

Lösungstechnologie
 Änderungen vorschlagen
Änderungen vorschlagen
Apache Spark ist ein beliebtes Programmierframework zum Schreiben von Hadoop-Anwendungen, das direkt mit dem Hadoop Distributed File System (HDFS) arbeitet. Spark ist produktionsbereit, unterstützt die Verarbeitung von Streaming-Daten und ist schneller als MapReduce. Spark verfügt über konfigurierbares In-Memory-Datencaching für effiziente Iteration und die Spark-Shell ist interaktiv zum Lernen und Erkunden von Daten. Mit Spark können Sie Anwendungen in Python, Scala oder Java erstellen. Spark-Anwendungen bestehen aus einem oder mehreren Jobs, die eine oder mehrere Aufgaben haben.
Jede Spark-Anwendung verfügt über einen Spark-Treiber. Im YARN-Client-Modus wird der Treiber lokal auf dem Client ausgeführt. Im YARN-Cluster-Modus läuft der Treiber im Cluster auf dem Anwendungsmaster. Im Clustermodus wird die Anwendung auch dann weiter ausgeführt, wenn die Verbindung zum Client getrennt wird.
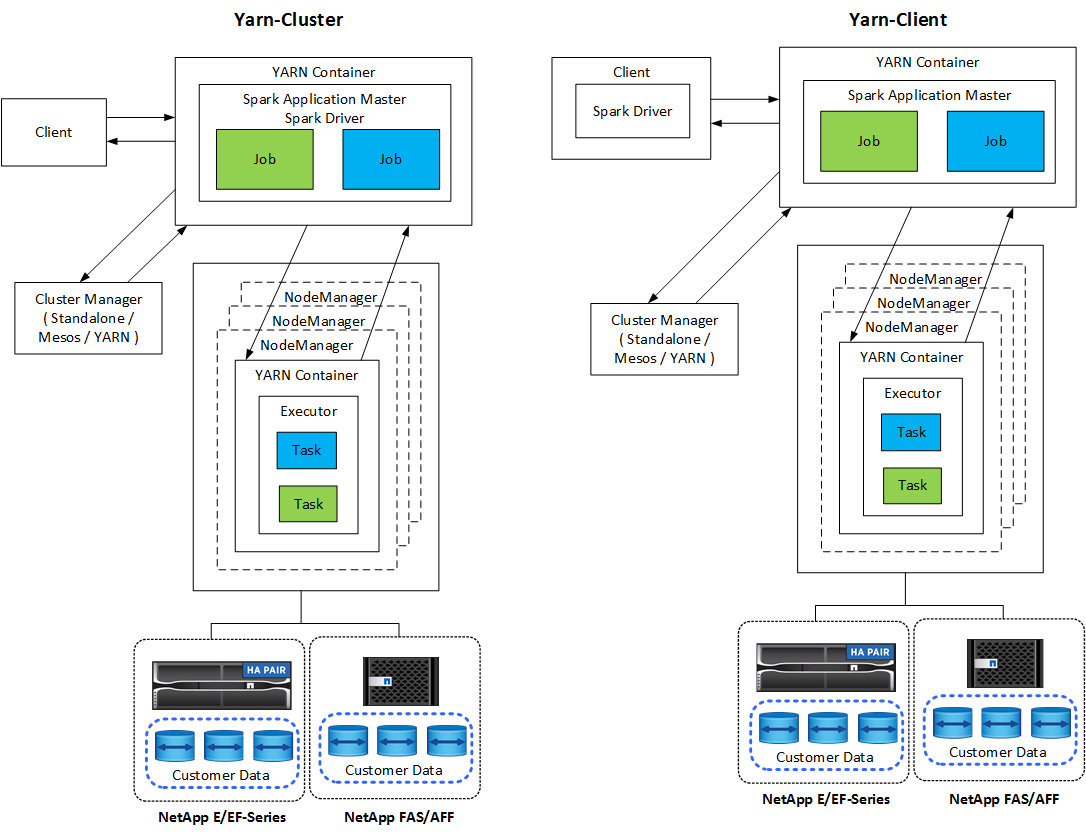
Es gibt drei Cluster-Manager:
-
Eigenständig. Dieser Manager ist Teil von Spark, wodurch die Einrichtung eines Clusters vereinfacht wird.
-
Apache Mesos. Dies ist ein allgemeiner Cluster-Manager, der auch MapReduce und andere Anwendungen ausführt.
-
Hadoop YARN. Dies ist ein Ressourcenmanager in Hadoop 3.
Der widerstandsfähige verteilte Datensatz (RDD) ist die Hauptkomponente von Spark. RDD erstellt die verlorenen und fehlenden Daten aus den im Speicher des Clusters gespeicherten Daten neu und speichert die ursprünglichen Daten, die aus einer Datei stammen oder programmgesteuert erstellt werden. RDDs werden aus Dateien, Daten im Speicher oder einem anderen RDD erstellt. Die Spark-Programmierung führt zwei Vorgänge aus: Transformation und Aktionen. Durch die Transformation wird ein neues RDD basierend auf einem vorhandenen erstellt. Aktionen geben einen Wert aus einem RDD zurück.
Transformationen und Aktionen gelten auch für Spark-Datasets und DataFrames. Ein Dataset ist eine verteilte Datensammlung, die die Vorteile von RDDs (starke Typisierung, Verwendung von Lambda-Funktionen) mit den Vorteilen der optimierten Ausführungs-Engine von Spark SQL kombiniert. Ein Datensatz kann aus JVM-Objekten erstellt und dann mithilfe funktionaler Transformationen (Map, FlatMap, Filter usw.) bearbeitet werden. Ein DataFrame ist ein in benannte Spalten organisierter Datensatz. Es ist konzeptionell gleichwertig mit einer Tabelle in einer relationalen Datenbank oder einem Datenrahmen in R/Python. DataFrames können aus einer Vielzahl von Quellen erstellt werden, beispielsweise strukturierten Datendateien, Tabellen in Hive/HBase, externen Datenbanken vor Ort oder in der Cloud oder vorhandenen RDDs.
Spark-Anwendungen umfassen einen oder mehrere Spark-Jobs. Jobs führen Aufgaben in Executoren aus und Executoren werden in YARN-Containern ausgeführt. Jeder Executor wird in einem einzelnen Container ausgeführt und Executoren existieren während der gesamten Lebensdauer einer Anwendung. Ein Executor wird nach dem Start der Anwendung fixiert und YARN ändert die Größe des bereits zugewiesenen Containers nicht. Ein Executor kann Aufgaben gleichzeitig auf Daten im Arbeitsspeicher ausführen.