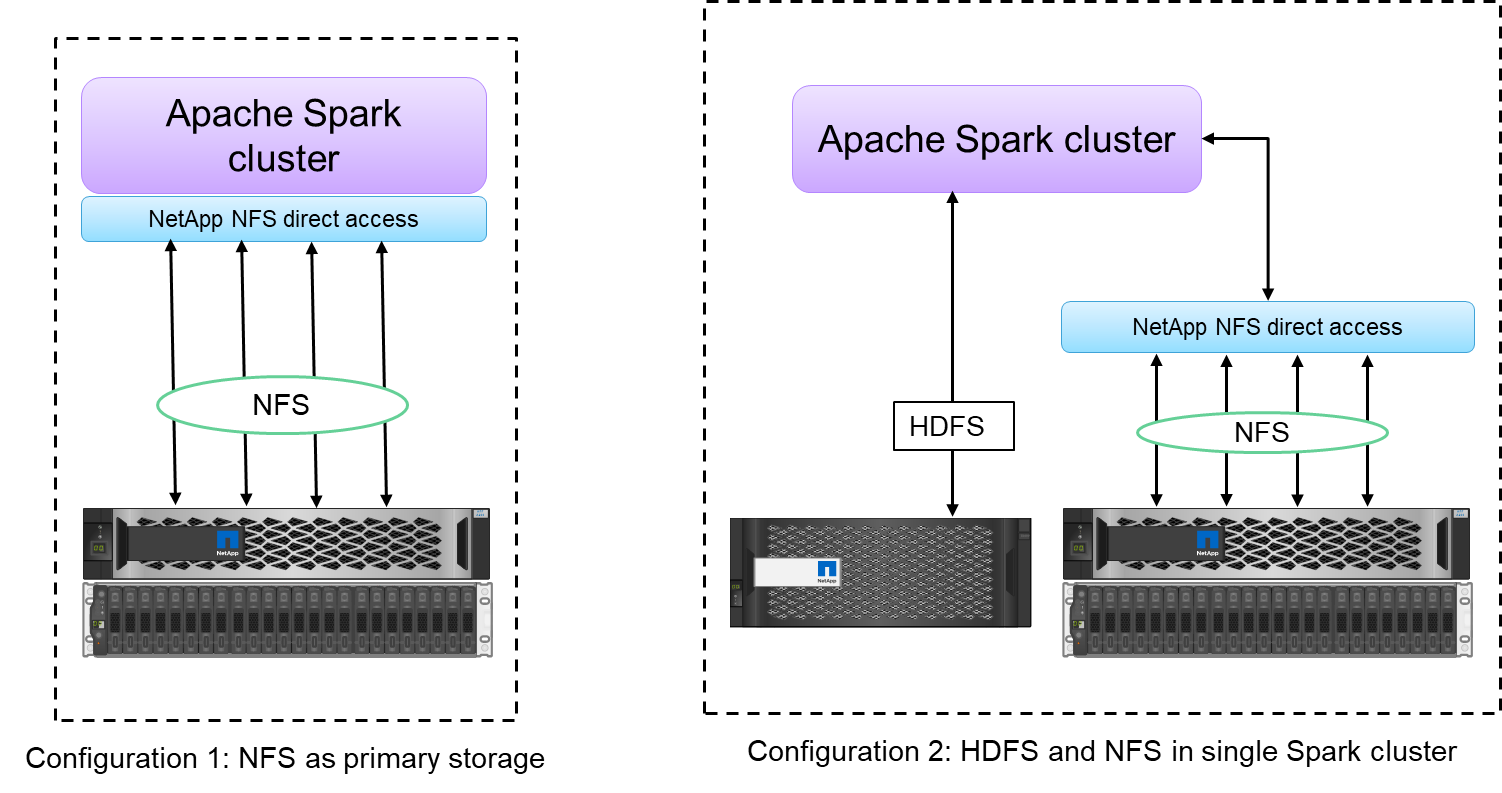
Der direkte NetApp NFS-Zugriff (siehe Abbildung unten) ermöglicht es Kunden, Big-Data-Analysejobs auf ihren vorhandenen oder neuen NFSv3- oder NFSv4-Daten auszuführen, ohne die Daten zu verschieben oder zu kopieren. Es verhindert mehrere Kopien der Daten und macht die Synchronisierung der Daten mit einer Quelle überflüssig.
-
Effizientere Speicherung und weniger Serverreplikation. Beispielsweise erfordert die NetApp E-Series Hadoop-Lösung zwei statt drei Replikate der Daten, und die FAS Hadoop-Lösung erfordert eine Datenquelle, jedoch keine Replikation oder Kopien der Daten. NetApp -Speicherlösungen erzeugen außerdem weniger Server-zu-Server-Verkehr.
-
Besseres Verhalten von Hadoop-Jobs und Clustern bei Laufwerk- und Knotenausfällen.
-
Bessere Datenaufnahmeleistung.
Im Finanz- und Gesundheitssektor beispielsweise muss die Datenübertragung von einem Ort zum anderen gesetzlichen Verpflichtungen entsprechen, was keine leichte Aufgabe ist. In diesem Szenario analysiert der NetApp NFS-Direktzugriff die Finanz- und Gesundheitsdaten von ihrem ursprünglichen Speicherort aus. Ein weiterer wichtiger Vorteil besteht darin, dass die Verwendung des direkten NetApp NFS-Zugriffs den Schutz von Hadoop-Daten durch die Verwendung nativer Hadoop-Befehle vereinfacht und Datenschutz-Workflows mit dem umfangreichen Datenverwaltungsportfolio von NetApp ermöglicht.
Der direkte NetApp NFS-Zugriff bietet zwei Arten von Bereitstellungsoptionen für Hadoop/Spark-Cluster:
-
Standardmäßig verwenden Hadoop- oder Spark-Cluster das Hadoop Distributed File System (HDFS) zur Datenspeicherung und als Standarddateisystem. Der direkte NetApp NFS-Zugriff kann das Standard-HDFS durch NFS-Speicher als Standarddateisystem ersetzen und so eine direkte Analyse von NFS-Daten ermöglichen.
-
In einer weiteren Bereitstellungsoption unterstützt der direkte NetApp NFS-Zugriff die Konfiguration von NFS als zusätzlichen Speicher zusammen mit HDFS in einem einzelnen Hadoop- oder Spark-Cluster. In diesem Fall kann der Kunde Daten über NFS-Exporte freigeben und zusammen mit HDFS-Daten vom selben Cluster aus darauf zugreifen.
Zu den wichtigsten Vorteilen des NetApp NFS-Direktzugriffs zählen die folgenden:
-
Analysieren der Daten von ihrem aktuellen Standort aus, wodurch die zeit- und leistungsintensive Aufgabe des Verschiebens von Analysedaten in eine Hadoop-Infrastruktur wie HDFS vermieden wird.
-
Reduzierung der Anzahl der Replikate von drei auf eins.
-
Ermöglicht Benutzern, Rechenleistung und Speicher zu entkoppeln, um sie unabhängig voneinander zu skalieren.
-
Bietet Unternehmensdatenschutz durch Nutzung der umfassenden Datenverwaltungsfunktionen von ONTAP.
-
Zertifizierung mit der Hortonworks-Datenplattform.
-
Ermöglicht die Bereitstellung hybrider Datenanalysen.
-
Verkürzung der Sicherungszeit durch Nutzung der dynamischen Multithread-Funktion.
Sehen"TR-4657: NetApp Hybrid Cloud-Datenlösungen – Spark und Hadoop basierend auf Kundenanwendungsfällen" zum Sichern von Hadoop-Daten, zur Sicherung und Notfallwiederherstellung von der Cloud vor Ort, zum Aktivieren von DevTest auf vorhandenen Hadoop-Daten, zum Datenschutz und zur Multicloud-Konnektivität sowie zum Beschleunigen von Analyse-Workloads.
In den folgenden Abschnitten werden Speicherfunktionen beschrieben, die für Spark-Kunden wichtig sind.
Speicher-Tiering
Mit Hadoop Storage Tiering können Sie Dateien gemäß einer Speicherrichtlinie in verschiedenen Speichertypen speichern. Zu den Speichertypen gehören hot , cold , warm , all_ssd , one_ssd , Und lazy_persist .
Wir haben die Validierung der Hadoop-Speicherschichtung auf einem NetApp AFF Speichercontroller und einem E-Series-Speichercontroller mit SSD- und SAS-Laufwerken mit unterschiedlichen Speicherrichtlinien durchgeführt. Der Spark-Cluster mit AFF-A800 verfügt über vier Compute-Worker-Knoten, während der Cluster mit E-Series acht hat. Dabei geht es hauptsächlich darum, die Leistung von Solid-State-Laufwerken (SSDs) mit der von Festplatten (HDDs) zu vergleichen.
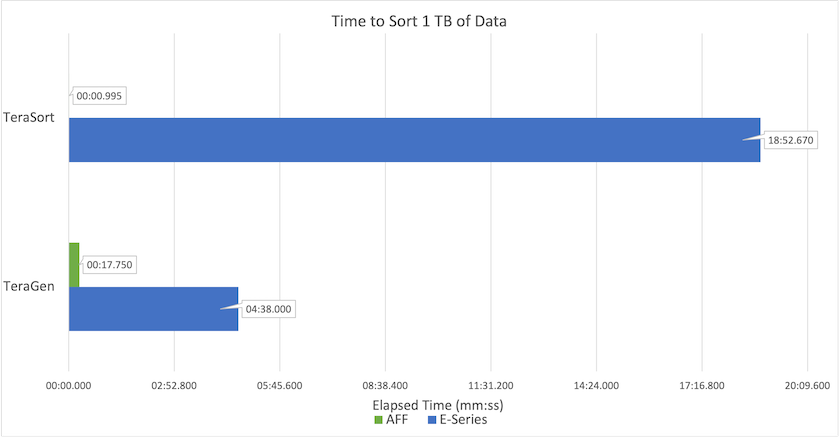
Die folgende Abbildung zeigt die Leistung von NetApp -Lösungen für eine Hadoop-SSD.
-
Die NL-SAS-Basiskonfiguration verwendete acht Rechenknoten und 96 NL-SAS-Laufwerke. Diese Konfiguration generierte 1 TB Daten in 4 Minuten und 38 Sekunden. Sehen "TR-3969 NetApp E-Series-Lösung für Hadoop" für Details zur Cluster- und Speicherkonfiguration.
-
Mit TeraGen generierte die SSD-Konfiguration 1 TB Daten 15,66-mal schneller als die NL-SAS-Konfiguration. Darüber hinaus verwendete die SSD-Konfiguration nur die Hälfte der Rechenknoten und die Hälfte der Festplattenlaufwerke (insgesamt 24 SSD-Laufwerke). Basierend auf der Zeit, die für die Auftragserledigung benötigt wurde, war es fast doppelt so schnell wie die NL-SAS-Konfiguration.
-
Mit TeraSort sortierte die SSD-Konfiguration 1 TB Daten 1138,36-mal schneller als die NL-SAS-Konfiguration. Darüber hinaus verwendete die SSD-Konfiguration nur die Hälfte der Rechenknoten und die Hälfte der Festplattenlaufwerke (insgesamt 24 SSD-Laufwerke). Daher war es pro Laufwerk ungefähr dreimal schneller als die NL-SAS-Konfiguration.
-
Das Fazit ist, dass die Umstellung von rotierenden Festplatten auf reine Flash-Speicher die Leistung verbessert. Die Anzahl der Rechenknoten war nicht der Engpass. Mit dem All-Flash-Speicher von NetApp lässt sich die Laufzeitleistung gut skalieren.
-
Mit NFS waren die Daten funktional gleichbedeutend mit einer gemeinsamen Bündelung, wodurch die Anzahl der Rechenknoten je nach Arbeitslast reduziert werden kann. Die Benutzer des Apache Spark-Clusters müssen die Daten nicht manuell neu ausbalancieren, wenn sie die Anzahl der Compute-Knoten ändern.
Leistungsskalierung – Scale-Out
Wenn Sie mehr Rechenleistung von einem Hadoop-Cluster in einer AFF Lösung benötigen, können Sie Datenknoten mit einer entsprechenden Anzahl von Speichercontrollern hinzufügen. NetApp empfiehlt, mit vier Datenknoten pro Speichercontroller-Array zu beginnen und die Anzahl je nach Arbeitslastmerkmalen auf acht Datenknoten pro Speichercontroller zu erhöhen.
AFF und FAS eignen sich perfekt für In-Place-Analysen. Basierend auf den Rechenanforderungen können Sie Knotenmanager hinzufügen und unterbrechungsfreie Vorgänge ermöglichen Ihnen, bei Bedarf und ohne Ausfallzeiten einen Speichercontroller hinzuzufügen. Wir bieten umfangreiche Funktionen mit AFF und FAS, wie z. B. NVME-Medienunterstützung, garantierte Effizienz, Datenreduzierung, QOS, prädiktive Analysen, Cloud-Tiering, Replikation, Cloud-Bereitstellung und Sicherheit. Um Kunden bei der Erfüllung ihrer Anforderungen zu unterstützen, bietet NetApp Funktionen wie Dateisystemanalyse, Kontingente und On-Box-Lastausgleich ohne zusätzliche Lizenzkosten. NetApp bietet eine bessere Leistung bei der Anzahl gleichzeitiger Jobs, eine geringere Latenz, einfachere Vorgänge und einen höheren Durchsatz in Gigabyte pro Sekunde als unsere Wettbewerber. Darüber hinaus läuft NetApp Cloud Volumes ONTAP auf allen drei großen Cloud-Anbietern.
Leistungsskalierung – Hochskalieren
Mithilfe der Scale-up-Funktionen können Sie Festplattenlaufwerke zu AFF, FAS und E-Series-Systemen hinzufügen, wenn Sie zusätzliche Speicherkapazität benötigen. Mit Cloud Volumes ONTAP ist die Skalierung des Speichers auf PB-Ebene eine Kombination aus zwei Faktoren: der Auslagerung selten verwendeter Daten aus dem Blockspeicher in den Objektspeicher und dem Stapeln von Cloud Volumes ONTAP -Lizenzen ohne zusätzliche Rechenleistung.
Mehrere Protokolle
NetApp -Systeme unterstützen die meisten Protokolle für Hadoop-Bereitstellungen, einschließlich SAS, iSCSI, FCP, InfiniBand und NFS.
Operative und unterstützte Lösungen
Die in diesem Dokument beschriebenen Hadoop-Lösungen werden von NetApp unterstützt. Diese Lösungen sind auch bei den wichtigsten Hadoop-Distributoren zertifiziert. Weitere Informationen finden Sie im "Hortonworks" Site und die Cloudera "Zertifizierung" Und "Partner" Websites.